Motivation & Direction
- 많은 부분에서 Transformer라는 모듈을 다루는데 --> GPT & Bert 등장
= positional Encoding, Multi Self-Attention + a
= 기계어 번역에서는 좋은 성능을 보이는데, 자연어에서는 레이블을 주기 애매함. 그러나 다양한 Task에 정확한 레이블 없이도 작동 가능하게 하고 싶다!
contents
- 자연어 데이터의 특징
-
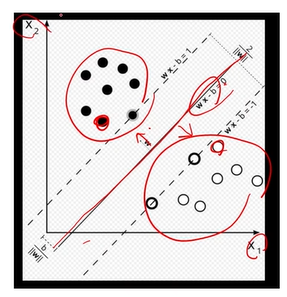
Tabular Dataset
= 각각의 데이터 샘플들이 구성하고 있는 features는 독립적이다.
= KNN, Linear Regression 의 기초가 되는 데이터셋 구조
= 키, 성별, 몸무게별로 매핑해서, decision boundary를 그어줄 때 0보다 크면 검정색, 작으면 하얀색으로 마킹해주는 모델에서 잘 작동하는 데이터 셋!
-
이미지
= 이미지 안의 의미있는 정보는 위치와 무관함. 눈이라는 의미는 30px이 그렇게 생겼기 때문에. 한 픽셀은 눈이 아님.
= locality라는 정보 = 데이터 셋이 이미 귀납적으로 평향을 갖고 있다는 뜻 -
자연어 데이터(문장)의 경우
= Translation Invariance 가 적용X (다 같은 석상인데, 위치가 3가지로 달라져도 똑같이 이해하는게 이미지에는 적용되는데, 문장에는 적용 안 됨)
= 문장을 구성하고 있는 단어들의 위치가 변해서는 안됨
= 단어들 간의 관계가 중요, 하나의 단어만 바뀌거나 추가돼도 전혀 다른 의미가 됨(나는 미국인을 좋아한다 -> 나는 미국인을 안 좋아한다 = 긍정 -> 부정문)
SUMMERY
- Gpt를 구성하는 모델은 transformer에서 가져온 것
- Bert, GPT의 경우 특히 자연어 데이터에 특화된 프레임워크
- 자연어데이터는 단어와 단어들 사이 순서, 관계가 중요
- 문장이 갖고 있는 문맥을 알고리즘이 이해할 수 있게 하는 게 어렵다
- 자연어 데이터의 토큰화
토큰화할 수 있다= 문장을 의미있는 단위로 쪼갤 수 있다
-
Character 기반으로
= L e t ' s d o t o k e n i z a t i o n
= 문장의 시계열 길이가 너무 늘어남.
= 각각의 문자는 의미를 갖고있지않음 -> 결국 단어로 표현해야함 -
split on spaces(word)
= Let's do tokenization!
= 경우의 수가 너무 많음
= 사전에 없는 단어가 생길 위험이 큼 -
split on punctuation
= let 's do tokenization!
- hugging face와 같은 대중적 공유 라이브러리가 존재하기 전 개발자들이 각각 토큰화를 임의 진행
= 모델을 다운받아 실행시킬경우 전혀 다른 결과가 나타남. 데이터셋이나 환경에 따라.
= 토큰처리 과정에 대해 아는 건 매우 중요
- hugging face와 같은 대중적 공유 라이브러리가 존재하기 전 개발자들이 각각 토큰화를 임의 진행
- 언어모델
- 자연어 처리 tesk
하나의 문장을 확률적으로 모델링; 분석한다.
= 하나의 문장을 여러개로 나누고, 나눈 토큰들의 결합분포로 문장에 대해 확률계산
-
나는 사과를 먹었다
w1 / w2 / w3
P(W) = P(w1, w2, w3)
= P : 일반적인 문장에 대한 확률. -
문장 감정 분석:
맛있는 사과를 먹었다 = P(w1, w2, w3)
= P는 긍정적인 확률 가정 = 높아짐
/ 맛없는 사과를 먹었다 = 낮아짐 -
기계어 번역 & Question answering
나는 사과를 먹었다 => I ate an apple
P(w'1, w'2, w'3 | w1, w2, w3)
= 확률이 높게 나옴
/ crush = w'5
P(w'1, w'5, w'2, w'3)
= 확률이 낮게 나옴
= 단어가 중요한 이유
- 나는 ? 을 먹었다
w1 / w2 / w3
: w = 사과 일경우, P(w|w1, w3) >> 0
: w = 식탁 일경우, P(w|w1, w3) ~~ 0
= 조건부 확률
뭘 푸는지 정해놓고, 가장 맞는 모델을 찾는 것
- metric
자연어 처리, 감정분석 = 정량분석은 어렵다. 장 파악하고 접근하기
Text metrics
자연어 처리 모델 기존연구들
-
context(문맥)이 중요하다
한 -> 사투리 : 단어만 바꾸면 되지만,
한 -> 영어 : 순서, 포맷이 바뀜.
= "한 문장을 context를 가진 벡터로 표현하고 싶다"로 접근 -
기존의 이미지나 tabular 데이터와는 달리
순서가 중요 -
(문장의 문맥을 하나의 벡터로 표현하기 위해) 인코딩
1) token = 나는 / 사과를 / 좋아한다
2) 숫자로 표현하고 백터화 -> 인코딩해서 입력 -> n차원의 context 벡터가 됨.
