Training Region-based Object Detectors with Online Hard Example Mining 논문 정리
CPN읽다가 RetineNet 부분에서 도저히 이해가 안가서 OHEM(Online Hard Example Mining) 이해하려고 가져온 paper이다. 저자는 R-CNN 계열 논문을 냈던 Ross Girshick이 있었고, Avhinav Gupta도 어디서 많이 본 이름이길래 봤더니 Non-local Neural Network 논문 내신 분이었다..
세상은 넓고 똑똑한 사람은 진짜 말도 안되게 많은 것 같다 ㅠㅡㅠ
1. Introduction
Object detection 분야에서 딥러닝을 활용한 모델이 굉장히 많이 등장하고 있다. 하지만 아키텍처 자체를 구성할때 여전히 휴리스틱한 부분이 많이 들어간다. 그래서 이 논문에서는 region based ConvNet detector 를 학습시킬 때 사용하는 online hard example mining이라는 간단하고 효과적인 알고리즘을 제안한다.
online hard example mining이 무슨 의미냐면, 보통 이미지를 가지고 학습을 시키면 네트워크가 잘 식별하고 찾아내는 데이터(easy example)가 있을꺼고 잘 찾아내지 못하는 데이터(hard example)가 있을텐데, hard example들을 자동으로 골라서 학습을 좀더 효율적이고 효과적으로 하겠다는 이야기이다.
이때 hard example을 자동으로 골라서 학습에 비중을 두는 역할을 OHEM(online hard example mining)이 대신 해주기 때문에 원래 학습에서 존재했던 휴리스틱한 부분이랄지 하이퍼 파라미터들을 대신할 수 있었다.
이 논문에서는 이렇게 기존에 인간의 개입이 어느정도 필요했던 부분들을 학습의 대상으로 바꾸어 성능을 올렸다. 하지만 이 뿐만 아니라, detection performance에서 일정하고 높게 잘 boosting되었다고 한다.
사실 예전부터 데이터 셋의 불균형성 문제는 계속해서 있어왔다. 그리고 기존 솔루션(딥러닝 이전, SVM 많이 사용할 때)은 bootstrapping (요즘은 hard negative mining이라고 부름) 이었는데, 이는 training set을 샘플링할때 모델이 잘 예측하지 못하는 false positive 위주로 데이터를 샘플링 하는 것이다.
근데 이 방법을 딥러닝과 함께는 잘 사용하지 않았다고 한다. Convolution network를 학습시킬 때 기본적으로 사용하는 방법이 gradient descent인데, 기술적으로 gradient descent와 bootstrapping을 함께 쓰는 일이 어려웠나보다. 이거를 같이 쓰려면 잠깐 모델 fix하고 새로운 training set 뽑아서 이번엔 데이터 셋 fix해서 학습하고, 또 모델 fix해서 training set 뽑아서 학습하고, 이거를 계속 반복해서 학습을 해야하는데 그러면 너무 전체 학습 속도가 느려진다는 이야기이다. 그러면 결국 online으로 hard example을 바로바로 찾아낼 수 있는 어떤 매커니즘이 필요하다는 결론이 나온다. 바로 OHEM이다.
2. Training Region-based Object Detectors with Online Hard Example Mining
1) Fast R-CNN Overview

논문에서는 Fast R-CNN을 간단하게 요약해준다. Fast R-CNN에서 다루는 전체 내용은 아니고 짧은 아키텍쳐 설명(convolutional layer + RoI-pooling layer)과 왜 이 논문에서 base object detector로 Fast R-CNN을 선택했는지, 그리고 Fast-RCNN을 학습할 때 Foreground ROI와 Background ROI를 어떻게 처리하는지의 여부 등을 설명한다.
먼저 Fast R-CNN을 학습할 때는 SGD 방법을 이용해서 학습을 하는데, 각 RoI의 loss는 classfication loss와 localization loss의 합으로 이루어진다. 그리고 이때 detect 된 RoI들에 대해서 foreground roi와 background roi로 분류한다. 분류 기준은 해당 roi와 ground truth가 겹치는 영역(IoU)이 0.5 이상이면 foreground roi이고, 0.1 이상 0.5 이하이면 background roi이다.
일반적으로 훈련할 때 foreground roi와 background roi의 비율을 1:3 정도로 맞춰서 각 미니배치를 구성한다. 실험 결과에 따르면 이 비율이 성능에 꽤 중요한 역할을 하는데, OHEM을 통해서 성능은 그대로 두고 ratio를 정할때 개입하는 휴리스틱한 하이퍼 파라미터는 제거할 수 있었다.
