📌3/8 영상 강의 EDA 웹데이터 3~6
예제1-2 네이버 금융
urllib.request
웹주소(url)에 접근 할때는 urllib의 request모듈이 필요하다
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
response = urlopen(url)
#response.status -> HTTP 상태 코드(200:성공, 5xx:불가능, 확인해야함)
soup = BeautifulSoup(response, "html.parser")
print(soup.prettify()) #코드문을 예쁘게 정리해준다
- import requests
response = requests.get(url) 혹은 request.post(url)
- from urllib.request.Request import urlopen
response = urlopen(url)
두 모듈은 같은 역할을 한다. 둘 중 편한거 쓰면된다
태그 찾기(id, class)
# soup.find_all("li", "on") # li 태그의 on 클래스
# id => #
# class => .
exchangeList = soup.select("#exchangeList > li") # id=exchangeList 바로 아래 있는 li 가져와줘class 사이의 공백
exchangeList[0].select_one(".head_info point_up > .blind").text
⬇️
exchangeList[0].select_one(".head_info.point_up > .blind").text
# class 사이 공백은 제거하고 .으로 이어붙인다 (공백이 있으면 class를 두개로 인식)환율 데이터 시각화
# 4개 데이터 수집
exchange_datas = []
baseUrl = "https://finance.naver.com"
for item in exchangeList:
data = {
"title" : item.select_one(".h_lst").text,
"exchange" : item.select_one(".value").text,
"change" : item.select_one(".change").text,
"updown" : item.select_one(".head_info.point_up > .blind").text,🔥
"link" : baseUrl + item.select_one("a").get("href")
}
exchange_datas.append(data)
exchange_datas
df = pd.DataFrame(exchange_datas)
df.to_excel("./naverfinance.xlsx", encoding="utf-8") # excel 저장
df.head()
