DB SELECT 구문의 동작 과정
- 쿼리가 처리되는 과정
- 구문 분석(Parsing)
해당 쿼리가 문법적으로 틀리지 않은지 확인.
해당 구문을 SQL 서버가 이해할 수 있는 단위들로 분해하는 과정.
만약 구문이 부정확하다면 여기서 처리를 중단한다.
이 문장이 일괄 처리(batch) 내에 있다면 일괄 처리 전체를 중단한다.
(Batch abort : Batch 중 하나라도 syntax error가 있다면 전체 batch가 실행되지 않는다.)
- 표준화(Standardization)
실제로 필요없는 부분들이 제거. 표준화된 쿼리 트리(Standard Query Tree)가 만들어 진다.
- 최적화(Optimization)
통계나 조각 정보 등을 바탕으로 실행 계획을 만들어 낸다.
쿼리처리에서 매우 중요한 단계이다.
① 쿼리 분석 : 검색 제한자(SARG)인지 조인 조건인지 판단한다.
- SARG (Search argument) : 옵티마이저가 인덱스를 선택할 수 있도록 해주는 WHERE 절의 검색 조건.
② 인덱스 선택 : 분포 통계 정보를 이용하여 인덱스 검색이나 테이블 스캔 중의 하나를 선택한다.
여러 인덱스 중 가장 효율적인 인덱스를 선택한다.
③ 조인 처리 : JOIN, UNION, GROUP BY, ORDER BY 절을 가지고 있는지 확인하여 적절한 작업 순서를 선택한다.
이 단계의 출력은 실행 계획(Execution Plan) 이다.
- 컴파일(Compilation)
컴파일을 하면 이진 코드가 생성된다.
일반적인 경우에는 컴파일하고 나면 .exe, .dll 등의 이진 파일이 만들어 지는데,
SQL Server에서는 그냥 메모리(프로시저 캐시)에만 올린다.
그래서 컴파일 속도가 매우 빠르다.
- 실행(Execute)
엑세스 루틴으로 가서 실제 처리를 하고 결과를 돌려준다.
이상의 다섯 단계는 단순화한 논리적 절차로 받아들여야 하며, 실제 쿼리 과정은 이보다 훨씬 더 복잡하다.
- SELECT 쿼리 실행 순서
SQL 쿼리문을 작성할때 사용되는 WHERE, GROUP BY, ORDER BY 절과 같은 구문을 실행하는데 순서가 존재한다.
이 순서에 의해서 쿼리가 처리되고 어떻게 쿼리문을 작성하느냐에 따라 퍼포먼스의 차이가 발생한다.
예) ORACLE HR 계정의 EMPLOYEES 테이블로 어떤 처리 과정에 의해서 SELECT 쿼리가 실행되는지 알아보자!
SELECT
JOB_ID
,AVG(SALARY) SAL_AVG
FROM
EMPLOYEES
WHERE
SALARY > 13000
GROUP BY
JOB_ID
HAVING
COUNT(*) > 1
ORDER BY SAL_AVG DESC;
위의 쿼리문을 실행했을 때의 최종 결과이다.
화면에 출력되는 양은 매우 적지만 실제 내부적으로 이 결과를 얻기까지
SELECT, FROM, WHERE, GROUP BY, HAVING, ORDER BY 총 6단계에 걸쳐서 결과를 출력한다.
- 실행 순서
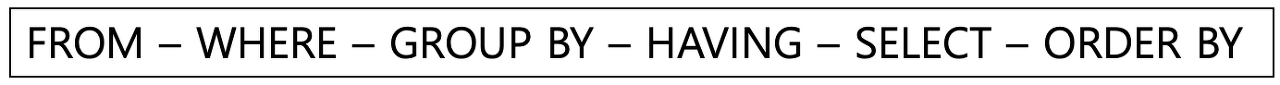
SELECT 쿼리문을 실행했을때 FROM - WHERE GROUP BY - HAVING - SELECT - ORDER BY 순서대로 실행된다.