2) Online Hard Example Mining
 이 논문에서는 Faster R-CNN과 같은 object detect에 사용할 수 있는 효과적인 online hard example mining 알고리즘을 제안한다. 기존에 SVM과 같은 모델을 사용했을 때 hard example mining이 어떻게 이루어졌는지와 왜 딥러닝에서 hard example mining과 같은 방법이 적용되기 어려운지를 고민해보았을 때, 딥러닝 모델이 학습시킬때 매우 작은 batch size로 iteration을 돌더라도, 한 이미지 내에서 roi가 매우 여러개 나올 수 있다는 사실에 집중했다고 한다.
이 논문에서는 Faster R-CNN과 같은 object detect에 사용할 수 있는 효과적인 online hard example mining 알고리즘을 제안한다. 기존에 SVM과 같은 모델을 사용했을 때 hard example mining이 어떻게 이루어졌는지와 왜 딥러닝에서 hard example mining과 같은 방법이 적용되기 어려운지를 고민해보았을 때, 딥러닝 모델이 학습시킬때 매우 작은 batch size로 iteration을 돌더라도, 한 이미지 내에서 roi가 매우 여러개 나올 수 있다는 사실에 집중했다고 한다.
학습 과정을 설명하자면, iteration t에 이미지 한장이 들어왔을 때, 일단 ConvNet을 이용해서 feature map을 계산한다. 그리고 각 검출된 각 roi 영역들을 샘플 배치 대신에 모두 RoI network에 넣고 propagation 시킨다. 그래서 나온 roi들 중에서 loss가 가장 큰 N개의 roi를 뽑아서 back propagation 시킨다. 그런데 여기에서 동일한 object에 대해서 여러개의 roi가 잡힐 수 있으니 non-maximum suppression을 사용해서 중복을 제거한다.
앞서 설명한 OHEM을 구현하기 위한 방법에는 여러가지가 있을 수 있다. 제일 쉬운 방법으로는 loss layer를 hard example selection에 맞도록 수정하는 것이겠지만 비효율적이기 때문에 저자는 상단의 아키텍처를 제안한다.
솔직히 그림이 너무 복잡하게 생겼지만 간단하게 설명하면 RoI network을 똑같은거 하나를 더 두는데, 이거를 읽기 전용으로 두는 것이다. (readonly라길래 무슨 부산줄^^;) 읽기 전용인 (a) roi network를 통해서 모든 roi 영역들의 loss를 계산하고, 여기에서 hard example만 몇개 고른 다음에 얘네들만 가지고 (b) roi network에서 forward propagation과 backward propagation을 진행한다..
3. Experiment
1) Various comparison of OHEM

일단 상단의 표를 보면 기존의 휴리스틱한 방법들에 비해 OHEM의 성능(mAP)이 유의미하게 향상되었음을 확인할 수 있다. 보다 다양한 bg_lo에 대해서 성능 비교가 있으면 더 좋았을 텐데 아쉬웠다. 그래도 뭐 bg_lo가 0.1일때 가장 성능이 좋았으니까 table에 넣어놨을 것 같기는 하다 (1-4라인과 11-13라인 비교).
그리고 학습할 때 gradient가 robust해서 N이 1이던지 2이던지 그렇게 최종 성능에 영향을 크게 미치지 않는다는 것을 확인할 수 있다 (7-10라인과 11-13라인 비교). 마지막으로, 사실 학습할 때 자연스럽게 loss가 큰 데이터에 gradient가 크게 간다는 것은 당연한 사실인데, hard example만을 사용하는 것이 성능에 얼마나 영향을 끼치는지 비교한 내용이 있다 (7-10라인과 11-13라인 비교).
2) Memory cost
 roi network를 복사해서 2개를 두고, 그 중 하나를 읽기 전용으로 두어서 back propagation을 위한 메모리 소비량을 줄인다는 아이디어 때문에, max memory가 그으으으ㅡㅇ렇게 많이 늘지는 않았다. 그리고 원래 base detector였던 fast R-CNN이 원래 빠른 모델이었기 때문에 이 정도의 속도 증가는 뭐 대부분의 사람들이 그냥 받아들일 수 있는 정도의 속도라고 한다.
roi network를 복사해서 2개를 두고, 그 중 하나를 읽기 전용으로 두어서 back propagation을 위한 메모리 소비량을 줄인다는 아이디어 때문에, max memory가 그으으으ㅡㅇ렇게 많이 늘지는 않았다. 그리고 원래 base detector였던 fast R-CNN이 원래 빠른 모델이었기 때문에 이 정도의 속도 증가는 뭐 대부분의 사람들이 그냥 받아들일 수 있는 정도의 속도라고 한다.
