1. Cache 의 개념
개발을 하다보면 '캐시를 지우고 확인해보세요~' 라는 말을 듣기도 하는데,
많은 서비스에서 성능 향상을 위해 캐싱을 도입한다.
- 캐시(Cache) 란?
캐시 메모리는 메인 메모리와 CPU 간의 데이터 속도 향상을 위한 중간 버퍼 역할을 하는 CPU 내 또는 외에 존재하는 메모리이다.즉, 실제 메모리와 CPU 사이에서 빠르게 전달을 위해서 미리 데이터들을 저장해두는 좀 더 빠른 메모리로 전체 시스템의 성능의 개선을 시킬 수 있다.
캐시는 자주 사용하는 데이터나 값을 미리 복사해 놓는 기법(매커니즘)이다.
아래와 같은 저장공간 계층 구조에서 확인할 수 있듯이 캐시 메모리는 저장 공간이 작고 비용이 비싼 대신 빠른 성능을 제공한다.

Cache는 아래와 같은 경우에 사용을 고려하면 좋다.
- 원본 데이터를 가져오는 시간이 오래 걸리는 경우(서버의 균일한 API 데이터)
- 반복적으로 동일한 결과를 돌려주는 경우(이미지나 썸네일 등)
Cache에 데이터를 미리 복사해 놓으면 계산이나 접근 시간 없이 더 빠른 속도로 데이터에 접근할 수 있다. 결국 Cache란 반복적으로 데이터를 불러오는 경우에, 지속적으로 DBMS 혹은 서버에 요청하는 것이 아니라 Memory에 데이터를 저장하였다가 불러다 쓰는 것을 의미한다.
Enterprise급 Application에서는 DBMS의 부하를 줄이고, 성능을 높이기 위해 캐시(Cache)를 사용한다. 원하는 데이터가 캐시에 존재할 경우 해당 데이터를 반환하며, 이러한 상황을 Cache Hit라고 한다. 하지만 원하는 데이터가 캐시에 존재하지 않을 경우 DBMS 또는 서버에 요청을 해야하며 이를 Cache Miss라고 한다.
캐시는 저장공간이 작기 때문에 지속적으로 Cache Miss가 발생하는 데이터의 경우 캐시 전략에 따라서 저장중인 데이터 구조를 변경해야 한다.
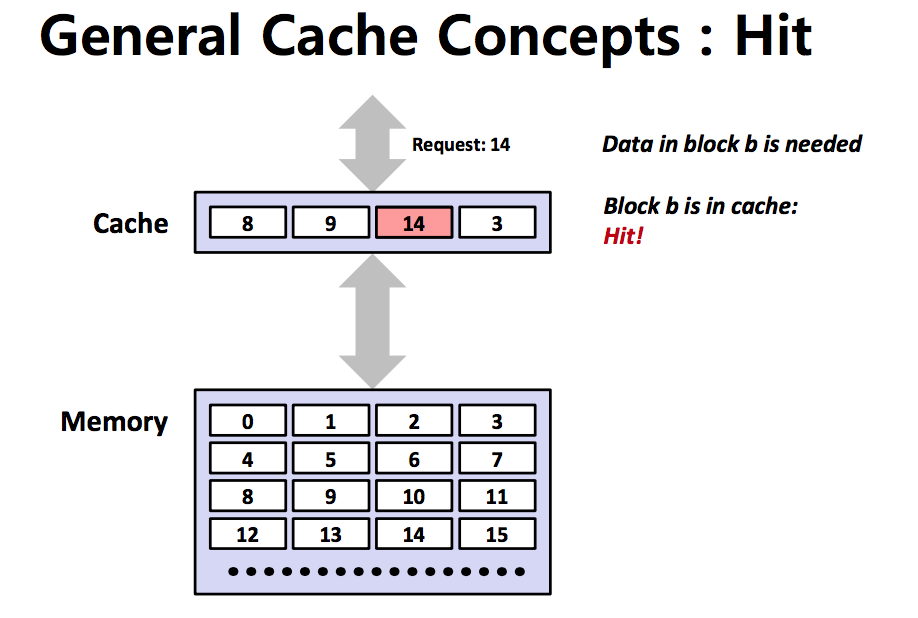
- Cache Hit
CPU가 값을 가져오려고 할 때 Cache에 해당하는 값이 있다면 Memory까지 가지 않고 Cache까지만 가서 값을 가져올 수 있다. 이 경우를 Cache Hit이라고 한다.
