주요 학습내용
1. 시계열 데이터란
2. fbprophet / prophet
3. 방문자수 예측하기
I. 시계열 데이터란
시간의 흐름에 대해 특정 패턴과 같은 정보를 가지고 있는 경우를 시계열 데이터라고 함
- 시계열 데이터 중 주기성을 가지고 있는 데이터를 다루는 경우를 Seasonal Time Series라고 한다
II. fbprophet / prophet
예측값 그래프로 나타내기
예제 1
1) 원데이터 생성
time = np.linspace(0, 1, 365*2)
result = np.sin(2*np.pi*12*time)
ds = pd.date_range("2018-01-01", periods = 365*2, freq = "D")
df = pd.DataFrame({"ds":ds, "y":result})
df.head()
df['y'].plot(figsize = (10, 6));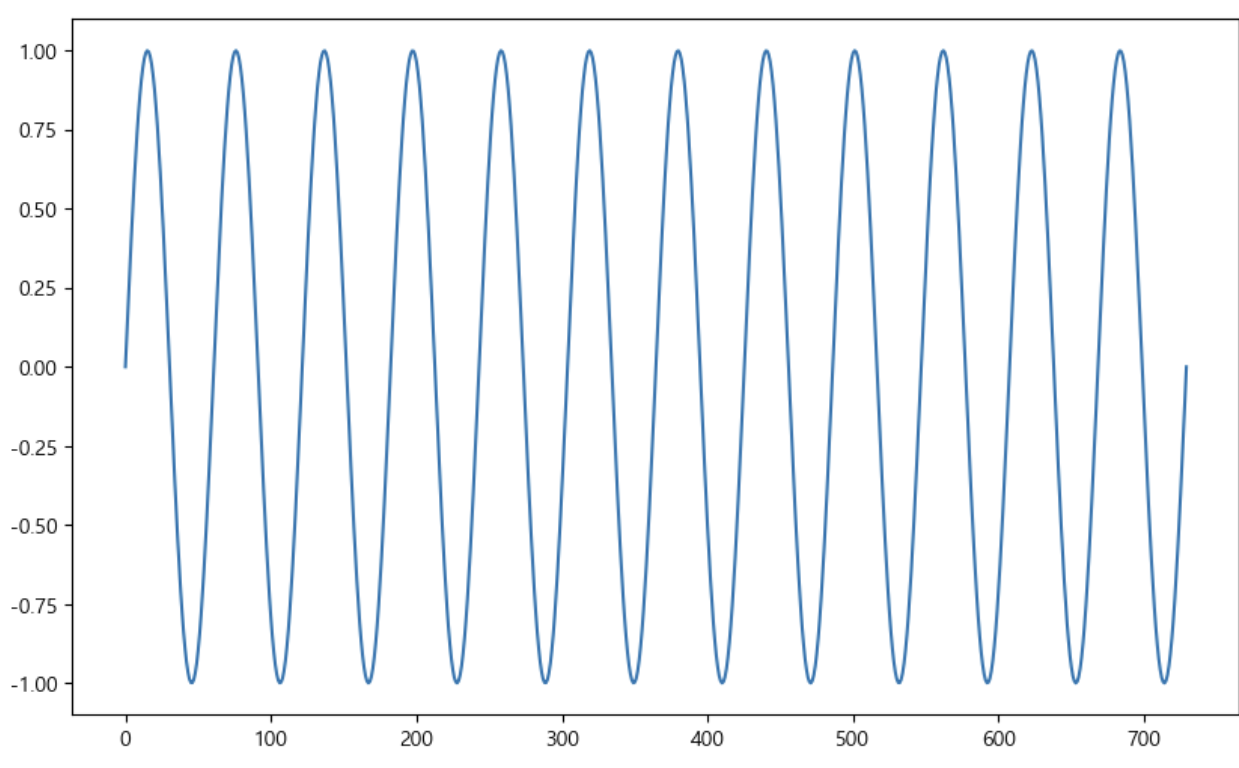
