- 이 장에서 배우는 내용
스프링 데이터(Spring Data)를 사용해서 JPA 선언하고 사용하기
3.2 JPA 를 사용해서 데이터 저장하고 사용하기
대표적인 스프링 데이터 프로젝트
- 스프링 데이터 JPA : 관계형 데이터베이스 JPA 퍼시스턴스
- 스프링 데이터 MongoDB: 몽고 문서형 데이터베이스의 퍼시스턴스
- 스프링 데이터 Neo4: Neo4j 그래프 데이터베이스의 퍼시스턴스
- 스프링 데이터 Redis: 레디스 Key-value 스토어 퍼시스턴스
- 스프링 데이터 cassandra: 카산드라 퍼시스턴스
3.2.1 스프링 데이터 JPA 프로젝트에 추가하기
JPA 스타터는 JPA 및 JPA 를 구현한 Hibernate 지원한다.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>3.2.2 도메인 객체에 어노테이션 추가하기
도메인 객체에 @Entity를 추가하여 JPA 개체(Entity) 로 선언한다.
- @Id : 이 속성이 데이터베이스의 개체를 고유하게 식별하게 한다.
- @GeneratedValue(strategy= GenerationType.AUTO) : id 는 디비가 자동으로 생성해주는 ID 값이 사용된다.
'hibernate_sequence'라는 키 생성 전용 테이블이 있다. - @NoArgsConstructor : 인자가 없는 생성자를 가지게 한다.
AccessLevel.PRIVATE : 클래스 외부에서는 사용 불가하다
force = true: 초기화 필요한 final 속성을 가지고 있으므로 설정 추가했다 - @Data: @RequiredArgsConstructor 를 생성하지만 @NoArgsConstructor 때문에 인자가 있는 생성자는 제거 된다
단, @RequiredArgsConstructor 를 따로 선언 하였으므로 인자 있는 생성자를 가질 수 있다. - @PrePersist : 엔티티 속성을 현재일자와 시간으로 설정한다.
- @Table : 테이블 명을 지정한다.
@Data
@RequiredArgsConstructor
@NoArgsConstructor(access = AccessLevel.PRIVATE, force = true)
@Entity
@Table(name = "ingredient")
public class Ingredient {
@Id
private final String id;
private final String name;
private final Type type;
public static enum Type {
WRAP, PROTEIN, VEGGIES, CHEESE, SAUCE
}
}
@Data
@Entity
@Table(name = "TACO")
public class Taco {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private Date createdAt;
@NotNull
@Size(min=5, message = "Name must be at least 5 characters long")
private String name;
@ManyToMany(targetEntity=Ingredient.class)
@Size(min=1, message = "You must choose at least 1 ingredient")
private List<Ingredient> ingredients;
@PrePersist
void createdAt() {
this.createdAt = new Date();
}
}3.2.3 JPA Repository 선언하기
JDBC 버전의 리퍼지토리에서는 리퍼지터리가 제공하는 메서드를 우리가 명시적으로 선언했다.
스프링 데이터에서는 CrudRepository 인터페이스를 확장할 수 있다.
CrudRepository 인터페이스는 CRUD 를 위한 많은 메서드가 선언되어 있다.
CrudRepository 인터페이스를 따로 구현해줄 필요가 없다. (커스터마이징 추가할 것이 아니라면)
애플리케이션이 시작될 때 스프링 데이터 JPA가 각 인터페이스 구현체들을 자동으로 생성해준다.
CrudRepository는 매개변수화 타입이다.
CrudRepository<리퍼지토리에 저장되는 개체 타입, 개체id속성>
public interface IngredientRepository extends CrudRepository<Ingredient, String> {}
public interface TacoRepository extends CrudRepository<Taco, Long> {}초기 데이터로드를 위한 부트스트랩 클래스 변경하기
초기데이터 로드가 필요하다면 아래와 같이 부트스트랩 클래스를 변경한다.
애플리케이션이 시작되면서 호출되는 dataLoader()에서 식자재 데이터를 미리 저장하게 한다.
