LESSON 4 : CORE AGGREGATION - MULTIDIMENSIONAL GROUPING
$sortByCount
-
지정된 표현식의 값을 기준으로 수신 문서를 그룹화한 다음 각 고유 그룹의 문서 수를 계산 및 정렬한다.
-
각 출력 문서에는 고유한 그룹화 값을 포함하는 필드(_id)와 해당 그룹화 또는 범주에 속하는 문서의 수(count)를 포함하는 필드의 두 필드가 포함된다.
-
문서는 내림차순으로 정렬된다.
{ $sortByCount: <expression> }-
expression : 그룹화 할 식이다.
문서 리터럴을 제외한 모든 식을 지정할 수 있다.
필드 경로를 지정하려면 필드 이름 앞에 달러 기호를 $접두사로 붙이고 따옴표로 묶는다. -
$sortByCount 단계는 다음 $group+ $sort 시퀀스와 동일하다.
{ $group: { _id: <expression>, count: { $sum: 1 } } },
{ $sort: { count: -1 } }$bucket
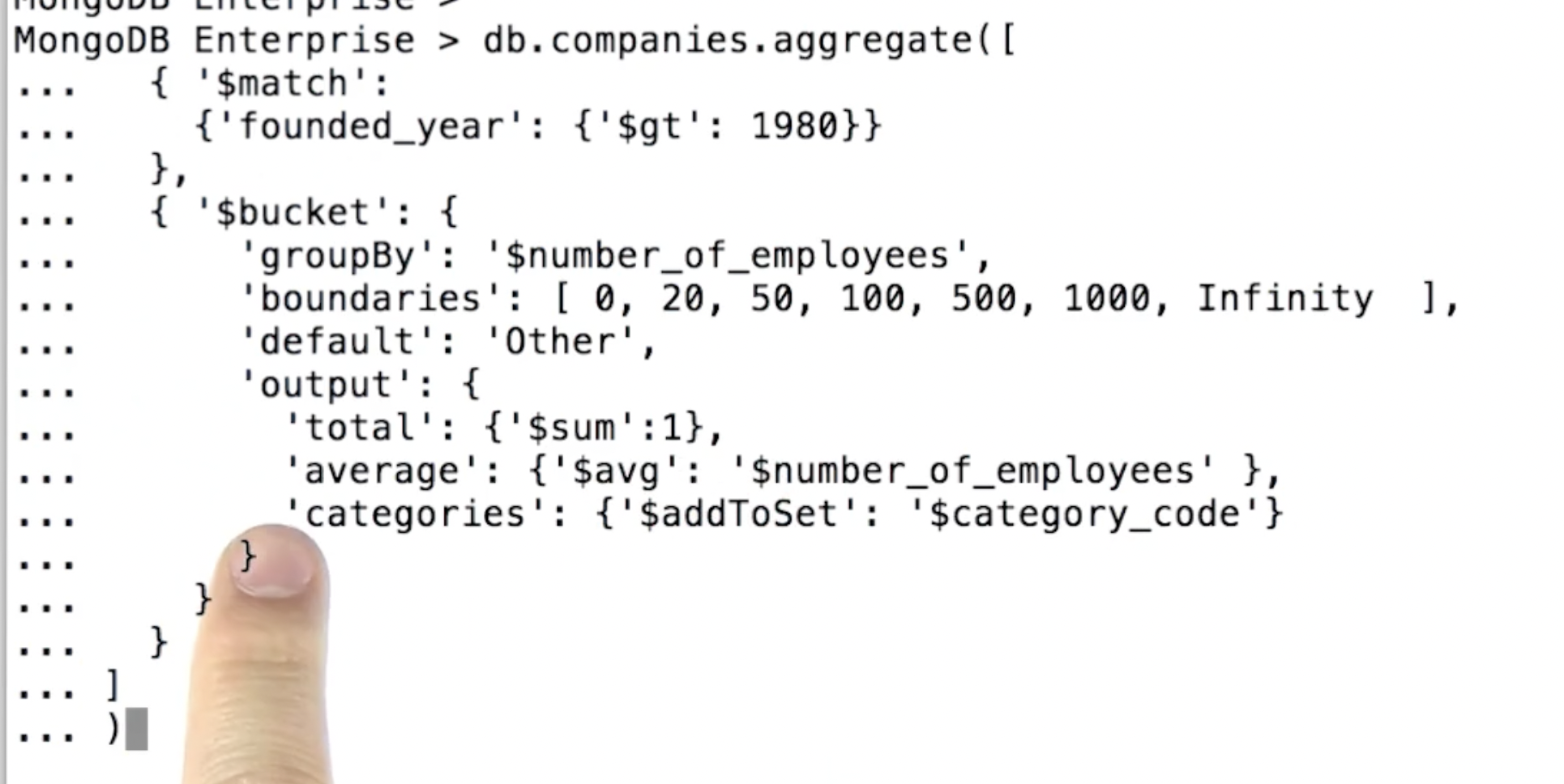
- 지정된 표현식 및 버킷 경계에 따라 버킷이라는 그룹으로 분류하고 각 버킷별로 문서를 출력한다.
