05-1 결정 트리
[키워드]
결정 트리: 예/아니오에 대한 질문을 이어나가면서 정답을 찾아 학습하는 알고리즘불순도: 결정트리가 최적의 질문을 찾기위한 기준, 사이킷런에서는 '지니 불순도'와 '엔트로피 불순도'제공정보 이득: 부모 노드와 자식 노드의 불순도 차이, 결정 트리의 알고리즘은 정보 이득이 최대화 되도록 학습가지치기: 결정 트리는 제한 없이 성장하면 훈련 세트에 과대적합되기 쉬움, 가지치기로 트리의 성장을 제한하는 방법
사이킷런의 결정 트리 알고리즘은 여러 가지치기 매개변수를 제공특성 중요도: 결정 트리에 사용된 특성이 불순도를 감소하는데 기여한 정도를 나타낸 값, 이를 계산할 수 있는 것이 결정 트리의 장점
로지스틱 회귀로 와인 분류하기
데이터 준비
- psndas로 데이터 불러옴
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')
wine.head()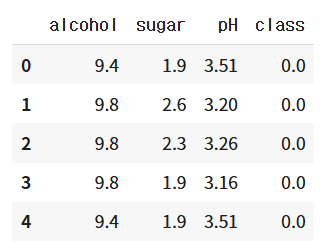
.info(): 데이터 타입, 누락 여부, 메모리 크기 등의 기본 정보를 보여주는 메소드.describe(): 각 열마다 간략한 통계치들을 출력해주는 메소드
wine.info()
wine.describe()
->
]
wine.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6497 entries, 0 to 6496
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 alcohol 6497 non-null float64
1 sugar 6497 non-null float64
2 pH 6497 non-null float64
3 class 6497 non-null float64
dtypes: float64(4)
memory usage: 203.2 KB
alcohol sugar pH class
count 6497.000000 6497.000000 6497.000000 6497.000000
mean 10.491801 5.443235 3.218501 0.753886 # 평균
std 1.192712 4.757804 0.160787 0.430779 # 표준편차
min 8.000000 0.600000 2.720000 0.000000 # 최소
25% 9.500000 1.800000 3.110000 1.000000 # 1사분위수
50% 10.300000 3.000000 3.210000 1.000000 #중간값/2사분위수
75% 11.300000 8.100000 3.320000 1.000000 # 3사분위수
max 14.900000 65.800000 4.010000 1.000000 # 최대test_size: 테스트 데이터로 나눌 크기 ex) 0.2 -> 20%
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42)
print(train_input.shape, test_input.shape)
->
(5197, 3) (1300, 3)
# 훈련세트: 5197개, 테스트 세트: 1300개- StandardScaler 클래스 사용해 훈련 세트 전처리
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)- 표준점수로 변환된 train_scaled와 test_scaled를 사용해 로지스틱 회귀 모델 훈련
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
->
0.7808350971714451
0.7776923076923077=> 훈련 세트와 테스트 세트의 점수가 모두 낮음, 과소적합
문제 해결을 위해
규제 매개변수 C의 값 변경 or solver 매개변수에서 다른 알고리즘 선택 or 다항특성 추가
설명하기 쉬운 모델과 어려운 모델
