
주제
- 이디야커피는 정말 스타벅스 커피 주변에 위치에 있을까?
스타벅스 데이터 수집
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from tqdm import tqdm_notebook1. 페이지 접속
url_sb = "https://www.starbucks.co.kr/store/store_map.do"
driver = webdriver.Chrome()
driver.get(url_sb)2. 지역 검색
search_tag = driver.find_element(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search > h3 > a')
action = ActionChains(driver)
action.click(search_tag)
action.perform()3. 서울 선택
search_tag = driver.find_element(By.CSS_SELECTOR, '#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a')
action = ActionChains(driver)
action.click(search_tag)
action.perform()4. 전체(서울) 선택
search_tag = driver.find_element(By.CSS_SELECTOR, '#mCSB_2_container > ul > li:nth-child(1) > a')
action = ActionChains(driver)
action.click(search_tag)
action.perform()5. 검색 결과 리스트 가져오기
driver.find_elements(By.CSS_SELECTOR, '#mCSB_3_container ul li')6. 데이터 수집
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
print(soup.prettify())
sbuck_list = soup.select("#mCSB_3_container ul li")
data_name = []
data_lat = []
data_lng = []
data_address = []
for i in range(len(sbuck_list)):
name = sbuck_list[i]["data-name"] # 각 반복에서 이름 가져오기
lat = sbuck_list[i]["data-lat"]
lng = sbuck_list[i]["data-long"]
data_name.append(name) # 이름을 리스트에 추가
data_lat.append(lat)
data_lng.append(lng)
address = sbuck_list[i].find("p", class_="result_details").text[:-9]
data_address.append(address)
datas = {
"StoreName": data_name,
"lat": data_lat,
"lng": data_lng,
"address": data_address
}
df = pd.DataFrame(datas)
df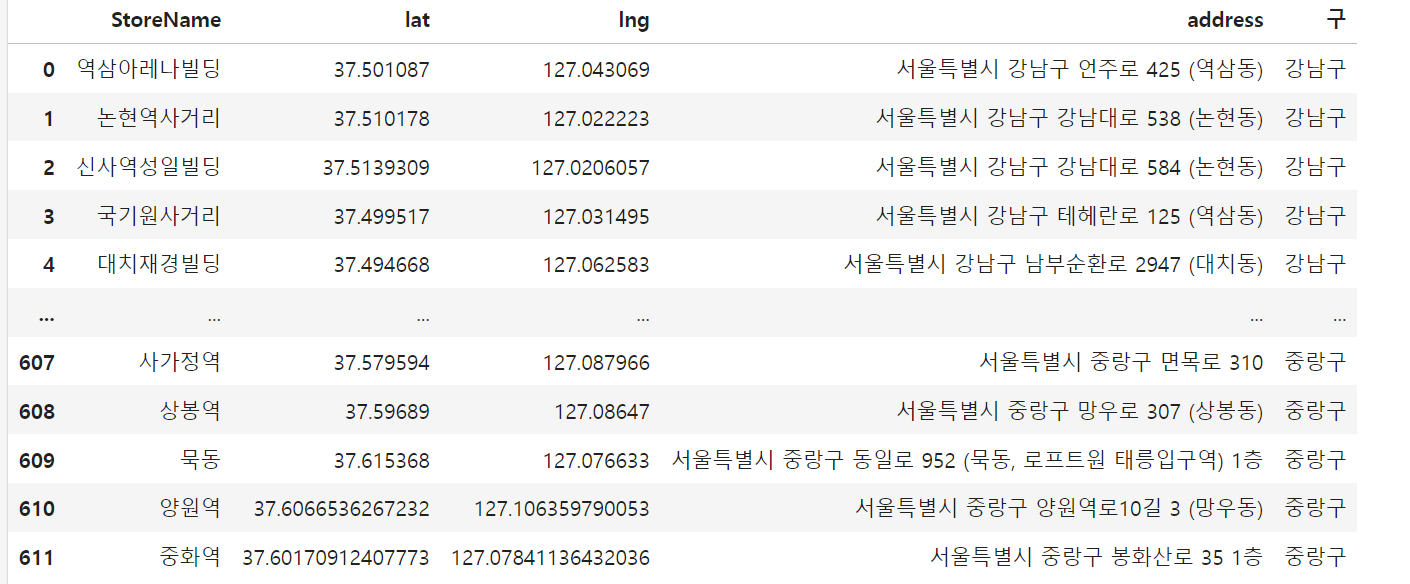
- 스타벅스의 데이터들을 가져오는 것은 수업시간에 비슷하게 다뤄봤던 부분들이라서 크게 어렵지는 않았다.
