2020-12-14 Topic!
Java bytecode
https://hoonmaro.tistory.com/19
Java Byte 코드를 알기전에!
JVM(Java Virtual Machine)
write once, run everywhere, 하나의 Java 파일이 모든 OS에서 실행되어야 한다.
즉, JVM만 각 OS에 설치되어 있다면 HW 기종에 상관없이 단 한번만 컴파일하면 된다.
이를 '플랫폼에 독립적'이라고 한다. 간단히 말해 JVM은 Java 클래스 파일을 로드하고,
바이트 코드를 해석하며, 메모리 등의 자원을 할당하고 관리하며 정보를 처리하는 작업을 하는 프로그램이다. OS는 JVM을 실행하고, JVM은 Java프로그램을 실행한다.
Java 컴파일러는 .java파일을 .class라는 Java Byte code로 변환시켜준다.
Byte code는 기계어가 아니기 때문에 OS에서 바로 실행되지 않는다. 이때 JVM은 OS가 byte code를 이해할 수 있도록 해석해준다. 하지만 JVM의 해석을 거치기 때문에 C언어와 같은 네이티브 언어에 비해 속도가 느렸지만 JIT(Just In Time)컴파일러를 구현해 이 점을 극복했다. Byte code는 JVM 위에서 OS에 상관없이 실행된다. 이런 점이 Java의 가장 큰 장점이라고 할 수 있다. OS에 종속적이지 않고 Java 파일 하나만 만들면 어느 디바이스든 JVM 위에서 실행할 수 있다.
JVM의 구성 요소
- 가비지 컬렉터 (Garbage Collector)
가비지 컬렉터를 이용하면 사용하지 않은 메모리를 자동으로 회수해준다.
메모리 관리를 알아서 해주니 개발자는 더욱 손쉽게 프로그래밍을 할 수 있게 도와준다.
- 클래스 로더 (Class Loader)
자바는 동적으로 클래스를 읽어오므로, 프로그램이 실행중인 런타임에서야 모든 코드가 자바 가상머신과 연결된다. 이렇게 동적으로 클래스를 로딩해주는 것이 클래스 로더이다.
- 실행 엔진 (Execution Engine) > Java 인터프리터 / JIT 컴파일러
Class Loader에 의해 JVM으로 Load된 Class 파일(바이트코드)들은 Runtime Data Areas의 Method Area에 배치되는데, JVM은 Method Area의 바이트 코드를 Execution Engine에 제공하여, Class에 정의된 내용대로 바이트 코드를 실행시킨다. 이 때, Load 된 바이트코드를 실행하는 Runtime Module이 Execution Engine(실행 엔진) 이다.
Execution Engine의 실행 방식
- 실행 엔진은 바이트코드를 명령어 단위로 읽어서 실행하는데, 두 가지 방식을 혼합하여 사용한다.
- Interpreter 방식
바이트코드를 한 줄씩 해석, 실행하는 방식이다. 초기 방식으로, 속도가 느리다는 단점이 있다.
- JIT(Just In Time) 컴파일 방식 또는 동적 번역(Dynamic Translation)
Interpreter 방식의 단점을 보안하기 위해 나온 것이 JIT(Just In Time) 컴파일 방식이다. 바이트코드를 JIT 컴파일러를 이용해 프로그램을 실제 실행하는 시점(바이트코드를 실행하는 시점)에 각 OS에 맞는 Native Code로 변환하여 실행 속도를 개선하였다. 하지만, 바이트코드를 Native Code로 변환하는 데에도 비용이 소요되므로, JVM은 모든 코드를 JIT 컴파일러 방식으로 실행하지 않고, 인터프리터 방식을 사용하다 일정 기준이 넘어가면 JIT 컴파일 방식으로 명령어를 실행한다.
또한, JIT 컴파일러는 같은 코드를 매번 해석하지 않고, 실행할 때 컴파일을 하면서 해당 코드를 캐싱해버린다. 이후에는 바뀐 부분만 컴파일하고, 나머지는 캐싱된 코드를 사용한다.