- 로지스틱 회귀가 학습한 계수와 절편 출력
print(lr.coef_, lr.intercept_)
->
[[ 0.51268071 1.67335441 -0.68775646]] [1.81773456]로지스틱 회귀의 단점
-
로지스틱 회귀모델은 계수와 절편을 학습, but 그 숫자들이 정확히 어떤 의미인지 설명하기 쉽지 않음
ex) "알코올 도수0.512720274 + 당도1.6733911 - pH*0.68767781 + 1.81777902를 계산한 값이 0보다 크면 화이트와인입니다..!" -
다항 특성을 추가한다면 더 복잡해짐
ex) (알코올도수∗pH) or (당도^2) 뭐라고 설명하지?
결정 트리(Decision Tree)
: 예/아니오에 대한 질문을 이어나가면서 정답을 찾는 알고리즘
: 비교적 예측 과정을 이해하기 쉽고 성능 Good
결정 트리 모델 훈련
DecisionTreeClassifier(): 결정트리 알고리즘
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
->
0.996921300750433
0.8592307692307692=> 훈련 세트에 대한 점수 높음, 테스트 세트 상대적으로 낮음, 과대적합
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()
- 트리의 깊이를 제한하여 다시 그려보기
max_depth: 루트 노드 및에 몇 층을 더 그릴지 설정하는 매개변수filled: 클래스의 비율에 맞게 노드를 색칠해주는 매개변수feature_names: 특성의 이름을 전달하는 매개변수 (없으면 'x[1]'으로 나옴)
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()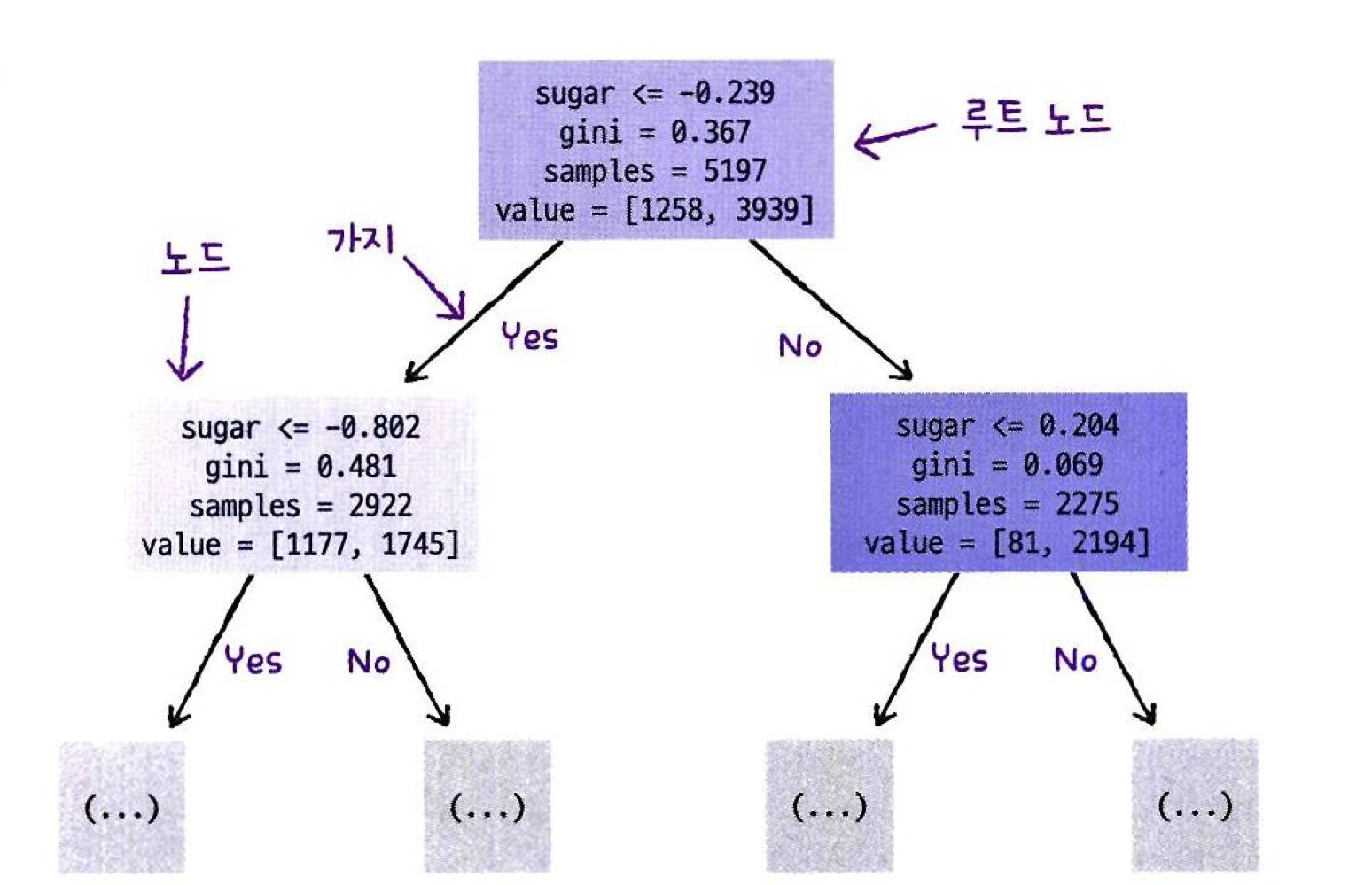
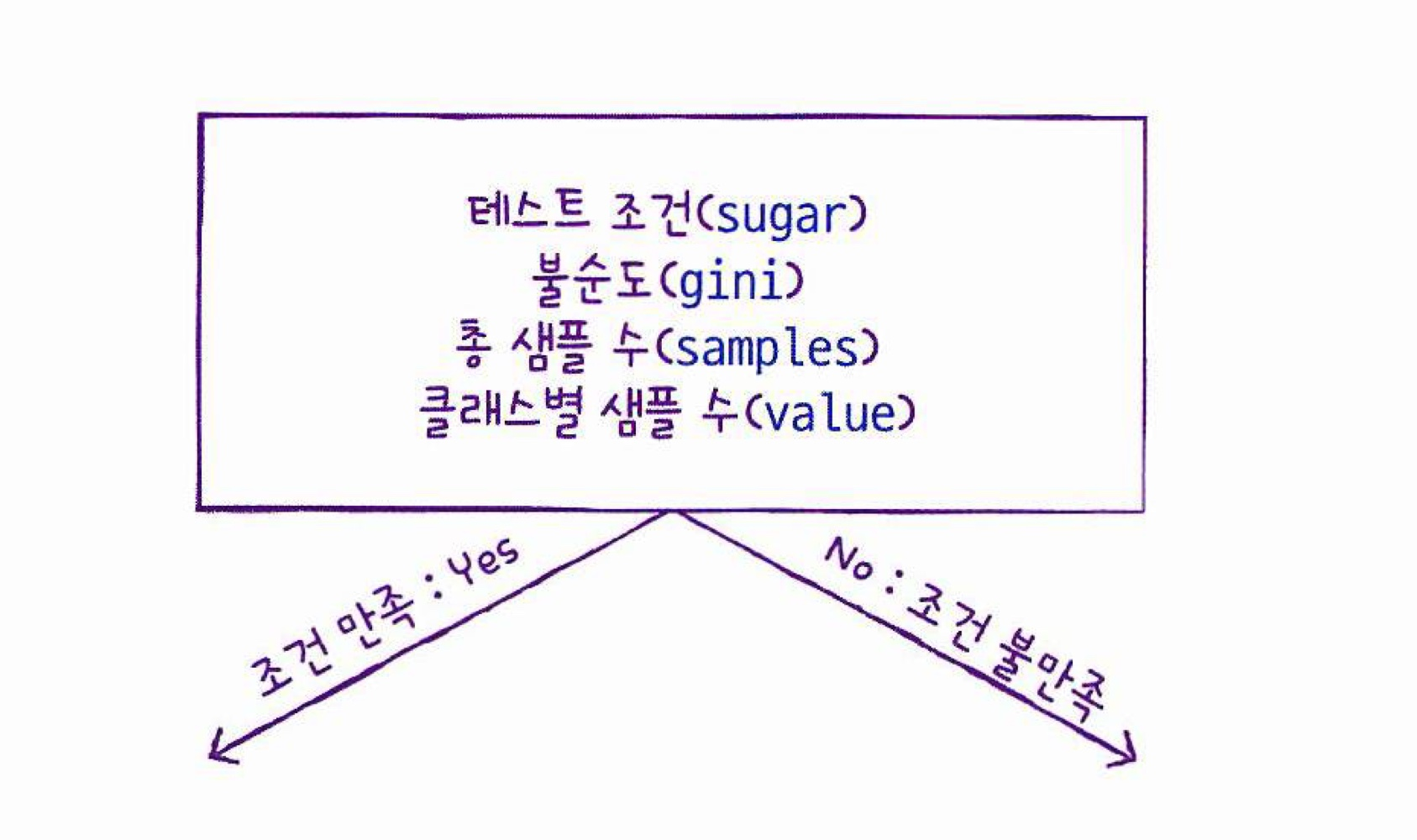
불순도
- 노드를 나누는 기준이 되는 수치
criterion매개변수로 설정 가능(기본값:gini)
지니 불순도 = 1 - (음성 클래스 비율^2 + 양성 클래스 비율^2)
-
불순도 0.5: 두 클래스가 정확히 반반으로 나누어져서 구분의 의미X, 최악의 노드
-
불순도 0: 노드에 한 클래스만 있는 경우, 완벽히 구분된 최선의 노드 = '순수 노드'
-
결정 트리 모델은 부모노드와 자식노드의 불순도 차이가 크도록 노드를 나눔
-> 이 차이를 '정보 이득'이라 함, 노드를 순수하게 나눌 수록 이득이 커짐
[정보 이득 계산(불순도 차이)]
부모의 불순도 - (왼쪽 노드 샘플 수/부모노드 샘플 수) x 왼쪽 노드 불순도 - (오른쪽 노드 샘플 수/부모의 샘플 수) x 오른쪽 노드 불순도
*DecisionTreeClassifier에서 불순도 차이가 크도록 알아서 노드를 분할 시킴
가지치기
- 무작정 깊이 훈련 시키면 훈련세트에만 과대적합됨
*트리의 깊이 제한x시, 리프노드가 순수노드가 될 때까지 함 - 이를 막기 위해 '가지 치기'함 ->
max_depth로 깊이 지정
(참고) 결정 트리는 선형 회귀처럼 가중치x -> L1, L2 규제 사용x
# 앞에서 훈련을 과도하게 하여 과대적합이 되었어서 규제 필요
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
->
0.8454877814123533
0.8415384615384616=> 깊이 3으로 지정하여 모델 만듦, 훈련 세트 성능 낮아졌지만 테스트 세트의 성능은 그대로
((과소적합된 거 아닌강..)) -> 0.8넘으면 낮은 건 아닌듯!
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()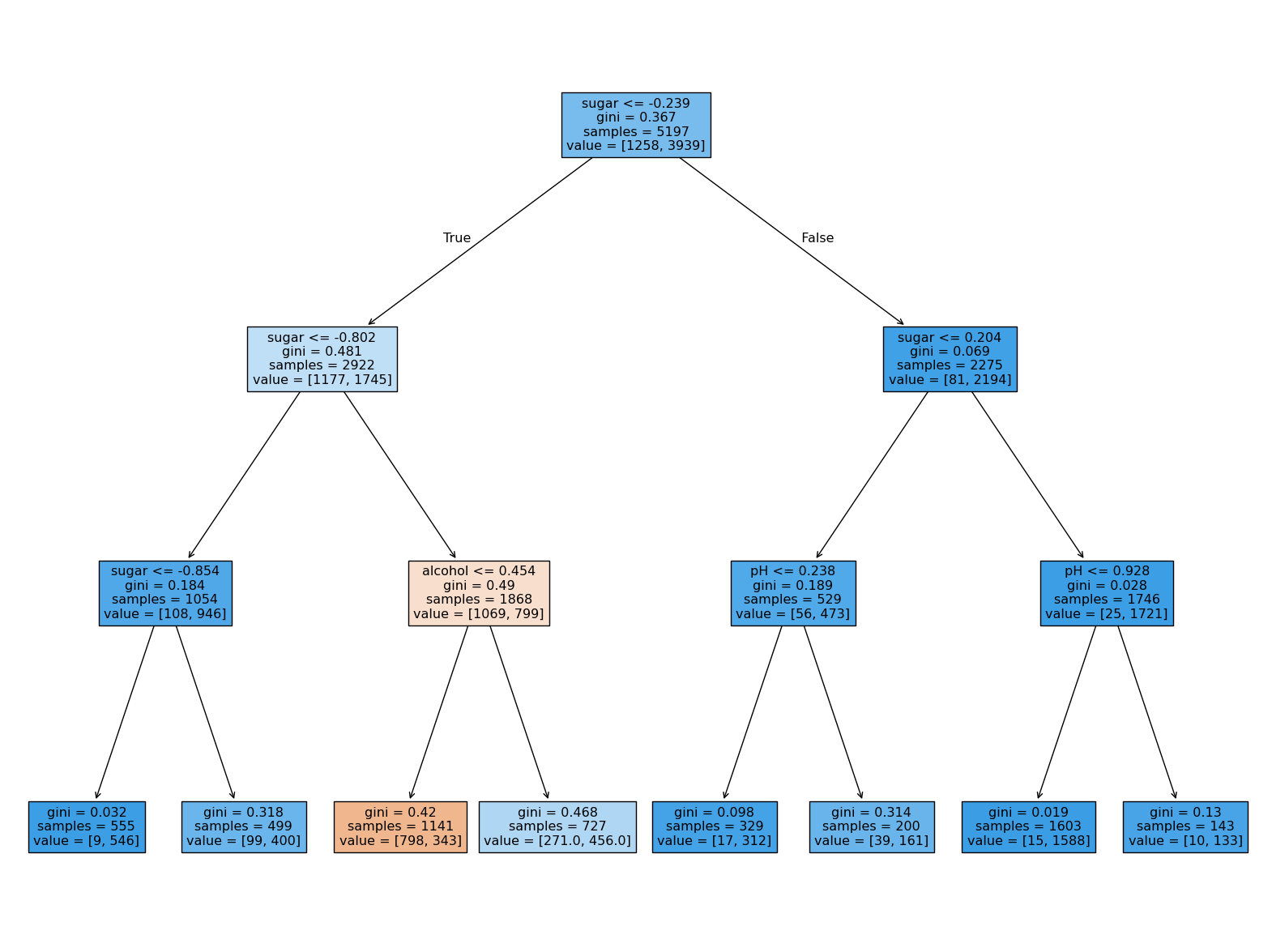
↪ 왼쪽에서 3번째 노드에 도착하는 경우만 음성 클래스(red)로 예측!