- 반복문을 3개씩 테스트를 해보며 데이터가 잘 끌어오는지를 검증해준 뒤 전체에 적용하여 끌고오면 수업에서 배운 것과 같이 데이터를 끌고 올 수 있었다.
이디야 데이터 수집
1. 페이지 접속
url_ed = "https://www.ediya.com/contents/find_store.html#c"
driver = webdriver.Chrome()
driver.get(url_ed)2. '주소' 검색
switch= driver.find_element(By.CSS_SELECTOR, "#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a").click()3. 검색어 클릭
search_click = driver.find_element(By.CSS_SELECTOR, "#keyword")
search_click.click()4. 검색결과 가져오기
🤦
- 이디야는 주소를 검색할 때, 스타벅스와는 다르게 주소를 직접 입력해야하는 방식이였다.
- 따라서 스타벅스에서 끌어온 '구' 데이터를 활용하여 검색결과를 가져오기로 하였다.
- 하지만 한 두시간동안 계속 오류가났다.. 왜인지 도무지 모르겠 자꾸 창이 꺼졌다는 메세지가 나와서 블로그를 찾아보니, 데이터양이 방대해서 생기는 오류이므로 "서울"을 추가하면 해결된다고 하길래 적용해줬더니 바로 됐다..(그치만 그래도 오래걸림!)
- 가만히 두면 이게 돌아가는건지 확인이 안될 수준이라서 tqdm으로 진행률을 확인해주었다

req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
print(soup.prettify())
# 스타벅스 "구"검색
df_sb["구"].unique()
gu_list = list(df_sb["구"].unique())
gu_list
# 서울 붙이기
gu_list = [str('서울 ') + gu for gu in gu_list]
gu_list5. 전체 반복문 수행
import time
from tqdm import tqdm_notebook
url_ed = "https://www.ediya.com/contents/find_store.html"
driver = webdriver.Chrome()
driver.get(url_ed)
time.sleep(10)
for gu in tqdm_notebook(gu_list):
# 주소 창 입력
driver.find_element(By.CSS_SELECTOR, value='#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a').click()
# 검색어 입력 창 클릭
keywords = driver.find_element(By.CSS_SELECTOR, "#keyword")
# 돋보기
click_btn = driver.find_element(By.CSS_SELECTOR, "#keyword_div > form > button")
time.sleep(2)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
ed_list = soup.select('#placesList li')
title = soup.select_one('dt').text
address = soup.select_one('dd').text
ediya = []
# 각 구를 검색하여 데이터 수집
for gu in gu_list:
keywords.clear()
keywords.send_keys(gu)
click_btn.click()
time.sleep(2)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
ed_list = soup.select('#placesList li')
for data in ed_list:
title = data.select_one('dt').text
address = data.select_one('dd').text
ediya.append({
'title' : title,
'address' : address
})6. '구'추가
# 구 col추가
data_gu_ed = []
for n in range(len(df_ed)):
data_gu_raw = df_ed['address'][n].split()
gu = data_gu_raw[1]
data_gu_ed.append(gu)
df_ed['gu'] = data_gu_ed
df_ed가설 check
이디야는 전략적으로 스타벅스 옆에 있을까?
🤷♂️
- 우선 옆에 있다라는 것이 어느정도로 가까워야할까 고민을했다. 현재 대한민국 특히나 서울은 카페가 정말 많다.
