- 이 장에서 배우는 내용
스프링 JdbcTemplate 사용하기
SimpleJdbcInsert 사용해서 데이터 추가하기
3.1 JDBC를 사용해서 데이터 읽고 쓰기
관계형 데이터를 사용할 때 가장 많이 사용하는 두 가지 방법이 JDBC, JPA 다.
스프링은 이 두가지 모두를 지원하며, 스프링을 사용하지 않을 때에 비해 더 쉽게 JDBC나 JPA를 사용할 수 있도록 해준다.
스프링의 JDBC 지원은 JdbcTemplate 클래스에 기반을 둔다. JdbcTemplate은 JDBC를 사용할 때 요구되는 모든 형식적이고 상투적인 코드없이 개발자가 관계형 데이터베이스에 대한 SQL 연산을 수행할 수 있는 방법을 제공한다.
JdbcTemplate를 사용하지 않고 데이터베이스 쿼리하기
@Override
public Ingredient findById(String id) {
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try {
connection = dataSource.getConnection();
statement = connection.prepareStatement("select id, name, type from Ingredient where id = ?");
statement.setString(1, id);
resultSet = statement.executeQuery();
Ingredient ingredient = null;
if (resultSet.next()) {
ingredient = new Ingredient(
resultSet.getString("id"),
resultSet.getString("name"),
Ingredient.Type.valueof(resultSet.getString("type")));
}
return ingredient;
} catch (SQLException e) {
// 여기서는 무엇을 해야 할까?
} finally {
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
}
}
}
return null;
}위 코드 어딘가에는 식자재를 조회하는 쿼리가 있을 것이다.
하지만 찾기가 힘들다.
왜냐하면 DB 연결 생성, 명령문 생성, 그리고 연결과 명령문 및 결과 세트를 닫고
클린업하는 코드들로 쿼리 코드가 둘러싸여 있기 때문이다.
설상가상으로 연결이나 명령문 등의 객체를 생성할 때, 또는 쿼리를 수행할 때 얼마든지 많은 일들이 잘못될 수 있다.
따라서 SQLException 예외를 처리해야 한다.
하지만 이 처리도 문제의 해결 방법을 찾는데 도움이 될 수 도 있고 안될 수도 있다.
SQLException은 catch 블록으로 반드시 처리해야 하는 checked 예외다.
그러나 DB 연결 생성 실패나 작성 오류가 있는 쿼리와 같은 대부분의 흔한 문제들은 catch 블록에서 해결될 수 없다.
따라서 현재 메서드를 호출한 상위 코드로 예외 처리를 넘겨야 한다.
JdbcTemplate를 사용해서 데이터베이스 쿼리하기
@Override
public Ingredient findById(String id) {
return jdbcTemplate.queryForObject(
"select id, name, type from Ingredient where id=?",
this::mapRowToIngredient, id);
}
private Ingredient mapRowToIngredient(ResultSet rs, int rowNum)
throws SQLException {
return new Ingredient(
rs.getString("id"),
rs.getString("name"),
Ingredient.Type.valueOf(rs.getString("Type")));
}dbcTemplate 를 사용하지 않는 경우에 비해 훨씬 간단하다.
명령문이나 데이터베이스 연결 객체를 생성하는 코드가 아예 없다.
그리고 메서드의 실행이 끝난 후 그런 객체들을 클린업하는 코드 또한 없다.
또한, catch 블록에서 올바르게 처리할 수 없는 예외를 처리하는 코드도 없다.
쿼릴ㄹ 수행하고 그 결과를 Ingredient 객체로 생성하는 것에 초점을 두는 코드만 존재한다.
3.1.2 JdbcTemplate 사용하기
JDBC 환경 구성
pom.xml 에 스프링 부트의 JDBC 스타터 의존성을 빌드 명세에 추가
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>데이터베이스 의존성 추가
pom.xml 에 데이터를 저장하는 데이터 베이스 의존성을 빌드 명세에 추가 (H2 내장 데이터베이스)
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>H2 데이터베이스의 경우에 의존성 추가와 더불어 버전 정보도 추가해야 한다.
<properties>
<h2.version>1.4.169</h2.version>
</properties>JDBC Repository 정의하기
@Repository 애노테이션은 @Controller와 @Component 외에 스프링이 정의하는 몇 안 되는 스트레오타입 애노테이션 중 하나다.