↪ "−0.802<sugar≤−0.239 이면서 alcohol≤0.454 인 경우만 red로 분류되고, 나머지 경우는 white로 분류하는 모델이 완성
결정트리의 장점
- 표준화 전처리 필요 X
: 위의 결과에서 당도가 -0.802 음수로 설명되어 있음. 그런데 불순도의 정의를 보면 클래스별 비율을 가지고 계산하기 때문에 특성값의 스케일이 영향을 미치지 않음
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_input, train_target) #표준화 하기 전 input으로 넣음
print(dt.score(train_input, train_target))
print(dt.score(test_input, test_target))
->
0.8454877814123533
0.8415384615384616=> 전처리 안 한 train_input으로 넣어도 값이 같은 걸 알 수 있음
↪ "1.625<sugar≤4.325 이면서 alcohol≤11.025 인 경우만 red로 예측
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show() # 그려봤을 때 숫자들 양수로 나옴 -> 해석 쉬워짐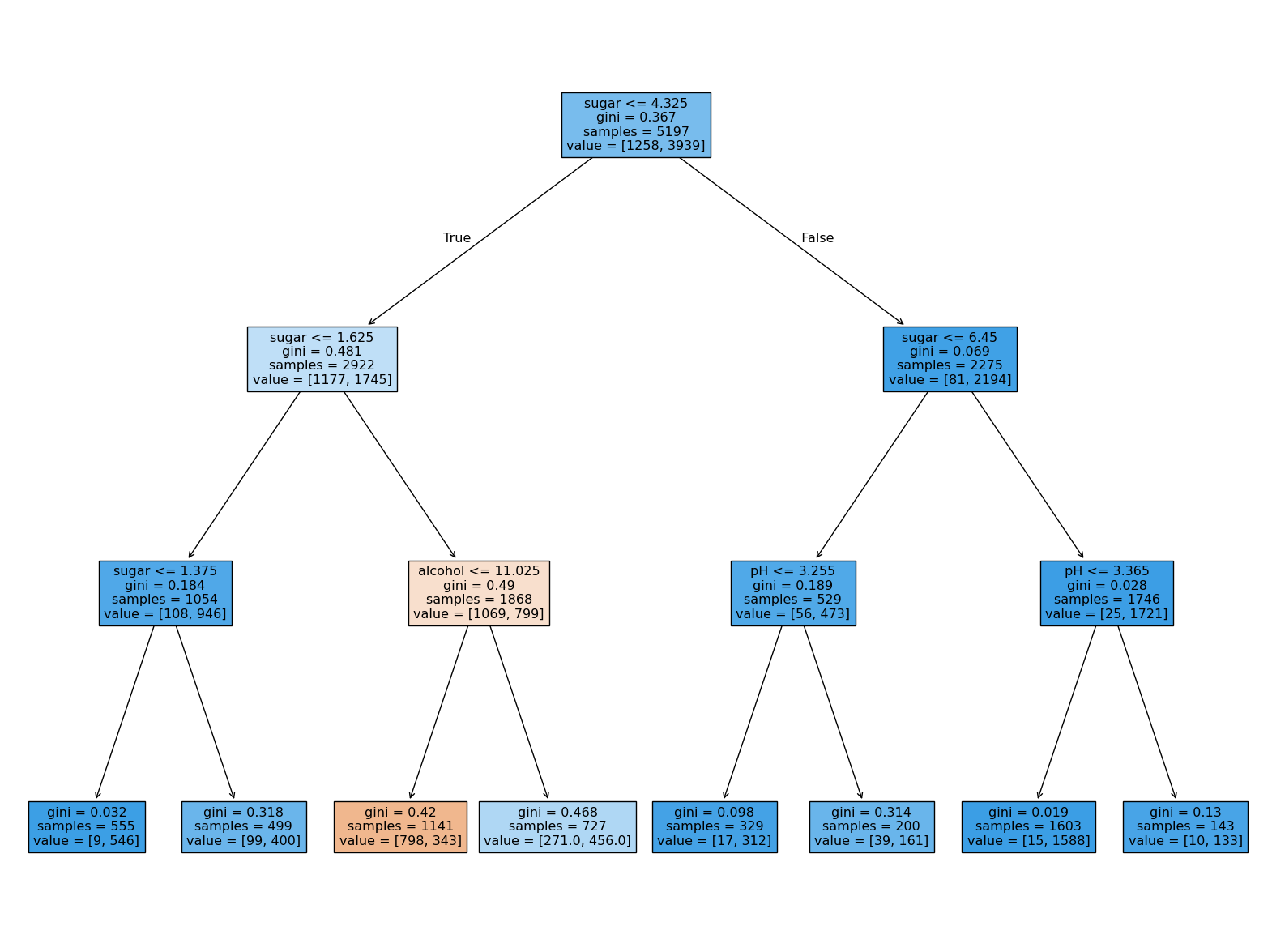
dt.feature_importances_: 어떤 특성이 가장 유용한지 '특성 중요도' 계산해줌
print(dt.feature_importances_)
->
[0.12345626 0.86862934 0.0079144 ]
# alcohol sugar pH=> sugar, 당도가 가장 중요도가 높은 것을 알 수 있음
-
그래프를 직관적으로 이해하기 좋음
: 특정 클래스 비율이 높아질 수록 색깔이 진해지기 때문에 어떤 노드가 어떤 클래스인지 한 눈에 보기 쉬움
ex) 위 그래프에서 3번째 노드만 주황색으로 칠해져있어 이 노드만 음성 클래스이고 나머지는 양성 클래스라는 것을 알 수 있음 -
회귀모델보다 설명하기 쉬움
: 어떤 조건이면 어떤 클래스인지가 명확하게 구분되기에 해석이 쉬움
다만, 트리의 깊이가 깊어지면 해석이 쉽지 않아질 수 있음
05-2 교차 검증과 그리드 서치
[키워드]
검증세트
: 하이퍼파라미터 튜닝을 위한 모델을 평가할 때, 테스트 세트를 사용하지 않기 위해 훈련 세트에서 다시 떼어낸 데이터 세트
교차 검증
: 훈련 세트를 여러 폴드로 나눈 다음 한 폴드가 검증 세트의 역할을 하고 나머지 폴드에서는 모델 훈련을 함
-> 이런 식으로 모든 폴드에 대해 검증 점수를 얻어 평균을 내는 방법
그리드 서치
: 하이퍼파라미터 탐색을 자동화해 주는 도구, 탐색할 매개변수를 나열하면 교차 검증을 수행하여 가장 좋은 검증 점수의 매개변수 조합을 선택 -> 이 매개변수의 조합으로 최종 모델을 훈련함
랜덤 서치
: 연속된 매개변수 값을 탐색할 때 유용, 탐색할 값을 직접 나열하는 것이 아니라 탐색 값을 샘플링할 수 있는 확률 분포 객체를 전달
- 지정된 횟수만큼 샘플링하여 교차 검증을 수행하기 때문에 시스템 자원이 허락하는 만큼 탐색량 조절 가능
검증세트
- 훈련/검증/테스트 3개의 세트로 나눔
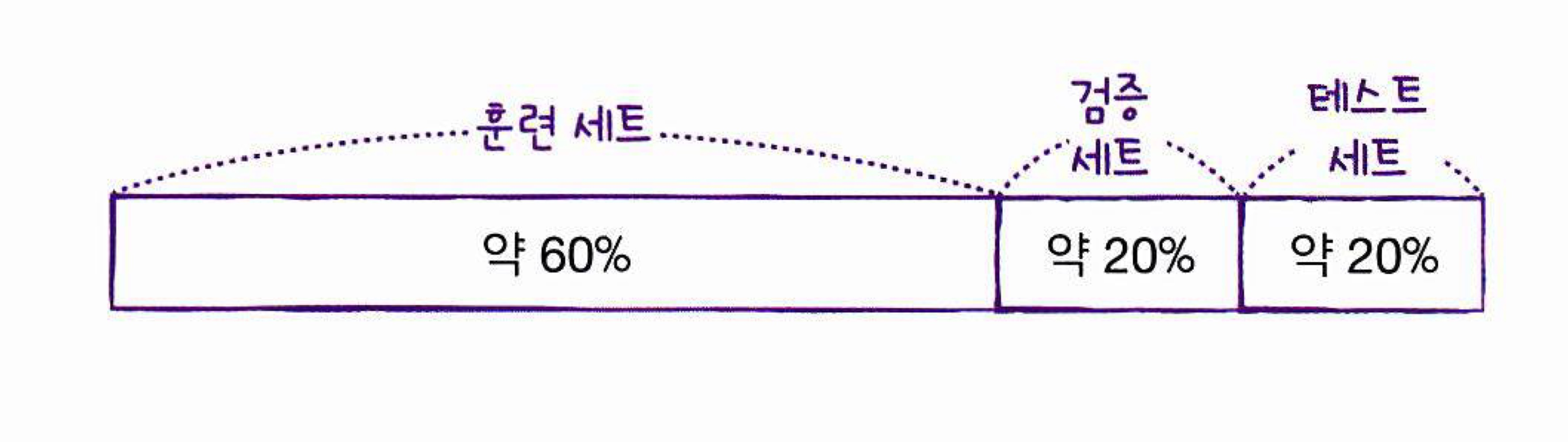
+) 테스트 세트와 검증 세트를 얼마나 나눠야 될까?
: 보통 20~30% 테스트/검증으로 나누지만 훈련 데이터가 많다면 단 몇 %만 떼어 놓아도 전체 데이터를 대표하는데 문제 X
- 일반적인 활용 과정
1) 모델을 훈련세트로 훈련(fit)하고, 검증세트로 평가(score)한다
2) 매개변수 바꿔가며 score 점수 가장 좋은 모델을 고른다
3) 최적의 매개변수로, 훈련세트+검증세트 합친 걸 다시 훈련(fit)한다
4) 그리고 맨 마지막에 테스트세트로 최종 점수(score)를 평가한다
검증 세트를 활용한 모델 평가
import pandas as pd # 판다스 데이터 불러오기
wine = pd.read_csv('https://bit.ly/wine_csv_data')
# 전과 동일하게 입력/타깃 데이터 설정
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
# 훈련/테스트 세트 분할
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42)
