04-1 로지스틱 회귀
[키워드]
로지스틱 회귀
: 선형방정식을 사용한 분류 알고리즘
- 선형회귀와 달리 시그모이드 함수나 소프트 맥스 함수를 사용하여 클래스 확률을 출력함
다중 분류
: 타깃 클래스가 2개 이상인 분류 문제
- 로지스틱 회귀는 다중 분류를 위해 소프트 맥스 함수를 사용하여 클래스를 예측함
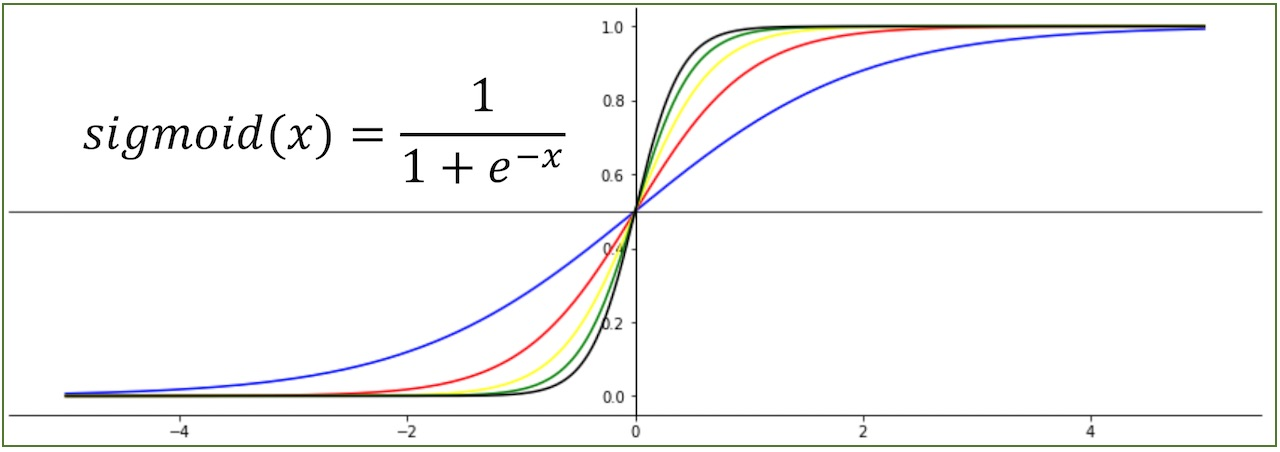
시그모이드 함수
: 선형 방정식의 출력을 0과 1사이의 값으로 압축하며 이진 분류를 위해 사용
소프트 맥스 함수
: 다중 분류에서 여러 선형 방정식의 출력 결과를 정규화하여 합이 1이 되도록 함
즉, 시그모이드 함수는 하나의 선형 방정식의 출력값을 0~1사이로 압축하지만 소프트맥스 함수는 여러 개의 선형 방정식의 출력값을 0~1사이로 랍축하고 전체 합이 1이 되도록 만듦 -> 지수함수 사용
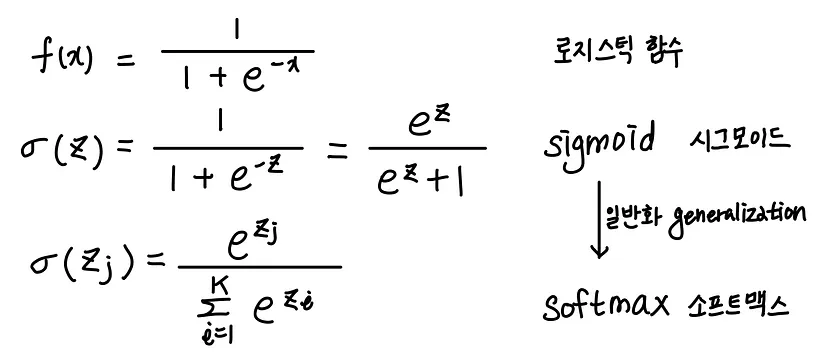
[핵심 패키지와 함수]
scikit-learn
LogisticRogression 클래스
:선형 분류 알고리즘인 로지스틱 회귀를 위한 클래스
[주요 하이퍼 파라미터]
-
solver: 사용할 알고리즘 선택lbfgs가 기본
lbfgs: 메모리 공간 절약, CPU 코어 수 많으면 최적화를 병렬로 수행
saga: 확률적 평균 경사 하강법 알고리즘으로 특성과 샘플 수가 많을 때 성능 good -
penalty: 규제방식 선택L2 규제: 릿지 방식
L1 규제: 라쏘 방식 -
C: 규제의 강도를 제어
- 기본값은 1.0, 값이 작을 수록 규제 강해짐
predict_proba() 메서드
: 예측 확률 반환
- 이중 분류에서는 샘플마다 음성 클래스와 양성 클래스에 대한 확률 반환
- 다중 분휴에서는 샘플마다 모든 클래스에 대한 확률 반환
decision_function() 메서드
: 모델이 학습한 선형 방정식의 출력 반환
- 이진 분류의 경우 양성 클래스의 확률이 반환됨
- 값이 0보다 크면 양성 클래스, 작거나 같으면 음성 클래스 - 다중 분류의 경우 각 클래스마다 선형 방정식을 계산
- 가장 큰 값의 클래스가 예특 클래스가 됨
[실습] 데이터 준비하기
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
fish.head() # 제대로 불러 왔는지 보기 위해 처음 5행 출력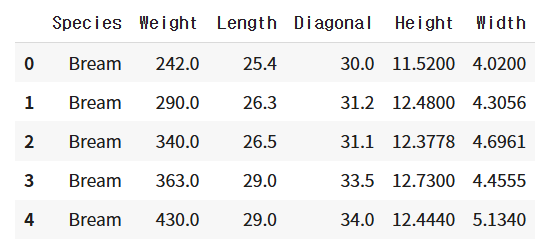
print(pd.unique(fish['Species']))
