스펙
Spring Boot 3.0.6
Spring Core 6.0.8
Spring Data Elasticsearch 4.2.2
Elastic Search 7.10.2
Elastic Search
- 역인덱스 구조로 데이터를 저장한다.
- JSON 형식으로 사용자와 소통한다.
- 간결하고 개발자들이 다루기 편한 구조로 다른 클라이언트 프로그램과 연동이 쉽다.
- Elastic Search 자체에서도 REST API를 지원한다.
- 검색에 서버를 거치지 않아도 되어서 용이함
역인덱스 구조
- 관계형 DB는 도큐먼트에 대해 텍스트를 저장한다.

- 데이터가 늘어날수록 검색해야 할 대상이 늘어나 시간도 오래 걸리고, row 안의 내용을 모두 읽어야 하기 때문에 기본적으로 속도가 느리다.
- like 문을 활용해 모든 데이터를 탐색해야 한다.

- 역인덱스 구조는 키워드에 대한 도큐먼트를 저장하는 것을 의미한다.
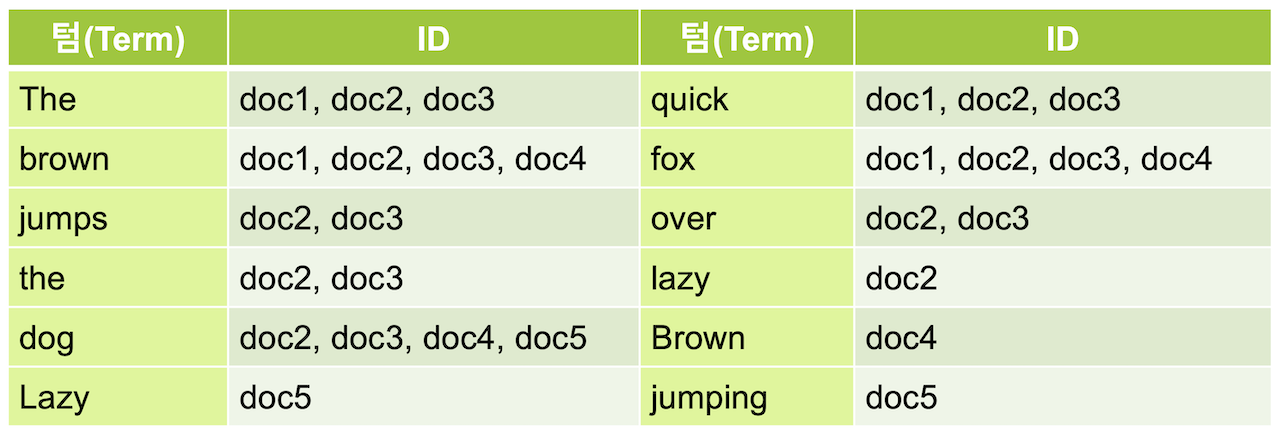
- 키워드에 대한 도큐먼트 리스트를 바로 가져올 수 있다.

- 키워드에 대한 도큐먼트 리스트를 바로 가져올 수 있다.