🔥"updown" 에서 에러가 난다. 상승, 하락 데이터를 가져오지 못한다 왜죠..
예제2. 여명의 눈동자
위키백과 문서 정보 가져오기, 등장인물에 접근하기
format(), quote( )
한글을 url로 인코딩
웹주소는 UTF-8로 인코딩되어야 한다
import urllib
from urllib.request import urlopen, Request # request모듈 안에있는 Request기능 사용
html = "https://ko.wikipedia.org/wiki/{search_wards}"
# https://ko.wikipedia.org/wiki/여명의_눈동자 , 한글 주소 부분을 {}에 안에 변수로 한다
req = Request(html.format(search_wards=urllib.parse.quote("여명의 눈동자"))) # 한글을 url로 인코딩
response = urlopen(req)
soup = BeautifulSoup(response, "html.parser")
print(soup. prettify())url decoding 구글링 해보기 . 포맷팅 검색해보기
Python List 데이터형
- list형은 대괄호로 생성
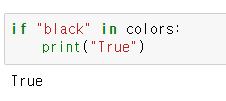
- in 명령으로 조건문(if)에 적용
- append : list 제일 뒤에 추가
- pop : 제일 뒤부터 자료를 하나씩 삭제
- extend : 제일 뒤에 자료 추가
- remove : 자료를 삭제
- 슬라이싱 : [n : m ] n번째 부터 m-1까지
- insert : 원하는 위치에 자료를 삽입
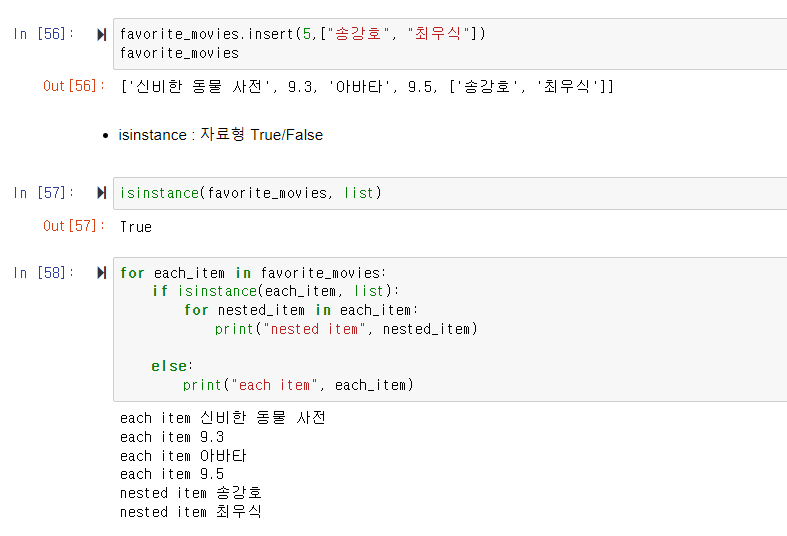
- list안에 list
- isinstance : 자료형 타입 True/False
2. 시카고 맛집 데이터 분석
최종목표
총 50개 페이지에서 각 가게의 정보를 가져온다
- 가게 이름
- 대표 메뉴
- 대표 메뉴의 가격
- 가게 주소
웹페이지 html 가져오기
from urllib.request import Request, urlopen
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
ua = UserAgent()
# req = Request(url, headers={"User Agent":ua.ie}) # 이 방법으로 했을시 오류남.. 동기님이 알려준 해결방법 -> # headers={'User-Agnet':'Mozilla/5.0'})
req = Request(url, headers={"User-Agent":"Chrome"}) # error 403 뜨면서 페이지 막혔을때 사용(윗줄과 동일함)
html = urlopen(req)