JIT (Just In Time) Compiler
Interpreter 방식의 단점을 보완하기 위해 도입된 방식으로, Interpreter 방식으로 실행하다가 적절한 시점에 Byte code 전체를 컴파일하여 네이티브 코드로 변경하고, 더 이상 Interpreting 하지 않고 네이티브 코드로 직접 실행하는 방식이다. 네이티브 코드는 캐시에 보관되기 때문에 한 번 컴파일된 코드는 빠르게 실행할 수 있다. 물론 한 번만 실행되는 코드라면 JIT보다 Interpreter 방식이 유리하다. 따라서 JVM은 해당 메소드가 얼마나 자주 수행되는지 체크하고, 일정 정도를 넘을때 컴파일을 수행한다.
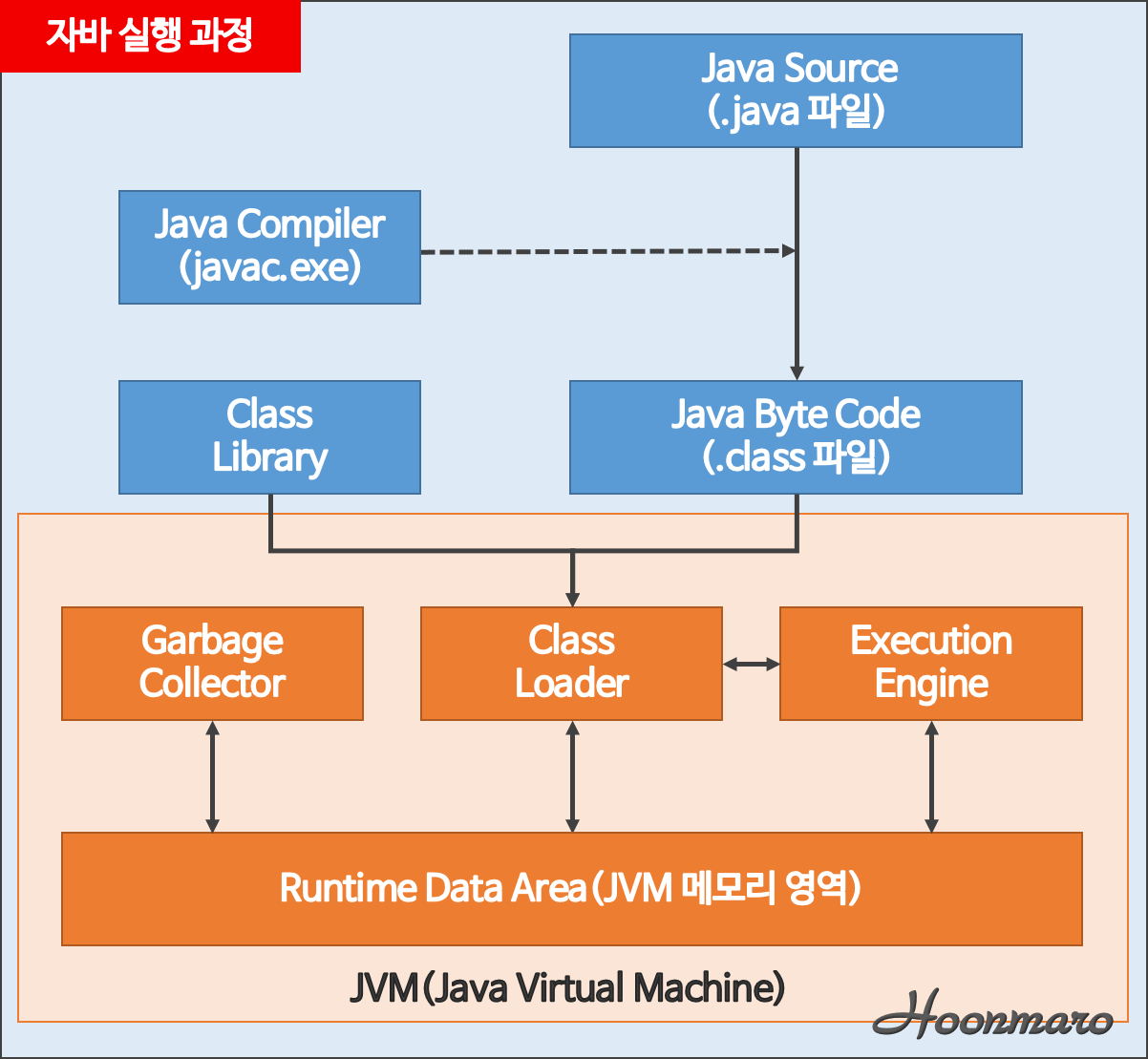
JVM 실행 과정
-
프로그램이 실행되면 JVM은 OS로부터 이 프로그램이 필요로 하는 메모리를 할당 받는다. JVM은 이 메모리를 용도에 따라 여러 영역으로 나누어 관리한다.
