앞서서 선형분리 가능한 문제에 대한 SVM을 배웠고,
선형분리 불가능한 문제에 대한 SVM Soft margin을 배웠다.
그러나 soft margin은 어느정도 선형분리 가능한 꼴 에서 몇 개의 데이터를 허용해주는 정도이기 때문에, 모든 선형분리 불가능한 문제에는 적용할 수 없다.
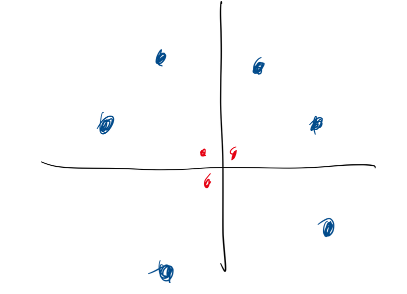
예를들어 다음과 같은 데이터가 있다.
다음과 같은 데이터는 선형분리가 불가능하다. Soft Margin을 사용하더라도 분류할 수 없다.
이러한 비선형 데이터에 대해서는 어떻게 접근해야 할 것인가?
다음과 같은 방법이 있다.
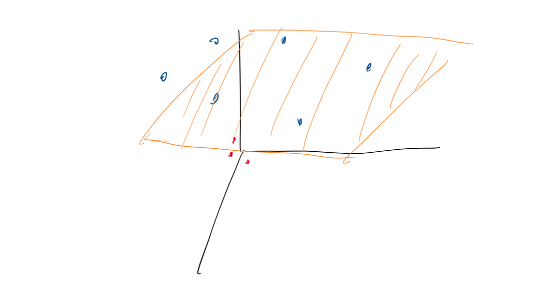
위 그림의 2차원 데이터를 3차원으로 변경하는 것이다.
기존의 데이터가 x=[x1x2]였다면, 여기서 x_3에 대한 것을 임의로 추가시켜 (x3=x12+x22)
x=⎣⎢⎡x1x2x12+x22⎦⎥⎤ 와 같은 3차원 데이터로 만든다면 그림이 다음과 같이 그려진다.
그리고 데이터를 다음과 같이 노란색 초평면으로 선형분리 할 수 있게 된다.
여기서 우리가 알 수 있는 것은
선형분리 불가능한 문제를 해결하는 방법은 차원을 증가시키면 된다는 것이다.
이 과정을 다음과 같은 식으로 쓸 수 있다.
Φ(x)=Φ((x1,x2,⋯,xd)⊺)=(ϕ1(x),ϕ2(x),⋯,ϕq(x))⊺
d 차원의 data를 변환함수 Φ에 넣으면, q차원의 data로 변한다.
근데 여기서 어려운 점은 차원을 증가시키는건 알겠는데, 어떤 변환을 통해서 차원을 증가시켜야 하는지에 대한 문제다. 위 그림에서는 (x3=x12+x22) 을 통해서 차원을 증가시켰지만, 다른 방법 예를들어 x3=x1과 같은 방법으로 변환시킨다면 선형분리시킬 수 없다.
그럼 이 상황을 어떻게 해결할 수 있을까?
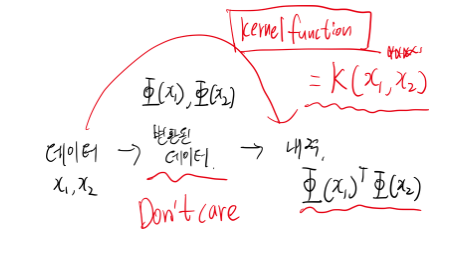
이 상황을 해결하기 위해서 만들어진 것이 커널 트릭이다.
커널 함수의 정의부터 살펴보자
원래 특징 공간 L에서 정의된 두 특징 벡터 x 와 z 에 대해 K(x,z)=Φ(x)⋅Φ(z) 인 변환함수 Φ가 존재하면 K(x,z)를 커널함수라고 부른다.
다음 상황을 보자.
특징 공간 L 에 있는[x]를 다음과 같이 변환시키는 함수를 생각해보자.
Φ([x])=⎣⎢⎡x22x1⎦⎥⎤
이렇게 되면 특징 공간에 있는 데이터 α=[x1],β=[x2] 가 다음과 같이 변화한다.