- 하나 이상의 입력 문서가 포함된 버킷에 대한 출력 문서만 생성한다.
{
$bucket: {
groupBy: <expression>,
boundaries: [ <lowerbound1>, <lowerbound2>, ... ],
default: <literal>,
output: {
<output1>: { <$accumulator expression> },
...
<outputN>: { <$accumulator expression> }
}
}
}-
groupBy : 문서를 그룹화하는 표현식
-> 필드 경로를 지정하려면 필드 이름 앞에 달러 기호를 $접두사로 붙이고 따옴표로 묶는다. -
boundaries : 그룹별로 각 버킷의 경계를 지정하는 표현식
-> 지정된 값은 오름차순이어야 하며 모두 동일한 유형이어야 한다. -
default : 지정한 버킷에 속하지 않은 대상을 정의
-
output : 출력 문서에 포함할 필드를 지정하는 문서
$bucketAuto
- 지정된 표현식을 기반으로 버킷이라고 하는 특정 수의 그룹으로 분류한다.
- 버킷 경계는 지정된 수의 버킷에 문서를 고르게 배포하기 위해 자동으로 결정된다.
{
$bucketAuto: {
groupBy: <expression>,
buckets: <number>,
output: {
<output1>: { <$accumulator expression> },
...
}
granularity: <string>
}
}
- groupBy : 문서를 그룹화하는 표현식
- buckets : 그룹화되는 버킷 수를 지정하는 양의 32비트 정수
- output : 필드 외에 출력 문서에 포함할 필드를 지정하는 문서
- granularity
: 계산된 경계 가장자리가 기본 라운드 숫자 또는 10의 거듭제곱에서 끝나도록 하는 데 사용한다.
즉, 버킷의 경계를 세분화 할 수 있다.
-> "R5" / "R10" / "R20" / "R40" / "R80" / "1-2-5" ...

$facet
-
동일한 입력 문서 세트의 단일 단계 내에서 여러 집계 파이프라인을 처리한다.
-
각 하위 파이프라인에는 결과가 문서 배열로 저장되어 자체 필드로 출력된다.
-
이 $facet를 사용하면 단일 집계 단계 내에서 여러 차원 또는 패싯에 걸쳐 다면적 집계를 만들 수 있다. 다면적 집계는 데이터 검색 및 분석을 안내하는 여러 필터 및 분류를 제공한다.
-
여러 번 검색할 필요 없이 동일한 입력 문서 세트에서 다양한 집계를 활성화한다.
{ $facet:
{
<outputField1>: [ <stage1>, <stage2>, ... ],
<outputField2>: [ <stage1>, <stage2>, ... ],
...
}
}- 지정된 각 파이프라인의 출력 필드 이름을 지정합니다.
Practice - $facet
var pipeline = [
{
$match: {
'tomatoes.critic.rating': { $gte: 0 },
'imdb.rating': { $gte: 0 }
}
}, {
$project: {
_id: 0,
tomatoes: 1,
imdb: 1,
title: 1
}
}, {
$facet: {
top_tomatoes_critic: [
{
$sort: { 'tomatoes.critic.rating': -1, title: 1 }
}, {
$limit: 50
}, {
$project: { title: 1 }
}
],
top_imdb: [
{
$sort: { 'imdb.rating': -1, title: 1 }
}, {
$limit: 50
}, {
$project: { title: 1 }
}
]
}
}, {
$project: {
movies_in_both: {
$setIntersection: [ '$top_tomatoes_critic', '$top_imdb' ]
}
}
}
]LESSON 5: MISCELLANEOUS AGGREGATION
$redact
- 문서 자체에 저장된 정보를 기반으로 문서의 내용을 제한한다.
{ $redact: <expression> }
- 표현식
- $$DESCEND : subdocument를 제외한 현재 수준의 document field를 return 한다.
- $$PRUNE : 해당되는 document와 그 하위document를 제외한다.
- $$KEEP : 더이상 검사하지 않고, 현재 level 에서의 document/subdocument들을 return 한다.
