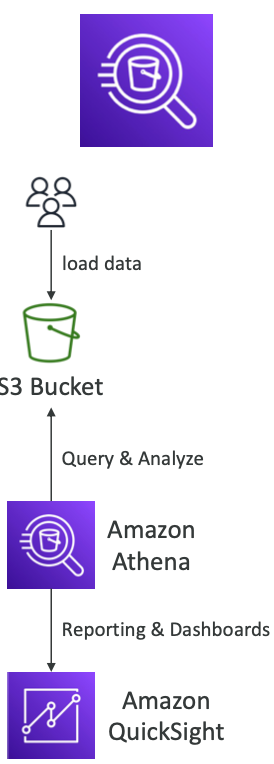
Amazon Athena는 Amazon S3에 저장된 데이터를 SQL로 분석할 수 있는 서버리스 쿼리 서비스입니다. 데이터 인프라를 관리할 필요 없이 즉시 사용 가능하며, 데이터 분석과 비즈니스 인텔리전스를 손쉽게 지원합니다.
1. Amazon Athena 개요
1. 주요 특징
- 서버리스 : 별도의 인프라 설정 없이 사용 가능
- SQL 지원 : 표준 SQL 언어를 사용하여 데이터를 쿼리(Presto 기반)
- 다양한 데이터 형식 지원 : CSV, JSON, ORC, Avro, Parquet 등
- 비용 구조 : 스캔한 데이터 양에 따라 과금 (5달러 / 1TB 스캔)
2. 활용 사례
1. 비즈니스 분석 및 보고
Amazon QuickSight와 연동하여 대시보드 및 리포트 생성
2. 로그 분석
VPC Flow Logs, ELB Logs, CloudTrail Logs 등 분석
3. 데이터 분석
대량의 데이터 세트의 SQL 쿼리 및 분석
Amazon Athena는 간편한 설정과 강력한 데이터 분석 기능을 통해 비즈니스 인텔리전스, 로그 분석, 대시보드 구축 등에 최적화된 솔루션입니다.
2. Amazon Athena 성능 개선 방법
Amazon Athena의 성능을 최적화하고 비용을 절감하려면 다음의 전략을 활용할 수 있습니다. 이를 통해 더 빠른 쿼리 처리와 효율적인 데이터 스캔을 구현할 수 있습니다.
1. 열 형식 데이터 사용
- Apache Parquet 또는 ORC 형식으로 데이터를 저장하면 스캔해야 할 데이터 양이 줄어들어 비용 절감 가능
- 열 기반 데이터 형식은 대규모 데이터 세트에서 쿼리 성능을 크게 향상시킴
2. AWS Glue로 데이터 변환
- AWS Glue를 사용하여 데이터를 Parquet 또는 ORC 형식으로 변환
- Glue는 데이터 카탈로그를 자동 생성하여 Athena와 쉽게 통합 가능
3. 데이터 압축
- 데이터를 bzip2, gzip, lz4, snappy, zlib, zstd와 같은 압축 형식으로 저장하면 데이터 스캔 양을 줄이고 쿼리 속도를 높일 수 있음
- 압축은 저장 공간을 줄이고 네트워크 대역폭을 효율적으로 활용
4. 데이터 파티셔닝
S3 경로에서 가상 열로 데이터를 파티셔닝하여 쿼리 효율성 향상
- 파티션 구조
s3://yourBucket/pathToTable/<PARTITION_COLUMN_NAME>=<VALUE>/- 예시
s3://athena-examples/flight/parquet/year=1991/month=1/day=1/5. 파일 크기 최적화
- 파일 크기를 128MB 이상으로 설정하여 처리 오버헤드 최소화
- 작은 파일이 많은 경우 쿼리 처리 시간이 증가하므로, 데이터를 병합하여 최적 크기를 유지
3. Amazon Athena – Federated Query 개요
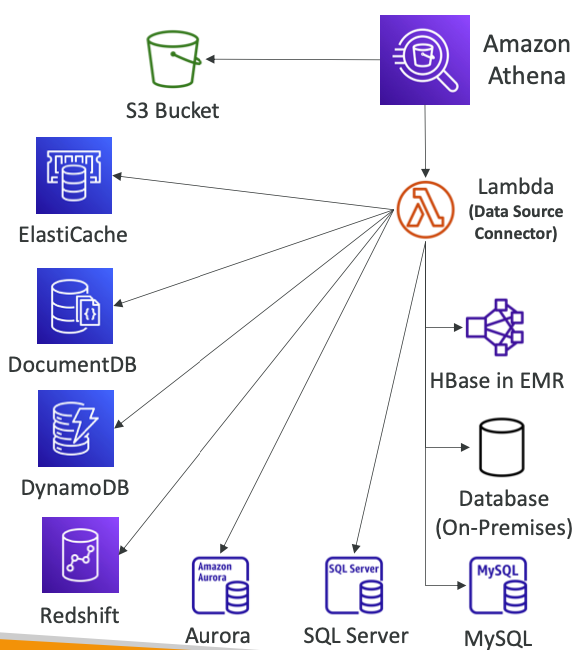
Amazon Athena Federated Query는 다양한 데이터 소스에 걸쳐 단일 SQL 쿼리를 실행할 수 있는 기능입니다. 이를 통해 관계형, 비관계형, 객체 저장소, 그리고 사용자 정의 데이터 소스(AWS 또는 온프레미스)에 있는 데이터를 통합적으로 분석할 수 있습니다.
1. 다양한 데이터 소스 지원
- 관계형 데이터베이스: RDS, Aurora, MySQL, PostgreSQL 등
- 비관계형 데이터베이스: DynamoDB
- 로그 서비스: CloudWatch Logs
- 사용자 정의 데이터 소스: 온프레미스 데이터베이스 등
2. 데이터 소스 커넥터
AWS Lambda에서 실행되는 데이터 소스 커넥터를 통해 다양한 데이터 소스와 통합
커넥터는 Amazon 제공 또는 사용자 정의로 구성 가능
3. 쿼리 결과 저장
쿼리 결과는 Amazon S3에 저장되어 재활용 가능

아는 만큼 보인다