-> ['Bream' 'Roach' 'Whitefish' 'Parkki' 'Perch' 'Pike' 'Smelt'].unique(): 중복되는 거 빼고 고유한 값을 보여줌
# 입력 데이터 설정
fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
print(fish_input[:5])
->
[[242. 25.4 30. 11.52 4.02 ]
[290. 26.3 31.2 12.48 4.3056]
[340. 26.5 31.1 12.3778 4.6961]
[363. 29. 33.5 12.73 4.4555]
[430. 29. 34. 12.444 5.134 ]]
# 타깃 데이터 설정
fish_target = fish['Species'].to_numpy()
# 훈련/테스트 세트 나눠줌
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_input, fish_target, random_state=42)
# 표준 점수로 전처리
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)k-최근접 이웃 분류기의 확률 예측
- 모델 훈련시키기
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=3) # 이웃 3개
kn.fit(train_scaled, train_target)
print(kn.score(train_scaled, train_target))
print(kn.score(test_scaled, test_target))
# 점수는 현재 별로 안중요
->
0.8907563025210085
0.85
print(kn.classes_)
->
['Bream' 'Parkki' 'Perch' 'Pike' 'Roach' 'Smelt' 'Whitefish']
print(kn.predict(test_scaled[:5]))
->
['Perch' 'Smelt' 'Pike' 'Perch' 'Perch']- 타깃값을 그대로 사이킷런 모델에 전달시, 자동으로 알파벳 순서로 정렬됨
- KNeighborsClassifier에서 정렬된 타깃값은
.classes_에 저장됨
import numpy as np
proba = kn.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=4))
->
[[0. 0. 1. 0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 1. 0. ]
[0. 0. 0. 1. 0. 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]