- Cache Miss
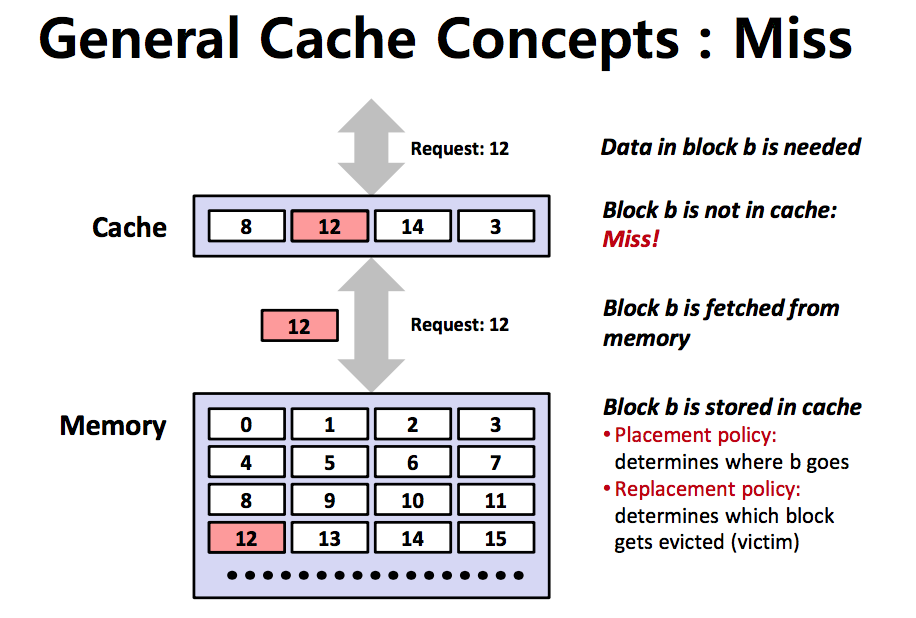
반대의 경우로 CPU가 값을 가져오려고 할 때 Cache에 해당하는 값이 없다면 Memory까지 가서 값을 가져와야 한다. 이 경우를 Cache Miss이라고 한다.
그림은 12가 cache에 없는 경우에 메모리에서 가져오는 것을 보여주고 있다.
- 캐시 관련 용어
-
origin
origin 혹은 origin server 는 캐시에 저장할 실 데이터가 존재하는 공간이다.
웹 캐시라면 DB 서버일 수도 있고, SW 내에서라면 파일 혹은 실행 함수 그 자체일 수도 있다. -
cache expire
프로세스 내에서 사용하는 인메모리 캐시나 영구히 상주해야하는 정보를 가진 캐시가 아니라면 Cache 는 Expire Date 를 갖고 있으며 해당 시간이 지나면 상한(Stale) 상태가 된다. -
cache freshness
캐시가 만료되지 않은 경우를 fresh 한 캐시라 하고 만료된 경우 stale cache라 한다. -
cache hit ratio
적중률로 전체 참조 횟수 대비 Cache hit 된 비율을 의미한다.
실질적으로 캐시의 설계는 Cache hit Ratio 를 높이는 데 초점을 둔다.
2. Cache 구현 방식
- 구현 원리
- 지역성(Locality)의 원리에 따라 CPU가 참조하는 데이터를 예측하여 캐시 메모리에 미리 담아둔다.
- 캐시 메모리에 있는 데이터는 주기억장치를 참조하지 않고 고속의 캐시메모리에서 바로 가져와 실행한다.
- 지역성(Locality)
캐시가 효율적으로 동작하려면, 캐시에 저장할 데이터가 지역성을 가져야 한다.
지역성이란 데이터 접근이 시간적, 혹은 공간적으로 가깝게 일어나는 것을 의미한다.