- 따라서 웬만한 거리로는 전략적으로 옆에 위치한다라고 할 수 없다고 생각하여, 거리가 10m터 이내면 옆에 위치한다고 설정을 해주었다.
1. googlemaps 사용
import googlemaps
gmaps_key = "개인키값"
gmaps = googlemaps.Client(key=gmaps_key)
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
get_ipython().run_line_magic("matplotlib", "inline")
path = "C:/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
rc("font", family = "Arial Unicode MS")
elif platform.system() == "Windows":
font_name = font_manager.FontProperties(fname = path).get_name()
rc("font", family = font_name)
else:
print("Unknown system")
import json
import folium
import warnings2. 위도, 경도 추출
2-1) 기존 데이터에서 추출(이디야)
- 스타벅스 데이터는 위도, 경도가 잘 나와있지만, 이디야의 경우 일부 데이터의 위도, 경도가 (0, 0)으로 나와있어 사용할 수가 없었다
## 기존 데이터에서 위도 경도 추출 import re from bs4 import BeautifulSoup lat_ed = [] lng_ed = [] for item in ed_list: onclick_attr = item.find("a")["onclick"] # onclick 속성의 값을 파싱하여 위도와 경도를 추출합니다. lat_lng_info = onclick_attr.split("'")[1:4:2] # 홀수 인덱스에 위도, 짝수 인덱스에 경도가 있습니다. lat_ed.append(lat_lng_info[1]) lng_ed.append(lat_lng_info[0]) lat_ed, lng_ed # 데이터 부정확해서 사용 불가능
2-2) googlemaps 사용
from tqdm import tqdm
lat = []
lng = []
for idx, row in tqdm(df_ed.iterrows()):
if not row["address"] == "Multiple location":
target_name = row["address"]
# print(target_name)
gmaps_output = gmaps.geocode(target_name)
# 검색 후 해당되는 위도, 경도 출력됨
location_output = gmaps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
# 지리정보에 해당되는 값만 추출
else:
lat.append(np.nan)
lng.append(np.nan)