Spring Data Elastic Search
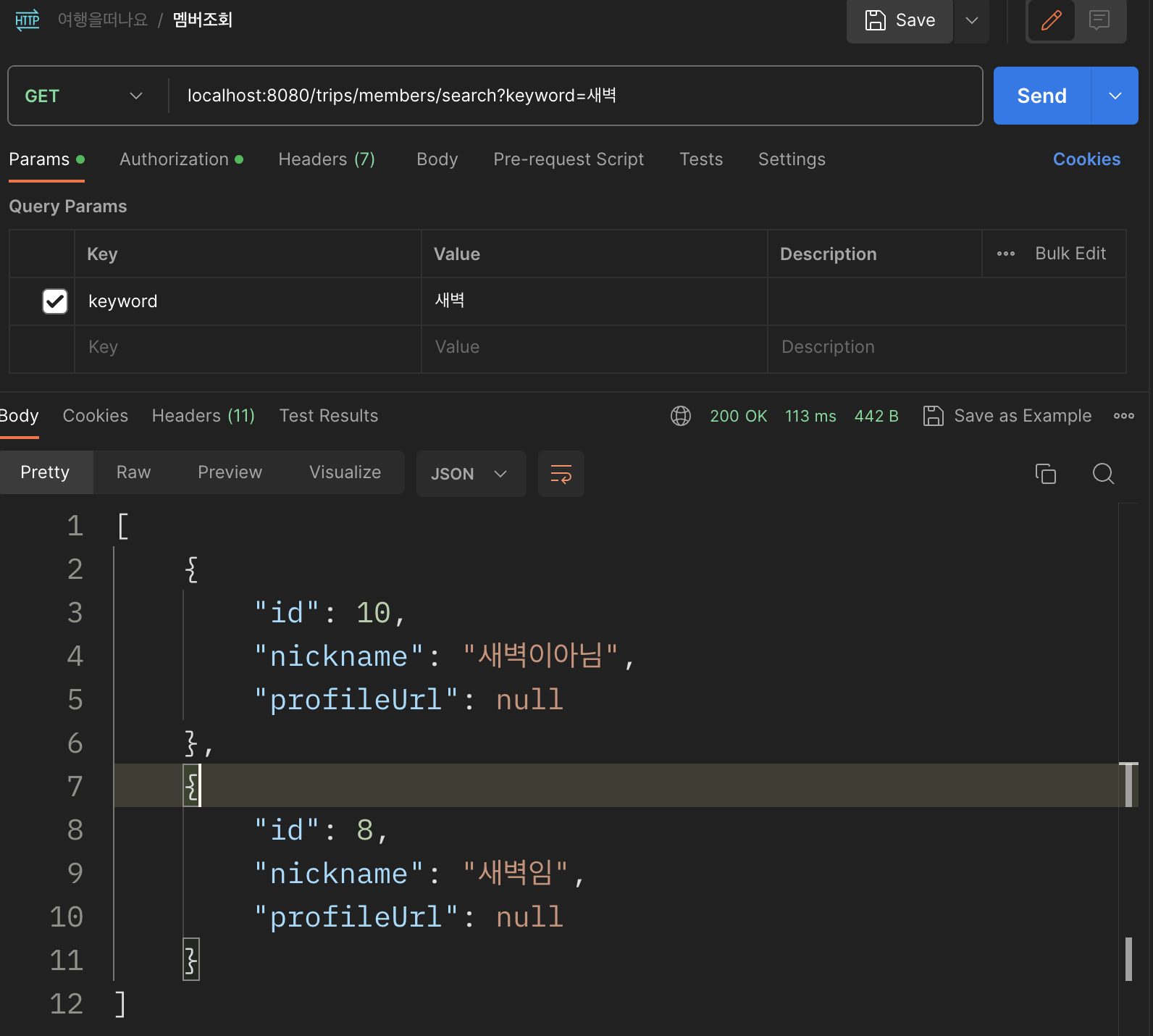
서비스 상황은 전체 유저를 대상으로 닉네임으로 검색하는 상황이다.
데이터가 많으므로 es를 활용해보자
implementation 'org.springframework.data:spring-data-elasticsearch:4.2.2'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'gradle에 spring data es를 임플한다.
spring data es는 버전이 변경될 때마다 사용하는 메서드가 확확 바뀐다.
반드시 아래 표를 보고 자신의 es 버전과 spring 버전에 맞춰 spring data es 버전을 정해야 한다.