-
시간적 지역성
특정 데이터가 한번 접근되었을 경우, 가까운 미래에 또 한번 데이터에 접근할 가능성이 높은 것을 시간적 지역성이라고 한다. 메모리 상의 같은 주소에 여러 차례 읽기 쓰기를 수행할 경우 상대적으로 작은 크기의 캐시를 사용해도 효율성을 꾀할 수 있다. -
공간적 지역성
특정 데이터와 가까운 주소가 순서대로 접근되었을 경우를 공간적 지역성이라고 한다. CPU 캐시나 디스크 캐시의 경우 한 메모리 주소에 접근할 때 그 주소뿐 아니라 해당 블록을 전부 캐시에 가져오게 된다. 이때 메모리 주소를 오름차순이나 내림차순으로 접근한다면, 캐시에 이미 저장된 같은 블록의 데이터를 접근하게 되므로 캐시의 효율성이 크게 향상된다.
- 구현 기법
CPU 관점에서의 캐시 구현 방식은 조사하신 3가지가 있다.
어플리케이션 관점에서는 memory 기반 캐시(java heap 메모리)도 있고 서버기반 캐시(redis)도 있으며, cache-control 과 같이 컨텐트 기반도 있다.
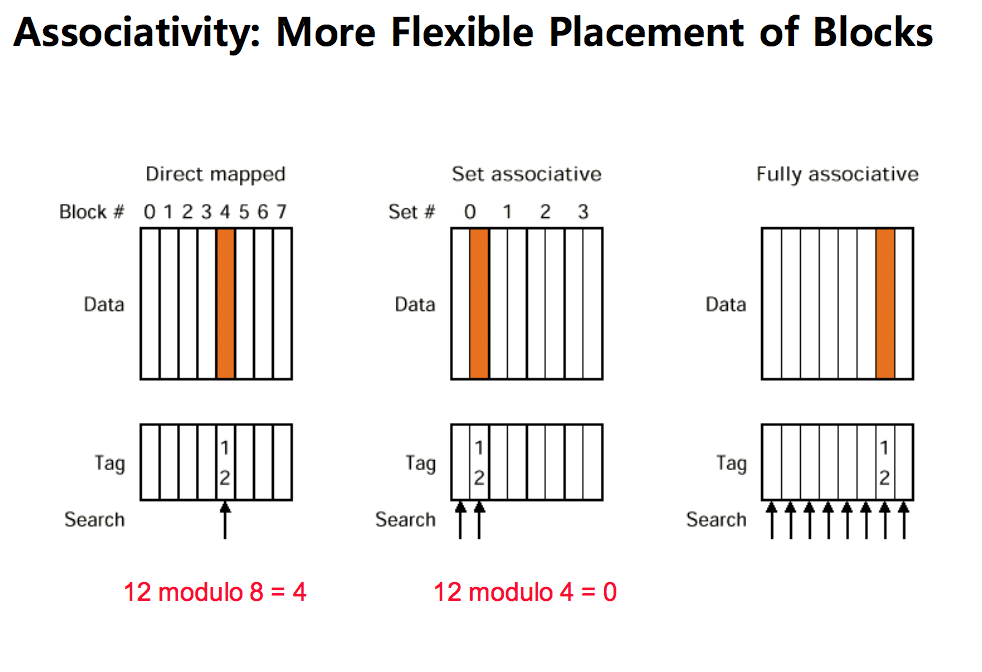
- Direct Mapping (직접 방식)
-
메모리의 특정 블록 주소가 상위 계층의 단 한 곳에만 배치, 주 기억장치의 블록들이 지정된 한 개의 캐시 라인으로만 매핑한다.
-
메모리 주소와 캐시의 순서를 일치시킨다.
ex) 메모리가 1~100, 캐시가 1~10으로 가정하면 1~10까지의 메모리는 캐시의 1에 할당, 11~20까지의 메모리는 캐시의 2에 할당한다. -
구현 정말 간단하지만 캐싱 효율이 떨어져 잦은 교체 발생한다.
-
적중률이 낮고 성능이 낮은 단순한 방식이다.