soup = BeautifulSoup(html, "html.parser")
print(soup.prettify())re.split()

from urllib.parse import urljoin
url_base = "https://www.chicagomag.com/"
가게에 대한 정보 추출
# 필요한 내용을 담을 빈 리스트
# 리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all("div", "sammy") # soup.select(".sammy")
for item in list_soup:
rank.append(item.find(class_="sammyRank").get_text())
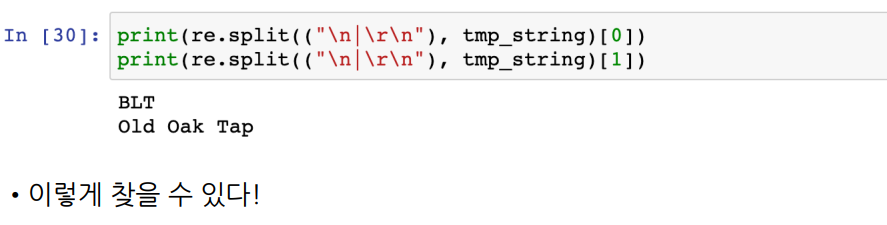
tmp_string = item.find(class_="sammyListing").get_text()
main_menu.append(re.split(("\n|\r\n"), tmp_string)[0])
cafe_name.append(re.split(("\n|\r\n"), tmp_string)[1])
url_add.append(urljoin(url_base, item.find("a")["href"]))
df = pd.read_csv("../data/03. best_sandwiches_list_chicago.csv", index_col=0) #저장
df.tail()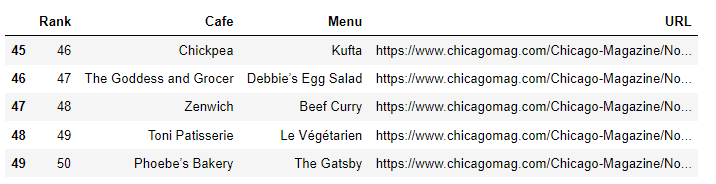
Regular Expression
1. Regular Expression 기초
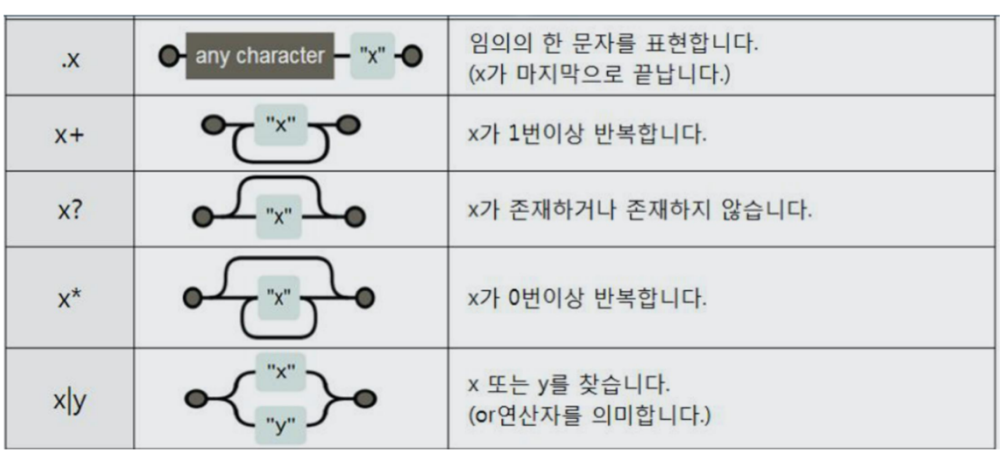
2. 시카고 맛집 데이터에 적용하기 (주소 찾기)
tqdm
작업이 얼마나 진행됐는지 bar 형태로 보여준다. 소요 시간도 알려준다
from tqdm import tqdm
price = []
address = []
for idx, row in tqdm(df.iterrows()):
req = Request(row["URL"], headers={"User-Agent":"Chrome"}) # "User-Agent":ua.ie
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(",.", gettings)[0]
tmp = re.search("\$\d+\.(\d)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp) + 2:])
print(idx)DataFrame에 주소 추가
df["Price"] = price
df["Address"] = address
df = df.loc[:, ["Rank", "Cafe", "Menu", "Price", "Address"]]
