
자료(Data)
자료(Data)
"문자, 숫자, 소리, 그림, 영상, 단어 등의 형태로 된 의미 단위이다. 자료를 의미있게 정리하면 정보가 된다."
출처:wikkipedia
데이터(자료)들은 정리되고 분석되고 사용되어야 의미가 있다고 볼 수 있다.
사람이 컴퓨터에게 줄 수 있는 정보의 종류는 1.명령, 2.데이터 두 가지이다.
컴퓨터의 언어는 0아니면 1로 이것은 컴퓨터의 등장 이후 아직까지 넘지 못한 물리적인 한계이다.
처음에는 천공카드라는 것으로 0과1을 통해서 컴퓨터에 데이터를 저장했었다. 그러나 이런 방식은 사람이 쓰기에 불편하였기 때문에 인간의 언어로 컴퓨터에 명령을 줄 수 있게 하기 위해서 프로그래밍언어를 만들게 되었고 이것을 컴퓨터의 언어로 변환하기 위한 번역기로 컴파일러가 등장하게 되었다. 하지만 컴퓨터에는 아직도 0과1로 데이터가 저장되기 때문에 사람들은 데이터 타입을 나누게 되었다.
데이터 타입(Data Type)
컴퓨터에 이런 형태의 데이터가 주어졌다고 가정했을 때 사람은 이것을 어떻게 읽어야 할까?

0과 1로 이루어진 이진수 데이터를 특정한 길이로 나눈다.
0또는 1을 비트라고 하는데 이를 1바이트단위(8개)로 나눈다.
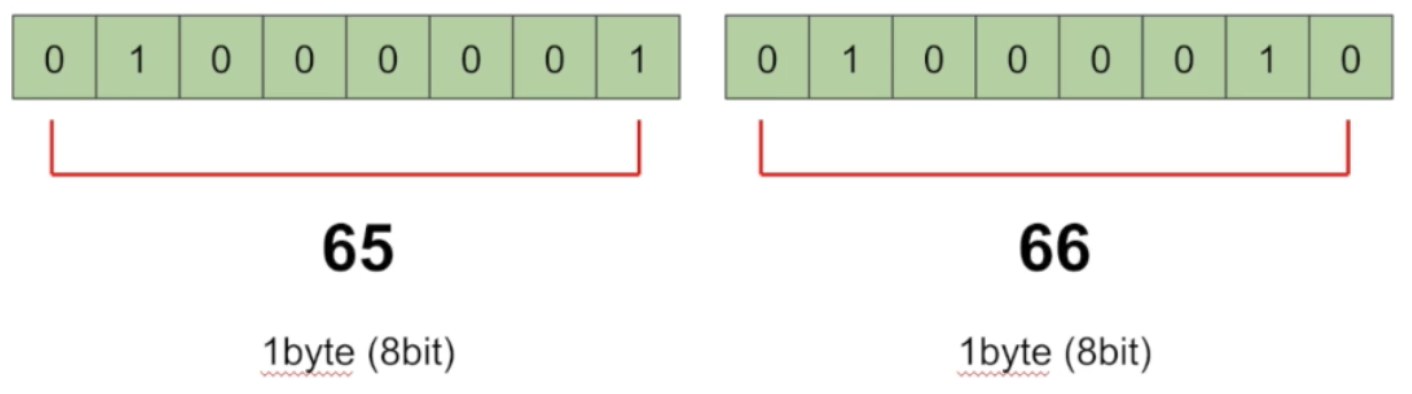
1바이트 단위로 읽었을 때 위와 같은 값을 얻을 수 있다.
그런데 이 65와 66은 A와 B가 되기도 한다.
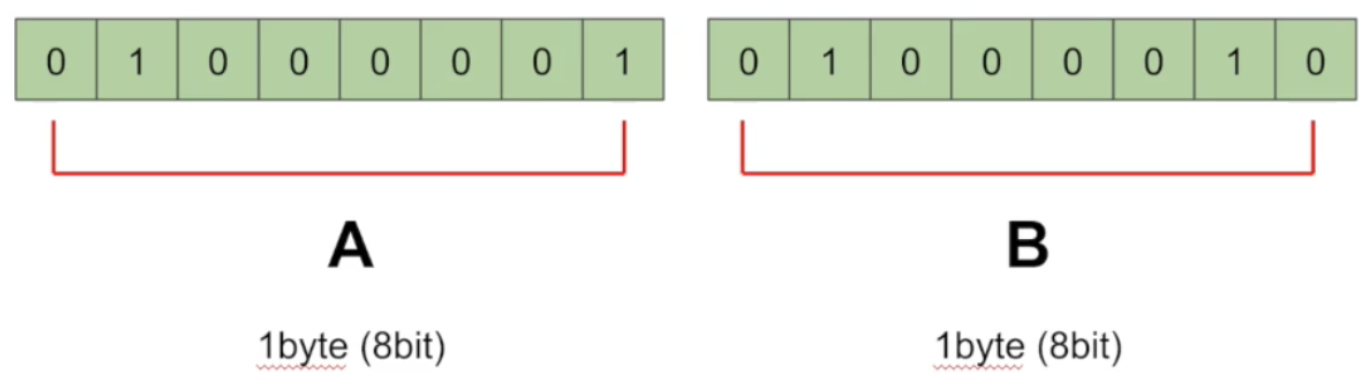
어떻게 65와 66이 A,B가 될 수 있을까?