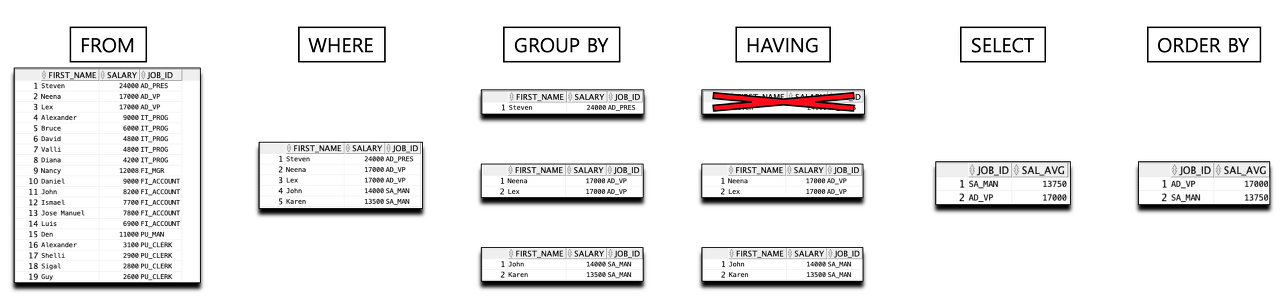
1. FROM 절
FROM EMPLOYEESSELECT 부터 시작할 것 같지만 쿼리의 가정 첫번째 실행 순서는 FROM 절이다.
FROM 절에서는 전체 테이블의 결과를 갖고온다.
INDEX를 사용하지 않는다는 가정에서 WHERE 절이나 SELECT 절에서
일부 행이나 열을 제거하여 출력한다고 해도 가장 처음에 테이블의 모든 데이터를 갖고온다.
2. WHERE 절
WHERE SALARY > 13000WHERE 절에서는 FROM절에서 읽어온 테이블에서 조건에 맞는 결과만 갖도록 데이터를 간추린다.
3. GROUP BY 절
GROUP BY JOB_IDGROUP BY 절에서는 WHERE 조건으로 추출된 데이터를 선택한 칼럼으로 GROUPING 작업을 한 결과를 갖고 있다. GROUP BY 절을 사용하게 되면 해당 칼럼으로 그룹함수를 사용할 수 있
4. HAVING 절
HAVING COUNT(*) > 1HAVING 절은 GROUP BY된 이 후 사용되는 조건 절이다.
똑같이 조건을 걸 수 있는 WHERE절과는 조금 다르게 써야한다.
WHERE 절에 있는 내용을 HAVING절에서 사용할 수 있지만
HAVING절에서 일반 조건들을 다루면 쿼리 실행 순서에 의해 퍼포먼스가 많이 떨어지게 된다.
위의 예제에서 "SALARY > 13000" 조건을 WHERE절에서 처리했을 때와 HAVING절에서 처리했을 때를 비교하면?
HAVING 절 처리
FROM 절에서 테이블의 전체 데이터를 불러오고 WHERE 절이 아닌 바로 GROUP BY 절로 넘어간다.
그렇게 되면 우선 전체 테이블에 대한 GROUPING 작업을 한다.
그 이후 각각 그룹에 "SALARY > 13000" 조건으로 데이터를 걸러준다.
WHERE 절 처리
FROM 절에서 테이블의 전체 데이터를 불러오고 WHERE 절에서 "SALARY > 13000" 조건을 처리하여 데이터의 양을 줄인다. 그다음 조건에 맞는 데이터만 남은 상태에서 GROUPING 작업을 진행한다.
위의 두가지 처리방법을 봤을때 WHERE 절에서 일발 조건을 처리하는 방식이 효율적이라는 것을 확인할 수 있다.
적은 양의 데이터에서는 큰 차이를 못 느낄 수 있지만, 데이터 양이 늘어날수록 퍼포먼스에 대한 차이가 커진다.
SELECT 절
SELECT JOB_ID, AVG(SALARY) SAL_AVG여러 조건들을 처리한 후 남은 데이터에서 어떤 열을 출력해줄지 선택한다.
ORDER BY 절
ORDER BY SAL_AVG DESC마지막으로 어떤 열까지 출력할지 정했다면 행의 순서를 어떻게 보여줄지 정렬해준다.
- 실행순서가 중요한 이유
실행순서에 대한 숙지는 필수이다.
쿼리를 사용할 때 우리는 최종적으로 출력되는 결과만 육안을 확인할 수 있다.