-
자바 컴파일러(javac)가 자바소스(.java)코드를 읽어 들여 자바 바이트코드(.class)로 변환시킨다.
-
이 변경된 Class 파일들을 Class Loader를 통해 JVM 메모리영역(Runtime Data Areas) 영역으로 로딩한다.
-
로딩된 class파일들은 Execution engine을 통해 해석된다.
-
해석된 바이트코드는 Runtime Data Areas에 배치되어 실질적인 수행이 이루어지게된다.
이러한 실행과정속에서 JVM은 필요에 따라 Thread Synchronization과 GC같은 관리 작업을 수행한다
Java bytecode 의 개념
자바 가상 머신이 이해할 수 있는 언어로 변환된 자바 소스 코드를 의미한다.
자바 컴파일러에 의해 변환되는 코드의 명령어 크기가 1바이트라서 자바 바이트 코드라고 불리고 있다.
이러한 자바 바이트 코드의 확장자는 .class이다.
자바 바이트 코드는 자바 가상 머신만 설치되어있으면, 어떤 운영체제에서라도 실행될 수 있다.
Java bytecode 의 형태 살펴보기
자바코드를 바이트코드로 변환
public class Hello {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
System.out.println(i);
}
}
}위 자바 코드를 자바 컴파일러를 통해 아래와 같은 바이트코드로 번역한다.
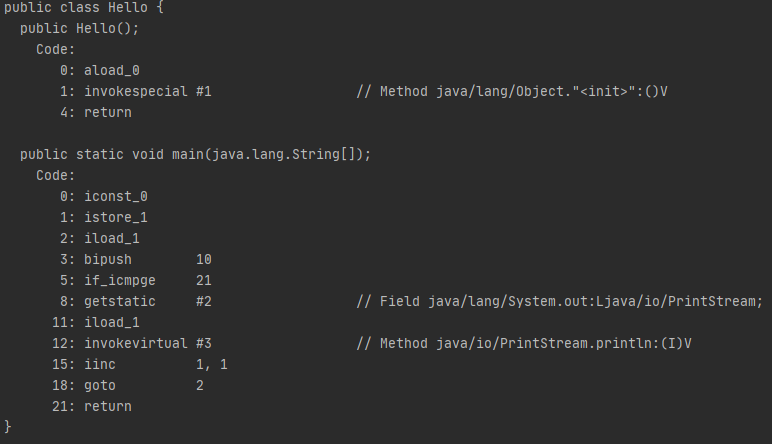
for (int i = 2; i < 1000; i++) {
for (int j = 2; j < i; j++) {
if (i % j == 0)
continue outer;
}
System.out.println (i);
}위 자바 코드를 자바 컴파일러를 통해 아래와 같은 바이트코드로 번역한다.
0: iconst_2
1: istore_1
2: iload_1
3: sipush 1000
6: if_icmpge 44
9: iconst_2
10: istore_2
11: iload_2
12: iload_1
13: if_icmpge 31
16: iload_1
17: iload_2
18: irem
19: ifne 25
22: goto 38
25: iinc 2, 1
28: goto 11
31: getstatic #84; // Field java/lang/System.out:Ljava/io/PrintStream;
34: iload_1
35: invokevirtual #85; // Method java/io/PrintStream.println:(I)V
38: iinc 1, 1
41: goto 2
44: return위와 같은 명령어로 변환되어, 보다 기계가 이해하기 쉬운 코드가 되는 것입니다.

바이트코드 명령어(opcode)
한 바이트에는 256개의 값이 있듯이 바이트코드에는 256개가량의 opcode들이 존재합니다.
각각의 명령어들은 넓게 다음과 같이 분류할 수 있습니다.