# 한 번 더 훈련/검증(val_) 세트 분할
sub_input, val_input, sub_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42)
print(sub_input.shape, val_input.shape)
->
(4157, 3) (1040, 3)=> 크기 출력을 확인해보면 5197개였던 훈련세트가 한 번 더 쪼개진 것을 확인 가능
- 이후 모델 평가 시
test말고val로 평가
from sklearn.tree import DecisionTreeClassifier
# 결정 트리 모델 만듦
dt = DecisionTreeClassifier(random_state=42)
dt.fit(sub_input, sub_target) # 훈련
print(dt.score(sub_input, sub_target)) # 훈련 세트 평가
print(dt.score(val_input, val_target)) # 검증 세트 평가
->
0.9971133028626413
0.864423076923077검증세트의 문제점
- 보통 많은 데이터 훈련해야 좋은 모델이 됨 하지만 테스트/검증 세트로 떼어내면 훈련할 데이터가 줄어 들음
- 그렇다고 검증 세트를 줄이면 작은 표본으로 평가하기에 신뢰성 떨어짐
-> 이를 해결하기 위해 나온 것이 '교차 검증'
교차 검증
- 훈련 세트에서 검증 세트를 이분할 하는 것이 아니라 훈련 세트를 조각내놓고 그 조각들을 번갈아가면서 검증세트가 되도록 하는 방식
- 여기서 '조각'='폴드', 보통 5-폴드 or 10-폴드 교차검증을 많이 사용
- 결론적으로 데이터의 8-90%까지 훈련가능하고 검증 점수고 모든 폴드 경우의 평균으로 구하기 때문에 신뢰성이 떨어지지 않음
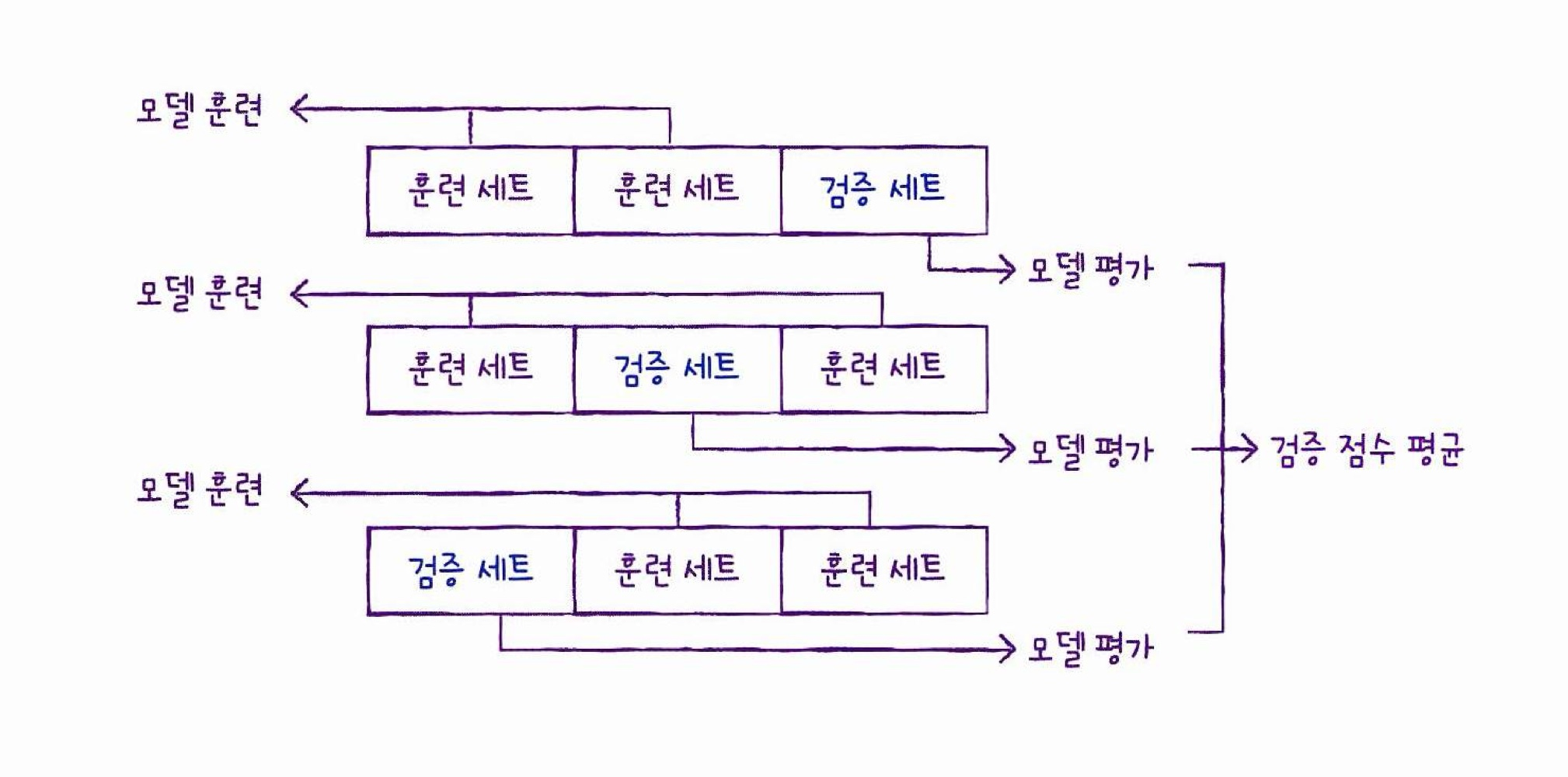
+) k-폴드 교차 검증이라고 함 / 훈련 세트를 몇부분으로 나누야에 따라 다르게 부름
교차 검증을 활용한 모델 평가
cross_validate(): 사이킷런에서 제공하는 교차검증 함수
-> 직접 검증세트를 떼어낼 필요X, 1차로 떼어낸 훈련 세트를 전달하면 알아서 검증 세트 나누고 폴드마다 바꿔가면서 평가해줌cv: 이 매개변수로 폴드 수를 지정 가능(기본값 = 5)
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)
->
{'fit_time': array([0.01341891, 0.02167416, 0.02525187, 0.04882073, 0.03598666]), 'score_time': array([0.0027864 , 0.0019815 , 0.00886154, 0.01437068, 0.02624893]), 'test_score': array([0.86923077, 0.84615385, 0.87680462, 0.84889317, 0.83541867])}- 각 폴드별 검증 점구는 'test_score'에 저장됨, 이 점수들을 평균하면 교차 검증의 최종 점수가 됨
(test라고 적혀 있지만 테스트 세트의 점수가 아님)
import numpy as np
print(np.mean(scores['test_score']))
->
0.855300214703487+) 교차 검증은 train_test_split처럼 알아서 훈련세트를 섞어주지는 않음. 훈련세트를 섞으려면 따로 '분할기'를 지정해줘야 함.
하이퍼파라미터 튜닝
- 모델이 학습하는 변수 = '모델 파라미터'
- 사용자가 지정해주는 변수 = '하이퍼파라미터(=매개변수)'
- 매개변수를 바꿔가면서 score의 점수를 보고 최적의 매개변수를 찾음(검증세트로 해야함)
✌🏻그런데 여기서 짚고 넘어가야 할 포인트가 두 가지 있다.
Point① 그럼 우리가 매개변수 바꿔가면서 일일이 cross_validate 하고 있어야 하나?
Point② 사실, 매개변수들의 최적값은 순차적으로 찾을 수 없게 되어있다. 이를테면, max_depth 최적값 찾아서 고정해놓고 그 다음으로 min_samples_split을 바꿔가면서 찾는 것이 불가능하다. 매개변수 상호 간에 영향을 끼치기 때문이다.
그렇다면,
동시에 매개변수를 바꿔가며 최적의 값을 찾는 이 복잡한 과정을 어찌할 것인가?
그리드 서치