그래서 각 단계에서 어떤 데이터를 읽고 사용할 수 있는지, 실행순서를 모르면 쿼리를 작성하는데 많이 불편하다.
실행 순서에 있어서 몇가지 주의해야하는 사항이 있다.
1. ALIAS 사용
1번쿼리 : ORDER BY 절 ALIAS 사용
SELECT
EMPLOYEE_ID
,FIRST_NAME || ' ' || LAST_NAME AS NAME
,SALARY
,JOB_ID AS JOB
FROM EMPLOYEES
WHERE SALARY > 5000
ORDER BY NAME;1번 쿼리에서는 아무 문제가 없다.
ORDER BY 절은 맨 마지막에 실행되기 때문에 칼럼의 ALIAS를 사용해도 아무 문제가 없다.
2번쿼리 : WHERE 절 ALIAS 사용
SELECT
EMPLOYEE_ID
,FIRST_NAME || ' ' || LAST_NAME AS NAME
,SALARY
,JOB_ID AS JOB
FROM EMPLOYEES
WHERE SAL > 5000
ORDER BY NAME;그럼 WHERE 절에서 ALIAS를 사용하면?
"Invalid Identifier"에러가 발생한다.
이유는 SELECT 절은 WHERE 절 이후에 실행되기 때문에
WHERE 절이 실행 될때는 SAL 칼럼은 아직 존재하지 않는 칼럼이다.
2. ROWNUM 사용
SELECT
ROWNUM
,EMPLOYEE_ID
,FIRST_NAME || ' ' || LAST_NAME AS NAME
,SALARY
,JOB_ID AS JOB
FROM EMPLOYEES
WHERE SALARY > 5000
ORDER BY NAME;ROWNUM을 SELECT에 포함시켜 결과를 출력한다.
1 부터 출력 될것만 같았던 ROWNUM이 뒤죽박죽 섞여 있다.
현재 결과는 NAME 칼럼으로 정렬된 결과이다.
'A' 부터 순서대로 NAME칼럼을 기준으로 데이터를 정렬하여 출력된 올바른 출력결과이다.
하지만 ROWNUM은 이상하게 섞여있는 이유는 실행 순서에 따른 결과이다.
ORDER BY 절은 SELECT 절이 실행된 이후 처리되는 절이다.
그래서 ROWNUM은 NAME 칼럼으로 정렬되기 이전의 값에 행을 번호매긴 순서이다.
우리가 볼 수 있는 출력 결과는 ROWNUM을 매긴 후, NAME 칼럼으로 정렬된 결과 뿐이다.
DB Index 의 개념
- 인덱스란?
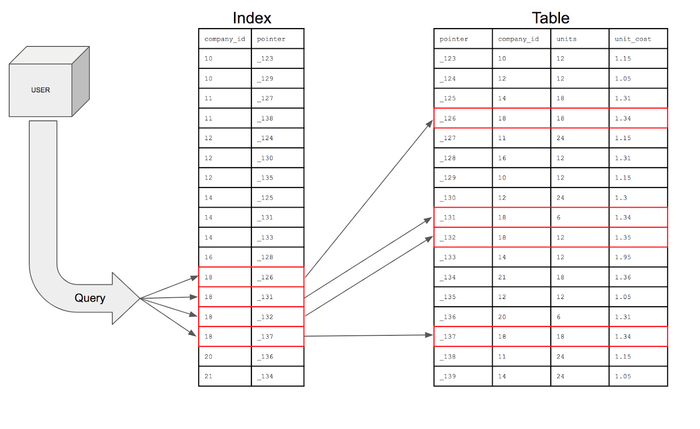
인덱스(영어: index)는 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다.
인덱스는 테이블 내의 1개의 컬럼, 혹은 여러 개의 컬럼을 이용하여 생성될 수 있다.
고속의 검색 동작뿐만 아니라 레코드 접근과 관련 효율적인 순서 매김 동작에 대한 기초를 제공한다.
인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작다.
(왜냐하면 보통 인덱스는 키-필드만 갖고 있고, 테이블의 다른 세부 항목들은 갖고 있지 않기 때문이다.)
관계형 데이터베이스에서는 인덱스는 테이블 부분에 대한 하나의 사본이다.
인덱스는 고유 제약 조건을 실현하기 위해서도 사용된다.
