The $group Stage
- "그룹 키"에 따라 문서를 그룹으로 구분하며, 출력은 각 고유 그룹 키에 대한 하나의 문서
- accumulator 연산자를 지정하여 연산도 가능 (선택)
{
$group:
{
_id: <expression>, // Group key
<field1>: { <accumulator1> : <expression1> },
...
}
}
- movies 컬렉션에 directors 배열의 사이즈를 구해 numDirectors 기준으로 그룹핑한다.
-> $isArray : 배열인지 체크
-> $cond : if 문 과 동일한 처리 - numFilms 이란 필드에 그룹핑 대상으로 sum 한 값을 저장한다.
- averageMetacritic 이란 필드에 그룹핑 대상으로 metacritic 에 대한 avg 값을 저장한다.
- 그룹핑 키인 _id.numDirectors 기준으로 내림차순 정렬한다.
- Accumulator Operator
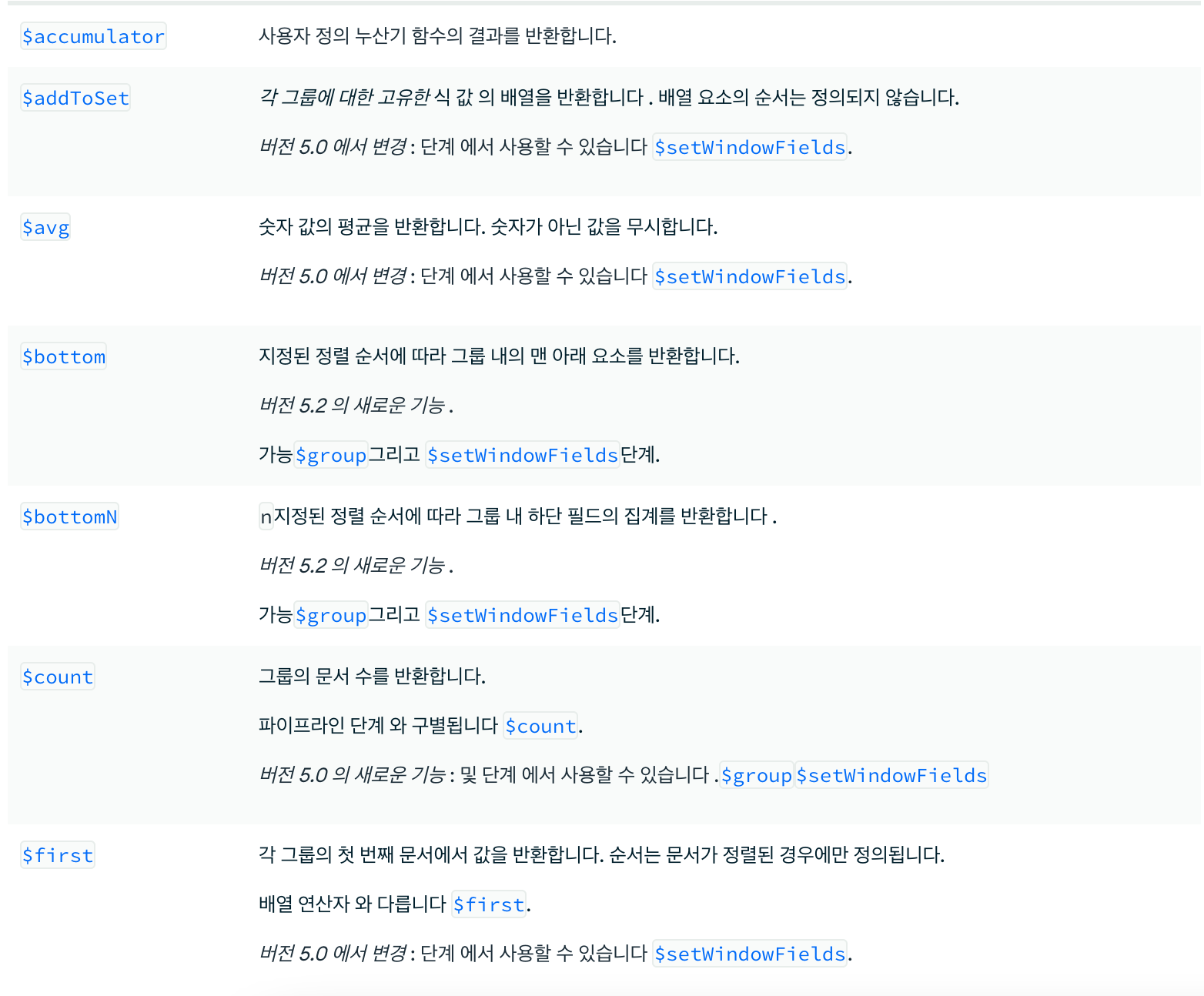
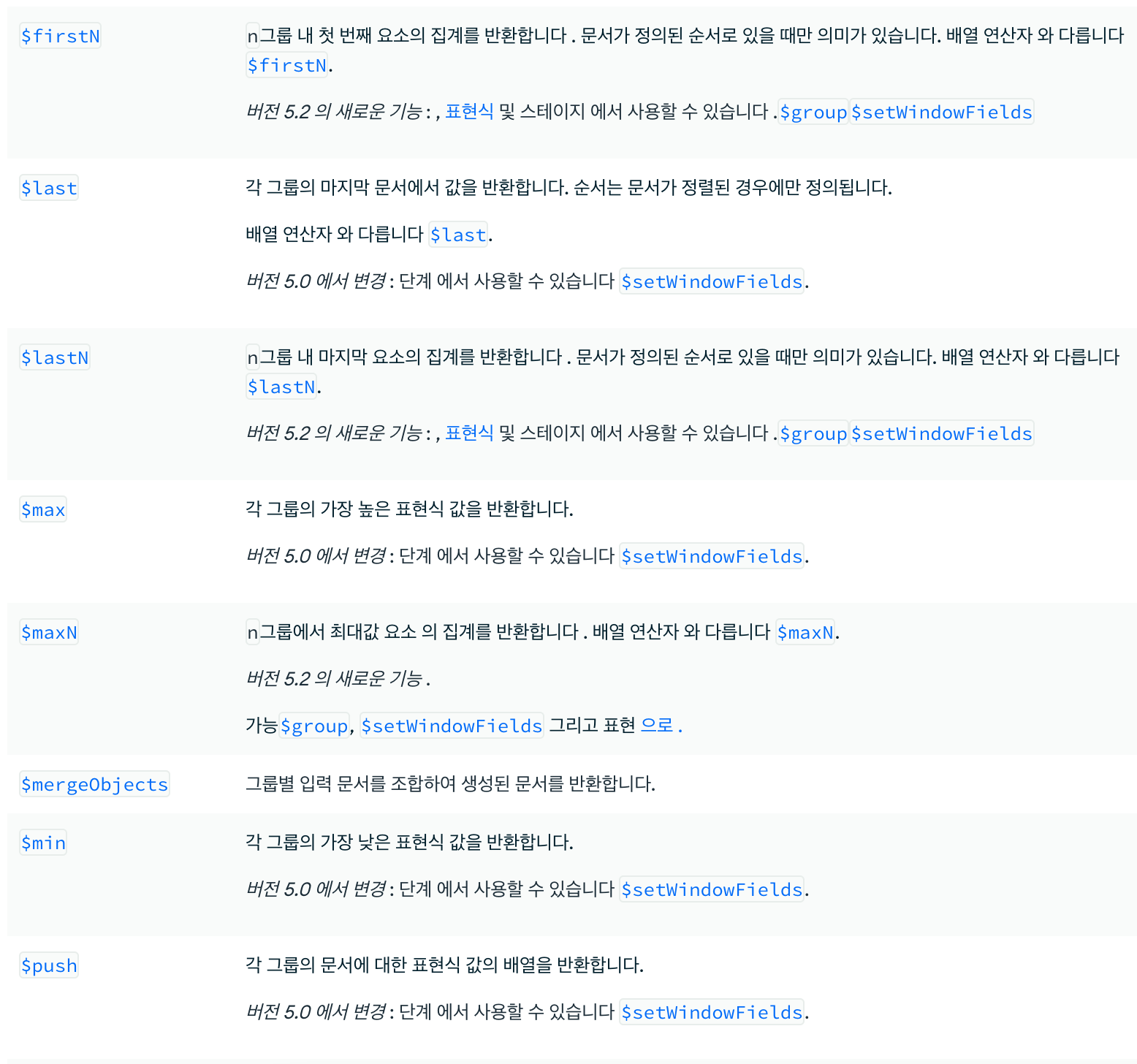