[0. 0. 0.6667 0. 0.3333 0. 0. ]]
distances, indexes = kn.kneighbors(test_scaled[3:4])
print(train_target[indexes])
# 위 5개 중에 4번째 샘플의 인덱스 받아서 모델의 실제 이웃들 확인
->
[['Roach' 'Perch' 'Perch']].predict_proba(): 예측에 대한 확률값을 계산해주는 메소드np.round: 소수점 첫째자리에서 반올림해주는 넘파이 함수decimals: 반올림(round)의 자릿수를 지정해주는 매개변수
ex) 4번째 샘플 : Perch일 확률이 66%, Roach일 확률이 33%였음
-> 가까운 이웃을 구해보니 일치 -> 예측확률
하지만 이 경우 가능한 확률이 0, 1/3, 2/3, 3/3 뿐임
로지스틱 회귀
import numpy as np
import matplotlib.pyplot as plt
z = np.arange(-5, 5, 0.1)
phi = 1 / (1 + np.exp(-z))
plt.plot(z, phi)
plt.xlabel('z')
plt.ylabel('phi')
plt.show()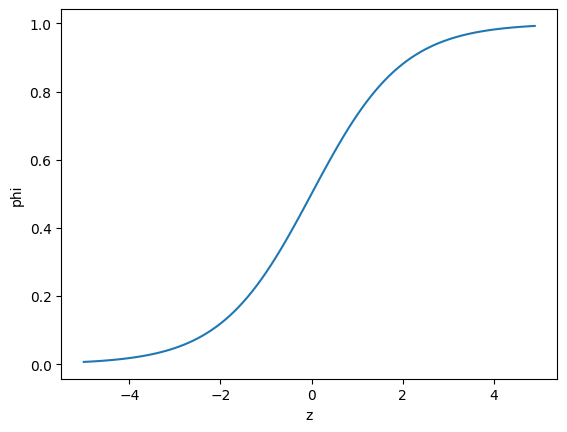
로지스틱 회귀로 이진분류하기
z=a×(무게)+b×(길이)+c×(대각선)+d×(높이)+e×(두께)+f
: z를 그대로 사용하면 회귀가 되지만 시그모이드 함수에 넣으면 0~1사이의 값이 됨 즉, 확률처럼 볼 수 있음
char_arr = np.array(['A', 'B', 'C', 'D', 'E'])
print(char_arr[[True, False, True, False, False]])
->
['A' 'C'][데이터 준비 및 모델 훈련]
- 2마리(도미, 빙어)로 이진 분류 연습하자
- 불리언 인덱싱(True, False로 분류)으로 Bream, Smelt행만 골라내기
# Bream과 Smelt인 타깃들만 True로 하고
bream_smelt_indexes = (train_target == 'Bream') | (train_target == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]
# 위에서 True로 바뀐 것들의 인덱스만 갖고 옴, 이진 분류시 사용할 데이터 준비 과정
# 로지스틱 회귀모델 객체 만들기
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt, target_bream_smelt)[샘플 예측하기]
# 처음 5개 샘플로 예측 해봄
print(lr.predict(train_bream_smelt[:5]))