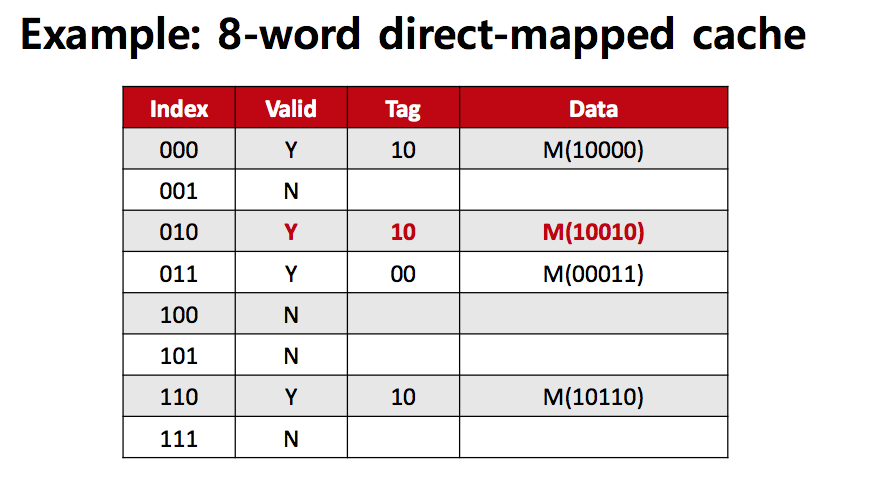
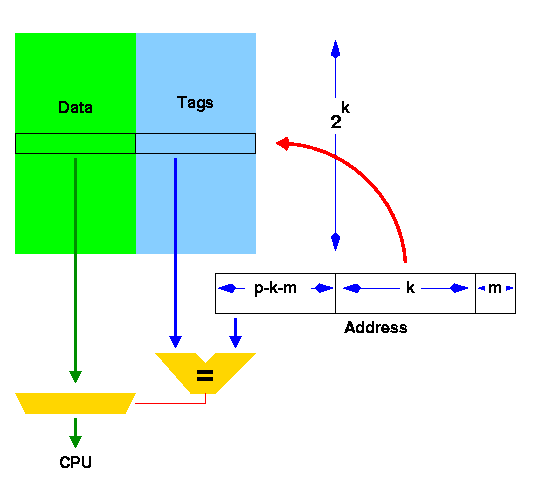
Index는 set의 주소이고 Cache의 주소를 Tag라고 부른다.
여기에서는 1비트만 저장하는 캐시라고 보면 block Offset은 0이라고 생각한다.
Data에는 Memory(10000)에 있는 값이 저장되었다고 보면 된다.
Valid가 필요한 이유는 캐시 블록에 값이 없는 경우에는 칸이 비어있는 것처럼 보이지만 사실 의미없는 0과 1의 값이 쓰레기값으로 들어가있기때문에 이런 값을 실제 데이터와 구분해주기 위해서 Valid를 표시하는 1비트가 필요하다.
- N-way Set Associative Mapping (N-way 집합 연관 방식)
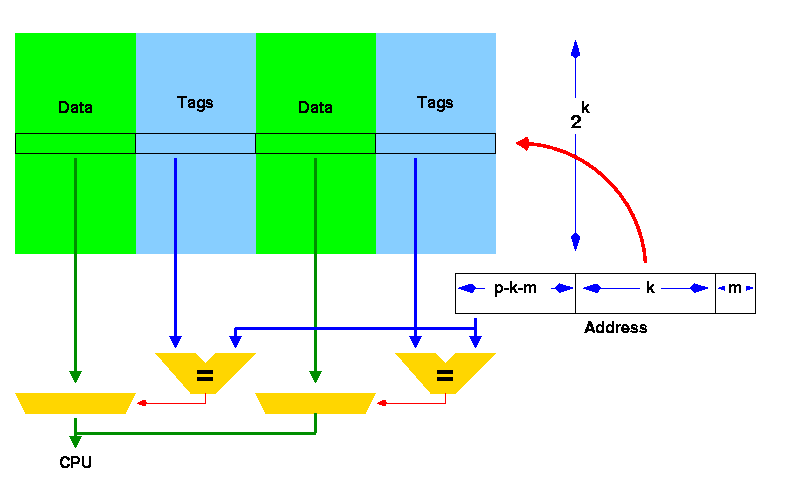
-
연관매핑에 직접매핑을 합쳐 놓은 방식으로 순서를 일치시키고 저장하되, 일정 그룹을 두어 그 그룹 내에서 저장토록 한다.
ex) 메모리가 1~100, 캐시가 1~10으로 가정하면 캐시 1~5에는 1~50의 데이터 저장 가능하다. -
블록화가 되어 있으므로 검색 효율 증가, 적중률도 일정 수준 보장한다.