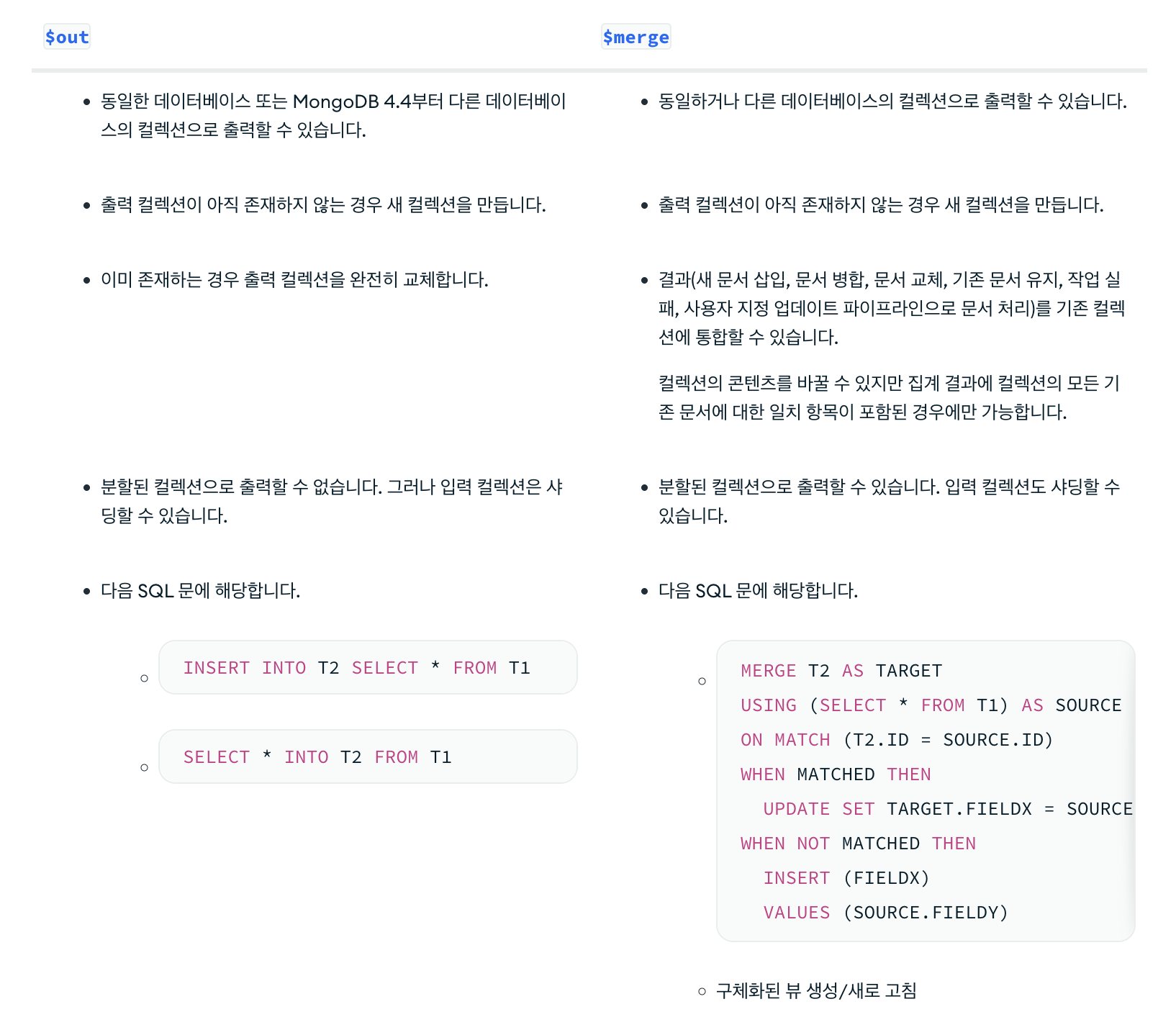
$out
- 조회된 데이터를 새로운 collection 으로 생성한다.
- 컬렉션이 없으면 새로 생성하고, 있으면 해당 결과로 대체된다.
- 수행중에 파이프라인이 실패 할 경우, 기존 컬렉션 값은 변경 되지 않는다.
- 컬렉션이 존재하는 경우, 기존 켈렉션의 인덱스를 존중해야 한다.
- 파이프라인의 마지막 단계로 사용한다.

$merge
- 집계 파이프라인 의 결과를 지정된 컬렉션에 쓴다.
- 파이프라인의 마지막 단계로 사용한다.

{ $merge: {
into: <collection> -or- { db: <db>, coll: <collection> },
on: <identifier field> -or- [ <identifier field1>, ...], // Optional
let: <variables>, // Optional
whenMatched: <replace|keepExisting|merge|fail|pipeline>, // Optional
whenNotMatched: <insert|discard|fail> // Optional
} }- into : 출력 컬렉션
-> into: "myOutput" / into: { db:"myDB", coll:"myOutput" }
- on : 문서의 고유 식별자 역할을 하는 필드
- whenMatched : 결과 문서와 컬렉션의 기존 문서가 지정된 값에 대해 동일한 값을 갖는 경우
다음 중 하나를 지정할 수 있습니다.
-> replace / keepExisting / merge (default) - let : whenMatched 에서 사용할 변수를 지정
- whenNotMatched : 결과 문서가 아웃 컬렉션의 기존 문서와 일치하지 않는 경우
미리 정의된 작업 문자열 중 하나를 지정할 수 있습니다.
-> insert(default) / discard / fail
Views
- 컬렉션 또는 집계 파이프 라인에 의해 콘텐츠가 정의되는 읽기 전용 쿼리 가능 개체
db.createCollection(
"<viewName>",
{
"viewOn" : "<source>",
"pipeline" : [<pipeline>],
"collation" : { <collation> }
}
)
db.createView(
"<viewName>",
"<source>",
[<pipeline>],
{
"collation" : { <collation> }
}
)
- 지원하지 않는 작업

참고