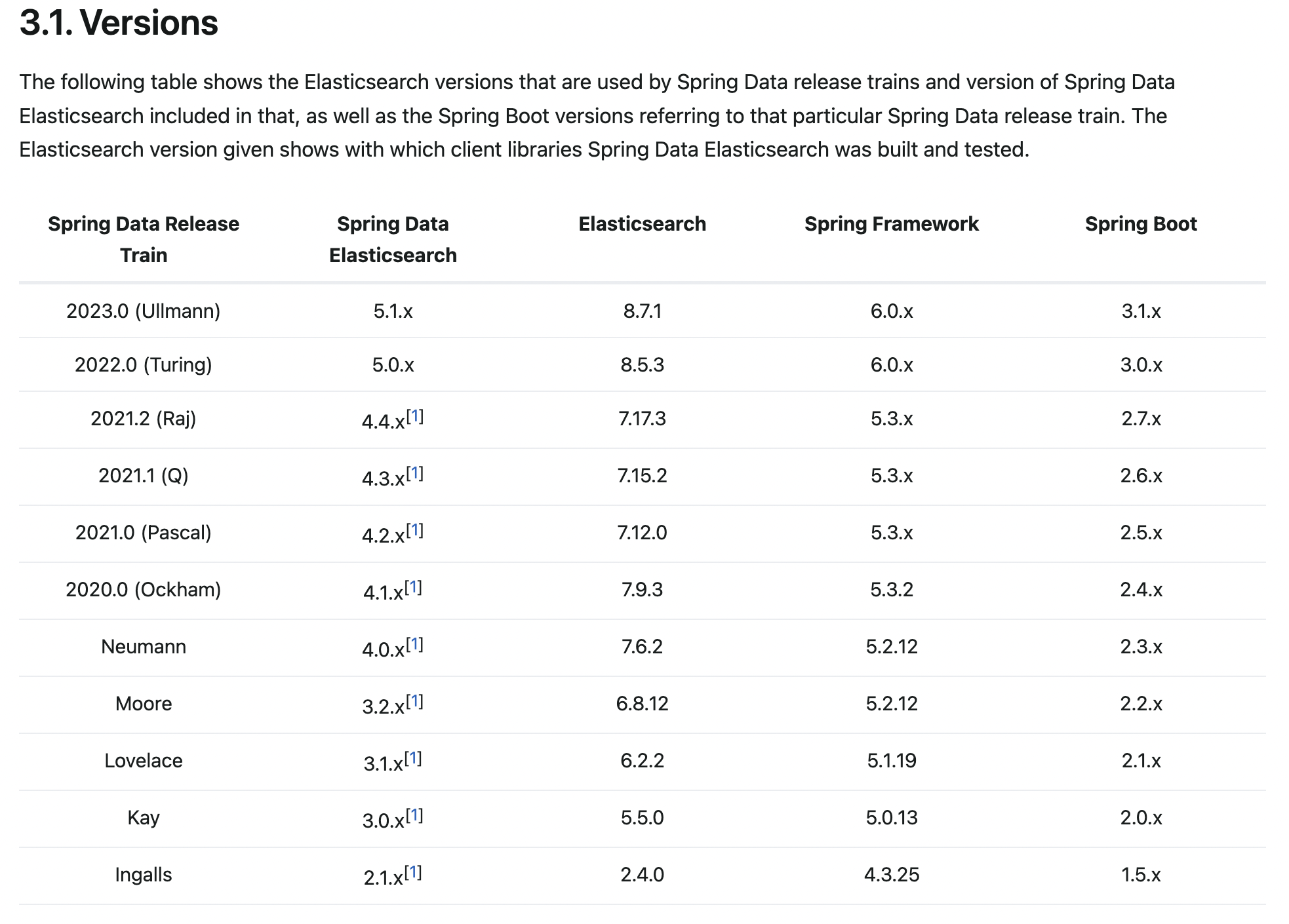
나는 es 버전이 7.10.x 이고, spring boot가 3.0.6, spring core가 6.0.8이므로 4.2.2 버전을 적용했다.
0. Elastic Search Configuration
es를 사용하겠다는 걸 스프링에게 알려주고 연결 정보를 추가한다.
-
application.ymlspring: data: elasticsearch: repositories: enabled: true url: localhost:9200- es 에 ElasticSearchRepository 를 활용하겠다고 선언했다.
ElasticSearchRepository는 쿼리를 일부 자동화해주고, 직접 생성한 쿼리를 날릴때도 오퍼레이션을 간단하게 할 수 있기 때문에 사용한다.
- es 에 ElasticSearchRepository 를 활용하겠다고 선언했다.
-
ElasticSearchConfig.java
@Configuration
public class ElasticSearchConfig {
@Value("${spring.data.elasticsearch.url}")
String url;
@Override
public RestHighLevelClient elasticsearchClient() {
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo(url)
.build();
return RestClients.create(clientConfiguration).rest();
}
}- 나의 es는 7.10 버전이므로
RestHighLevelClient를 이용했다.- es가 7.15 버전 이상이라면 JavaAPIClient 를 활용해야 한다.
1. Document 객체 생성
도큐먼트는 검색했을 때 보여야 할 데이터의 집합이라고 생각하면 이해하기 쉽다.
