Transformer
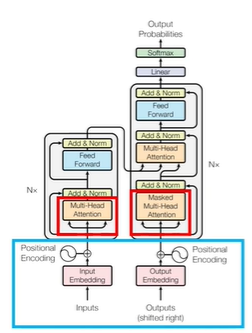
** 가장 핵심적인 아이디어
-
파란박스 = 입력방법: position encoding
: 기존의 RNN에서는 가능했던 순서처리가 안 되는 Transformer
: 단순한 병렬처리가 되기 때문에 -> 성능이 좋아짐 -> 속도가 빨라져서 한꺼번에 여러개할 수 있음
: 단점 - 순서를 알 수 없음 -
빨간박스 = 핵심모듈: (Masked) Multi head attention
: self-attention 매커니즘을 이용한 자연어 처리 향상 모듈
1) 왜 self - attention인지
2)key query value = 각각 해서 화살표가 3개
기존에는 key 와 query만 있었음
왜 value값이 들어가고 왜 좋은지? -
간단한 참고 도구
-
(파란부분)성능향상1: skip connection
: multihead attention의 output dimension과 input의 크기가 같아야 함 -
(빨간부분)성능향상2: layer normalization
- transformer
- 기계번역 task에서 기존의 연구들보다 성능적으로 우수
- 병렬적으로 처리가 가능한 모델 -> time complexity 감소
- 이후에 사용되는 Bert, GPT모델에서 일반화에 강점이 있다는 게 확인됨
: 자연어는 데이터의 랩을 얻는게 어렵고 처리하는게 어려움 - 이번 클립에서는 Transformer의 모듈별로 자세한 메커니즘을 공부
- positional Encoding(Transformer)
왜 필요한가?
- 자연어 자체가 문장에 순서가 존재. 영어도 순서가 중요.
- 순서를 고려하기 위한 다른 모델이 필요없음
- 병렬처리를 해야ㅎ서 느리긴 함
어떻게 줄까?
-
단어 순서대로 숫자를 카운팅하다보면,
: 숫자가 너무 빨리 커져서 weight 학습시 어려움이 있다.
: (CNN에서의 initialization method를 생각) -
단어 순서대로 숫자를 카운팅후 정규화하면, : 0부터 1사이이므로 학습 weight는 안정적.
: 그런데 두번째 단어는 같은 값을 할당해야하는데 단어의 길이가 다를 경우 값이 변함.
: 처리가 힘들고, 길이에 마다 성능이 천차만별일 수 잇음 -
단어 순서대로 벡터로 표현할 경우?
: 가변적인 길이에 상관없이 같은 벡터 할당 가능
: 단어 순서끼리의 거리가 달라진다 -
연속함수이며 주기함수인 sin과 soc를 이용하자
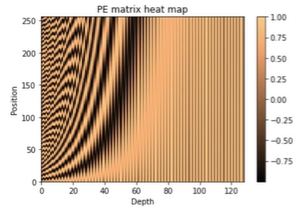
-
0부터 250까지 포지션
250까지 가다보면 훨씬 프리퀀시가 낮음
: 차원은 128
= 벡터의 차원에 따라서 진동수가 줄어든다
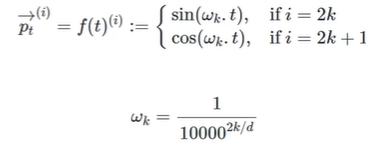
-
p = 포지션
i = depth
wk = 진동수
2k = 포지션의 길이
= 이렇게 복잡한 방법이 각도를 기준으로 상대적인 거리가 같게 만들어준다
- 요약
: 기존의 RNN방법과는 달리 위치 정보를 얻을 수 없는 Transformer의 input embedding
: 이를 해결하기 위해서 positional Encoding을 사용
- multi-head self-attention(Transformer)
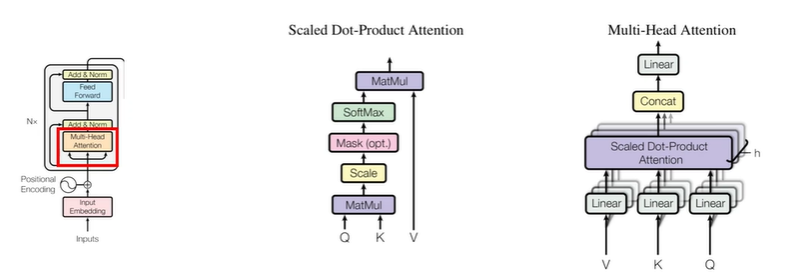
- key, quary, value attention을 기반으로
- scaled Dot-product attention을 사용함
예) I am a teacher
1. teacher는 am 과 i와 연관이 있을 것이다
2. am과 i가 연관이 되는 근거는 서로 다르다
INTRO
- 문장을 이해할 때 각각의 단어는 서로 영향을 끼친다 = attention
- 그 강도는 다르다 = key value quary
key값이 어떤 의미를 가지냐. 주어나 동사 등에 따라 value값에 더해줌.