고유 인덱스는 중복된 항목이 등록되는 것을 금지하기 때문에 인덱스의 대상인 테이블에서 고유성이 보장된다.
인덱스는 특정 칼럼 값을 가지고 있는 열 혹은 값을 빠르게 찾기 위해서 사용된다.
MySQL은 첫 번째 열부터 전체 테이블에 걸쳐서 연관된 열을 검색하기 때문에
테이블이 크면 클 수록 비용이 엄청나게 늘어난다.
만약 테이블이 쿼리에 있는 컬럼에 대한 인텍스를 가지고 있다면,
MySQL은 모든 데이터를 조사하지 않고도 데이터 파일의 중간에서 검색위치를 빠르게 잡아낼 수 있다.
인덱스 위주 검색 후, 관련된 혹은 원하는 데이터들을 가져올 수 있다고 생각할 수도 있다.
- 인덱스를 사용하는 이유
-
WHERE 구문과 일치하는 열을 빨리 찾기 위해서.
-
열을 고려 대상에서 빨리 없애 버리기 위해서.
-
조인 (join)을 실행할 때 다른 테이블에서 열을 추출하기 위해서.
-
특정하게 인덱스된 컬럼을 위한 MIN() 또는 MAX() 값을 찾기 위해서.
-
사용할 수 있는 키의 최 좌측 접두사 (leftmost prefix)를 가지고 정렬 및 그룹화를 하기 위해서.
-
데이터 열을 참조하지 않는 상태로 값을 추출하기 위해서 쿼리를 최적화 하는 경우를 위해서.
- 인덱스를 사용해야 하는 경우
-
데이터 양이 많고 검색이 변경보다 빈번한 경우
-
인덱스를 걸고자 하는 필드의 값이 다양한 값을 가지는 경우
* 추후 실제 어떻게 사용하는지 방법에 대해 조사할 예정~
JOIN 의 유형과 동작 메커니즘
- 조인(JOIN) 이란?
2개 이상의 테이블을 연결하여 데이터를 검색하는 방법이다.
보통 공통된 값인 PK 및 FK 값을 사용하여 조인한다.
조인은 조인 연산자에 따라, From 절의 조인 형태에 따라서 구별한다.
- JOIN 의 유형
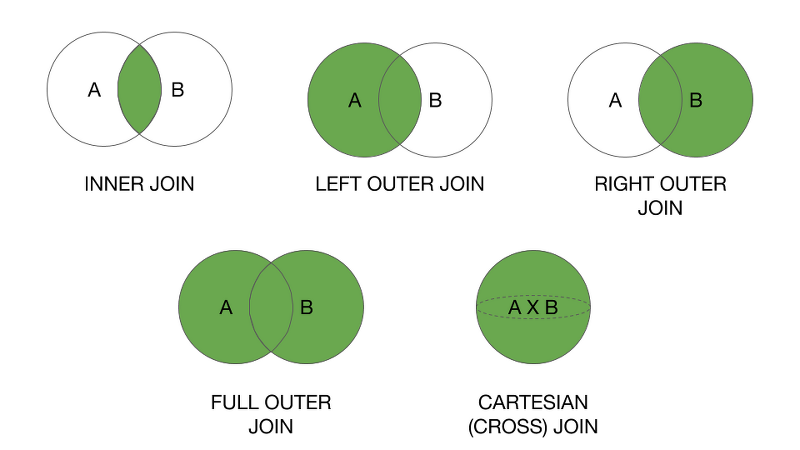
1. INNER JOIN
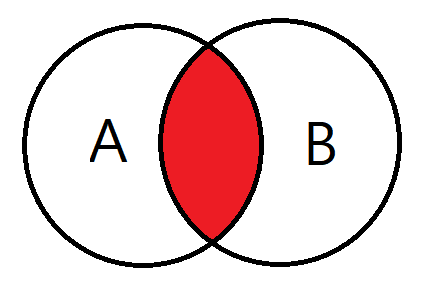
쉽게말해 교집합이라고 생각하시면 된다.
기준테이블과 JOIN한 테이블의 중복된 값을 출력한다.
결과값은 A의 테이블과 B테이블이 모두 가지고있는 데이터만 검색된다.