그것은 사람들이 숫자값과 문자를 1대1로 연결시키자는 약속을 했기에 가능하다. 아스키코드표를 보면 이 약속들을 알 수 있다.
데이터 타입이란
컴퓨터에 0과 1로 저장되어 있는 데이터를 인간이 사용하는 여러가지 데이터들의 종류로 해석하기 위한 장치이다
같은 데이터라도 해석에 따라 다른 데이터가 될 수 있다(65,66이 A B인것처럼)
프로그램을 만들 때는 기본적으로
원시타입인 정수, 실수, 문자, 논리(참,거짓)을 사용한다
원시타입들을 사용해서 프로그래머가 직접 타입을 정의할 수 있다.(구조체, 클래스 등)
자료구조(Data Structure)
앞서 데이터 타입이 하나의 데이터를 어떻게 해석할지를 정의한 것이라면
자료구조는 여러 데이터들의 묶음을 어떻게 저장하고 사용할지 정의한 것이다.
배열, 스택, 트리등과 같은 자료구조가 있다.
대부분의 자료구조는 특정한 상황에 문제를 해결하는데 특화되어 있기때문에 많은 자료구조를 알고있으면 어떤 상황에서 어떤 자료구조가 적합한지 판단하고 사용할 수 있을 것이다.
스택(Stack)
Stack은 쌓여있는 접시 더미와 같이 작동하는데, 새로운 접시가 쌓일 때도 맨 위에서 쌓이고, 접시를 가져갈 때도 맨 위에서 가지고 가는 것과 같다. 이것을 LIFO: last in, first out 즉, 나중에 들어온 데이터가 처음으로 나간다. 처음에 들어온 데이터에 접근하기 위해서는 나중에 들어온 데이터들을 모두 빼내야 처음에 들어온 데이터에 접근할 수 있다.

위의 움직임이 스택을 직관적으로 이해하는데 도움을 줄 수 있다고 생각된다.
처음에 들어온 초록색에 접근하기 위해서는 맨 마지막에 들어온 보라색을 빼내고 그다음으로 들어온 파란색을 빼내야 초록색을 빼낼 수 있다.
스택의 구조에서
위의 움직임에서 보여지듯이
가장 마지막에 입력된 데이터(보라색)를 top이라고 하며, top위치 에서만 추가, 삭제, 읽기를 할 수 있다. 가장처음에 입력된 데이터(초록색)를 bottom이라고 한다.
스택의 동작
스택의 동작은 3가지가 있는데
- 추가(push) : 스택에 새로운 데이터를 삽입하는 것. 새로 추가된 데이터가 top이 된다.
- 삭제(pop) : top위치의 데이터를 삭제하는 것.
- 읽기(peek) : top위치의 데이터를 읽는 작업.
위의 3가지이다.
추가와 삭제는 배열메소드인 push(맨뒤에 요소 추가), pop(맨뒤의 값을 뺌)으로 이해하면 더 편할 것 같다.
큐(Queue)
Queue는 판매에 관련된 아르바이트를 해본사람이하면 한번쯤은 들어봤을 선입선출의 느낌이다. 이를 FIFO: first in, first out 라고 하며 나중에 들어온 데이터에 접근하기 위해서는 이전에 들어왔던 데이터 들을 모두 빼내야 나중에 들어온 데이터에 접근할 수 있다.