- 읽고 쓰기 (e.g. aload_0, istore)
- 산술논리 연산 (e.g. ladd, fcmpl)
- 타입변환 (e.g. i2b, d2i)
- 객체생성 및 조작 (new, putfield)
- 오퍼랜드 스택 관리 (e.g. swap, dup2)
- 제어 (e.g. ifeq, goto)
- 함수 호출 및 반환 (e.g. invokespecial, areturn)
많은 명령어는 피연산자(operand)의 타입을 나타내는 접두사(prefix) 또는 접미사(suffix)를 가지고 있습니다. 아래는 각 접두사/접미사가 나타내는 피연산자 타입입니다.
접두사/접미사 피연산자 타입
- i integer
- l long
- s short
- b byte
- c character
- f float
- d double
- a reference
바이트코드 시작하기
바이트코드는 다음과 같은 형식을 가집니다.
<index><opcode> [<operand1> [<operand2>...]] [<comment>]Decompile 의 원리
바이트 코드 (.class 파일)을 다시 원래 소스인 자바(Java) 형식으로 바꿔주는 것을 Decompile이라 한다.
(decompile을 사용한 경험은 class 파일 밖에 없을 때, java 소스 파일해석을 위해 jd-gui를 사용함)
특히 코드 난독화 (Code Obfuscation)이 이루어지지 않은 클래스(Class) 파일의 경우에는 사실상 거의 특정한 어플리케이션을 그대로 복원할 수 있다.
코드 난독화
코드 난독화는 프로그램을 변화하는 방법의 일종으로, 코드를 읽기 어렵게 만들어 역공학을 통한 공격을 막는 기술을 의미한다.
난독화는 난독화의 대상에 따라 아래와 같이 나눌 수 있다.
1) 소스 코드 난독화
2) 바이너리 난독화
소스 코드 난독화는 C/C++/자바 등의 프로그램의 소스 코드를 알아보기 힘든 형태로 바꾸는 기술이고, 바이너리 난독화는 컴파일 후에 생성된 바이너리를 역공학을 통해 분석하기 힘들게 변조하는 기술이다.
디컴파일 단계
- 로더
입력된 기계어나 중간 언어 프로그램의 바이너리 형식을 로드하고 분석
- 디스어셈블리
기계어 명령어들의 디스어셈블리를 기계와 독립적인 중간 표현 형식 (IR: intermediate representation, 컴퓨터 프로그램의 분석을 돕기위해 설계된 추상적 기계 언어) 변환
- "x = (a + b * c) / 2" 연산이 다음과 같은 형태로 구현됩니다.
x = (a + b * c) / 2
t1 := b * c
t2 := a + t1
t3 := t2 / 2
x := t3- 관용구
디스어셈블리 과정 또는 다음의 분석 과정에서 이러한 관용적인 결과물들은 알려진 IR과 동등한 것으로 번역될 필요가 있다.
다음은 x86 기계어 코드이다.
cdq eax ; edx is set to the sign-extension of eax
xor eax, edx
sub eax, edx이것은 다음과 같이 변환될 수 있다.
eax := abs(eax);
몇몇 관용적 결과들은 머신에 독립적이다. 즉 오직 하나의 명령어에 관련된다. 예를 들면, xor eax, eax는 eax 레지스터를 비우는 명령이다. 이것은 a xor a = 0 같은 머신에 독립적인 간단한 규칙으로 간소화될 수 있다.
일반적으로 다음 단계에서 명령어 순서에 영향을 덜 미치게 하기 위해서 가능한 한 관용적 결과들에 대한 탐지는 늦추는게 좋다. 예를 들면, 컴파일러의 명령어 스케줄 단계에서는 다른 명령어를 관용적 결과에 삽입하거나 순서를 바꾸는 경우가 있다. 디스어셈블리 단계의 패턴 매칭 과정에서 바뀐 패턴을 인식하지 못할 수도 있다. 다음 단계에서 명령어 집합 표현들은 더 더 복잡한 표현들로 바뀌고 고전적인 형태로 수정하며 바뀐 관용구는 고급 패턴에 맞게 된다.
컴파일러 관용구를 서브루틴 호출, 예외 처리 그리고 Switch 문으로 인식하는 것은 특히 중요하다. 또한 몇몇 언어들은 문자열이나 정수형에 대한 광범위한 지원을 가진다.