- 문법
SELECT
테이블별칭.조회할칼럼,
테이블별칭.조회할칼럼
FROM 기준테이블 별칭
INNER JOIN 조인테이블 별칭 ON 기준테이블별칭.기준키 = 조인테이블별칭.기준키....- 예제
SELECT
A.NAME, --A테이블의 NAME조회
B.AGE --B테이블의 AGE조회
FROM EX_TABLE A
INNER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP AND A.DEPT = B.DEPT2. LEFT OUTER JOIN
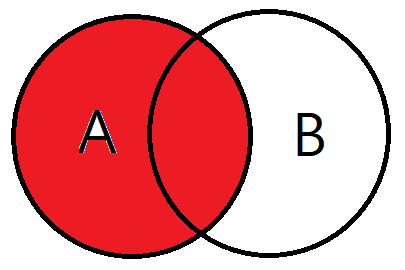
기준테이블의 값 + 테이블과 기준테이블의 중복된 값을 출력한다.
왼쪽 테이블을 기준으로 JOIN을 하겠다고 생각하면 된다.
그럼 결과값은 A테이블의 모든 데이터와 A테이블과 B테이블의 중복되는 값이 검색된다.
- 문법
SELECT
테이블별칭.조회할칼럼,
테이블별칭.조회할칼럼
FROM 기준테이블 별칭
LEFT OUTER JOIN 조인테이블 별칭 ON 기준테이블별칭.기준키 = 조인테이블별칭.기준키 .....- 예제
SELECT
A.NAME, --A테이블의 NAME조회
B.AGE --B테이블의 AGE조회
FROM EX_TABLE A
LEFT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP AND A.DEPT = B.DEPT3. RIGHT OUTER JOIN
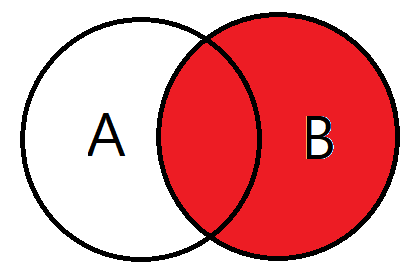
LEFT OUTER JOIN의 반대이다.
오른쪽 테이블을 기준으로 JOIN을 하겠다고 생각하면 된다.
그럼 결과값은 B테이블의 모든 데이터와 A테이블과 B테이블의 중복되는 값이 검색된다.
- 문법
SELECT
테이블별칭.조회할칼럼,
테이블별칭.조회할칼럼
FROM 기준테이블 별칭
RIGHT OUTER JOIN 조인테이블 별칭 ON 기준테이블별칭.기준키 = 조인테이블별칭.기준키 .....
- 예제
SELECT
A.NAME, --A테이블의 NAME조회
B.AGE --B테이블의 AGE조회
FROM EX_TABLE A
RIGHT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP AND A.DEPT = B.DEPT
FULL OUTER JOIN
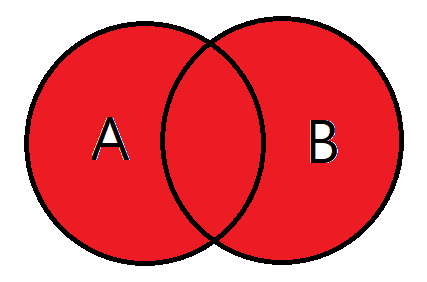
쉽게말해 합집합을 생각하면 된다.
A테이블이 가지고 있는 데이터, B테이블이 가지고있는 데이터 모두 검색된다.
사실상 기준테이블의 의미가 없다.
- 문법
SELECT
테이블별칭.조회할칼럼,
테이블별칭.조회할칼럼
FROM 기준테이블 별칭
FULL OUTER JOIN 조인테이블 별칭 ON 기준테이블별칭.기준키 = 조인테이블별칭.기준키 .....- 예제
SELECT
A.NAME, --A테이블의 NAME조회
B.AGE --B테이블의 AGE조회
FROM EX_TABLE A
FULL OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP AND A.DEPT = B.DEPT
CROSS JOIN
크로스 조인은 모든 경우의 수를 전부 표현해주는 방식이다.
기준테이블이 A일경우 A의 데이터 한 ROW를 B테이블 전체와 JOIN하는 방식이다.
그러니 결과값도 N * M 이 된다.