나의 경우에는 memberId, 닉네임, 프로필 url이다.
@Builder
@Getter
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "members")
public class MemberDocument {
@Id
private Long id;
private String nickname;
private String profileUrl;
public static MemberDocument from(Member member) {
return MemberDocument.builder()
.id(member.getId())
.nickname(member.getNickname())
.profileUrl(member.getProfilePath())
.build();
}
}@Document(indexName = "members")es의 도큐먼트임을 선언했다.- index는 도큐먼트의 논리적인 집합을 의미한다 .
- 여기에서는
Member에 대한 도큐먼트이므로 members로 했다.
Member에 대한 정보를 바탕으로MemberDocument를 생성하므로 정적 팩토리 메서드를 만들었다.@Id는 도큐먼트에 대한 식별값이므로 member 객체의 아이디로 했다.- 이 아이디가 도큐먼트를 수정, 삭제할 때도 활용되므로 적당한 값을 골라야 한다.
참고로 Member 클래스는 아래와 같다.
public class Member {
private Long id;
private String nickname;
private String profilePath;
}2. Document 저장
생성한 도큐먼트를 elastic search에 저장한다.
우리는 저장만 하면, es가 알아서 term 단위로 잘라 역인덱스 구조로 변환해줄것이다.
@Service
@RequiredArgsConstructor
public class MemberSearchService {
private final ElasticsearchOperations elasticsearchOperations;
public void save(Member member) {
elasticsearchOperations.save(MemberDocument.from(member));
}
}ElasticsearchOperations.save()MemberDocument객체를 저장한다.- 참고로 spring data es는 저장, 수정, 삭제는 자동화해주지 않는다.
3. Document 조회하기
키워드를 통해 es 내 도큐먼트를 조회해보자.
원래는 쿼리 오퍼레이션을 따로 만들어야 하지만, spring data elastic search 를 활용해 좀 더 간결하게 할 수 있다.
@Repository
public interface MemberSearchRepository extends ElasticsearchRepository<MemberDocument, Long> {