2) Prophet 사용하여 예측값 만들기(periods = 30)
from prophet import Prophet
m = Prophet(yearly_seasonality = True, daily_seasonality = True)
m.fit(df);
future = m.make_future_dataframe(periods = 30)
forecast = m.predict(future)
m.plot(forecast);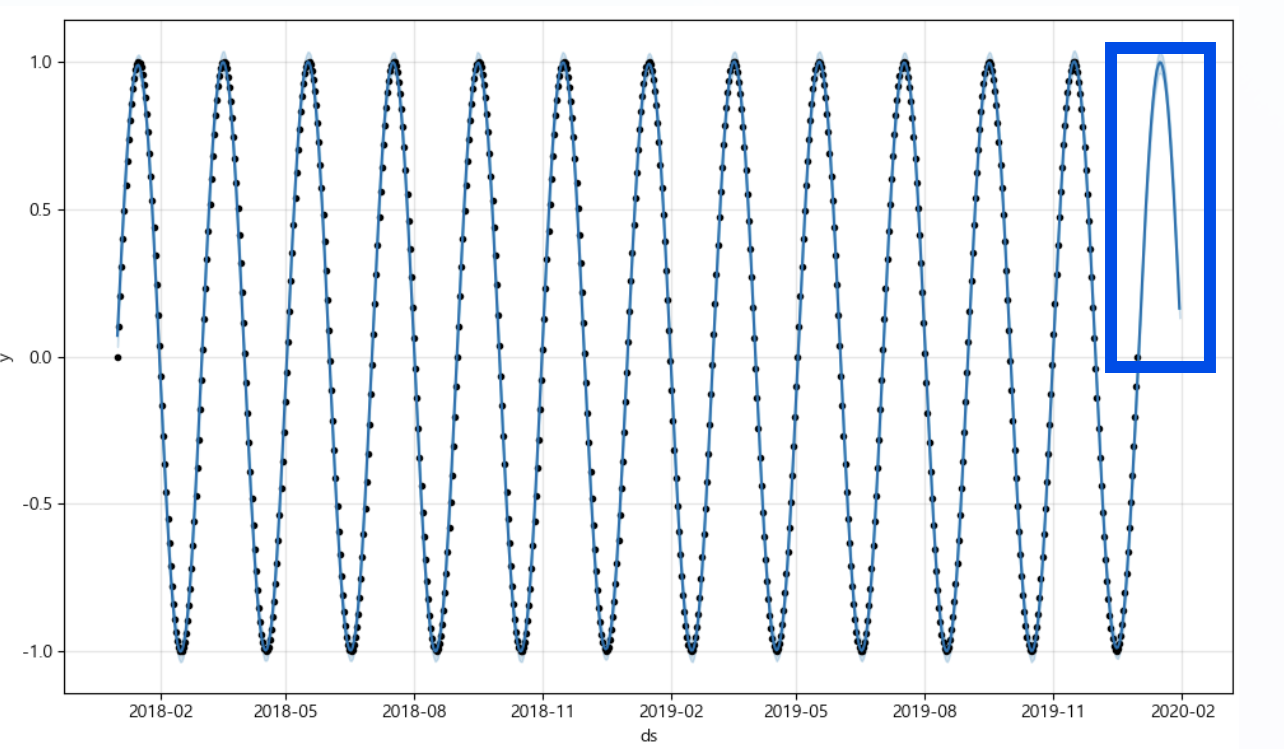
예제 2
- result에 time 추가
1) 원데이터 생성
time = np.linspace(0, 1, 365*2)
result = np.sin(2*np.pi*12*time) + time
ds = pd.date_range("2018-01-01", periods = 365*2, freq = "D")