GridSearchCV(): 사이킷런에서 제공하는 하이퍼파라미터 탐색(최적의 매개변수 탐색)과 교차 검증을 한 번에 수행해주는 클래스parms: 딕셔너리 형태로 탐색할 매개변수 후보들을 전달하기 위해 사용한 변수n_jobs: 작업에 사용할 cpu 코어 수를 지정하는 매개변수(기본값 = 1)
-> -1로 지정 시 모든 코어 사용(느려짐)
from sklearn.model_selection import GridSearchCV
# cross_valdate 필요X
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
# 매개변수 이름은 문자열로 입력해야 함
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1) # 그리드 서치 객체 생성
gs.fit(train_input, train_target)
.best_params_: 찾아낸 최적의 매개변수가 저장된 곳.best_estimator_: 최적의 매개변수 조합으로 훈련시킨 최적의 모델이 저장된 곳
dt = gs.best_estimator_
print(dt.score(train_input, train_target))
->
0.9615162593804117print(gs.best_params_)
->
{'min_impurity_decrease': 0.0001}.cv_results_딕셔너리의 'mean_test_score'키에 교차검증의 평균 점수가 저장됨
↪ 그 중에 제일 큰 값의 인덱스를 .argmax()로 꺼내고, 'params' 키를 거쳐서, 최적의 매개변수를 뽑아볼 수도 있음.
print(gs.cv_results_['mean_test_score'])
->
[0.86819297 0.86453617 0.86492226 0.86780891 0.86761605]best_index = np.argmax(gs.cv_results_['mean_test_score'])
print(gs.cv_results_['params'][best_index]) #parms 중 best_index 번째에 있는 값
->
{'min_impurity_decrease': 0.0001}[과정 정리]
- 탐색할 매개변수 지정
- 그다음 훈련 세트에서 그리드 서치를 수행하여 최상의 평균 검증 점수가 나오는 매개변수 조합을 찾음 -> 이 조합은 그리드 객체에 저장
- 그리드 서치는 최상의 매개변수에서 (교차 검증에 사용한 훈련 세트가 아니라) 전체 훈련 세트를 사용해 최종 모델을 훈련함 -> 이 모델도 그리드 서치 객체에 저장
좀 더 복잡한 매개변수 조합
- 넘파이의
np.arange()함수와 파이썬의range()함수를 활용
# arange와 range로 여러 개 한 번에 지정해 놓고 교차 검증
params = {'min_impurity_decrease': np.arange(0.0001, 0.001, 0.0001),
'max_depth': range(5, 20, 1),
'min_samples_split': range(2, 100, 10)
}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1) # 객체 생성
gs.fit(train_input, train_target) # 훈련- 그리드 서치가 최적의 매개변수 조합과 검증 점수를 구함
print(gs.best_params_) # 최상의 매개변수들 확인 가능
# 개별이 아니라 이 조합으로 사용해야 함
->
{'max_depth': 14, 'min_impurity_decrease': 0.0004, 'min_samples_split': 12}print(np.max(gs.cv_results_['mean_test_score']))
# 최상의 조합을 썼을 때 검증 점수 확인
->
0.8683865773302731✌🏻그런데, 여기서 또 한 번 아쉬운 점이 두 가지 있다.
Point① 위에서 매개변수 후보 간격들을 0.001, 1, 10으로 했었는데, 굳이 이렇게 간격을 둔 것에 대한 특별한 근거가 없다.
Point② 또, 너무 많은 매개변수 조합이 있어서 그리드서치 수행 시간이 오래 걸릴 수 있다. (위 예시는 무려 91510*5=6,750 가지나 있었다)
랜덤 서치
RandomizedSearchCV(): 매개변수의 범위나 간격을 미리 정하기 어려우니, 그냥 넓은 범위를 던져주고 "이 안에서 랜덤하게 매개변수들 뽑아서 해보고, 최적인 걸 찾아줘!"