df.set_index("Rank", inplace=True)
df.head()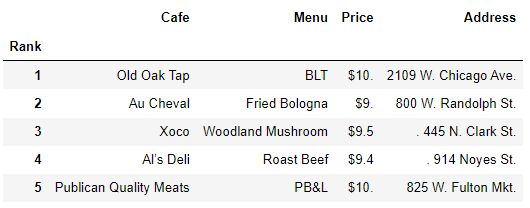
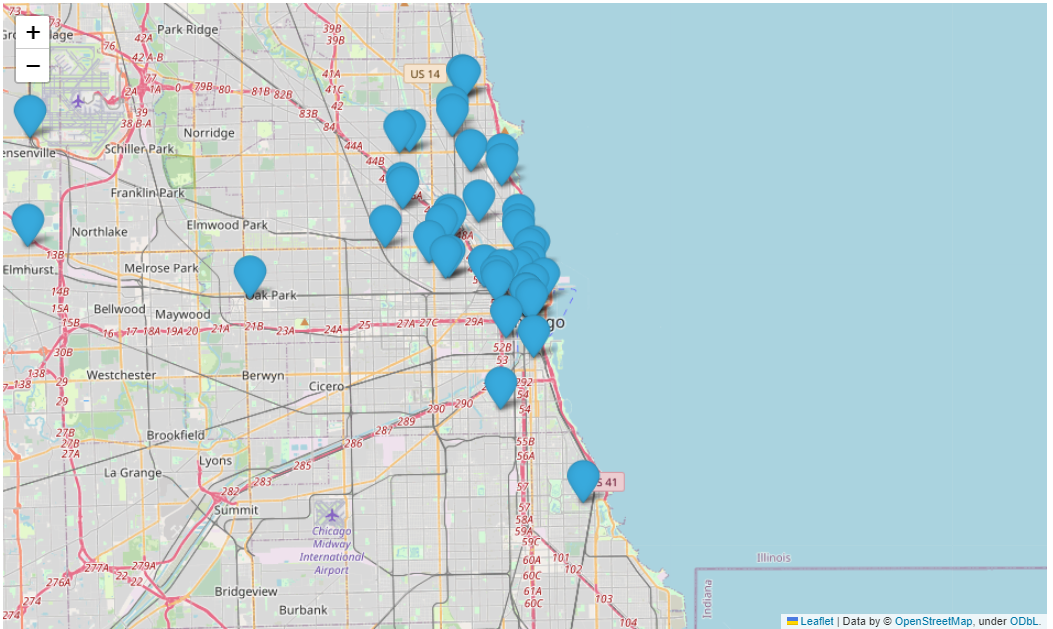
시카고 맛집 데이터 지도 시각화(folium)
1.googlemap api
gmaps_key = "개인 key 입력"
gmaps = googlemaps.Client(key=gmaps_key)2. 위도, 경도 찾기
lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
if not row["Address"] == "Multiple locations": # 지점이 여러개면 패쓰
target_nama = row["Address"] + ", Chicago" # 지도에서 검색 유리하게 시카고 붙여줌
# print(target_nama)
gmaps_output = gmaps.geocode(target_nama)
location_output = gmaps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
else:
lat.append(np.nan)
lng.append(np.nan)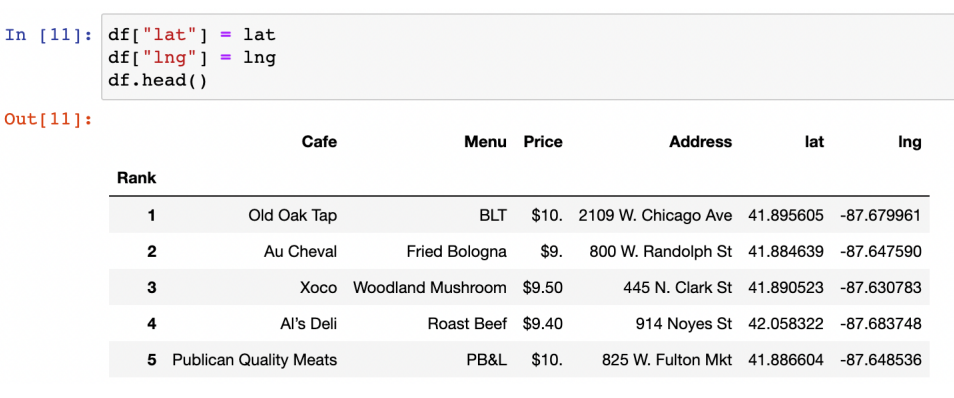
3. 지도에 Marker 표시
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple locations":
folium.Marker(
location=[row["lat"], row["lng"]],
popup=row["Cafe"],
tootip=row["Menu"],
icon=folium.Icon(
icone="house",
prefix="fa"
)
).add_to(mapping)
mapping
🔥아이콘 모양이 나오질 않고 tooltip도 표시되지 않는다..왜죠..ㅜㅜ
3. Naver Movie Ranking
네이버 영화 평점 사이트 분석
- https://movie.naver.com/
- 영화 랭킹 탭 이동
- 영화 랭킹에서 평점순(현재 상영작) 선택
https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date=20230307- 웹 페이지 주소에는 많은 정보가 담겨있습니다.
- 원하는 정보를 얻기 위해서 변화시켜줘야하는 주소의 규칙을 찾을 수 있습니다.
- 여기에서는 날짜 정보를 변경해주면 해당 페이지에 접근이 가능합니다.
자동화를 위한 코드
"https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date=20230307"- 날짜만 변경하면 우리가 원하는 기간 만큼 데이터를 얻을 수 있습니다.