즉, JdbcIngredientRepository 클래스에 @Repository를 지정하면 스프링 컴포넌트 검색에서 이 클래스를 자동으로 찾아서 스프링 애플리케이션 컨텍스트의 빈으로 생성된다.
스트레오타입 애노테이션이란?
스프링에서 주로 사용하는 역할 그룹을 나타내는 애노테이션이다.
예를 들어, @Component는 클래스를 빈으로 지정하는 클래스 수준의 애노테이션이다.
@Repository는 @Component가 특화된, 데이터 액세스 관련 애노테이션이다.
@Controller 역시 @Component가 특화된, 해당 클래스를 스프링 웹 MVC 컨트롤러로 지정하는 애노테이션이다.
JdbcIngredientRepository 빈이 생성되면 @Autowired를 통해 스프링이 해당 빈을 JdbcTemplate 에 주입한다.
JdbcIngredientRepository의 생성자에서는 jdbcTemplate 참조를 인스턴수 변수에 저장한다.
이 변수는 데이터베이스의 데이터를 쿼리하고 추가하기 위해 다른 메서드에서 사용된다.
- findAll() : jdbcTemplate.query(sql, RowMapper 인터페이스) 사용
- findById(String id) : jdbcTemplate.queryForObject(sql, RowMapper 인터페이스)
- save(Object object): jdbcTemplate.update(sql, 쿼리 매게변수에 저장할 값만 인자로 전달)
Ingredient repository가 해야 할 일을 IngredientRepository 인터페이스에 정의
public interface IngredientRepository {
Iterable<Ingredient> findAll();
Ingredient findById(String id);
Ingredient save(Ingredient ingredient);
}JdbcTemplate 사용하여 IngredientRepository 구현
@Repository
public class JdbcIngredientRepository implements IngredientRepository {
private JdbcTemplate jdbcTemplate;
@Autowired
public JdbcIngredientRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public Iterable<Ingredient> findAll() {
return jdbcTemplate.query(
"select id, name, type from Ingredient",
this::mapRowToIngredient);
}
@Override
public Ingredient findById(String id) {
return jdbcTemplate.queryForObject(
"select id, name, type from Ingredient where id=?",
this::mapRowToIngredient, id);
}
@Override
public Ingredient save(Ingredient ingredient) {
jdbcTemplate.update(
"insert into Ingredient (id, name, type) values (?, ?, ?)",
ingredient.getId(),
ingredient.getName(),
ingredient.getType().toString());
return ingredient;
}
}3.1.3 스키마 정의하고 데이터 추가하기
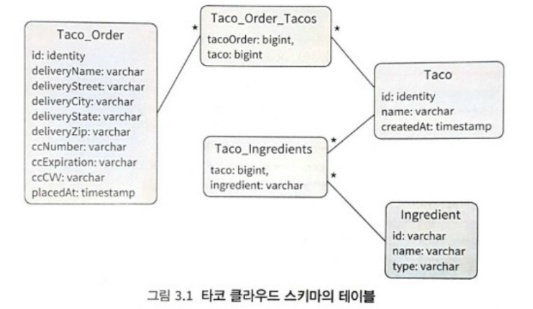
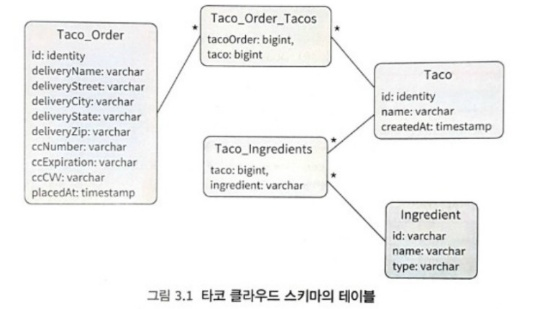
3.1.4 타코와 주문 데이터 추가하기
JdbcTemplate을 사용해서 데이터 저장하기
JdbcTemplate을 사용해서 데이터를 저장하는 방법은 다음 두 가지가 있다.
- update 사용
- SimpleJdbcInsert Wrapper 클래스 사용
먼저 update 메서드를 더 자세히 사용하는 방법을 알아보자.
앞의 식자재에서 했던 것처럼, 우선 타코와 주문 repository에서
Taco와 Order 객체를 저장하기 위한 인터페이스를 정의하자.