+) 사이파이 라이브러리의 uniform과 randint 클래스를 활용하면 됨
from scipy.stats import uniform, randint
# 그리드 서치랑 똑같지만 range대신 난수발생기를 사용(randint)
params = {'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25),
}- 대부분의 구성은 그리드 서치와 동일 하지만
n_iter로 샘플링 횟수 지정해줘야 함
# 랜덤서치 객체 생성 및 훈련
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params,
n_iter=100, n_jobs=-1, random_state=42)
# 매개변수 후보 몇개 뽑을 건지 지정!
gs.fit(train_input, train_target)- 그리드 서치보다 더 넓은 영역을 무작위로 탐색하면서 교차검증 수를 줄임
(최적의 매개변수 조합과 검증 점수도 그리드 서치와 동일하게 계산)
print(gs.best_params_) # 최적의 매개변수 저장
->
{'max_depth': 39, 'min_impurity_decrease': 0.00034102546602601173, 'min_samples_leaf': 7, 'min_samples_split': 13}print(np.max(gs.cv_results_['mean_test_score'])) #최적의 매개변수들로 구한 검증세트 점수
->
0.8695428296438884- 검증세트로 필요한 검즌 다 하고 나면, 마지막에 한 번만 테스트 세트 확인
dt = gs.best_estimator_
print(dt.score(test_input, test_target))
->
0.86와인 구분하는 결정트리 모델 만들었지만, '테스트 세트에만 맞춰진 거 아니냐'는 이사님의 일침 → 검증 세트 추가 → but 검증세트까지 떼어내는 부담 있음 → 교차검증으로 극복! → 근데 매개변수를 바꿔가면서 평가하는 과정이 지루하고 복잡해짐ㅠ → 그 과정을 자동화한 그리드서치 활용! → but 간격 설정에 관한 한계가 있고, 시간이 오래 걸림 → 넓은 범위 속을 무작위로 탐색하여 효율적인 랜덤서치로 극복!
05-3 트리의 앙상블
[키워드]
앙상블 학습
: 더 좋은 예측 결과를 만들기 위해 여러 개의 모델을 훈련하는 머신러닝 알고리즘
랜덤 포레스트
: 대표적인 결정 트리 기반의 앙상블 학습법
- 부트스트랩 샘플을 사용하고 일부 특성을 선택하여 트리를 만드는 것이 특징
엑스트라 트리
: 랜덤 포레스트와 비슷하게 결정 트리를 사용하여 앙상블 모델을 만들지만 부트스트랩 샘플을 사용하지 않음
- 랜덤하게 노드를 분할해 과대적합을 감소시킴
그레디언트 부스팅
: 랜덤 포레스트나 엑스트라 트리와 달리 결정 트리를 연속적으로 추가하여 손실함수를 최소화 하는 앙상블 방법
- 훈련 속도가 조금 느리지만 더 좋은 성능을 기대할 수 있음
- 그래디언트 부스팅 속도를 개선한 것 -> 히스토그램 기반 그레디언트 부스팅 => 안정적인 결과와 높은 성능으로 인기 좋음
정형 데이터와 비정형 데이터
- 정형 데이터: csv나 database 혹은 excel처럼 어떤 구조로 가지런히 정리되어있는 데이터, 주로 머신러닝 알고리즘을 통해 다룸
- 비정형 데이터: 텍스트, 사진, 음악 등 database나 excel로 표현하기 어려운 데이터, 주로 딥러닝(신경망) 알고리즘을 통해 다룸
앙상블 학습
- 정형 데이터를 다루는 데 가장 뛰어난 성과를 내는 알고리즘으로, 여러 개의 모델을 합쳐서 더 좋은 결과를 도출함
- 주로 결정 트리를 기반으로 만들어져 있음
랜덤 포레스트
- 앙상블 학습의 대표, 랜덤한 결정트리의 '숲'이라고 봄
랜덤포레스트의 기본 원리
: Ⓐ+Ⓑ로 개별 트리에 무작위성을 부여해서 트리의 성능이 너무 강력해지는 것을 막음 (=과대적합 방지) → 물론 개별트리의 성능은 떨어짐 but 그걸 여러 개 묶어서 일반화하면 높은 성능이 나오게 됨!
Ⓐ 훈련세트에 무작위성 주입
- 랜덤포레스트 속의 각 트리는 우리가 입력한 훈련데이터를 그대로 학습하지 않고, 훈련세트와 같은 크기의 부트스트랩 샘플(=중복을 허용한 추출)을 만들어 학습
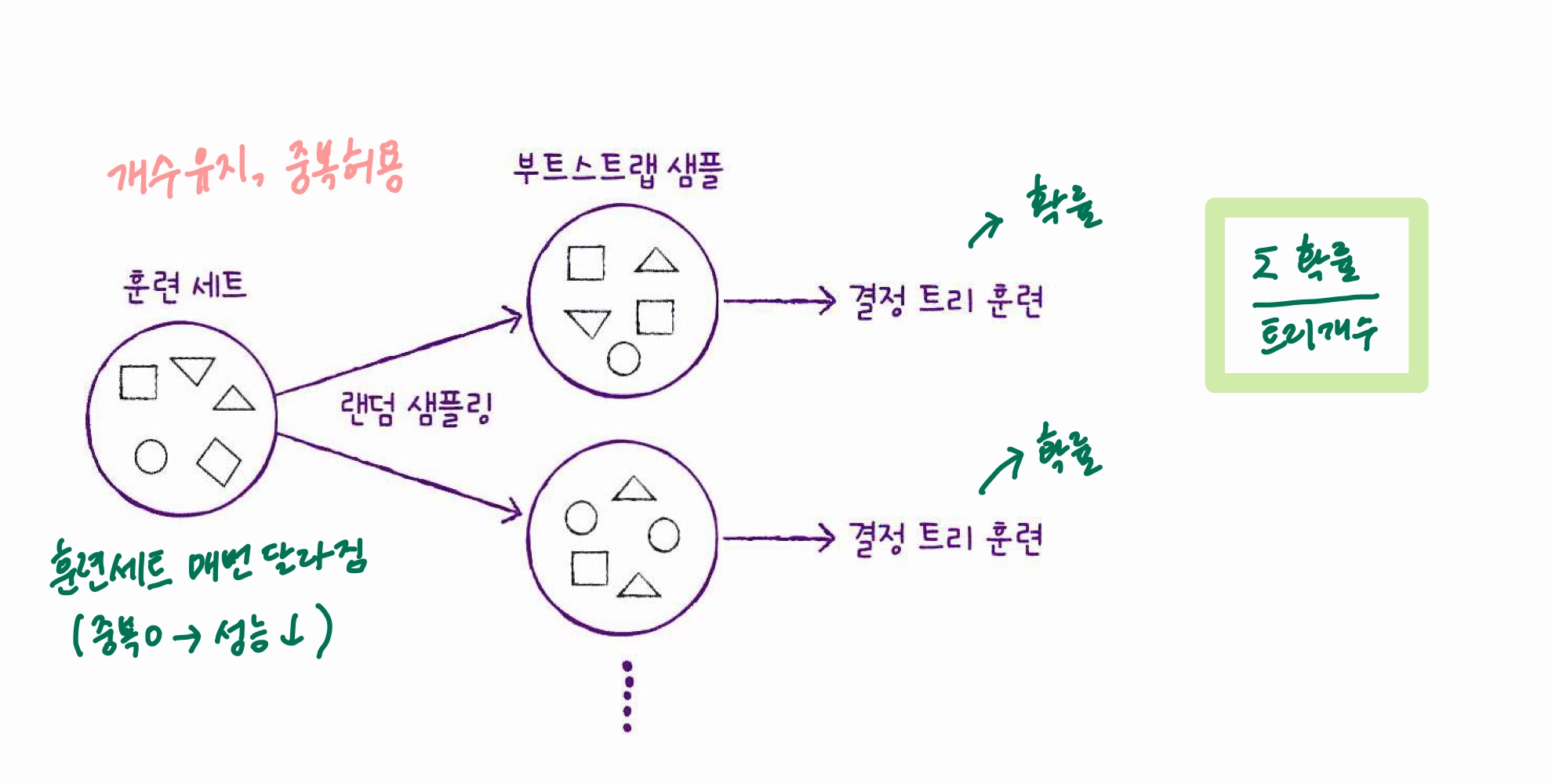

Ⓑ 특성 선택에 무작위성 주입
- 노드를 분할할 때도(트리를 성장시킬 때도) 모든 특성을 다 써서 최선의 분할을 하는 게 아니라,√특성개수 개의 특성만 써서(일부러 특성 개수 줄여서) 분할
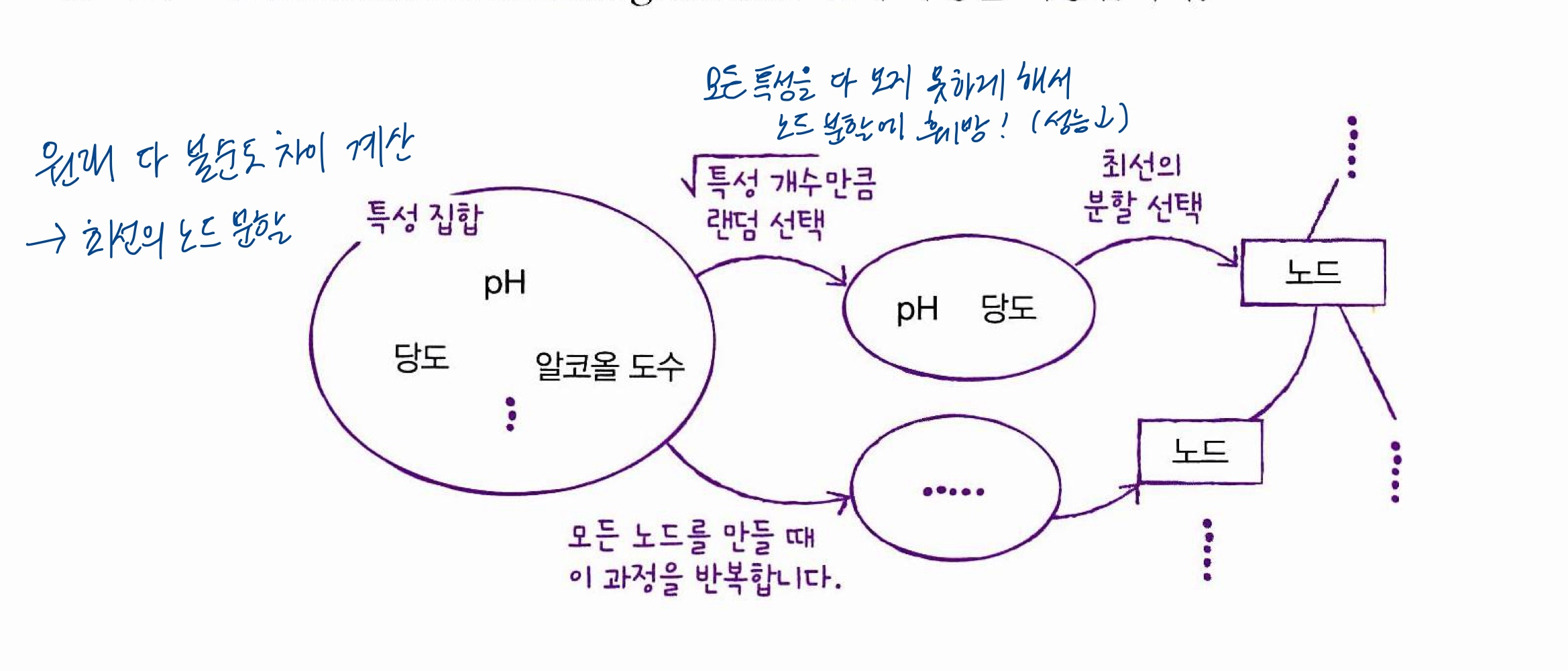