df_ed["lat"] = lat
df_ed["lng"] = lng
df_ed.tail()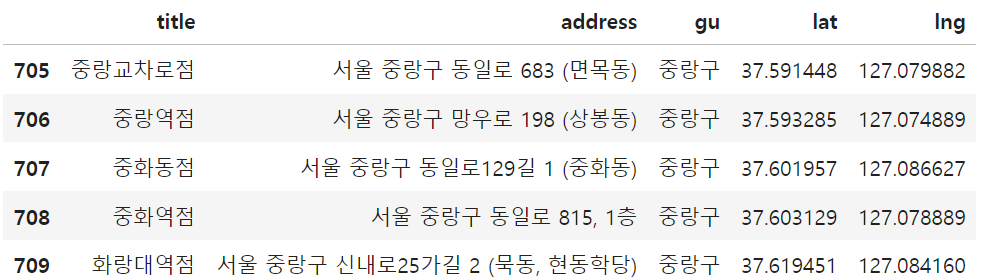
2. 브랜드 col 추가
df_ed.rename(columns = {"title": "StoreName"})
df_ed["Brand"] = "EDIYA"
df_ed.tail()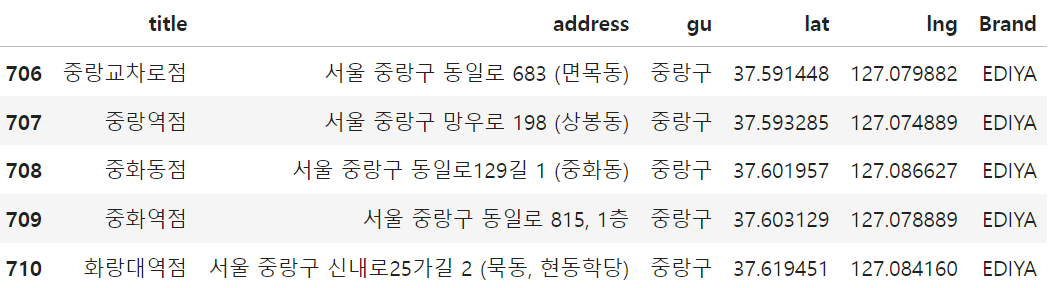
3. 지도 생성
3-1) 위도, 경도로 마커 찍어서 눈으로 확인
# 지도 생성
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
get_ipython().run_line_magic("matplotlib", "inline")
path = "C:/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
rc("font", family = "Arial Unicode MS")
elif platform.system() == "Windows":
font_name = font_manager.FontProperties(fname = path).get_name()
rc("font", family = font_name)
else:
print("Unknown system")
import json
import folium
import warnings
# 서울 지도
# my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11)
# folium.Choropleth(
# geo_data = geo_str,
# fill_color = 'PuRd'
# ).add_to(my_map)
# my_map
my_map = folium.Map(
location = [37.5502, 126.982],
zoom_start = 15,
tiles = "OpenStreetMap"
)
for idx, rows in df_sb.iterrows():
folium.Marker(
location = [rows["lat"], rows["lng"]],
icon = folium.Icon(
icon = "star",
prefix = "fa",
color = "darkgreen"
)
).add_to(my_map)
for idx, rows in df_ed.iterrows():
if not row["address"] == "Multiple location":
folium.Marker(
location = [rows["lat"], rows["lng"]],
icon = folium.Icon(
icon = "coffee",
color = "blue",
prefix = "fa"
)
).add_to(my_map)
my_map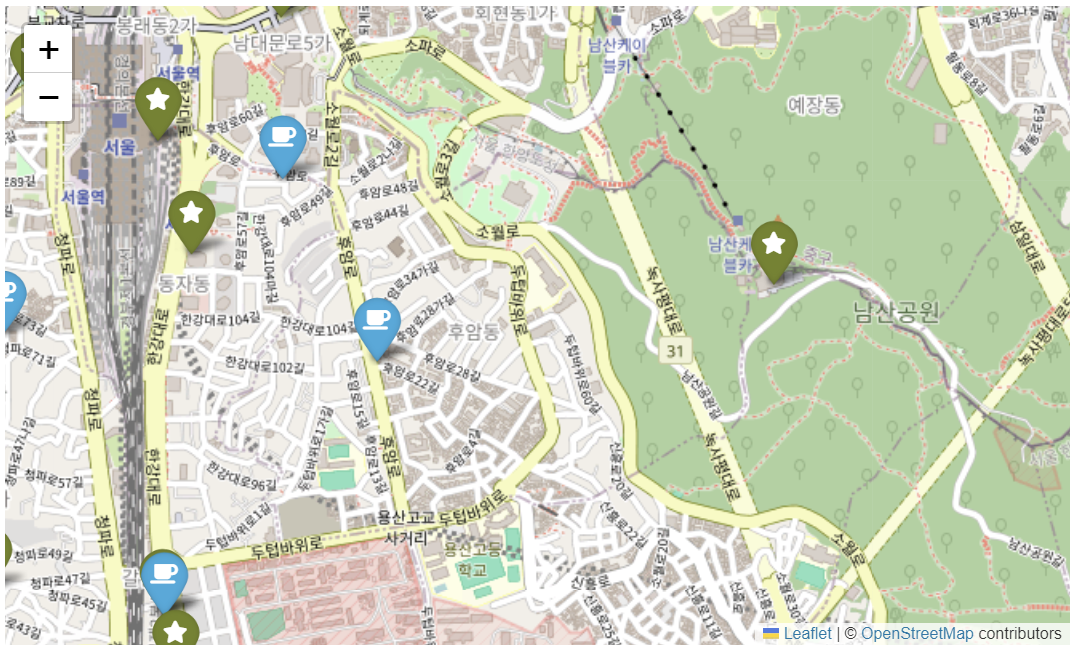
🤷♂️
- 단순하게 위도, 경도를 마커로 찍어서 육안으로 확인해봤을 때는 이디야의 위치가 스타벅스 옆에 전략적으로 위치한다고 볼 수 없다.