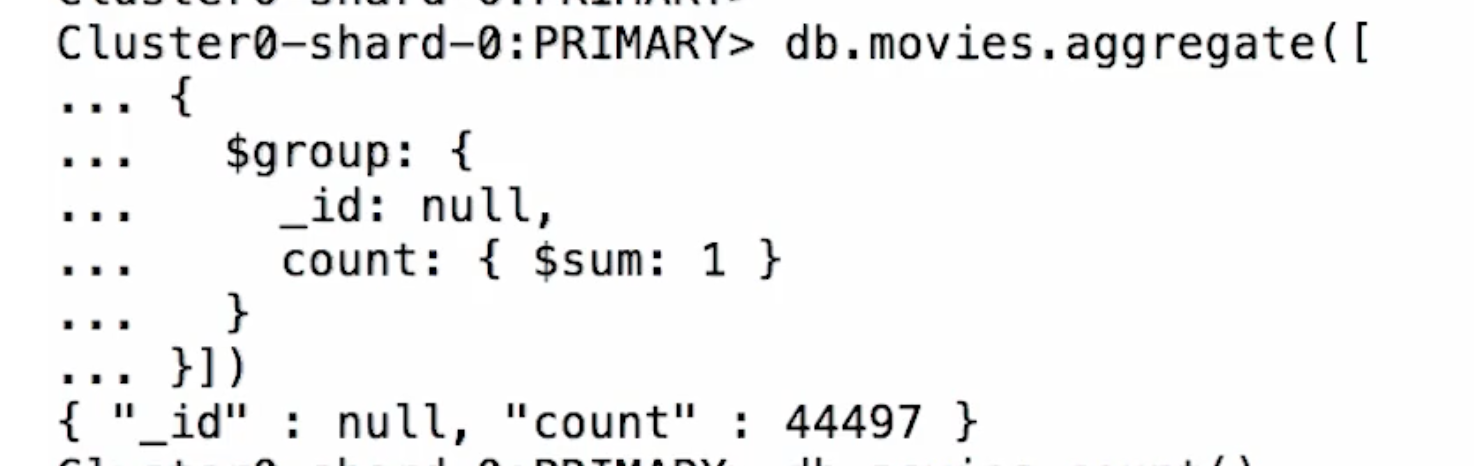
- 위와 같이 그룹키를 null 로 지정하고 accumulator 연산자를 지정하여 연산만 처리할 수도 있다.
Accumulator Stages with $project
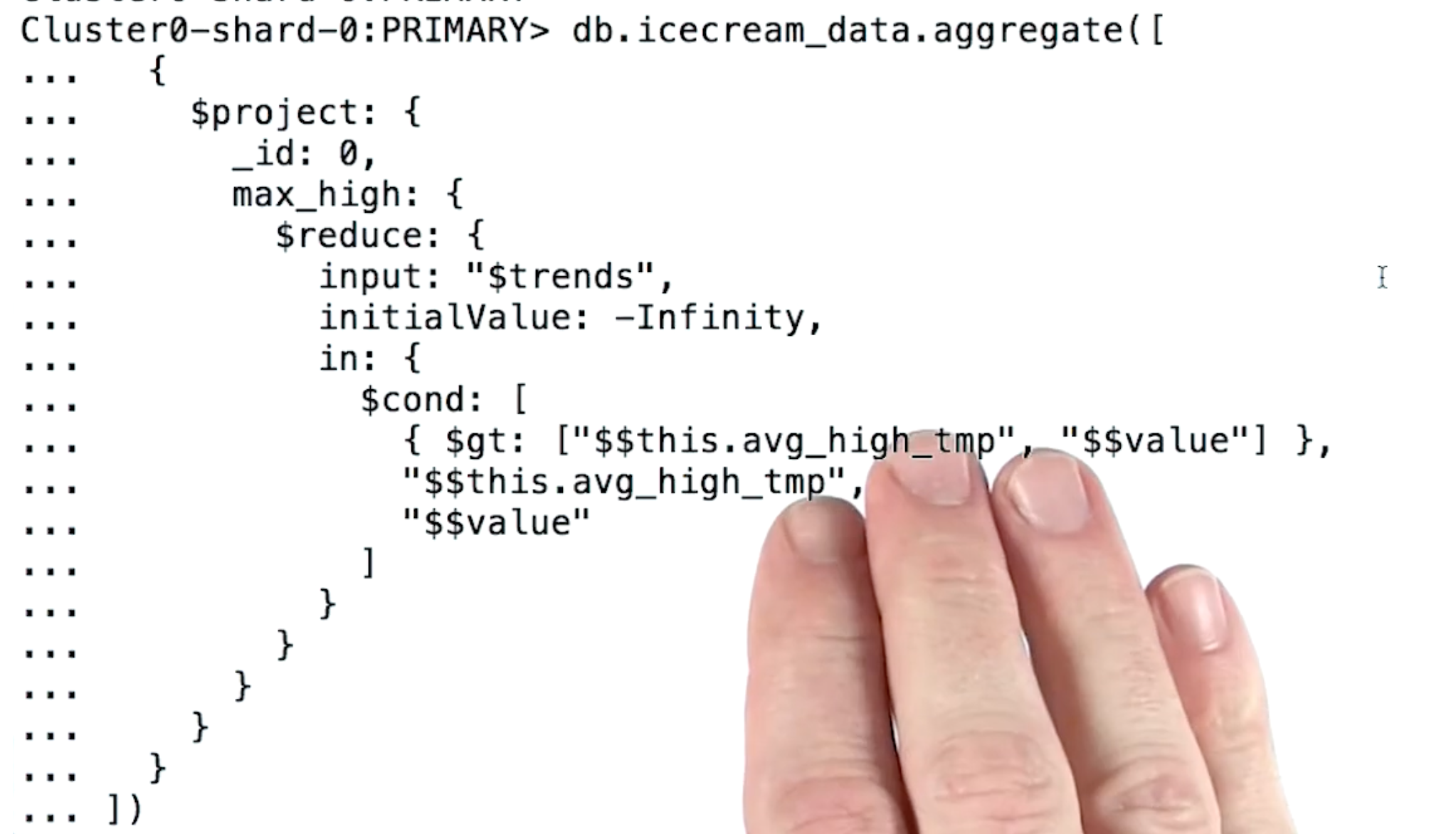
- icecream_data 컬렉션의 trends 필드의 avg_high_temp 값이 initialValue 보다 크다면 max_high 값은 avg_high_temp 가 되고 아니면 value 가 된다.
- $reduce 를 통해 컬렉션 내에 조건을 만족하는 애들을 돌아가면서 체크한다.
근데 이를 간단하게 처리할 수 있다! -> Accumulator 연산자 + $project


- $project 와 같이 쓸수 있는 Accumulator 연산자는 6개로 제한되어 있는 건가??
(수업 내용에서는 그러는 것 같은디...)
The $unwind Stage
- 입력 문서에서 배열 필드를 분해하여 각 요소에 대한 문서를 출력