date = pd.date_range("2022.10.01", periods=100, freq="D")
date
# 2022.10.01 부터 100일
1. format

2. 100일간의 데이터를 for문을 이용해 받기
import time
from tqdm import tqdm
movie_date = []
movie_name = []
movie_point = []
for today in tqdm(date):
url = "https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date={date}"
response = urlopen(url.format(date=today.strftime("%Y%m%d")))
soup = BeautifulSoup(response, "html.parser")
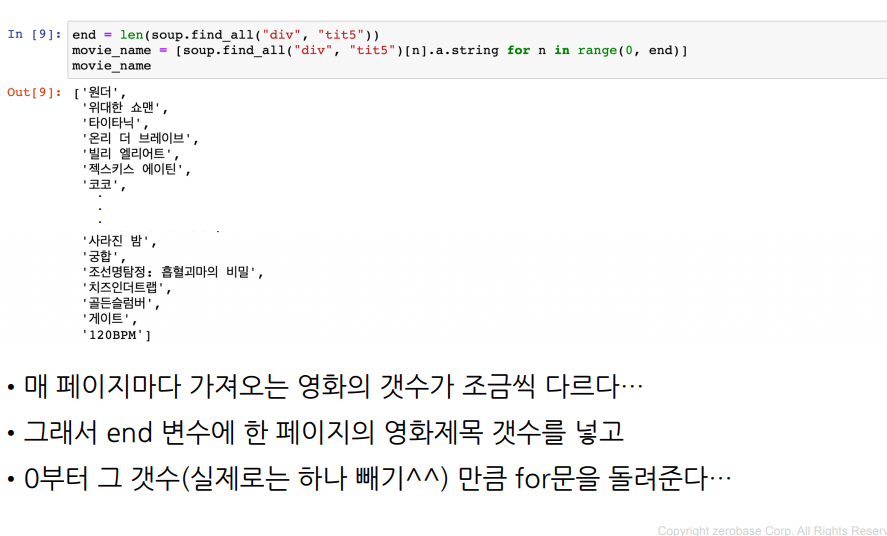
end = len(soup.find_all("td", "point"))
movie_date.extend([today for _ in range(0, end)])
movie_name.extend([soup.find_all("div", "tit5")[n].find("a").get_text() for n in range(0, end)])
movie_point.extend([soup.select(".point")[n].string for n in range(0, end)])
time.sleep(0.5) # 요청 속도가 너무 빠르면 로봇인줄 알고 차단당함. 일부러 텀을 준다3. dataFrame 으로 만들기
movie = pd.DataFrame({
"date":movie_date,
"title":movie_name,
"point":movie_point
})
movie.tail()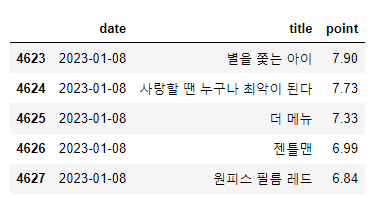
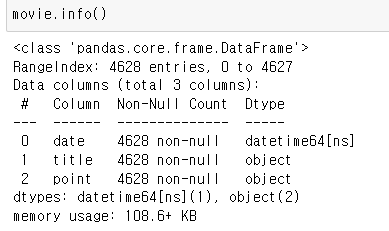
-> info 확인해보니 point가 object
-> 숫자로 바꿔주기
- astype() : 타입 변환
movie["point"] = movie["point"].astype(float) # astype() : 타입 변환
movie.info()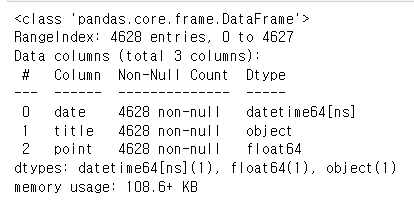
영화 평점 데이터 정리
- 영화 이름으로 인덱스를 잡습니다.
- 점수의 합산을 구합니다.