Taco 객체를 저장하는데 필요한 TacoRepository 인터페이스는 다음과 같다.
package tacos.data;
/*
* @USER JungHyun
* @DATE 2020-07-29
* @DESCRIPTION
*/
import tacos.Taco;
public interface TacoRepository {
Taco save(Taco taco);
}한편 사용자가 식자재를 선택하여 생성한 타코 디자인을 저장하려면 해당 타코와 연관된 식자재 데이터도 Taco_Ingredients 테이블에 저장해야 한다.
어떤 식자재를 해당 타코에 넣을지 알 수 있어야 하기 때문이다.
마찬가지로 주문을 저장하려면 해당 주문과 연관된 타코 데이터를 Taco_Order_Tacos 테이블에 저장해야 한다.
해당 주문에 어떤 타코들이 연관된 것인지 알 수 있어야 하기 때문이다.
이러한 이유로 식자재를 저장하는 것보다 타코와 주문을 저장하는 것이 조금 더 복잡하다.
TacoRepository의 구현체를 생성해보자.
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.PreparedStatementCreator;
import org.springframework.jdbc.core.PreparedStatementCreatorFactory;
import org.springframework.jdbc.support.GeneratedKeyHolder;
import org.springframework.jdbc.support.KeyHolder;
import org.springframework.stereotype.Repository;
import tacos.Ingredient;
import tacos.Taco;
import java.sql.Timestamp;
import java.sql.Types;
import java.util.Arrays;
import java.util.Date;
@Repository
public class JdbcTacoRepository implements TacoRepository {
private JdbcTemplate jdbc;
public JdbcTacoRepository(JdbcTemplate jdbc) {
this.jdbc = jdbc;
}
@Override
public Taco save(Taco taco) {
long tacoId = saveTacoInfo(taco);
taco.setId(tacoId);
for (Ingredient ingredient : taco.getIngredients()) {
saveIngredientToTaco(ingredient, tacoId);
}
return taco;
}
private long saveTacoInfo(Taco taco) {
taco.setCreatedAt(new Date());
PreparedStatementCreatorFactory preparedStatementCreatorFactory = new PreparedStatementCreatorFactory(
"insert into Taco (name, createdAt) values (?, ?)",
Types.VARCHAR, Types.TIMESTAMP
);
preparedStatementCreatorFactory.setReturnGeneratedKeys(true);
PreparedStatementCreator psc =
preparedStatementCreatorFactory.newPreparedStatementCreator(
Arrays.asList(
taco.getName(),
new Timestamp(taco.getCreatedAt().getTime())));
KeyHolder keyHolder = new GeneratedKeyHolder();
jdbc.update(psc, keyHolder);
return keyHolder.getKey().longValue();
}
private void saveIngredientToTaco(Ingredient ingredient, long tacoId) {
jdbc.update("insert into Taco_Ingredients (taco, ingredient) " + "values (?, ?)", tacoId, ingredient.getId());
}
}save 메서드에서는 우선 Taco 테이블에 각 식자재를 저장하는 saveTacoInfo 메서드를 호출한다.
그리고 이 메서드에서 반환된 타코 ID를 사용해서 타코와 식자재의 연관 정보를 저장하는 saveIngredientToTaco를 호출한다.
골치아픈 코드는 saveTacoInfo다.
Taco 테이블에 하나의 행을 추가할 때는 DB에서 생성되는 ID를 알아야 한다.
그래야만 각 식자재를 저장할 때 참조할 수 있기 때문이다.
식자재 데이터를 저장할 때 사용했던 update 메서드로는 생성된 타코 ID를 얻을 수 없으므로 여기서는 다른 update 메서드가 필요하다.
여기서 사용하는 update 메서드는 PreparedStatementCreator 객체와 KeyHolder 객체를 인자로 받는다.
생성된 타코 ID를 제공하는 것이 바로 이 KeyHolder다. 그러나 이것을 사용하기 위해서는PreparedStatementCreator도 생성해야 한다.
PreparedStatementCreator 객체의 생성은 간단하지 않다.
실행할 SQL 명령과 각 쿼리 매개변수의 타입을 인자로 전달하여 PreparedStatemenCreatorFactory 객체를 생성하는 것으로 시작한다.
그리고 이 객체의 newPreparedStatementCreator를 호출하며 이 때 PreparedStatementCreator를 생성하기 위해 쿼리 매개변수의 값을 인자로 전달한다.