- 하지만 육안으로 확인한 것은 정확성이 떨어짐
3-2) 위도, 경도를 기준으로 거리 측정
from geopy.distance import distance
n = 0
for idx_sb, loc_sb in tqdm(df_sb.iterrows()):
sb_location = (loc_sb["lat"], loc_sb["lng"])
for idx_ed, loc_ed in tqdm(df_ed.iterrows()):
if loc_ed["address"] != "Multiple location":
ed_location = (loc_ed["lat"], loc_ed["lng"])
dist = distance(sb_location, ed_location).m
# m단위로 추출
if dist <= 10:
folium.Marker(
location=ed_location,
icon=folium.Icon(
icon="exclamation mark",
color="red",
prefix="fa"
)
).add_to(my_map)
n += 1
my_map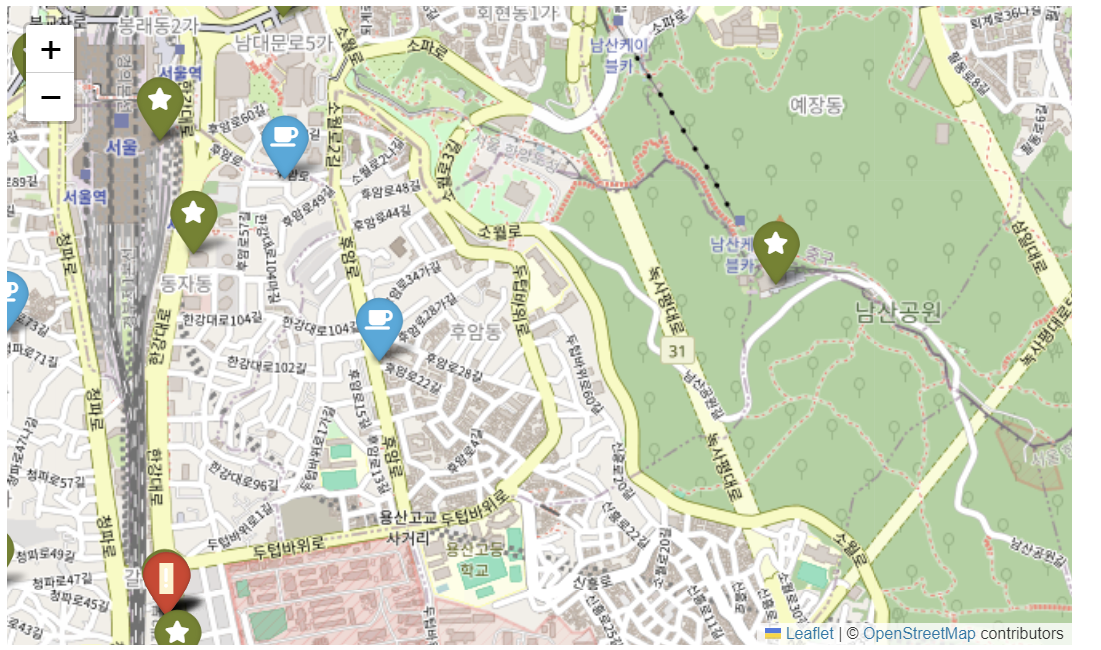
🤦
- 인접하게 있는걸 파악하는건 거리를 측정하는게 best라고 생각하여 이렇게 했는데 시간이 진짜 너무 오래걸린다...이렇게 오래 걸릴 줄은 생각을 못했다..
구 별로 나눠서했으면 좀 더 빨라졌을것 같기도...?
# 전체 스벅 매장 수, 전체 이디야 매장 수, 인접(10m)한 매장 수 len(df_sb["StoreName"]), len(df_ed["title"]),n

# 이디야 전체 매장 중 비율 percentage = (n/len(df_ed["title"]))*100 percentage

결론
- 서울시 내 전체 이디야 매장 중, 스타벅스 매장에 인접한(10m이내) 곳에 위치한 이디야 매장은 고작 0.84%이므로, 이디야가 전략적으로 스타벅스 옆에 위치한다는 가설을 거짓이다.

할 거면 제대로 하자