- 각 출력 문서는 배열 필드의 값이 요소로 대체된 입력 문서

- short form
{ $unwind: <field path> }- long form
{
$unwind:
{
path: <field path>,
includeArrayIndex: <string>,
preserveNullAndEmptyArrays: <boolean>
}
}-> includeArrayIndex : 배열 요소의 순번을 표시한다.
-> preserveNullAndEmptyArrays : 지정된 field path에 원소가 없거나 null 이어도 출력하는지 여부 ( 기본 값 : false)
The $lookup Stage
- 동일한 데이터베이스의 특정 컬렉션에 대해 LEFT OUTER JOIN 을 수행
- $lookup 단계에서 새 배열 필드를 추가하며, 새 배열 필드에는 "조인된" 컬렉션에서 일치하는 문서가 포함
--> LEFT OUTER JOIN
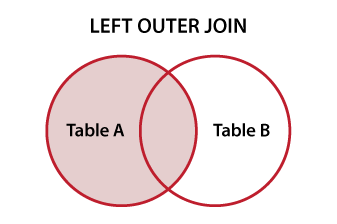
LEFT OUTER JOIN은 왼쪽 테이블의 것은 조건에 부합하지 않더라도 모두 결합되어야 한다는 의미이다.
즉, FROM 첫번째 테이블 LEFT OUTER JOIN 두번째 테이블이라면 첫번째 테이블의 것은 모두 출력되어야 한다.
참고 : https://qqplot.github.io/database/2021/09/15/left_outer_join.html
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}- from : 조인을 수행할 동일한 데이터베이스의 컬렉션을 지정 (샤딩 X)
- localField : 입력된 컬렉션에서 필드를 지정. foreignField 와 매칭을 위해 정의
- foreignField : "조인된" 컬렉션에서 필드를 지정.
localField 에 foreignField 가 일치하거나 포함되어 있을 경우, join 처리된다. - as : 입력 문서에 추가할 새 배열 필드의 이름을 지정
$graphLookup Introduction
- 재귀 깊이 및 쿼리 필터로 검색을 제한하는 옵션을 사용하여 컬렉션에 대한 재귀 검색을 수행
- RDBMS 의 재귀 쿼리와 같은 기능
- ex ) 회사 계층 구조 (=조직도)
--> 재귀 쿼리란?