->
['Bream' 'Smelt' 'Bream' 'Bream' 'Bream']
# 예측 확률 구하기
print(lr.predict_proba(train_bream_smelt[:5]))
->
[[0.99760007 0.00239993]
[0.02737325 0.97262675]
[0.99486386 0.00513614]
[0.98585047 0.01414953]
[0.99767419 0.00232581]]이진 분류에서 1열 = 음성 클래스, 2열 = 양성 클래스
사이킷런에서 타겟값을 알파벳 순으로 정렬하기 때문에 빙어는 양성, 도미는 음성이 됨
- predict_proba()가 반환한 값을 보면 두번째 샘플만 양성 클래스인 빙어의 확률이 높음, 나머지는 모두 도미로 예측할 것임
-> 이진 분류 성공~!
# 로지스틱이 학습한 계수 확인
print(lr.coef_, lr.intercept_)
->
[[-0.40451732 -0.57582787 -0.66248158 -1.01329614 -0.73123131]] [-2.16172774]-
절편과 계수가 있기 때문에 회귀방정식 사용해볼 수 있음
→ 방정식에 따라 샘플마다의 z값도 구할 수 있음 -
.decision_function(): LogisticRegression()에서 z값을 출력하는 메소드
# 샘플 5개의 z값 출력하기
decisions = lr.decision_function(train_bream_smelt[:5])
print(decisions)
->
[-6.02991358 3.57043428 -5.26630496 -4.24382314 -6.06135688] → 이 z값을 시그모이드 함수에 넣으면 확률을 얻을 수 있음
from scipy.special import expit
print(expit(decisions))
->
[0.00239993 0.97262675 0.00513614 0.01414953 0.00232581]expit(): 사이파이 라이브러리에서 제공하는 시그모이드 함수- 이진분류에서
decision_function의 반환값은 양성클래스에 대한 z값임(음성 = 1-양성으로 계산)
로지스틱 회귀로 다중분류하기
[모델 훈련]
- 7마리 분류하는 훈련
- 이진분류와 방식 동일
C: (릿지의 alpha처럼) 규제의 양을 조절하는 매개변수. (기본값=1)max_iter: 충분한 훈련을 위해 반복횟수를 지정하는 매개변수 (기본값=100)
lr = LogisticRegression(C=20, max_iter=1000)
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
