[spring] Spring 에서 Elastic Search 활용 (1) 글의 리팩토링을 다루는 포스팅입니다.
스펙
Spring Boot 3.0.6
Spring Core 6.0.8
Spring Data Elasticsearch 4.2.2
Elastic Search 7.10.2
implementation 'org.springframework.data:spring-data-elasticsearch:4.2.2'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'되돌아보기
@Builder
@Getter
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "members")
public class MemberDocument {
@Id
private Long id;
private String nickname;
private String profileUrl;
...
}@Repository
public interface MemberSearchRepository extends ElasticsearchRepository<MemberDocument, Long> {
Optional<MemberDocument> findById(Long id);
...
}@Service
@RequiredArgsConstructor
public class MemberSearchService {
private final MemberSearchRepository memberSearchRepository;
private final ElasticsearchOperations elasticsearchOperations;
public void save(Member member) {
elasticsearchOperations.save(MemberDocument.from(member));
}
public void update(Member member) {
MemberDocument document = memberSearchRepository.findById(member.getId())
.orElseThrow(RuntimeException::new);
document.updateProfileUrl(member.getProfilePath());
Document updateDocument = elasticsearchOperations.getElasticsearchConverter().mapObject(document);
elasticsearchOperations.update(UpdateQuery.builder(document.getId().toString())
.withDocument(updateDocument)
.withDocAsUpsert(true)
.build(), IndexCoordinates.of("members"));
}💡 위 코드의 개선점
- Service 단에서 쿼리를 생성하고 날리는 역할까지 담당한다.
- 코드 가독성의 문제
- 책임이 명확히 분리되지 않음
➡️ 좀 더 객체지향적으로 개선해보자- 업데이트 과정
MemberDocument객체는elasticsearch.core.document.Document로 변환된다.Document와 도큐먼트 아이디, 도큐먼트에 설정해준 indexName을 토대로 쿼리를 생성한다.- elasticsearch에 명령어를 날린다.
1. BaseDocument 만들기
ElasticsearchRepository 의 도메인은 공통으로 가질 BaseDocument 를 만든다.
ElasticsearchRepository 의 도메인이어야 이용할 수 있는 메서드를 만들기 위함이다.
@SuperBuilder
@Getter
@AllArgsConstructor
@NoArgsConstructor
public class BaseDocument {
@Id
private Long id;
}2. BaseDocument를 상속하도록 도메인 수정
ElasticsearchRepository 의 도메인이 BaseDocument 를 상속하도록 한다.
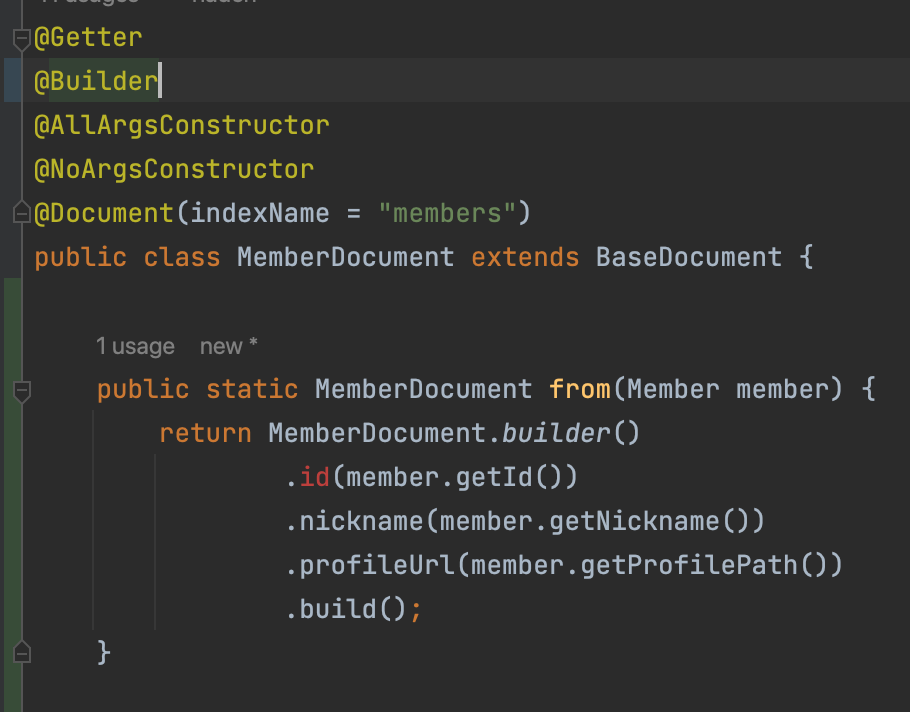
@SuperBuilder
@Getter
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "members")
public class MemberDocument extends BaseDocument {
private String nickname;
private String profileUrl;
}- (참고)
@SuperBuilder는 부모 객체가 가진 필드까지 빌더 패턴으로 객체를 생성할 수 있게 하는 어노테이션이다. 이때, 부모 객체에도@SuperBuilder어노테이션을 달아주어야 한다.@Builder로는BaseDocument의 id 필드가 빌드되지 않음
3. ElasticSearchClient 생성
ElasticSearchClient 는 ElasticsearchRepository 의 도메인 객체를 받아 쿼리를 생성한다.
@Component
@RequiredArgsConstructor
public class ElasticSearchClient<T extends BaseDocument> {
private final ElasticsearchOperations elasticsearchOperations;
public void save(T document) {
elasticsearchOperations.save(document);
}
public void update(T document) {
Document esDocument = elasticsearchOperations.getElasticsearchConverter().mapObject(document);
UpdateQuery updateQuery = UpdateQuery.builder(esDocument.getId())
.withDocument(esDocument)
.withDocAsUpsert(true)
.build();
elasticsearchOperations.update(updateQuery, IndexCoordinates.of(esDocument.getIndex()));
}
}- Generic 을 활용해 객체를 오직
ElasticsearchRepository의 도메인만으로 한정한다. - 쿼리 생성 및 오퍼레이션이
ElasticSearchClient내에서 이뤄진다. - 추가로 변환된
elasticsearch.core.document.Document객체에서 index와 id를 추출할 수 있어 수정했다.
4. Service 코드 수정
@Service
@RequiredArgsConstructor
public class MemberSearchService {
private final MemberSearchRepository memberSearchRepository;
private final ElasticSearchClient elasticSearchClient;
public void save(Member member) {
elasticSearchClient.save(MemberDocument.from(member));
}
public void update(Member member) {
MemberDocument memberDocument = memberSearchRepository.findById(member.getId())
.orElseThrow(RuntimeException::new);
memberDocument.updateProfileUrl(member.getProfilePath());
elasticSearchClient.update(memberDocument);
}
...
}- 이제 서비스는 비즈니스 로직만을 수행하게 코드를 작성할 수 있다.
결과
책임을 분리하며 코드를 작성하면서, 훨씬 비즈니스 로직이 간결해졌다.
기존 코드는 내가 봐도 한참을 살펴봐야 했다면, 리팩토링한 로직은 한눈에 무슨 의미인지 들어온다.
또한 ElasticSearch 관련 정책이 바뀌어도 ElasticSearchClient 수정하면 된다는 것이 큰 장점이다. 기존에는 서비스 로직을 하나하나 확인하며 수정해야 했을 것이다.