➡️ Ⓐ+Ⓑ의 방식으로 100개(기본값)의 결정트리를 훈련하고, (분류문제인 경우) 각 트리의 클래스별 확률을 평균하여 가장 높은 확률의 클래스를 예측클래스로!
cf. (회귀문제인 경우) '확률' 대신 '예측값(임의의 수치)'을 평균하면 됨!
실습
데이터 준비
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
# 판다스로 불러오기
wine = pd.read_csv('https://bit.ly/wine_csv_data')
#입력/타깃 설정
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
#훈련/테스트 세트 분할
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)모델 훈련과 교차 검증
RandomForestClassifier(): 사이킷런의 ensemble 패키지에 있음return_train_score: 훈련세트의 점수도 반환하도록 하는 설정 (for 과대적합 파악)
from sklearn.model_selection import cross_validate # 교차 검증
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
# 훈련세트 점수 / 검증세트 점수 출력
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
->
0.9973541965122431 0.8905151032797809=> 결정 트리 1개 썼을 때 보다 더 나은 점수가 나옴
(과대적합 약간 있지만, 일단 이 상태가 만족스럽다고 가정하고 그냥 최종모델이라 치고 다음 단계로)
특성 중요도 확인
- 각 결정트리의
feature_importances_취합 → 랜덤포레스트의feature_importances_
➡️ 특성 선택에 무작위성을 넣었기 때문에, 단일 결정트리보다 골고루 나옴
rf.fit(train_input, train_target)
print(rf.feature_importances_) # 특성 중요도 출력
->
[0.23167441 0.50039841 0.26792718]엑스트라 트리
- 개별 트리 성능을 억제하지만 많은 트리를 앙상블해서 과대적합 문제와 점수를 동시에 챙기는 기본적인 논리는 랜덤포레스트와 매우 비슷하지만 Ⓐ 대신 Ⓒ를 활용
Ⓑ 특성 선택에 무작위성 주입
- 랜덤 포레스트와 동일
Ⓒ 노드 분할에 무작위성 주입
- 랜덤 포레스트가 '부트스트랩 샘플(Ⓐ)'을 사용했던 것과 달리, 엑스트라 트리는 우리가 입력한 훈련세트 전체를 그대로 사용
- 대신, 노드를 분할할 때 최선의 분할(불순도 차이가 가장 큰 분할)을 찾는 게 아니라 그냥 무작위로 분할(랜덤하게 분할한 후보들 중에 그나마 불순도 차이 큰 걸로)
- 269p, 262p 참고!
❗ 분할 자체를 무작위로 하다보니 랜덤 포레스트보다 무작위성이 더 크다. 그래서 랜덤포레스트보다는 트리 개수를 더 많이 해야 좋은 성능을 낸다고 알려져있다. 하지만
더 큰 무작위성 때문에 계산속도는 상대적으로 더 빨라진다는 장점도 있다.
실습
데이터 준비
- 앞과 동일
모델 훈련과 교차 검증
ExtraTreesClassifier(): 역시 ensemble 패키지에 있음
from sklearn.ensemble import ExtraTreesClassifier
#엑스트라 트리로 교차검증
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target, return_train_score=True, n_jobs=-1)
#훈련 세트 점수 / 검증 세트 점수
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
->
0.9974503966084433 0.8887848893166506특성 중요도 확인
- 마찬가지로
feature_importances_제공하고, 마찬가지로 비교적 골고루 나옴
(= 단일 결정트리보다 'sugar(당도)' 특성에 대한 의존성 ↓)
et.fit(train_input, train_target)
print(et.feature_importances_)
->
[0.20183568 0.52242907 0.27573525]그레디언트 부스팅(GB)
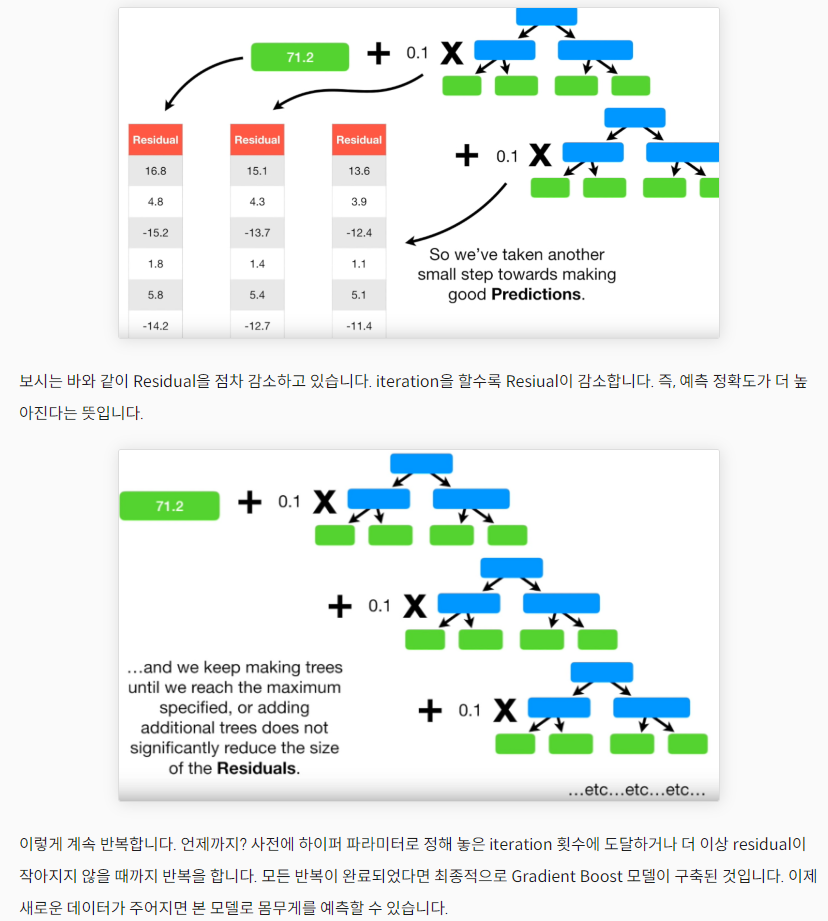
- 깊이가 얕은 결정 트리를 사용하여 이전 트리의 오차를 보완하는 방식의 앙상블 학습
(기본값=3 / 깊이가 얕으니까 역시 과대적합을 방지할 수 있음.) - 'Gradient'에서 유추할 수 있듯, 경사 하강법을 사용해 트리를 추가하는 거임!