df = pd.DataFrame({"ds":ds, "y":result})
df['y'].plot(figsize = (10, 6));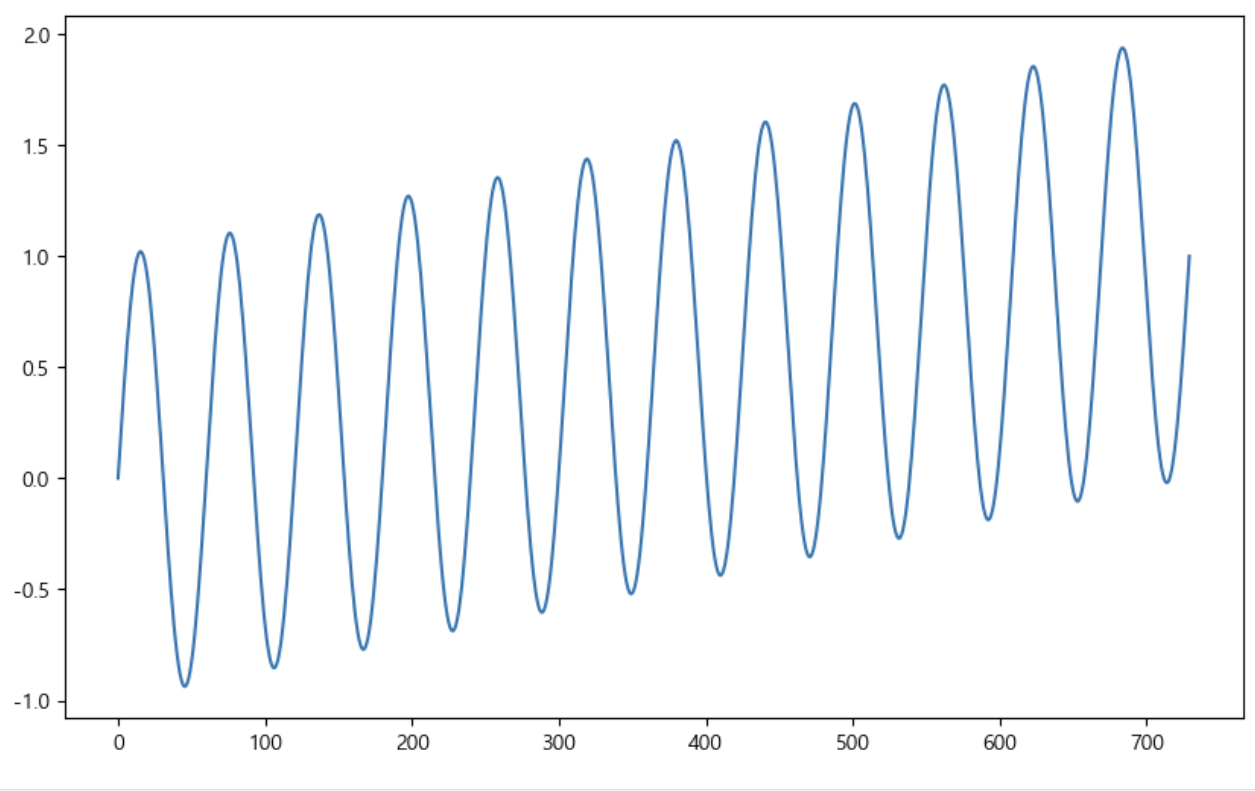
2) Prophet 사용하여 예측값 만들기 + 시각화 (periods = 30)
m = Prophet(yearly_seasonality = True, daily_seasonality=True)
m.fit(df);
future = m.make_future_dataframe(periods = 30)
forecast = m.predict(future)
m.plot(forecast)
# 예측한 값 시각화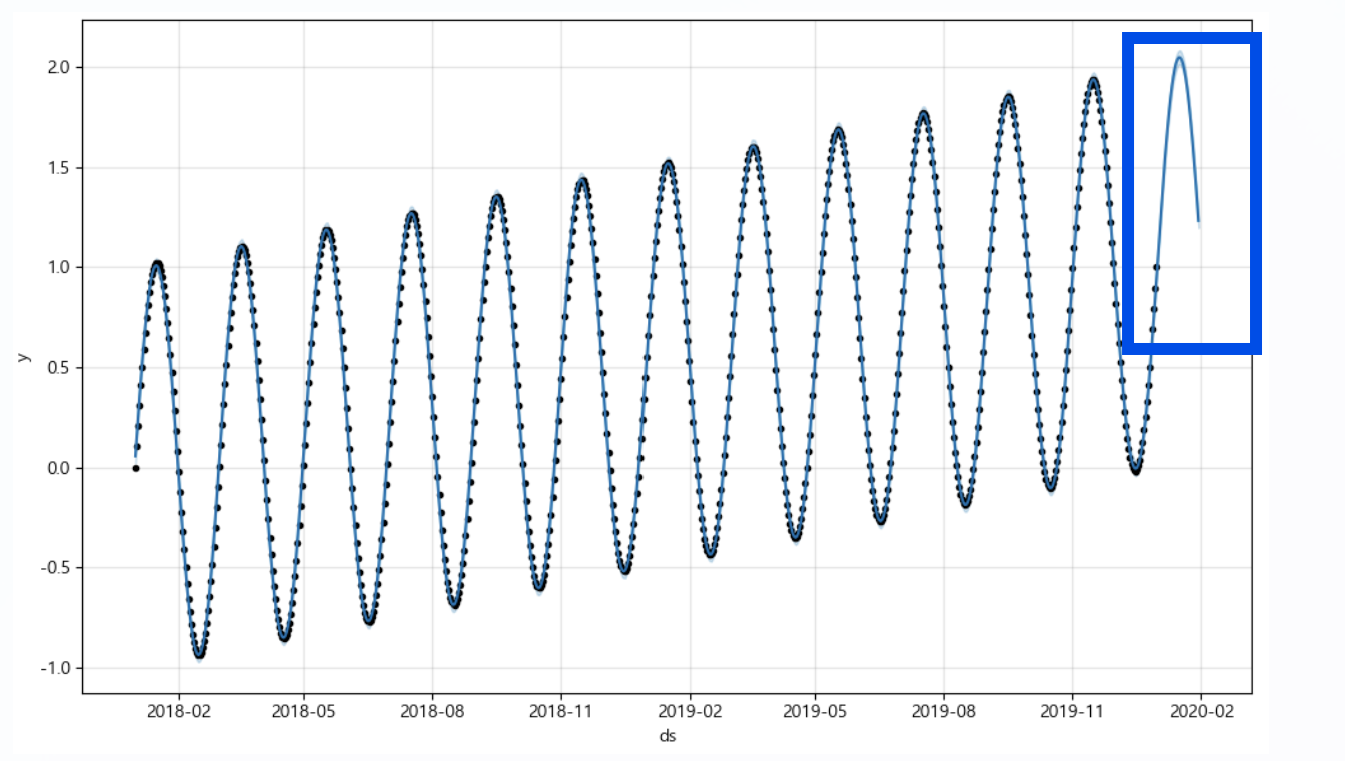
예제 3
- result에 random값 추가
1) 원데이터 생성
time = np.linspace(0, 1, 365*2)
