MySQL Character Set, Collation - 1
왜 중요한가
MySQL의 Character Set(캐릭터 셋), Collation(콜레이션)은 의도한 결과를 도출하기 위해 매우 중요하다.
캐릭터셋과 콜레이션 설정 값에 따라서 특히 유의해야 할 포인트들은 다음과 같다.
- 쿼리 결과가 깨지지 않는지
- 대소문자 구분 여부
- 예상한 정렬 순서와 같은지
- 비교 연산 결과가 예상한 것과 같은지
- Group by 시 예상한 결과가 도출되는지
- 의도한 실행 계획과 같은지
위 문제들이 발생 할 수 있는 이유는, 캐릭터셋과 콜레이션 설정 값에 따라서 데이터를 저장하는 형식이 다르고, 같거나 다르다, 또는 작다 크다를 판단하는 기준이 달라질 수 있기 때문이다.
캐릭터 셋이나 콜레이션을 고려하지 않아, 쿼리가 의도하거나 예상한 것과 다른 결과를 도출할 수 있고, 이 문제를 백엔드에서 마주하는 경우 상황의 원인이 되는 DB단 설정을 놓치는 경우가 많다.
이미 SQL 결과가 도출되어 Application단으로 올라가고 나면, 문제의 원인이 되는 DB 단 설정을 고려하기 어려울 수 있어 DB에서는 이러한 점들을 특히 신경써야 한다.
배경지식
캐릭터 셋과 콜레이션을 이해하기 위해 배경이 되는 단어들에 대해 살펴보자.
Unicode
유니코드는 키와 값이 1:1로 매핑하여, 기계와 사람이 이해 할 수 있도록 변환하는데 도움을 주는 역할을 한다.
그런 점에서 ASCII와 매우 비슷한데, 아스키코드에서 0x41 = A로 매핑 하는 것처럼, 유니코드도 다양한 문자를 특정 숫자(키)와 1:1로 매핑한다.
ASCII가 만들어 질 때는 ASCII의 범위(0~127)로 충분히 많은 문자들을 표현 할 수 있었다.
즉, 아스키를 통해 총 128개의 문자를 표현할 수 있고 과거에는 이 정도로 충분했다.
예상할 수 있듯, 세계 각국의 언어, 문자, 심지어는 이모티콘과 같이 컴퓨터가 표현해야 하는 문자의 종류가 다양해지자, ASCII 코드의 범위로는 모두 표현하기 어려워졌다.
또한 각 나라나 단체마다 각자 인코딩을 위한 규칙을 정의하면서, 서로 변환되지 않고 호환 될 수 없는 문제들이 발생했다.
Unicode는 이러한 문제점들을 해결하고자 만들어졌다.
Unicode는 세계 각국의 문자, 이모티콘과 같은 수 많은 문자들을 표현하면서도, 환경, 국가나 단체에 따라 서로 인코딩 / 디코딩 과정이 호환되지 않아 글자가 깨지는 것과 같은 문제들을 해결하였다.
ASCII 코드표를 본 적 있다면 유니코드 평면을 쉽게 이해 할 수 있다.
(유니코드 평면도 문자와 코드를 매칭한 단순한 표이기 때문이다)
평면(Plane)이라는 표현이 사용된 이유는, 유니코드는 앞서 설명한 것 처럼 ASCII보다 훨씬 더 많은 문자를 표현 하고 있기 때문에 ASCII 코드표와 같이 하나의 표로는 가독성 있게 보여주기 어렵다.
유니코드는 이러한 코드표를 여러 차원에 걸쳐 만드는 방법을 선택했다.
각 평면(Plane)은 0번부터 16번까지 총 17개가 존재한다.
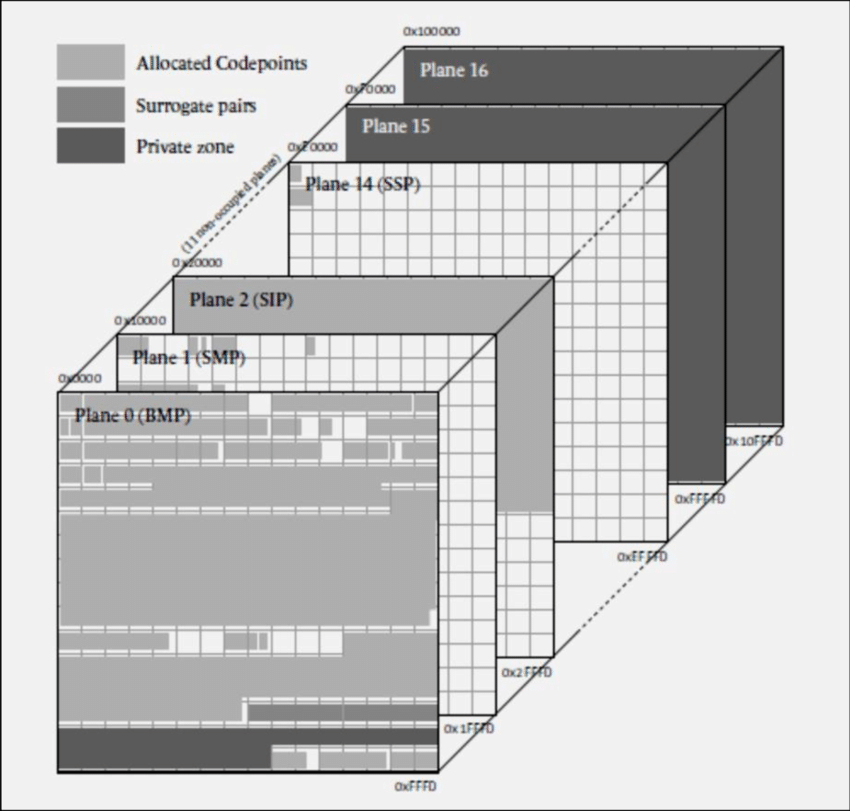
코드 포인트(Code Point), 코드 포지션(Code Position) 이라고 하는 값은 이 평면 내 문자가 어디에 위치하는지를 의미한다.