이 식을 이제 잘 풀기만 하면 된다. n이 작은 경우에는 우리가 해석적으로 풀 수 있지만, n이 커지는 경우에는 우리가 알고리즘으로 풀어야한다.
이러한 알고리즘에는 여러가지 종류가 있다.
SMO 알고리즘, plane cutting 알고리즘, coordinate descent알고리즘 등이 있다. 이러한 알고리즘에 대해서는 나중에 다시 다뤄보겠다.
만약 알고리즘을 통해서 라그랑주 승수를 다 구했다고 가정해보자.(학습이 끝났을 때)
그러면 새로운 샘플 x가 들어왔을 때 x의 레이블을 예측해야한다.
이에 대해서 알아보자.
SVM-PREDICTION
선형분리한 경우에 대해서 생각해보자
선형 분리 가능한 경우:
선형 SVM 예측: 새로운 샘플 x에 대하여 d(x)>0 이면 1, 그렇지 않으면 -1으로 분류. d(x)=w⊺x+b
우리는 알고리즘을 통해 라그랑주 승수를 구했으므로
∂w∂L=0⇒w=i=1∑nαiyixi를 통해서 가중치를 구할 수 있다.
여기서 αi=0인 것들은 제외할 수 있다. 왜냐하면 곱하더라도 0이기 때문이다.
즉 서포트 벡터에 해당하는 값들을 통해서 w를 구하겠다는 것이다.
그러면 식이 다음과 같이 바뀐다.
∂w∂L=0⇒w=i=1∑nαiyixi=ak=0∑αiyixi
이 식을 통해 가중치를 구한 후에
αi(yi(w⊺xi+b)−1+ξi)=0
에 대입해서 b(bias)를 구할 수 있다. 하나의 서포트 벡터만 대입해서 구해도 이론적으로는 괜찮지만,
수치적 정확도를 위해서 모든 서포트 벡터를 대입한 다음 평균을 취한다.
(왜냐하면 알고리즘으로 구하는 값은 근사값일 수 밖에 없으므로)
이렇게 우리가 x,b에 대해서 알게 되었으면,
새로운 샘플 x가 들어왔을 때 d(x)에 대입하고 부호를 통해서 분류하면 된다.
선형 분리 불가능한 경우:
비선형 SVM 예측: 새로운 샘플 x에 대하여 d(x)>0 이면 1, 그렇지 않으면 -1으로 분류. d(x)=ak=0∑αiyiK(xkx)+b
비선형 문제인 경우에는 내적 계산을 사용하므로 상황이 달라진다. 비선형 공간에서는 학습과정에서 공간을 변환시켰으므로, 예측할 때도 공간을 변환시켜야한다. 왜냐하면 우리가 구한 함수는 변환된 공간에서의 함수이기 때문에, 새로운 샘플을 이 함수에 대입시키기 위해서는 이 샘플의 차원 또한 변환시켜야한다.
그러나 우리는 매핑 함수를 모른다. 우리는 변환된 공간에서의 내적값을 이용하는 (Kernel Trick)을 사용했다. 그러니 우리는 예측할 때도 Kernel Trick을 사용해서 내적으로 예측값을 구해야한다. 즉 내적의 형태가 나오도록 유도해야한다.
d(x)=w⊺Φ(x)+b
(데이터에 대해서 공간변화) w=ak=0∑αkykΦ(xk) 이므로 대입하면 d(w)=(ak=0∑αkykΦ(xk))⊺Φ(x)+b
이다. 다행히 내적의 형태로 표현할 수 있다.
d(w)=ak=0∑αkykΦ(xk)⊺Φ(x)+b
이므로 커널 함수를 적용하면, d(w)=ak=0∑αkykK(xk,x)+b 로 표현할 수 있다.
여기서 주목할 점은 우리가 K(xk,x) 를 미리 계산할 수 없다는 것이다.
새로운 샘플 x가 들어오면 그때 이 함수를 계산할 수 있다.
즉 새로운 샘플이 들어오기 전까지는 xk들을 저장해 두어야 한다. 하지만 다행인 점은
서포트벡터만 저장해도 된다는 것이다. ak=0 인 데이터들로만 가중치를 계산하기 때문이다.
즉 비선형 SVM은 메모리 기반 방법이다. 메모리에 데이터들을 저장해두고 예측해야한다.
따라서 서포트 벡터가 많아질 수록 모델의 크기도 커지고 예측시간도 길어진다.