= 얼마나 의미있는 embeding이 되느냐가 중요 -
문맥을 알아내는 encoder를 학습했다면, 다양한 task에 적용가능
-> 감정분석, 기계어번역, QA(Question Answer)
예) QA = context라는 긴 문장을 보고, 영어지문풀듯 문제가 나옴. 질문에 정답을 내는 방식으로 진행 = 문맥, Q에 대한 이해가 둘다 필요하고 A를 냄
-
Recurrent neural networks(RNNs)
input이 순서대로 나올 때 - 모델이 output으 두가지로 내뱉음
= Transformer 이전에 사용
= encoder를 거치고 - context becter - decoder를 지나감. -
? 문장은 단어들이 순서를 갖고 있다는 것을 알겠다. 하지만 중요한 단어들이 처음 부분에 있다면 정보를 잊어버리지 않을까?
= 그래서 번역을 한 문장씩 하는 것. 일반적으로는 2-3문장 지나면 잊어버림. -
! 각각의 단어에 대해 attention을 줄 수 있다면 좋겠다
나는 사과를 좋아한다 = I like an Apple
= I를 번역할 때는 '나는', apple을 번역할 때는 '사과'에 집중 -
= attention score을 주고, 전체 문장을 보고 문장 중 중요한 단어에 attention을 줘서, 문장 번역에 도움을 줌
이전문장의 단어가 임베딩된 벡터 hi,
번역할 단어의 임베딩 벡터 hj
j는 apple이고, h2hj 스코어가 가장 높아야 한다.
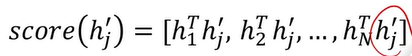
이 열 백터의 값이 나오면,
그 후 softmax함수를 취한다
softmax(score(hj)) = 단어 임베딩 벡터 hj가 어떤 단어와 가장 유사한지를 확률적으로 출력 = 이게 apple이다
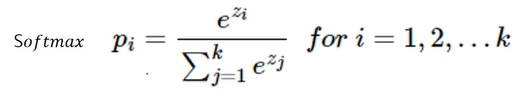
= 이전 문장의 벡터들을 보고, 변하지 않는 hj(=apple)과 뭐가 가장 유사한지 확인하는 것
= 한국어 문장 기준이니가 k는 3
정리
= 자연어 데이터의 순차적인 특성을 고려하는 기존 연구들
문장마다의 중요도를 계산해서 attention 모듈을 생각해냄
선형대수 기초
- ?

= 일단. 강의목표는 hihj = 어떤 h1벡터와 hj벡터간의 "유사도"를 의미한다는 걸 아는 것
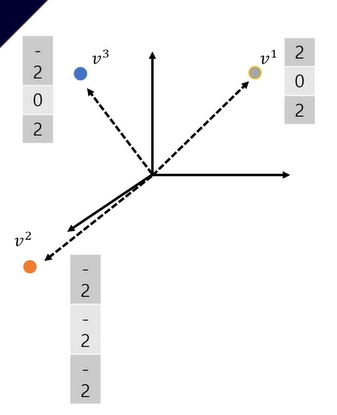
1) Cos 유사도(각에 대한 것)와 벡터의 내적의 관계
벡터 = []안의 숫자들이 있고 얘들은 순서가 있음
Cos 유사도 가 이렇게 생겼고, 그 안에 '내적'이 있다
a . b = 벡터의 내적
= ------
||a|| ||b|| = 벡터의 크기내적의 유사도의 근거가 1)또는 2)인 것!
2) 벡터의 내적과 거리의 관계, KL divergence
distance의 정의:
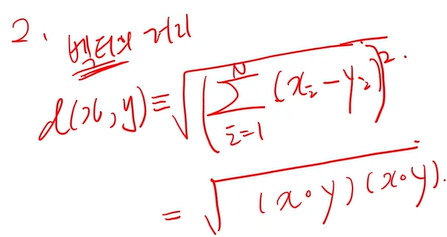
= 거리의 정의에 내적이 있다
= 내적은 유사도
벡터의 내적이 유사도라는 게 가슴으로 이해돼야한다
내적 -> 행렬
- 행렬과 벡터의 관계
열벡터와 행벡터로 이루어진 것 -> 행렬
m차원의 컬럼벡터가 n개 있다
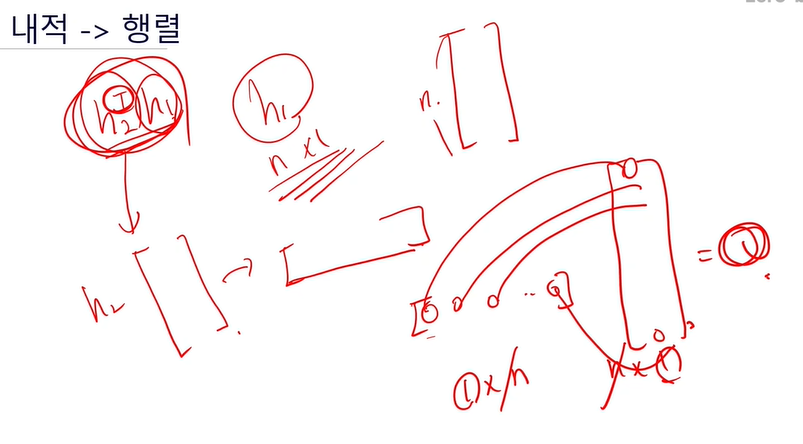
[ 가로로 긴 ] * [ 세로로 긴]
1*n * n*1 = 1
softmax
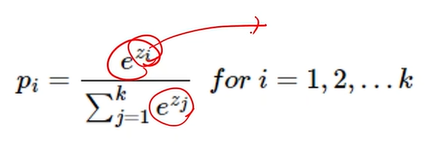
모든 사건의 확률 다 더하면 1이 나온다
확률은 다 0보다 큼
= 확률의 정의가 깨지지 않게 구현해줄 수 있음
= exponential = 미분이 많이 쓰임.
젠장
괜찮아
한국말이다
살려주세요