즉, 1개의 코드 포인트(또는 코드 포지션)은 1개의 문자와 매핑된다.
가장 많이 사용되는 평면 0, 1에 대해서 알아보자.
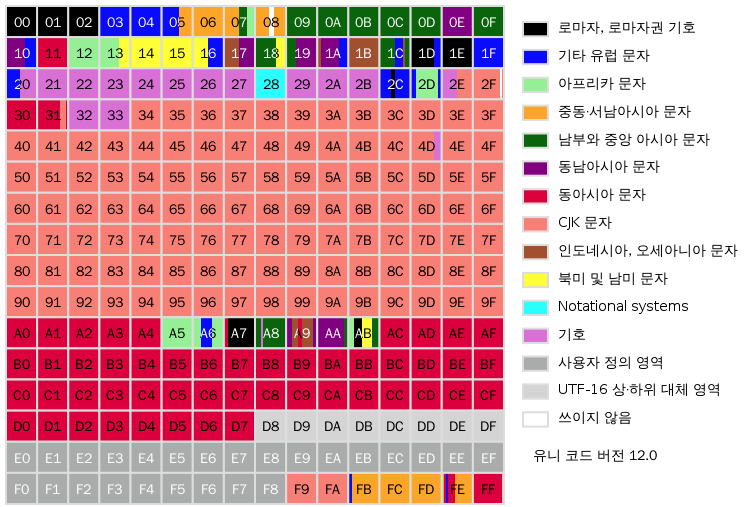 (BMP 평면 이미지)
(BMP 평면 이미지)
평면 0은 BMP (Basic Multilingual Plane) 이다.
- 코드 포인트 U+0000 - U+FFFF 범위를 나타낸다.
- 가장 많이 쓰이는 문자와 기호를 배정한 평면
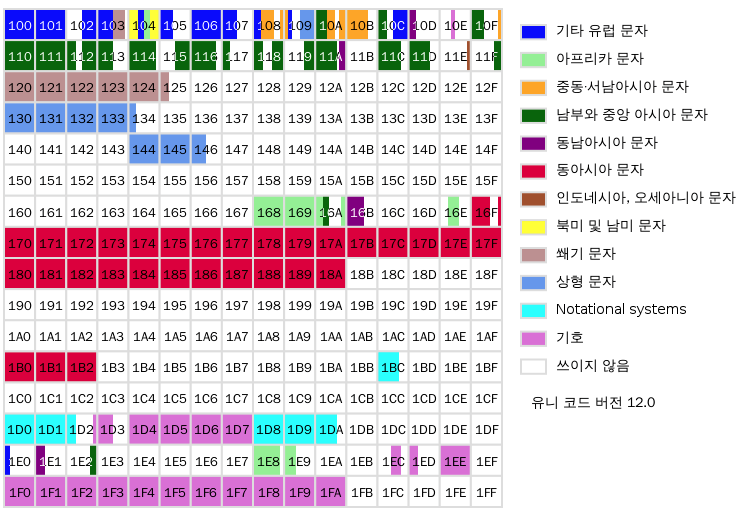 (SMP 평면 이미지)
(SMP 평면 이미지)
평면 1은 SMP (Supplementary Multilingual Plane) 이다.
- U+10000 - U+1FFFF
- 언어 표기에 보조적으로 필요한 문자가 기호가 포함된 평면
- 옛 한글, 이모티콘 등이 포함되어 있는 평면
이러한 평면이 총 17개 있다고 이해하면 된다.
인코딩
이제 우리는 Unicode 표를 이용해서, 표현하고자 하는 문자를 Unicode의 CodePoint로 변환 할 수 있다.
예를 들어, 한글 '가'를 의미하는 CodePoint 는 U+AC00 이다.
U+AC00을 컴퓨터가 이해하는 언어로 바꾸기 위해서, '인코딩'이라는 과정을 거쳐야 한다.
인코딩은 말 그대로, U+AC00과 같은 문자를 컴퓨터가 이해할 수 있고 쉽게 다루기 위한 형태, 즉 1과 0으로 이루어진 형태로 변환하는 작업을 말한다.
UTF8, UTF16, UTF32와 같은 것들이 인코딩 방법이다.
이 말은, 어떤 인코딩 방법을 사용하느냐에 따라서, 코드 U+AC00이 다르게 표현될 수 있다는 것이다.
디코딩은 인코딩 된 데이터를 다시 코드로 변환하는 과정을 말한다.
즉, 인코딩 과정의 역이라고 표현할 수 있다.
이어지는 글 : https://velog.io/@haegu/MySQL-Character-Set-Collation-2