->
0.9327731092436975
0.925[샘플 예측하기]
print(lr.predict(test_scaled[:5]))
->
['Perch' 'Smelt' 'Pike' 'Roach' 'Perch']테스트 세트의 처음 5개에 대한 샘플을 예측함
[예측확률 구하기]
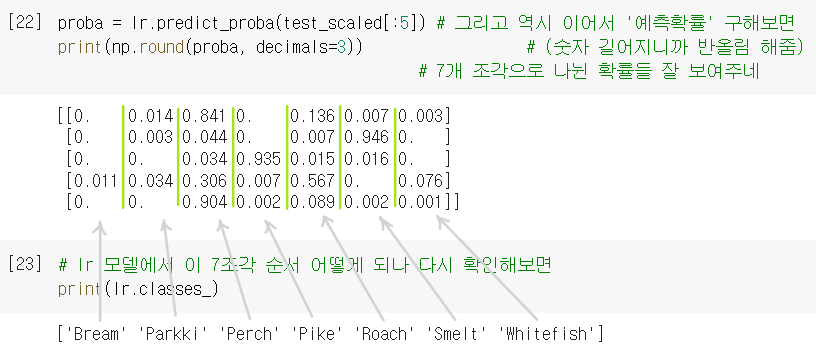
다중 분류에서 클래스 개수만큼 확률을 출력함
첫번째 샘플은 Bream일 확률 0 / Parkki일 확률 0.014 / Perch일 확률 0.841 / Pike일 확률 0 / Roach일 확률 0.136 / Smelt일 확률 0.007 / Whitefish일 확률 0.003 으로 봄
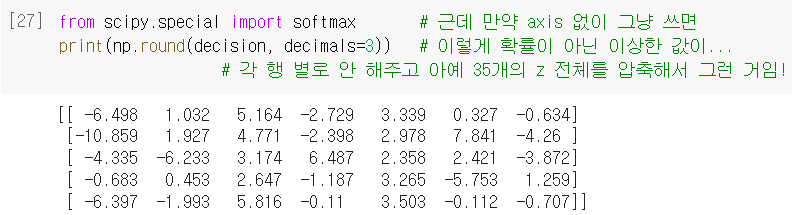
print(lr.coef_.shape, lr.intercept_.shape)
->
(7, 5) (7,)- 이 데이터는 5개의 특성 사용함 -> coef_배열의 열은 5개
- 행이 7이 나옴, intercept_도 7나옴
-> 즉, z값을 7개 계산한다는 의미- 다중 분류는 클래스마다 z값을 하나씩 계산함
-> 가장 높은 값은 z값을 출력하는 예측 클래스가 됨
- 다중 분류는 클래스마다 z값을 하나씩 계산함
decision = lr.decision_function(test_scaled[:5])
print(np.round(decision, decimals=2))
->
[[ -6.51 1.04 5.17 -2.76 3.34 0.35 -0.63]
[-10.88 1.94 4.78 -2.42 2.99 7.84 -4.25]
[ -4.34 -6.24 3.17 6.48 2.36 2.43 -3.87]
[ -0.69 0.45 2.64 -1.21 3.26 -5.7 1.26]
[ -6.4 -1.99 5.82 -0.13 3.5 -0.09 -0.7 ]]- 절편과 계수로 회귀방정식 사용
- 방정식이 7세트 나옴 -> 샘플마다 z값도 7개씩 나옴
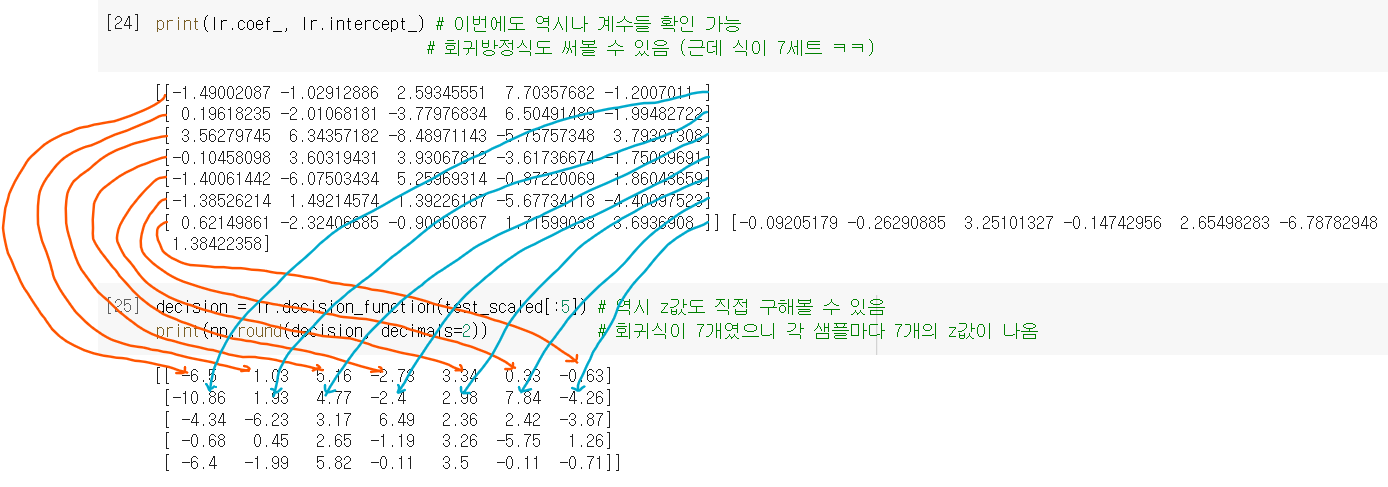
from scipy.special import softmax
proba = softmax(decision, axis=1)
print(np.round(proba, decimals=3))
->
[[0. 0.014 0.842 0. 0.135 0.007 0.003]
[0. 0.003 0.044 0. 0.007 0.946 0. ]
[0. 0. 0.034 0.934 0.015 0.016 0. ]
[0.011 0.034 0.305 0.006 0.567 0. 0.076]