- 프로그램 분석
다양한 프로그램 분석이 IR에 적용될 수 있다. 특히, 표현 전달은 여러 명령어들의 의미들을 더 복잡한 표현으로 통합한다. 예를 들면,
mov eax,[ebx+0x04]
add eax,[ebx+0x08]
sub [ebx+0x0C],eax은 표현 전달 이후로 아래와 같은 IR로 바뀔 수 있다.
m[ebx+12] := m[ebx+12] - (m[ebx+4] + m[ebx+8]);
결과를 표현한 것은 더 고급 언어와 닮았으며 기계어 레지스터 eax의 사용을 제거하였다. 분석 이후 ebx 레지스터도 제거될 것이다.
- 데이터 흐름 분석
레지스터 내용들이 정의되고 사용되는 곳은 데이터 흐름 분석을 통해 추적될 수 있어야 한다. 같은 분석은 임시 변수 그리고 로컬 데이터가 사용하는 위치에도 적용될 수 있다. 그 후 다른 이름은 값 정의 집합과 사용에 연결되어 구성된다. 같은 지역 변수의 위치는 원본 프로그램의 다른 부분의 변수들과 함께 사용될 수 있다. 더 심한 경우는, 실제로 절대 일어나지 않거나 현실에서는 중요하지 않지만, 데이터 흐름 분석 시에 값이 이러한 두 사용 사이에서 흐르는 경로를 인식하는것이 가능할 수 있다. 좋지 않은 경우, 이것은 타입들의 결합으로서 위치에 대한 정의의 필요성으로 이어질 수 있다. 역컴파일러는 사용자에게 명백히 이러한 비자연스러운 의존성을 깨게 허용함으로써 더 깨끗한 코드로 만들 수 있다. 이것은 물론 변수가 잠재적으로 초기화 없이 사용됐다는 것이고, 원본 프로그램에서 문제가 나타나게 된다.
- 타입 분석
좋은 기계어 코드 역컴파일러는 타입 분석을 수행한다. 레지스터나 메모리 위치들이 사용되는 방식은 위치의 가능한 타입에 대한 제약으로 귀결된다. 예를 들면, and 명령어는 피연산자가 정수라는 것을 의미한다. 즉, 프로그램은 부동소수점 값이나 포인터에서 동작하는 명령을 사용하지 않는다. add 명령어는 3가지 제약으로 귀결되는데, 피연산자가 정수거나 아닐 수 있기 때문이다. 나머지 하나는 두 피연산자가 다를 경우에 생기는 제한이다.
다양한 고급 표현들은 구조체나 배열들의 인식을 촉발하는 것으로 인식될 수 있다. 그러나 기계어나 C 같은 고급 언어들의 포인터 연산을 허용하는 자유 때문에 많은 가능성을 구별하는 것은 어려운 일이다.
앞의 섹션에서의 예는 다음과 같은 급 언어로 귀결될 수 있다.
struct T1 *ebx;
struct T1 {
int v0004;
int v0008;
int v000C;
};
ebx->v000C -= ebx->v0004 + ebx->v0008;- 구조화
역컴파일링의 끝에서 두 번째 단계는 IR을 구조화하여 while 루프와 if/then/else 조건부 선언 같은 고급 구조체로 만드는 것이다. 예를 들면 기계어는 아래와 같다.
xor eax, eax
l0002:
or ebx, ebx
jge l0003
add eax,[ebx]
mov ebx,[ebx+0x4]
jmp l0002
l0003:
mov [0x10040000],eax이것은 다음과 같이 변환될 수 있다.
eax = 0;
while (ebx < 0) {
eax += ebx->v0000;
ebx = ebx->v0004;
}
v10040000 = eax;구조화되지 않은 코드를 구조화된 코드로 변환하는 것은 이미 구조화된 코드를 변환하는 것보다 훨씬 어렵다. 해결법으로는 몇몇 코드를 자기복제하거나 불리언 변수들을 추가하는 것이 있다.[5]
- 코드 생성
마지막 단계는 역컴파일러의 백엔드에서 고급 언어를 생성하는 것이다. 컴파일러가 여러 다른 아키텍처에 따른 여러 다른 기계어를 생성하는 백엔드를 가지듯이 역컴파일러도 여러 고급 언어 별로 생성할 수 있는 백엔드를 갖는다.