: 문장구조상 목적어랑 목적보어관계 처럼 - 연관의 근거는 다 다르다 = multi head
ATTENTION
- T번째 ATTENTION스코어는 hidden에 각각의 attention 모듈을 더해줘서, 가장 큰 거에 영향받음
-> 기존의 attention기법의 경우에는 key와 query만 존재
-> 그러나 transformer의 attention의 경우 value까지 존재
-> 문장을 이해할 떄 단어들은 서로 영향을 끼치며 (Attention)/ 그 강도는 다르다(key 또는 value)
-> 이 단어에 대한 벡터는 (Q) 주어진 단어들에 대해 유사한 정도 만큼 (K) 고려하고, 각 주어진 단어들은 V만큼의 중요도를 가진다
; a는 중요도가 작다는 것.
- 단어에 대한 쿼리 벡터를 곱함.
quary(I love you)에 대해 key값을 구하고, value값을 곱해줘서(a는 작고 teacher은 크고) 유사값을 구함

- layer normalization
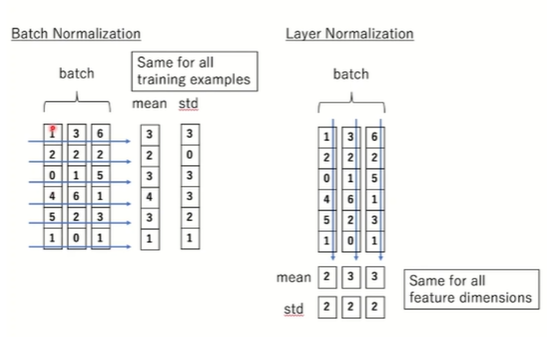
- betch normalization
데이터가 미분값을 구해서 loss값이 가장 낮은 것으로 거쳐갈 때, 데이터 형식을 다 같게 해주기 위해 나옴
크기에 따라 성능이 달라짐. 크기가 크면 의미가 있어서 표준화하면 성능이 좋은데
std가 3이되면 거의 의미가 없음 - layer normalization
batch별로 가 아니라 feature별로 normalization을
C(채널)이나 H, W등 각각의 feature에 따라
- final
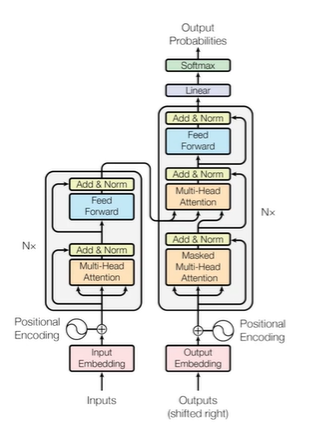
- input이 들어가면 embedding을 통해 쿼리가 나오고, position encoding을 해주면 - Q, K, V를 해줘서 Multi head attention을 해주고 - 대신 dimension이 같아야 한다 skip connection을 해줘야하니까 - 거쳐서 나온 걸 layer nomalization을 해주고 - skip connection을 해줘서 최적의 x'k를 뽑아준다