Optional<MemberDocument> findById(Long id);
List<MemberDocument> findByNicknameContainsIgnoreCase(String nickname);
@Query("{\"bool\": { \"must\": [ \n" +
" {\"wildcard\": {\"nickname\": \"*?0*\"}}]}}")
Page<MemberDocument> findByNicknameContainsIgnoreCase(String nickname, Pageable pageable);
}ElasticsearchRepository<MemberDocument, Long>Document 객체, 객체 아이디로ElasticsearchRepository의 데이터 타입을 지정해준다.findById(Long id)에 대한 함수를 직접 명시해야 한다.CrudRepository를 상속한 JPA 와의 차이점이다. findById 를 따로 명시 안해도 된다. 아래와 같이 이미 구현되어 있기 때문이다.
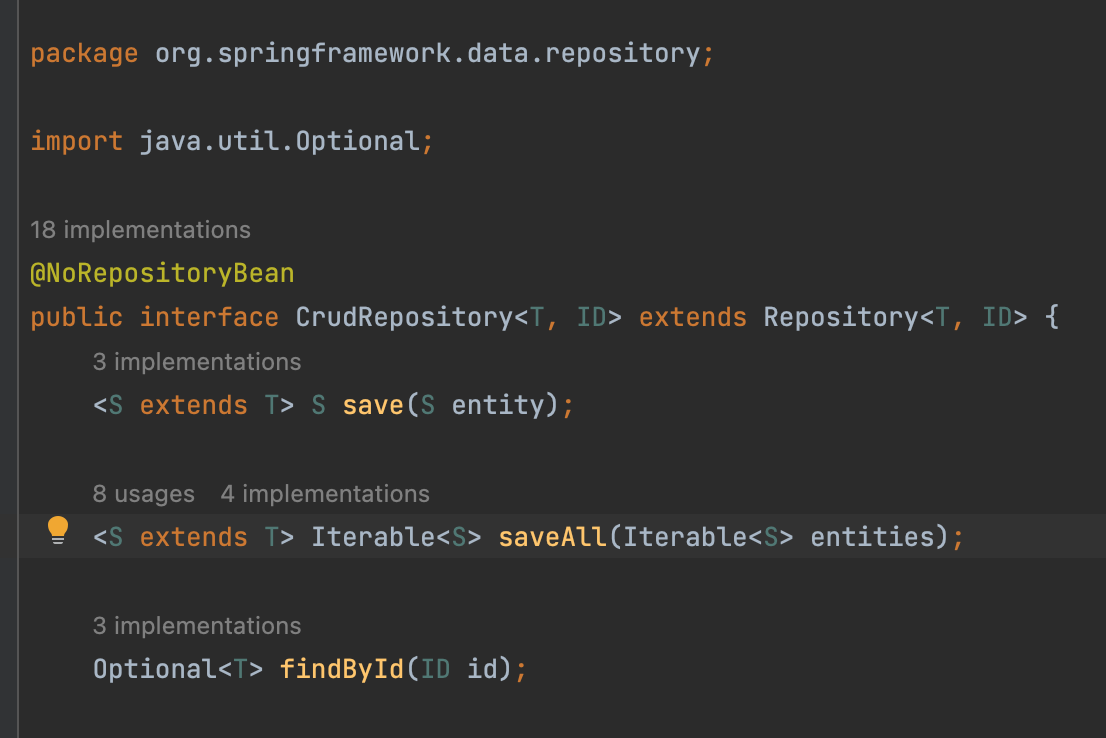
Page<MemberDocument>Pageable을 활용할 수 있다.ElasticsearchRepository는PagingAndSortingRepository을 상속했기 때문이다.
@Query("query string")쿼리를 직접 작성하고 싶다면@Query어노테이션을 활용한다."nickname": "*?0*"에서?0은 첫번째 파라미터를 의미한다.- es 가이드북
es 쿼리 가이드 (공식)
참고로 서비스 코드는 다음과 같다.
조회 유저와 동일한 유저는 검색에서 제외되게 하기 위해 따로 필터링했다.
이를 es 쿼리 filter 조건에 추가할 수도 있을 것 같다.
@Service
@RequiredArgsConstructor
public class MemberSearchService {
...
private final MemberSearchRepository memberSearchRepository;
public List<MemberDto> searchAddableMembers(String keyword, Member member) {
return memberSearchRepository.findByNicknameContainsIgnoreCase(keyword).stream()
.filter(memberDocument -> !Objects.equals(memberDocument.getId(), member.getId()))
.map(MemberDto::of)
.collect(Collectors.toList());
}
...
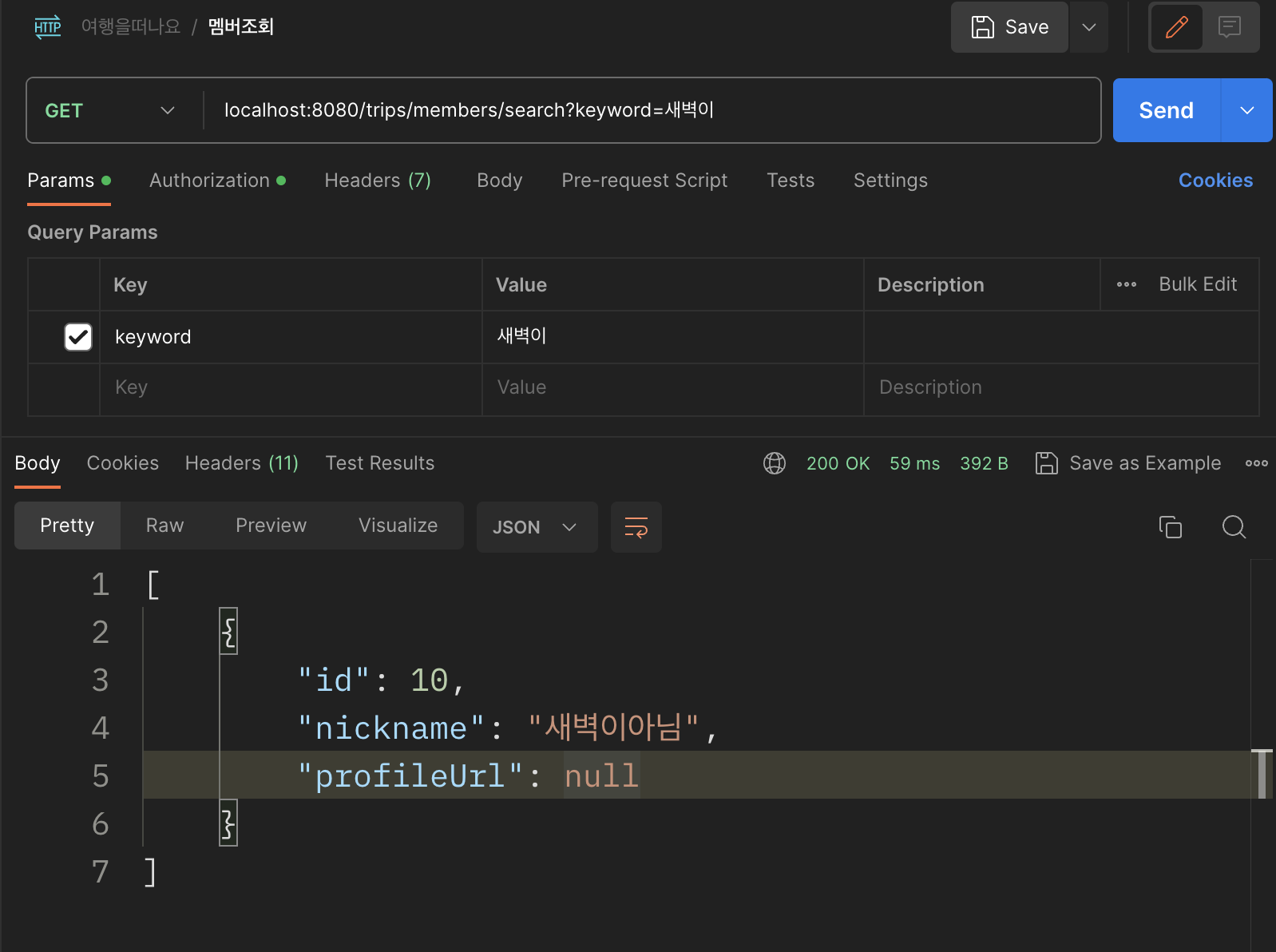