@SpringBootApplication
public class TacoCloudApplication {
public static void main(String[] args) {
SpringApplication.run(TacoCloudApplication.class, args);
}
@Bean
public CommandLineRunner dataLoader(IngredientRepository repo) {
return new CommandLineRunner() {
@Override
public void run(String... args) throws Exception {
repo.save(new Ingredient("FLTO", "Flour Tortilla", Type.WRAP));
repo.save(new Ingredient("COTO", "Corn Tortilla", Type.WRAP));
}
};
}
}컨버터 변경하기
null 반환 될 때를 대비하여 Optional로 변경한다.
@Override
public Ingredient convert(String id) {
Optional<Ingredient> optionalIngredient = ingredientRepository.findById(id);
return optionalIngredient.isPresent() ? optionalIngredient.get() : null;
}3.2.4 JPA Repository 커스터마이징하기
본질적으로 스프링 데이터는 일종의 DSL(Domain Specific Language) 로 정의하고 있어 퍼시스트에 관한 내용이 메서드의 시그니처에 표현된다.
public interface OrderRepository extends CrudRepository<Order, Long> {
List<Order> findByDeliveryZip(String deliveryZip);
List<Order> readOrdersByDeliveryZipAndPlacedAtBetween(
String deliveryZip, Date StartDate, Date endDate
);
}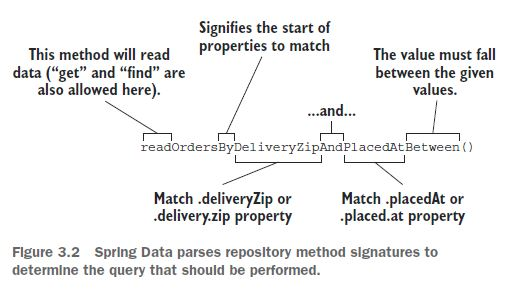
이 메서드 이름의 동사는 read다.
또한 스프링 데이터는 find, read, get이 하나 이상의 개체를 읽는 동의어임을 안다.
만일 일치하는 개체의 수를 의미하는 정수를 반환하는 메서드를 원한다면 count를 동사로 사용할 수도 있다.
한편 메서드의 처리 대상이 생략되더라도 Orders가 된다. 스프링 데이터는 처리 대상에서 대부분의 단어를 무시한다. 따라서 메서드 이름이 readPuppiesBy...일 경우에도 여전히 Order 개체를 찾는다.
Order가 CrudRepository 인터페이스의 매개변수로 지정된 타입이기 때문이다.
서술어는 메서드 이름의 By 단어 다음에 나오며 메서드 시그니처에서 가장 복잡한 부분이다.
위 경우에는 deliveryZip과 placedAt을 나타낸다.
deliveryZip 속성은 메서드의 첫 번째 인자로 전달된 값과 반드시 같아야 한다.
그리고 deliveryZip 값이 메서드의 마지막 두 개 인자로 전달된 값 사이에 포함되는 것이어야 함을 나타내는 것이 Between 키워드다.
묵시적으로 수행되는 Equals와 Between 연산 이외에도 아래 연산자를 사용할 수 있다.
- IsAfter, After, IsGreaterThan, GreaterThan
- IsGreaterThanEqual, GreaterThanEqual
- IsBefore, Before, IsLessThan, LessThan
- IsLessThanEqual, LessThanEqual
- IsBetween, Between
- IsNull. Null
- IsNotNull. NotNull
- IsIn, In
- IsNotIn, NotIn
- IsStartingWith, StartingWith, StartsWith
- IsEndingWith, EndingWith, EndsWith
- IsContaining, Containing, Contains
- IsLike, Like
- IsNotLike, NotLike
- IsTrue. True
- IsFalse, False
- Is, Equals
- IsNot, Not
- IgnoringCase, IgnoresCase간단한 쿼리는 이름 규칙이 유용하지만 더 복잡해질 경우에는 메소드에 이름만으로는 감당하기 힘들다.
이때는 어떤 이름이든 원하는 메소드 이름을 지정한 후 쿼리에 @Query 어노테이션을 지정한다.
@Query("Order o where o.deliveryCity='Seattle'")
List<Order> readOrdersDeliverydInSeattle();요약
- 스프링 데이터 JPA는 리퍼지터리 인터페이스를 작성하듯이 JPA 퍼시스턴스를 쉽게 해준다.