(분류 : 로지스틱 손실함수✔️ / 회귀 : 평균제곱오차 함수)
이전 트리의 손실을 보완하는 방향으로 트리 추가
❗ 경사하강법에서 손실함수의 낮은 곳을 찾아 조금씩 이동했던 것처럼❗
- 깊이가 얕은 트리를 사용해서 트리의 성능이 강력해지는 것을 막음 (=과대적합 방지)
→ 물론 처음에 score 구해보면 성능이 많이 높지 않음
→but 그건 트리 개수 점점 더 넣으면서 높이면 됨! (결정트리 개수 늘려도 과대적합에 강하다는 장점) - 조금씩 이동하도록 학습률도 조절함 by learning_rate (기본값=0.1)
실습
데이터 준비
- 앞과 동일
모델 훈련 & 교차검증
GradientBoostClassifier(): ensemble 패키지에 있음
-> 과대적합이 거의 없음, 성능이 좀 낮음 -> 트리 더 넣어서 높이면 됨
from sklearn.ensemble import GradientBoostingClassifier
#그레디언트 부스팅으로 교차 검증
gb = GradientBoostingClassifier(random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
#훈련세트 점수 / 검증세트 점수
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
->
0.8881086892152563 0.8720430147331015n_estimators: 추가할 트리 개수 설정learning_rate: 학습률 설정
# 트리 개수 늘리고 학습률도 약간 높임
gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.2, random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
# 트리 개수를 5배 늘림 -> 검증 세트 점수는 크게 변화 x (과대적합 억제)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
->
0.9464595437171814 0.8780082549788999특성 중요도 확인
- 랜덤 포레스트에 비해 덜 골고루 나옴(일부 특성에 더 집중함)
gb.fit(train_input, train_target)
print(gb.feature_importances_)
->
[0.15887763 0.6799705 0.16115187]보통 GB가 랜덤 포레스트(RF)보다 좀 더 높은 성능을 내지만, 트리를 하나하나 추가하기 때문에 훈련속도가 느리다는 단점 존재
-> 이걸 개선한 것이 '히스토그램 기반 GB'
히스토그램 기반 GB
-
정형 데이터를 다루는 머신러닝 알고리즘 중 가장 인기가 높음
-
기본 매개변수에서도 안정적인 성능을 얻을 수 있을 정도로 괜찮은 모델
-
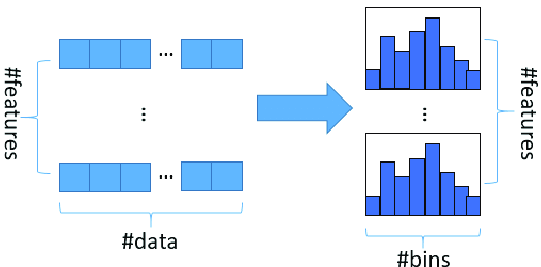
노드를 분할하기 전에, 훈련데이터를 256개의 구간으로 쪼갬
→ 특성의 범위가 짧게 끊어져있으니 최적의 분할을 매우 빠르게 찾을 수 있음
-
또한, 256(255+1)개 중에서 1개는 누락된 데이터를 위한 구간으로 할당함 → 훈련 데이터에 누락된 특성이 있더라도 이를 222p처럼 따로 전처리할 필요 없음
실습
데이터 준비
- 앞에와 동일
모델 훈련 & 교차검증
HistGradientBoostClassifier(): ensemble 패키지에 있음- 추가 트리 개수 설정 시
max_iter사용
from sklearn.ensemble import HistGradientBoostingClassifier
# 히스토그램 기반 GB로 교차 검증
hgb = HistGradientBoostingClassifier(random_state=42) # 기본 설정으로 해도 충분히 good
scores = cross_validate(hgb, train_input, train_target, return_train_score=True, n_jobs=-1)
# 훈련세트 점수 / 검증세트 점수
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
->
0.9321723946453317 0.8801241948619236=> 과대적합도 잘 억제, (기본 설정인데도) 그냥 GB보다 더 높은 성능
특성 중요도 확인
-
permutation_importance()함수를 사용 -
특성을 하나씩 랜덤하게 섞으면서 모델의 성능 변화를 관찰 (n_repeats로 섞을 횟수 지정 가능) → 많이 변할수록 중요한 특성으로, 별로 안 변할수록 중요하지 않은 특성으로 계산
-
반환된 객체에는 importances (계산한 개별 특성중요도 모두), importances_mean(그걸 평균 낸 최종 특성중요도), importances_std(특성중요도들 간 표준편차) 가 담겨 있음
from sklearn.inspection import permutation_importance
# HGB 모델 훈련 먼저
hgb.fit(train_input, train_target)
result = permutation_importance(hgb, train_input, train_target, n_repeats=10,
random_state=42, n_jobs=-1)
print(result.importances_mean) # 특성 중요도 계산
->
[0.08876275 0.23438522 0.08027708]- 이 함수는 훈련 세트뿐만 아니라 테스트 세트에서도 특성 중요도 계산 가능
result = permutation_importance(hgb, test_input, test_target, n_repeats=10,
random_state=42, n_jobs=-1)
print(result.importances_mean)
->
[0.05969231 0.20238462 0.049]'pH'는 실전에서 의미없는 특성일 것으로 예상
최종 성능 확인
- 이 모델을 최종모델로 하여, 테스트세트에서의 성능을 최종 확인해보면
단일 결정트리(86%였음)보다 좋은 결과를 얻을 수 있음
hgb.score(test_input, test_target)
->
0.8723076923076923그 외 라이브러리
- 많은 라이브러리에서 그레이디언트 부스팅 알고리즘을 구현하고 있음
XGBoost
- 다양한 부스팅 알고리즘을 지원하는 라이브러리 (오픈소스/코랩o)
- Kaggle에서 많이 사용하면서 유명해짐
from xgboost import XGBClassifier
#이렇게 설정하면 '히스토그램 기반'
xgb = XGBClassifier(tree_method='hist', random_state=42)
scores = cross_validate(xgb, train_input, train_target, return_train_score=True, n_jobs=-1)
# 사이킷런의 cross_validate도 함께 사용 가능
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
->
0.9558403027491312 0.8782000074035686LightGBM
- 마이크로소프트에서 만든, 그레디언트 부스팅 전용 라이브러리 (오픈소스/코랩o)
- 히스토그램 기반 GB를 지원해서 인기가 높아짐
from lightgbm import LGBMClassifier
# LightGBM을 임포트
lgb = LGBMClassifier(random_state=42)
scores = cross_validate(lgb, train_input, train_target, return_train_score=True, n_jobs=-1)
# 교차검증 -> 사이킷런 부스팅 알고리즘의 결과와 거의 비슷
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
->
0.935828414851749 0.8801251203079884