}4. Document 수정하기
만약 서비스 상황에서 도큐먼트를 수정해야 할 일이 발생한다면 수정된 도큐먼트 객체를 ElasticsearchOperations 를 통해 업데이트한다.
@Service
@RequiredArgsConstructor
public class MemberSearchService {
private final ElasticsearchOperations elasticsearchOperations;
...
public void update(Member member) {
MemberDocument document = memberSearchRepository.findById(member.getId())
.orElseThrow(RuntimeException::new);
document.updateProfileUrl(member.getProfilePath());
Document updateDocument = elasticsearchOperations.getElasticsearchConverter().mapObject(document);
elasticsearchOperations.update(UpdateQuery.builder(document.getId().toString())
.withDocument(updateDocument)
.withDocAsUpsert(true)
.build(), IndexCoordinates.of("members"));
}memberSearchRepository.findById()es 레포지토리에서 도큐먼트 객체를 조회해 업데이트 한다.elasticsearchOperations에 내장된 converter를 통해 도큐먼트 객체를 spring-data-es의Document객체로 만든다.withDocAsUpsert(true)도큐먼트 고유값이 중복된다면 업데이트 처리해야한다.IndexCoordinates.of("members")MemberDocument객체에 명시했던indexName을 인자로 넘겨주어야 한다.
결과
api 호출 결과 아래와 같이 잘 동작했다.
이 구조에는 문제점이 하나 있는데 MemberSearchService 가 elasticsearchOperations 을 직접 활용해 쿼리를 생성하고 날리는 역할까지 담당하고 있다는 것이다.
만약 elasticsearchOperations 클래스 메서드가 달라지거나 문제가 생긴다면 서비스 단을 하나하나 확인해서 수정해야할 것이다.
또 아마도 내가 아닌 사람이 처음 마주했을 때, 현재의 코드는 이해하기 쉽지 않을 것 같다.
es와 직접 소통하고 있는 이 부분을 별도의 레이어로 분리하면 좀 더 객체지향에 걸맞고 명확한 코드가 될 수 있을 것이다.
그래서 다음 포스팅에는 서비스와 es간 구조를 어떻게 개선했는지, 그 시행착오와 생각들을 정리해보려고 한다.

정리해주신 내용 잘 보고 갑니다.