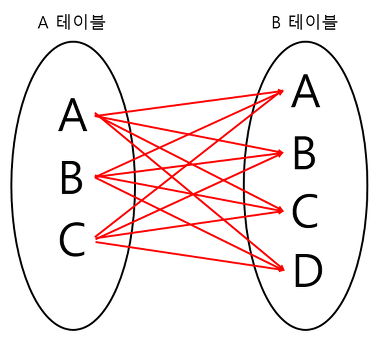
A테이블에 데이터가 3개, B테이블에는 데이터가 4개가 있으므로 총 12개가 검색된다.
- 문법
SELECT
테이블별칭.조회할칼럼,
테이블별칭.조회할칼럼
FROM 기준테이블 별칭
CROSS JOIN 조인테이블 별칭- 예제
SELECT
A.NAME, --A테이블의 NAME조회
B.AGE --B테이블의 AGE조회
FROM EX_TABLE A
CROSS JOIN JOIN_TABLE B- 문법(두번째방식)
SELECT
테이블별칭.조회할칼럼,
테이블별칭.조회할칼럼
FROM 기준테이블 별칭,조인테이블 별칭- 예제
SELECT
A.NAME, --A테이블의 NAME조회
B.AGE --B테이블의 AGE조회
FROM EX_TABLE A,JOIN_TABLE BSELF JOIN
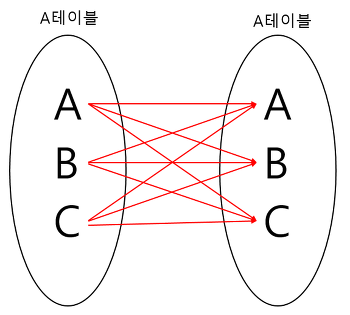
셀프 조인은 자기자신과 자기자신을 조인한다는 의미이다.
하나의 테이블을 여러번 복사해서 조인한다고 생각하면 된다.
자신이 가지고 있는 칼럼을 다양하게 변형시켜 활용할 경우에 자주 사용한다.
- 문법
SELECT
테이블별칭.조회할칼럼,
테이블별칭.조회할칼럼
FROM 테이블 별칭,테이블 별칭2- 예제
SELECT
A.NAME, --A테이블의 NAME조회
B.AGE --B테이블의 AGE조회
FROM EX_TABLE A,EX_TABLE BSQL 튜닝 사례
이건 튜닝이 아님...ㅎㅎ (다음 장에 자세하게 처리)
이전 메트에게 MYSQL 쿼리 튜닝 조언을 받아 개선한 사례이다.
, (select notice_img_url from tb_popup_notice_display d where p.popup_notice_id = d.popup_notice_id AND d.os_type != 'WEB' LIMIT 1) AS notice_img_url
, (select notice_img_url from tb_popup_notice_display d where p.popup_notice_id = d.popup_notice_id AND d.os_type = 'WEB' LIMIT 1) AS notice_pc_img_url
, (select notice_img_link_url from tb_popup_notice_display d where p.popup_notice_id = d.popup_notice_id AND d.os_type != 'WEB' LIMIT 1) AS notice_img_link_url
, (select notice_img_link_url from tb_popup_notice_display d where p.popup_notice_id = d.popup_notice_id AND d.os_type = 'WEB' LIMIT 1) AS notice_pc_img_link_urlselect 구문에 서브쿼리를 4개나 정의하여 매우 비효율적인 쿼리이었다.
, MAX(IF(d.os_type = 'WEB', null, d.notice_img_url)) AS notice_img_url2
, MAX(IF(d.os_type != 'WEB', null, d.notice_img_url)) AS notice_pc_img_url2
, MAX(IF(d.os_type = 'WEB', null, d.notice_img_link_url)) AS notice_img_link_url2
, MAX(IF(d.os_type != 'WEB', null, d.notice_img_link_url)) AS notice_pc_img_link_url2이를 LEFT OUTER JOIN 과 MAX 함수를 활용하여 튜닝하였다.


242ms > 239ms 로 속도가 개선되었고 쿼리도 가독성이 높아지게 튜닝되었다 ^_^
- 튜닝 시, 참고 사항 : https://velog.io/@gillog/SQL-%ED%8A%9C%EB%8B%9D