-
index를 통해 한번에 접근할 수 있지만, N번의 비교가 필요하며 여전히 공간을 완전히 효율적으로 사용하진 못한다.
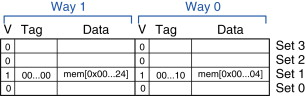
하나의 Set에 하나의 Block만 있었던 것을 여러개의 Block이 Set에 들어갈 수 있도록 늘려준다.
Direct Mapping과 비교해서 Cache의 자율성이 늘어나면서 이와 같은 상황에 대한 정책이 생겼다.
연속적으로 같은 set에 서로 다른 값들이 저장되려고 할 때 새로 들어온 값을 어디에 배치할 것인지에 대한 문제는 기존의 저장되있던 어떤 캐시의 값을 삭제할 것인지와 필연적으로 맞닿아 있다. 또한 CPU가 보내준 주소값의 cache hit을 확인하려고 할 때, set안에 여러개의 block이 있고 주소를 가지고는 그 중 어떤 블록에 값이 담겨있을지 전혀 예측할 수 없다는 단점도 생긴다. 그래서 해당 set안의 모든 block에 대해서 tag를 비교해서 값을 찾아내야 한다.
-
Fully Associative Mapping (연관 방식)
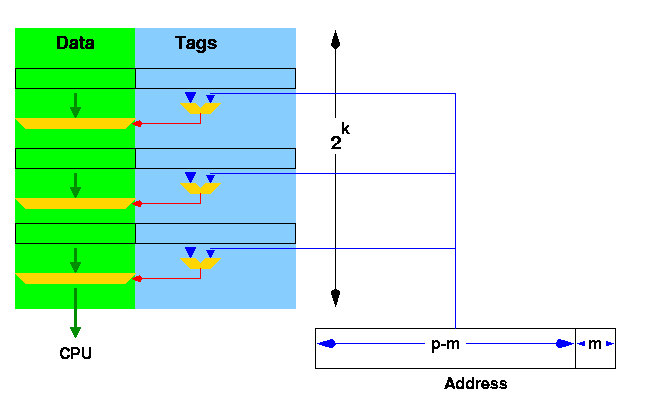
-
호출되는 블록이 캐시 내 어느곳에나 위치할 수 있는 방식이다. 즉, 블록을 찾기위해서는 모든 캐쉬내 블록을 찾아야한다.
-
검색을 효율적으로 수행하기 위해서 캐시 엔트리와 연결된 비교기를 이용하여 병렬로 검색한다.
이러한 비교기는 하드웨어 비용을 크게 증가시키므로 완전 연관 방식은 작은 수의 블록을 갖는 캐시에서만 유용하다. -
메모리 주소와 캐시의 순서를 일치시키지 않는다.
-
찾는 과정은 느리지만 필요한 캐시들 위주로 저장할 수 있기 때문에 적중률이 높다.
각 캐시 라인을 보고 요청받은 데이터의 주소와 일치하면 해당 위치에 요청받은 데이터가 들어 있음을 알 수 있다. 이러한 태그 일치는 끝에서부터 차례로 모든 캐시 라인을 조사해가게 되면 시간이 걸리므로 고속으로 데이터를 공급하는 캐시 목적에 적합하지 않다. 그래서 생각한 것이 캐시 라인 태그 각각에 비교회로를 장착해서 CPU에서 요청하는 주소와 태그 간 일치 여부를 병렬로 체크하는 방식이다.
3. Cache coherence 문제와 해결방법
- 캐시 일관성(Cache Coherence) 이란?
공유 메모리 시스템에서 각 클라이언트(혹은 프로세서)가 가진 로컬 캐시 간의 일관성을 의미한다.