이렇게 하여 PreparedStatementCreator 객체가 생성되면 이 객체와 KeyHolder 객체를 인자로 전달하여 update를 호출할 수 있다.
그리고 update의 실행이 끝나면 keyholder.getKey().longValue()의 연속 호출로 타코 ID를 반환할 수 있다.
그 다음에 save 메서드로 제어가 복귀된 후 saveIngredientToTaco를 호출하여
Taco 객체의 List에 저장된 각 Ingredient 객체를 반복 처리한다.
saveIngredientToTaco 메서드는 더 간단한 형태의 update를 사용해서 타코 ID와 Ingredient 객체 참조를 Taco_Ingredients 테이블에 저장한다.
SimpleJdbcInsert 사용해서 데이터 저장하기
SimpleJdbcInsert는 데이터를 DB에 더 쉽게 추가하기 위해 JdbcTemplate을 래핑한 객체다.
우선, OrderRepository를 구현하는 JdbcOrderRepository를 생성하자.
JdbcOrderRepository의 생성자는 Taco_Order와 Taco_Order_Tacos 테이블에 데이터를 추가하기 위해 두 개의 SimpleJdbcInsert 인스턴스를 생성한다.
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.simple.SimpleJdbcInsert;
import org.springframework.stereotype.Repository;
import tacos.Order;
import tacos.Taco;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Repository
public class JdbcOrderRepository implements OrderRepository {
private SimpleJdbcInsert orderInserter;
private SimpleJdbcInsert orderTacoInserter;
private ObjectMapper objectMapper;
@Autowired
public JdbcOrderRepository(JdbcTemplate jdbc) {
this.orderInserter = new SimpleJdbcInsert(jdbc)
.withTableName("Taco_Order")
.usingGeneratedKeyColumns("id");
this.orderTacoInserter = new SimpleJdbcInsert(jdbc)
.withTableName("Taco_Order_Tacos");
this.objectMapper = new ObjectMapper();
}
@Override
public Order save(Order order) {
order.setPlacedAt(new Date());
long orderId = saveOrderDetails(order);
order.setId(orderId);
List<Taco> tacos = order.getTacos();
for (Taco taco : tacos) {
saveTacoToOrder(taco, orderId);
}
return order;
}
private long saveOrderDetails(Order order) {
@SuppressWarnings("unchecked")
Map<String, Object> values = objectMapper.convertValue(order, Map.class);
values.put("placedAt", order.getPlacedAt());
long orderId = orderInserter.executeAndReturnKey(values)
.longValue();
return orderId;
}
private void saveTacoToOrder(Taco taco, long orderId) {
Map<String, Object> values = new HashMap<>();
values.put("tacoOrder", orderId);
values.put("taco", taco.getId());
orderTacoInserter.execute(values);
}
}save 메서드는 실제로 저장하는 일은 하지 않으며, Order 및 이것과 연관된 Taco 객체들을 저장하는 쿼리를 총괄한다.
그리고 실제로 저장하는 일은 saveOrderDetails()와 saveTacoToOrder()에 위임한다.
SimpleJdbcInsert는 데이터를 추가하는 두 개의 유용한 메서드인 execute()와 excuteAndReturnKey()를 갖고 있다.
두 메서드는 모두 Map<String, Object>를 인자로 받는다.
이 Map의 키는 데이터가 추가되는 테이블의 열 이름과 대응되며 Map의 값은 열에 추가되는 값이다.
Order 객체의 속성 값들을 Map의 항목으로 복사하는 것은 쉽다.
하지만 Order 객체는 여러 개의 속성을 가지며 속성 모두가 테이블의 열과 같은 이름을 갖는다.
따라서 saveOrderDetails() 에서는 ObjectMapper의 convertValue() 를 사용해서 Order를 Map으로 변환한다.
- @SessionAttributes
세션에 모델객체를 저장해두고 계속 보존 가능하다.
사용이 끝나면 즉 db 저장이 완료되면 세션을 제거한다.
sessionStatus.setComplete();
요약
- 스프링의 JdbcTemplate은 JDBC 작업을 굉장히 쉽게 해준다
- 데이터데이스가 생성해주는 ID 값을 알아야 할 때는 PreparedStatementCreator 와 KeyHolder 사용할 수 있다.
- 데이터 추가를 쉽게 실행할 때는 SimpleJdbcInsert 사용한다.