4. 결론
Training Region-based Object Detectors with Online Hard Example Mning의 경우에는 앞서 언급했듯이 기존의 연구에서 인간의 인위적인 개입이 필요했던 부분들(hyper parameter, background-foreground ratio 등등)을 제거해서 학습을 간단하게 만들었다.
그 결과 속도나 메모리 면에서도 acceptable하고 안정적으로 학습할 수 있었다 .. . . . 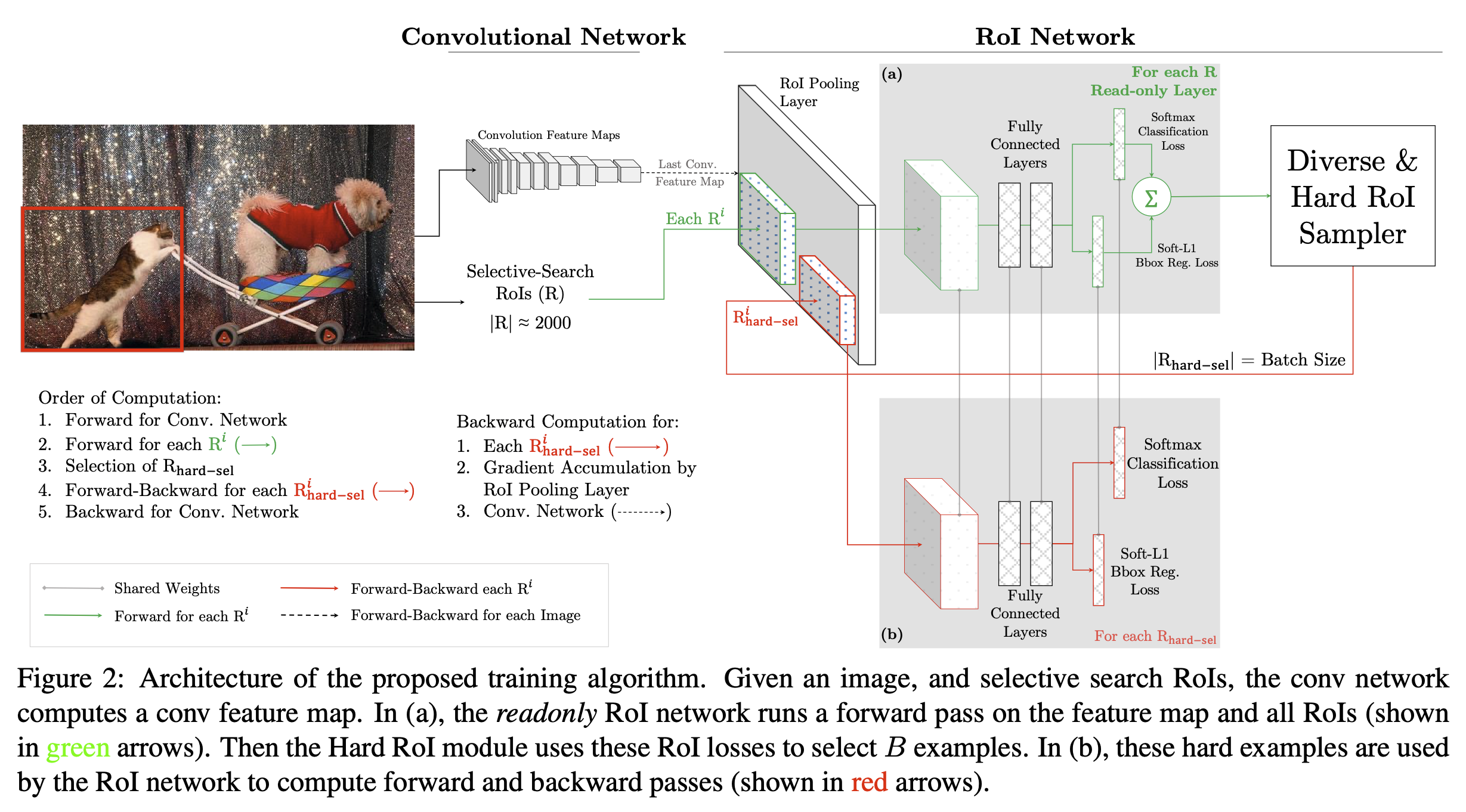
(+ 분명 머신러닝 수업시간에 bootstraping이랑 boosting이랑 다 배웠는데 왜 내 머리속에서는 휘발되었을까 ^___^ ;;;; 필기는 다 되어있는데 .... 열공하자 .. .. .)
Reference

안녕하세요 글 잘 읽었습니다!
한가지 궁금한게 있는데 bootstrapping을 hard negative mining이라고 하셨는데 hard negative mining은 boosting과 유사한 알고리즘 아닌가요?