가상의 테이블을 만들고, 그 테이블의 값을 참조하여 값을 결정하기 위해 사용되는 쿼리문
자기 자신을 참조하기 때문에 재귀 쿼리라고 불린다.
{
$graphLookup: {
from: <collection>,
startWith: <expression>,
connectFromField: <string>,
connectToField: <string>,
as: <string>,
maxDepth: <number>,
depthField: <string>,
restrictSearchWithMatch: <document>
}
}-
from : $graphLookup 대상 컬렉션
컬렉션 from은 작업에 사용된 다른 컬렉션과 동일한 데이터베이스에 있어야 하며, MongoDB 5.1부터 매개 from변수에 지정된 컬렉션을 샤딩할 수 있다. -
startWith : 재귀 검색을 시작할 값을 지정하는 식
-
connectFromField : 재귀 호출하여 일치하는 값이 있는 from 컬렉션의 문서 connectToField 와 일치시키는 필드 (.. 모르겟음..뭔말인지..)
-
connectToField : connectFromField 에 지정된 필드와 일치 시킬 다른 문서의 필드
-
as : 각 출력 문서에 추가된 배열 필드의 이름
-
maxDepth : 최대 재귀 깊이를 지정하는 음이 아닌 정수 (선택요소)
-
depthField : 검색 경로에서 순회된 각 문서에 추가할 필드의 이름
이 필드의 값은 NumberLong 로 표시되는 문서의 재귀 깊이. -
restrictSearchWithMatch : 재귀 검색을 위한 추가 조건을 지정하는 문서
db.employees.aggregate( [
{
$graphLookup: {
from: "employees",
startWith: "$reportsTo",
connectFromField: "reportsTo",
connectToField: "name",
as: "reportingHierarchy"
}
}
] )...뭥미 어려움...!
practice
- $group and Accumulators
var pipeline = [
{
$match: {
"awards.text": /Won \d{1,2} Oscars?/
}
},
{
$group: {
_id: null,
highest_rating: { $max: "$imdb.rating" },
lowest_rating: { $min: "$imdb.rating" },
average_rating: { $avg: "$imdb.rating" },
deviation: { $stdDevSamp: "$imdb.rating" }
}
}
]- $unwind
var pipeline = [
{
$match: {
languages: "English"
}
},
{
$project: { _id: 0, cast: 1, "imdb.rating": 1 }
},
{
$unwind: "$cast"
},
{
$group: {
_id: "$cast",
numFilms: { $sum: 1 },
average: { $avg: "$imdb.rating" }
}
},
{
$project: {
numFilms: 1,
average: {
$divide: [{ $trunc: { $multiply: ["$average", 10] } }, 10]
}
}
},
{
$sort: { numFilms: -1 }
},
{
$limit: 1
}
]- $lookup
var pipeline = [
{
$match: {
airplane: /747|380/
}
},
{
$lookup: {
from: "air_alliances",
foreignField: "airlines",
localField: "airline.name",
as: "alliance"
}
},
{
$unwind: "$alliance"
},
{
$group: {
_id: "$alliance.name",
count: { $sum: 1 }
}
},
{
$sort: { count: -1 }
}
]
db.air_routes.aggregate(pipeline)var pipeline = [
{
$match: { name: "OneWorld" }
}, {
$graphLookup: {
startWith: "$airlines",
from: "air_airlines",
connectFromField: "name",
connectToField: "name",
as: "airlines",
maxDepth: 0,
restrictSearchWithMatch: {
country: { $in: ["Germany", "Spain", "Canada"] }
}
}
}, {
$graphLookup: {
startWith: "$airlines.base",
from: "air_routes",
connectFromField: "dst_airport",
connectToField: "src_airport",
as: "connections",
maxDepth: 1
}
}, {
$project: {
validAirlines: "$airlines.name",
"connections.dst_airport": 1,
"connections.airline.name": 1
}
},
{ $unwind: "$connections" },
{
$project: {
isValid: { $in: ["$connections.airline.name", "$validAirlines"] },
"connections.dst_airport": 1
}
},
{ $match: { isValid: true } },
{ $group: { _id: "$connections.dst_airport" } },
{ $sort: { _id: 1 } }
]