[0. 0. 0.904 0.002 0.089 0.002 0.001]]- 이진분류에서 확률을 시그모이드 함수로 계산했지만 다중 분류는 소프트 맥스 함수를 이용해 7개의 z값을 확률로 변환
- 다중분류는 이진분류(샘플당 z값 1개)와 달리 z값이 여러개라서 다 합치면 1을 넘어갈 수 있음
-> 이를 해결하는게 소프트맥스 함수 softmax(): 여러 개의 선형방정식의 출력값(z)을 0~1 사이로 압축하고, 총합이 1이 되게 만드는 함수.

[참고]
- 소프트맥스 함수의 axis: 소프트맥스 계산의 단위를 각 행마다 하기 위해서 설정
04-2 확률적 경사 하강법
[키워드]
확률적 경사 하강법
: 훈련 세트에서 샘플 하나씩 꺼내 손실 함수의 경사를 따라 최적의 모델을 찾는 알고리즘
- 샘플을 하나씩 사용하지 않고 여러 개를 사용하면 미니배치 경사 하강법이 됨
- 한 번에 전체 샘플을 사용하면 배치 경사 하강법이 됨
손실함수
: 확률 경사 하강법이 최적화될 대상
- 대부분의 문제에 잘 맞는 손실 함수는 이미 정의되어 있음
- 이진 분류에서는 로지스틱 회귀 손실 함수를 사용
- 다중 분류에서는 크로스엔트로피 손실 함수를 사용
- 회귀 문제에서는 평균 오차 손실 함수 사용
에포크
: 확률적 경사 하강법에서 전체 샘플을 모두 사용하는 한 번 반복을 의미
- 일반적으로 경사 하상법 알고리즘은 수십에서 수백 번의 에포크를 반복함
- 지나치게 에포크를 높이게 되면 그 학습 데이터셋에 과적합(Overfitting)되어 다른 데이터에 대해서 제대로 예측을 못할 수 있음
확률적 경사 하강법
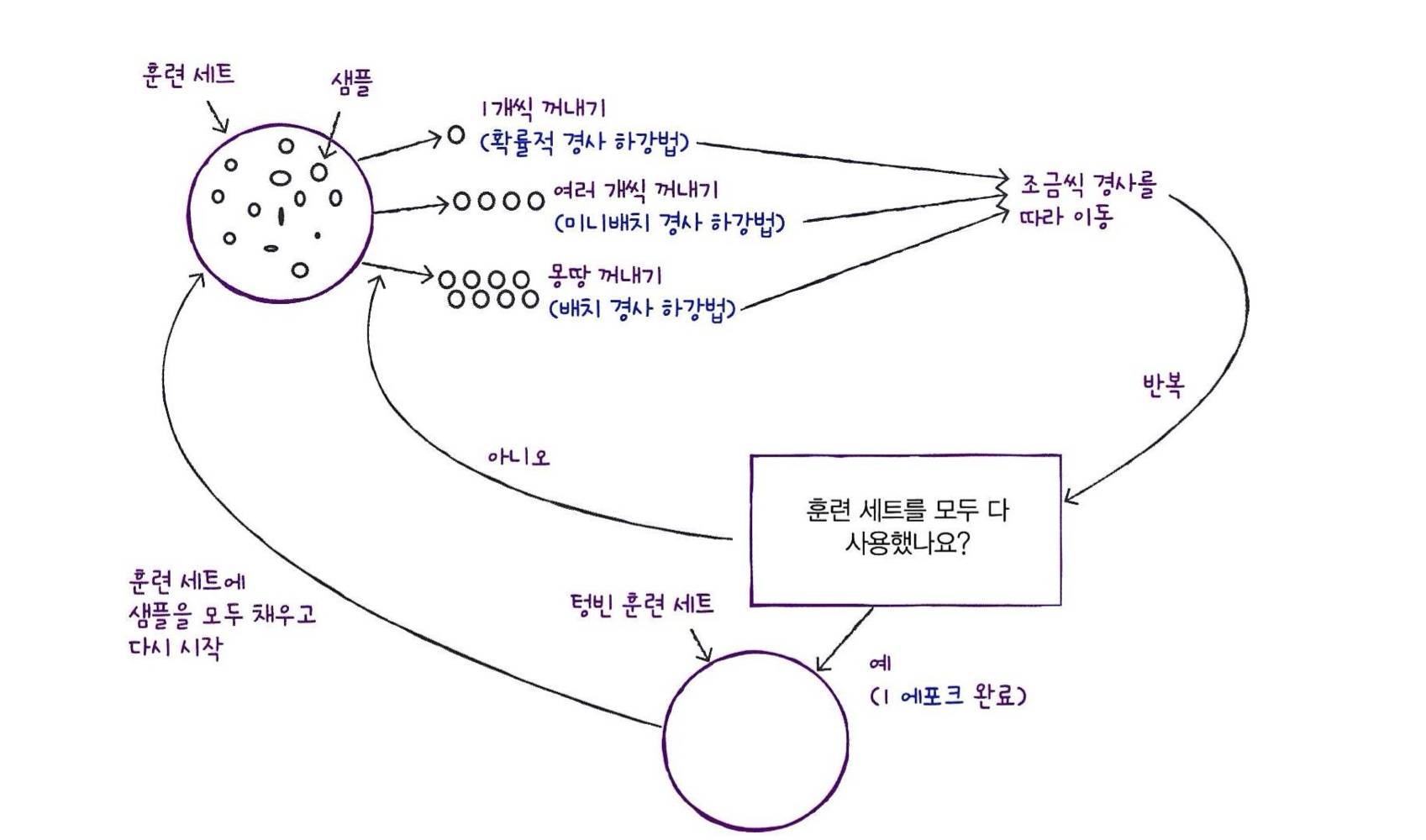
확률적 경사 하강법(SGD)
- 대표적인 '점진적 학습법', '알고리즘'이 아니라 이런 알고리즘을 '최적화 하는 방법'임
경사 하강: 가장 가파른 경사를 따라 조금씩 내려감확률적: 전체 샘플을 사용하지 않고 훈련 세트에서 딱 하나를 랜덤하게 골라 훈련함 = 전체 샘플을 다 쓸 때 까지 계속 하나씩 꺼내면서 조금씩 하강
-> 샘플을 다 사용했는데도 내려오지 못했다면
- 다시 샘플을 채워 넣고 같은 방법으로 내려가면 됨
- 에포크(epoch): 훈련세트를 한 번 모두 사용하는 과정
- 보통 수번백의 에포크를 거침
미니배치 경사 하강법(minibatch-GD)
- 한 개씩만 꺼내는게 아니라 여러개씩 꺼내서 경사하강법 가능
- 개수는 보통 2의 배수로 하는 것이 일반적
배치 경사 하강법(batch-GD)
- 아예 샘플을 모두 꺼내서 경사하강
- 가장 안정적인 방법, 메모리적 한계 때문에 잘 사용x