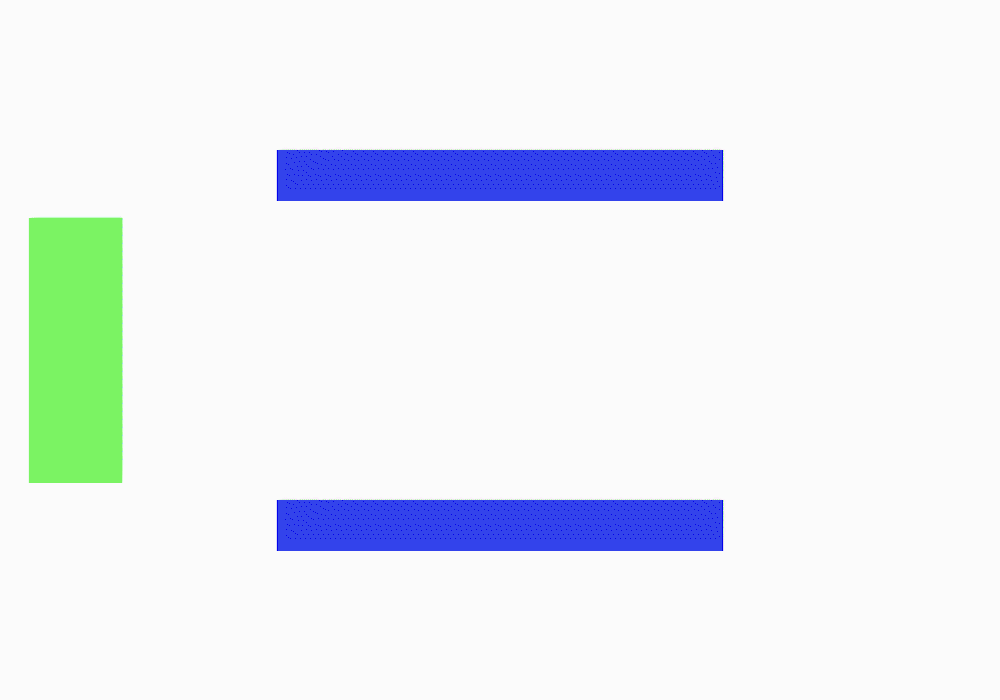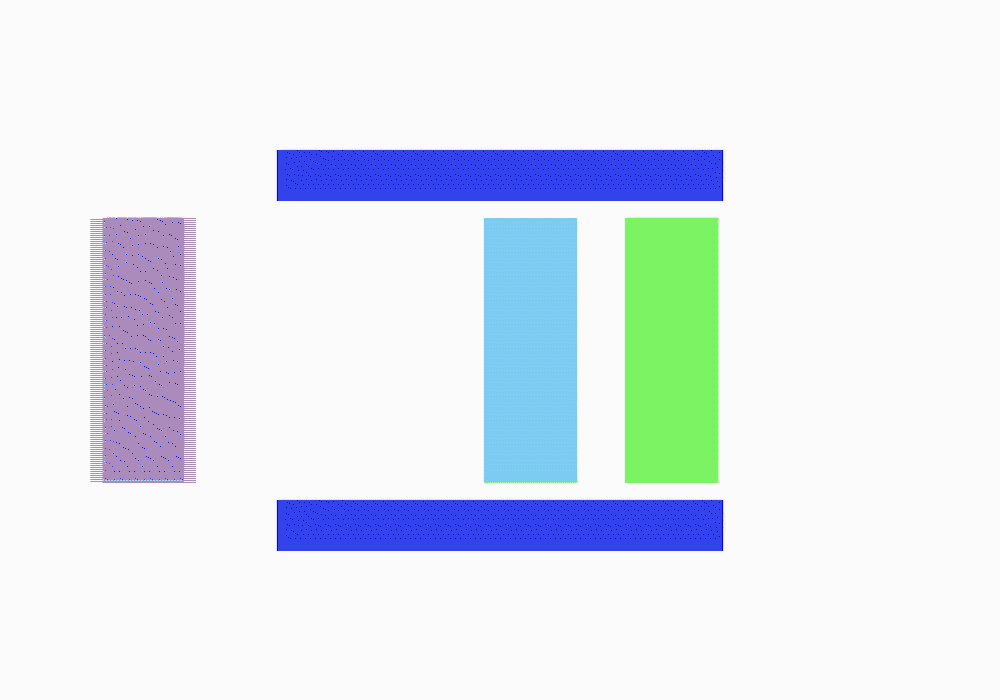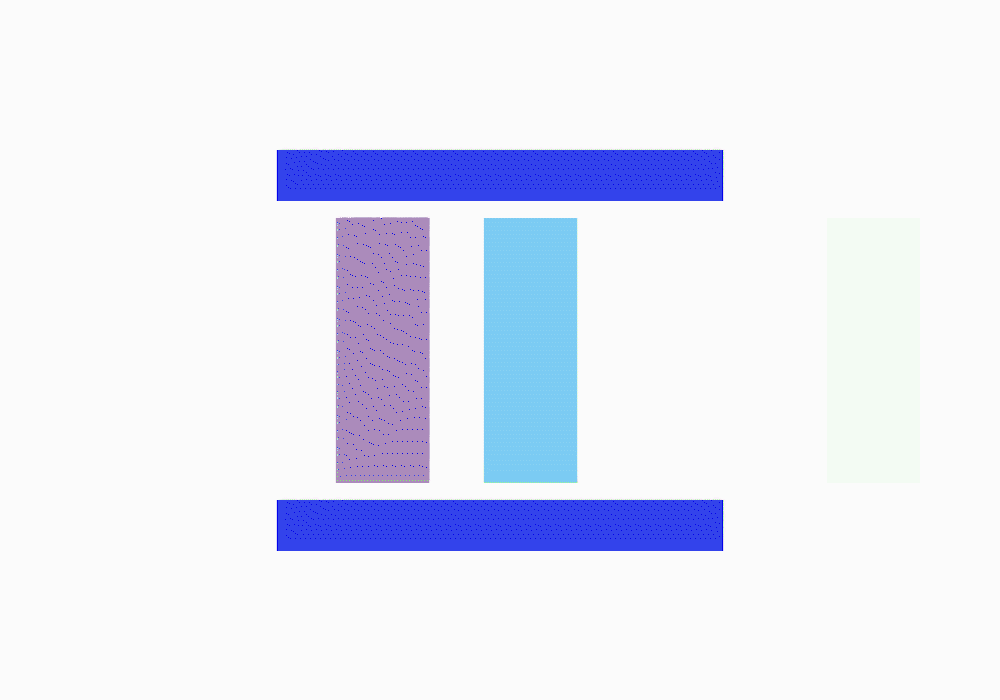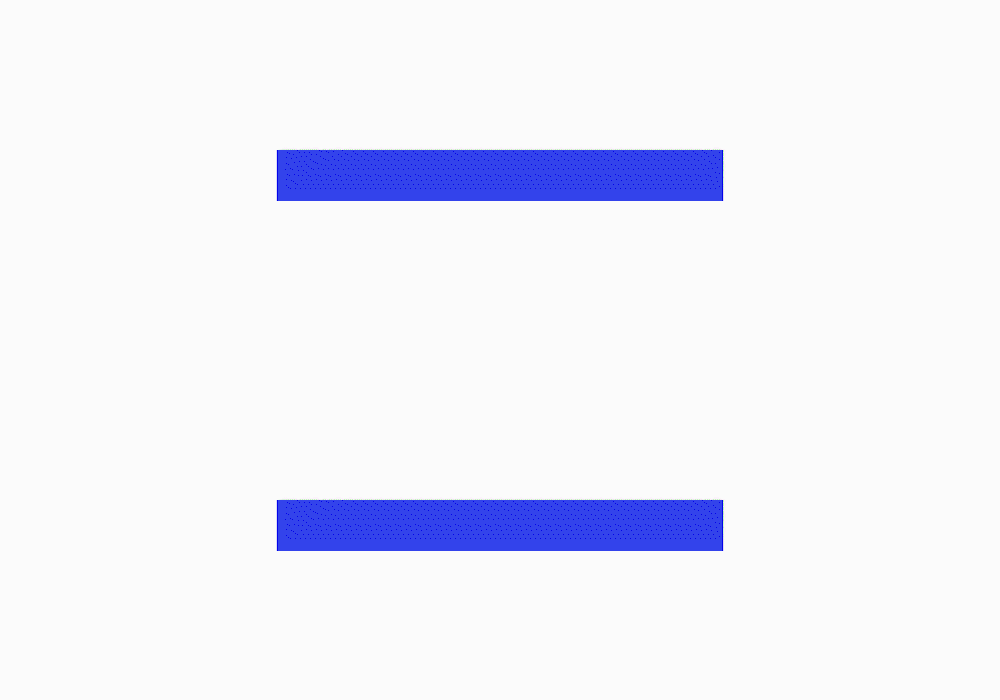
위 움직임으로 보면 맨 나중에 들어온 보라색에 접근하기 위해서는 처음에 들어온 초록색과 그 다음에 들어온 파란색을 빼내야 보라색에 접근할 수 있다.
큐의 구조에서
위의 움직임에서 보자면
가장 먼저들어 들어온 데이터를 front(그림에서 초록색)라고 하고, 가장 나중에 들어온 데이터를 rear(그림에서는 보라색)라고 한다.
큐의 동작
큐의 동작도 크게 3가지가 있는데
- 추가(enqueue) : 큐에 새로운 데이터를 추가한다. 데이터의 추가는 rear위치에서 일어난다.
- 삭제(dequeue) : 가장먼저 입력된 데이터의 위치인 front의 데이터를 빼내는 것
- 읽기(peek) : 큐의 가장먼저 입력된 데이터 위치인 front위치의 데이터를 읽는 것
위의 3가지 이다.