각 클라이언트가 자신만의 로컬 캐시를 가지고 다른 여러 클라이언트와 메모리를 공유하고 있을 때
캐시의 갱신으로 인한 데이터 불일치 문제가 발생한다.
예를 들어 변수 X에 대해서 두 클라이언트가 변수 X를 공유하고 있고 그 값이 0이라고 하자.
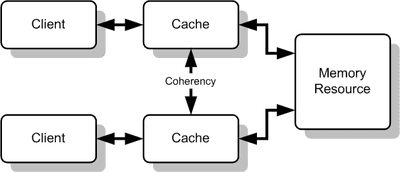
이때 클라이언트 1(그림의 윗쪽)이 X에 1을 대입하였고 클라이언트 2(그림의 아래쪽)가 변수 X를 읽어들이게 되면 클라이언트 2는 클라이언트 1에 의해 수정된 값인 1을 받아들이는 것이 아니라
현재 자신의 로컬 캐시에 있는 0을 읽어들이게 된다.
따라서 캐시 1, 2는 같은 X라는 변수에 대해 다른 값을 가지게 되므로 캐시 일관성 문제가 발생한다.
하드웨어 차원에서 항상 최신 내용을 읽을 수 있게 캐시 일관성(Cache Coherence)을 지원해야한다.
캐시 일관성을 유지하기 위해서는 다른 프로세서가 갱신한 캐시 값을 곧바로 혹은 지연하여 다른 프로세서에서 사용할 수 있도록 해주어야 한다.
- 캐시 일관성 문제 해결방법
캐시 일관성을 유지하기 위해 멀티 프로세서에서는 캐시에게 공유된 데이터의 이동(Migration)과 복사(Replication) 기능을 제공해준다.
- 이동(Migration)이란
데이터를 지역 캐시로 이동하는 것을 의미한다.
이동은 먼 곳에 위치한 공유 데이터를 접근할 때 발생하는 지연과 공유 메모리 요청에 따른 대역폭을 줄여준다.
- 복사(Replication)란?
공유 데이터가 동시에 읽혀질 때, 캐시는 지역 캐시 안에 복사본을 만든다.
복사는 공유 데이터 접근 시 대기시간과 읽기 경쟁을 감소시킨다.
이같은 이동과 복사를 지원하는 것은 공유 데이터를 접근하는 성능에 있어서 매우 중요하기 때문에 많은 멀티 프로세서들이 캐시 일관성을 유지하기 위해 하드웨어 프로토콜을 도입하고 있다.
멀티 프로세서에서 일관성을 유지하기 위한 프로토콜은 캐시 일관성 유지 프로토콜(Cache Coherence Protocol)이라고 부른다. 핵심은 데이터 블록의 모든 공유 상태를 추적하는 것이다.
가장 널리 사용되는 기법은 스누핑(Snooping)이다. 모든 캐시는 실제 메모리 블록으로부터 데이터의 복사본 갖고 있고, 블록의 공유상태에 대한 복사본도 갖고 있다. 그러나 중앙에서 관리되는 상태는 유지하지 않는다. 캐시들은 전송 매체(버스 또는 네트워크)를 통하여 모두 접근 가능하다. 그리고 모든 캐시 제어기들은 버스에 요청된 블록의 복사본을 갖고 있는지 없는지를 확인하기 위해 매체를 감시(Snoop)한다.
- 캐시 일관성 유지 프로토콜(Cache Coherence Protocol)
디렉토리와 스누핑 프로토콜이 존재하며, 연구가 활발히 진행되고 있다.
- 디렉토리 프로토콜
-
디렉토리 기반 일관성 구조는 캐시 블록의 공유 상태, 노드 등을 기록하는 저장 공간인 디렉터리를 이용하여 관리하는 구조이다.
-
데이터의 복사본이 존재하는 위치에 대한 정보를 수집하고 유지한다.
-
디렉터리 기반 구조는 어떤 노드에서 해당 캐시 블록의 복사본을 가지고 있는지를 알고 있기 때문에
특정 노드에만 요청을 하게 된다. 따라서 브로드캐스트가 불필요하게 되어 대역폭이 상대적으로 작아도 된다. -
주기억장치에는 여러 개의 지역 캐시들의 내용에 대한 전역 상태 정보가 담긴 디렉토리가 저장된다.