코드 생성 바로 직전에 GUI 형태를 사용하여 IR의 상호적인 수정을 허용하는 것이 바람직하다. 이것은 사용자에게 주석을 달거나 포괄적이지 않은 변수와 함수 이름들을 집어넣게 할 수 있다. 그러나 이것들은 역컴파일링 후에 하는 것처럼 쉽게 할 수 있다. 사용자는 구조적인 면을 바꾸고 싶어할 수도 있다(while 루프를 for 루프로 바꾼다든지). 이것들은 간단한 텍스트 에디터로는 쉽게 수정될 수 없다. 비록 소스 코드 리팩토링 도구들이 이 과정에서 도와준다고 하더라도 말이다. 마지막으로 결과 코드를 더욱 읽기 쉽게 하기 위하여, 부정확한 IR은 고쳐지거나 바뀌어야 한다.
JVM 과 bytecode 의 관계
JVM은 특정 운영체제(플랫폼) 상관없이 독립적으로 동작할 수 있다.
이는 자바 바이트코드를 실행할 수 있는 주체이며, .class 파일 형태인 bytecode가 실행될 수 있도록 .exe 실행 파일을 만들어 실제로 자바 파일을 실행하기 때문이다.
즉, JVM이 플랫폼에 상관없이 독립적으로 작동할 수 있는 이유는 바로 자바에서 컴파일 되어 기계어가 아닌 중간단계의 형태로 변환 된 코드인 bytecode가 특정 운영체제와 상관없이 독립적으로 작동하므로 JVM에 의해 실행되어 지는 것이다.
따라서 .java 형식의 특정 자바 프로그램이 운영체제에 독립적으로 동작할 수 있는 것은 컴파일러를 통해 만들어진 .class 형식의 바이트 코드로 인해 JVM에서 실행되기 때문이다.
질문
- 자바 소스는 이해가 되는데 컴파일러로 변환된 바이트 코드는 해석이 되지않습니다
혹시 제가 바이트 코드 명령어를 이해해야하나요? 그렇다면 더 공부를 할 시간이 필요합니다ㅜㅜ
https://iamsang.com/blog/2012/08/19/introduction-to-java-bytecode/ ??
-> 필수는 아닙니다. 어셈블러를 알면 바로 해석이 되지만, 우리는 시스템 프로그래밍을 하는 것이 아니기 때문에 꼭 알아야 하는 것은 아닙니다. 다만, 컴퓨터의 동작에 대해서 보다 깊이 있게 알고 싶어하는 욕구가 있다면 공부해 보는 것도 좋습니다. 운전면허에 비유해 보자면 보통 2종 자동 면허만 취득해도 승용차를 운전하고 생활 하는데 아무 문제 없습니다. 하지만, 1종 면허 또는 대형 , 특수장비(포크레인 등) 면허를 보유하게 되면 운전할 수 있는 대상 범위가 늘어나지만 현실적으로는 운전할 일이 거의 없겠죠.
- 디컴파일러 개념은 이해하는데 단계 상세하게 이해가 잘 안갑니다.. 특히 관용구,구조화,,,???
-> 위와 마찬가지로 개념 정도만 알아도 전혀 문제 없습니다. 관용구와 구조화에 대해서 부연 설명을 하자면,
관용구 : 관례적으로 사용하는 문구 라는 의미를 가지고 있습니다. 즉, for 문을 작성할 때 내부 변수를 i, j, k.. 등을 사용하는데 왜 i 로 정의 하나요? 라고 하면 관용구 라고 대답해도 무리가 없습니다.
구조화 : 바이트 코드의 경우 위에서 아래로 흘러가는 코드 구조로 되어 있습니다. 하지만, 자세히 보면 jmp 와 같이 다시 위로 올라가는 상황이 존재합니다. 결국 흐름에 대한 구조화가 되어 있지 않고 강제로 흐름을 변경하는 방식 입니다.(과거에 go to 라고...). 이는 기계가 읽고 실행하기에는 아무 문제 없지만 사람이 보고 해석하기에는 많은 어려움이 있습니다. 따라서, 명령의 흐름을 구조적으로 표현하는 과정을 구조화 라고 이해 하시면 됩니다.
- JVM이 운영체제에 독립적인 이유는 단지 bytecode를 실행하기 때문인가요? 또 다른 이유가 있나요? (단순 궁금)
-> JVM 은 운영체제에 독립적이지 않고 종속적입니다! Java 언어가 운영체제(플랫폼)에 독립적인 것이지, JVM 이 독립적인 것이 아닙니다.