- 100일 간 네이버 영화 평점 합산 기준 베스트&워스트 10 선정
#pivot table
movie_unique = pd.pivot_table(data=movie, index="title", aggfunc = np.sum)
movie_unique
# sort
movie_best = movie_unique.sort_values(by="point", ascending=False) #내림차순
movie_best.head()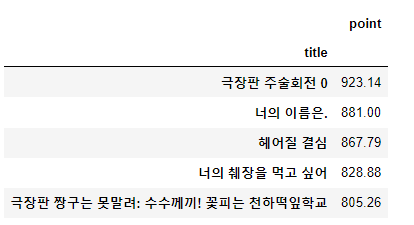
- query() : DataFrame 의 검색 명령
지정한 데이터에서 원하는 컬럼의 모든 데이터를 보여준다
괄호 안 큰따옴표, 작은따옴표 혼용 사용한다. 한가지로 사용시 오류남
tmp = movie.query("title == ['극장판 짱구는 못말려: 수수께끼! 꽃피는 천하떡잎학교']")
tmp
# movie(원본 데이터)에서 해당 컬럼의 모든 데이터를 보여준다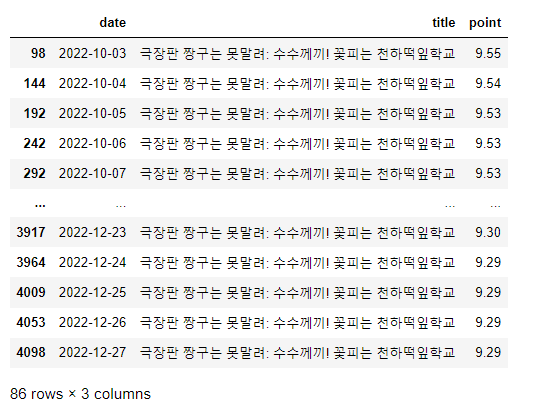
시각화
import matplotlib.pyplot as plt
from matplotlib import rc
rc("font", family="Malgun Gothic")
%matplotlib inline# 선 그래프. x축 날짜, y축 평점 => 날짜에 따른 평점 변화를 선 그래프로 표현(시계열)
target_col = ["공조2: 인터내셔날", "데시벨","리멤버", "사잇소리", "어바웃 타임","스마일" ]
plt.figure(figsize=(20,8))
plt.title("영화 평점 그래프")
plt.xlabel("날짜")
plt.ylabel("평점")
plt.xticks(rotation="vertical") # x축 표시 라벨 방향 회전
plt.tick_params(bottom="off", labelbottom="off") # x축 라벨과 그래프 사이에 눈금 표시해준다
plt.plot(movie_pivot[target_col])
plt.legend(target_col, loc="best")
plt.grid(True)
plt.show()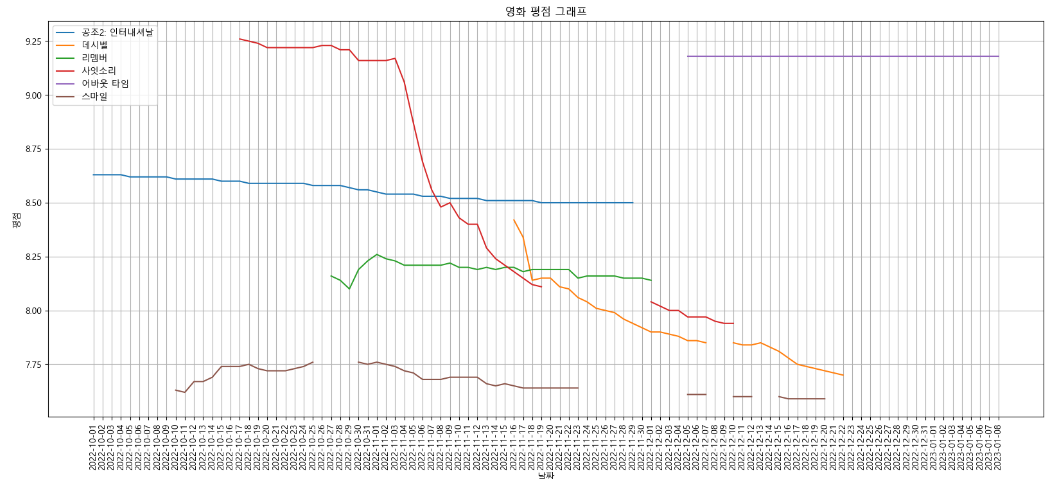
- matplotlib 한글 설정 (컴파일 제작 예정)
import platform
import seaborn as sns
from matplotlib import font_manager, rc
path = "C:/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
rc("font", family="Arial Unicode MS")
elif platform.system() == "Windows":
font_name = font_manager.FontProperties(fname=path).get_name()
rc("font", family=font_name)
else:
print("Unknown system. sorry")마무리
정리하려니 양이 꽤 많다. 휴휴휴
자소서 팀 스터디가 있는데 이제부터 준비해야겠다. 바쁘다 바빠 현대사회

study note