또한 주기억장치 제어기의 일부로 존재하는 중앙 제어기는 프로세서가 가진 복사본의 라인 정보를 가지고 있다. -
중앙 제어기는 모든 지역 캐시 제어기의 동작을 제어하고 보고를 받아 캐시 일관성을 유지한다.
-
중앙 병목(central bottleneck) 및 캐시 제어기들과 중앙 제어기 간의 통신 오버헤드를 가지는 단점이 존재한다. 하지만 다중 버스(multiple buses)나 복잡한 상호연결망을 포함하는 대규모 시스템에 효과적이다.
이러한 이유로 64개 이상의 프로세서를 가지는 대규모 시스템에서는 디렉터리 기반의 캐시 일관성 프로토콜을 사용하는 경우가 많다.
- 스누핑 프로토콜
-
스누핑(snooping)은 주소 버스를 항상 감시하여 캐시 상의 메모리에 대한 접근이 있는지를 감시하는 구조이다.
-
다른 캐시에서 쓰기가 발생하면 캐시 컨트롤러에 의해서 자신의 캐시 위에 있는 복사본을 무효화시킨다.
-
캐시 일관성 유지에 대한 책임을 다중 프로세서 내의 모든 캐시 제어기들에게 분산한다.
-
캐시는 자신이 가진 라인이 다른 캐시와 공유되는지를 파악하고 있으며 공유 캐시 라인이 갱신되었을 때, 각 캐시 제어기는 Broadcasting된 캐시 갱신 소식을 받아 해당 캐시를 무효화한다.
-
공유 버스가 Broadcasting과 Snooping에 유리하므로 스누핑 프로토콜은 버스 기반 다중 프로세서에 적합하다.
-
write-invalidate, write-update, write-broadcast 등으로 스누핑 방식을 구현한다.
이 방법은 모든 캐시 라인의 상태를 Modified, Exclusive, Shared, Invalid로 표현하기에
MESI 프로토콜이라고도 한다.
- MESI 프로토콜
-
캐시 메모리의 일관성을 유지하기 위해서 별도의 플래그(flag)를 할당한 후 플래그의 상태를 통해 데이터의 유효성 여부를 판단하는 프로토콜이다.
-
데이터 캐시는 태그 당 두 개의 상태 비트를 포함한다.
-
멀티프로세서 시스템에서 캐시 메모리의 일관성을 유지하기 위해 메모리가 가질 수 있는 4가지 상태를 정의한다.
- Modified(수정) 상태 : 데이터가 수정된 상태
- Exclusive(배타) 상태 : 유일한 복사복이며, 주기억장치의 내용과 동일한 상태
- Shared(공유) 상태 : 데이터가 두 개 이상의 프로세서 캐쉬에 적재되어 있는 상태
- Invalid(무효) 상태 : 데이터가 다른 프로세스에 의해 수정되어 무효화된 상태
스누핑의 경우 각 노드의 대역폭이 충분히 크다면 좋은 성능을 기대할 수 있다.
그러나 성능 확장성(Scalability)이 좋지 않다.
왜냐하면 메모리 요청(Request)에 대해 다른 모든 노드에 브로드캐스트 해야 하기 때문이며
노드의 수가 증가하면 더 많은 브로드캐스트가 발생하게 되고 이 때문에 버스의 대역폭도 더 늘어나야만 한다.
4. FLO 에서 적용되고 있는 cache 기법을 아는데로 나열해 보기
- Cache-Control
각 API 별로, 변동사항이 거의 없는 응답 값을 Cache-Control 처리하고 있다.
이전에 Search API > Cache-Control 도입 관련하여 공부한 자료
https://velog.io/@ha0kim/Cache-Control
내가 담당하는 Search API 는 검색 결과나 인기 급상승 키워드의 케이스는 캐시될 데이터가 아니라 판단되어 적용하지 않았다.
- Redis
현재 CMS에서 변경되는 사항들을 관련된 API에 알리기 위해, Redis를 사용한다.
- Memory Caching
실제 변경할 경우가 거의 없는 시스템 메뉴에 대해서 메모리 캐싱을 한다.