result = np.sin(2*np.pi*12*time) + time + np.random.randn(365*2)/4
ds = pd.date_range("2018-01-01", periods = 365*2, freq = "D")
df = pd.DataFrame({"ds":ds, "y":result})
df['y'].plot(figsize = (10, 6));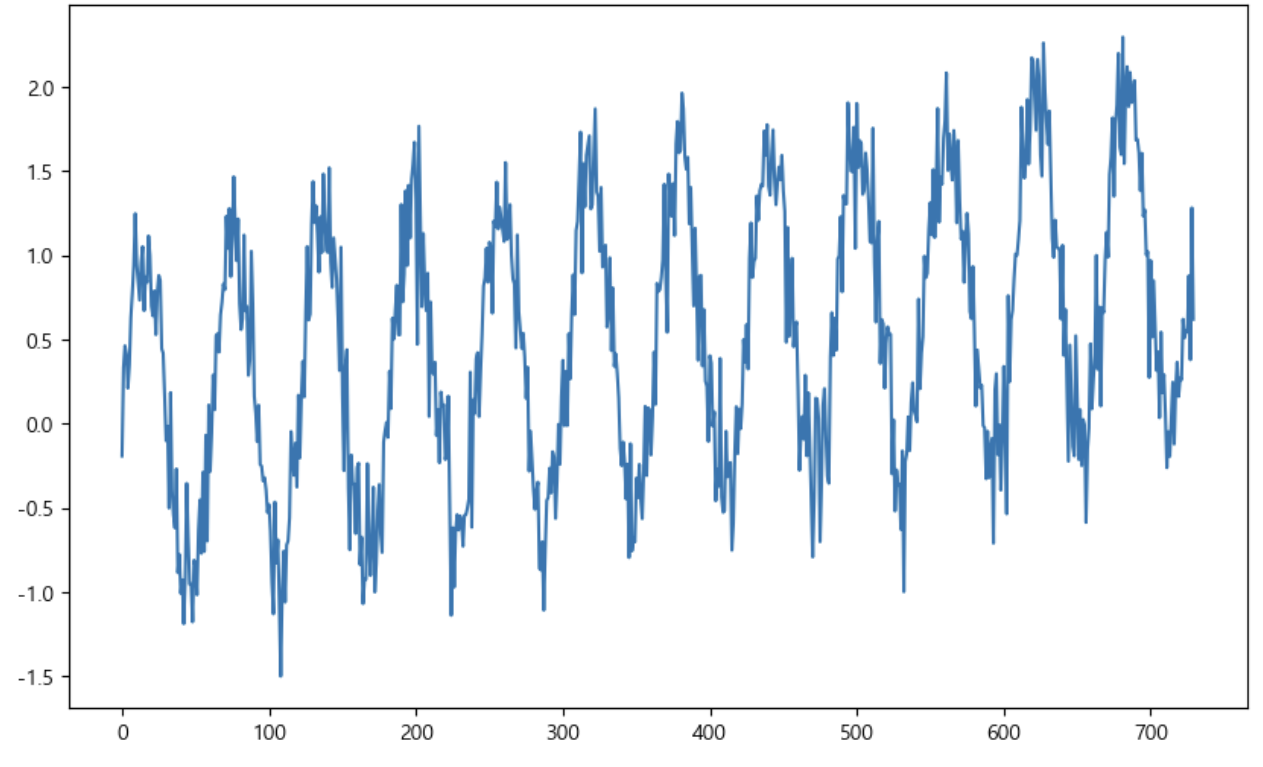
2) Prophet 사용하여 예측값 만들기 + 시각화 (periods = 30)
m = Prophet(yearly_seasonality = True, daily_seasonality=True)
m.fit(df);
future = m.make_future_dataframe(periods = 30)
forecast = m.predict(future)
m.plot(forecast)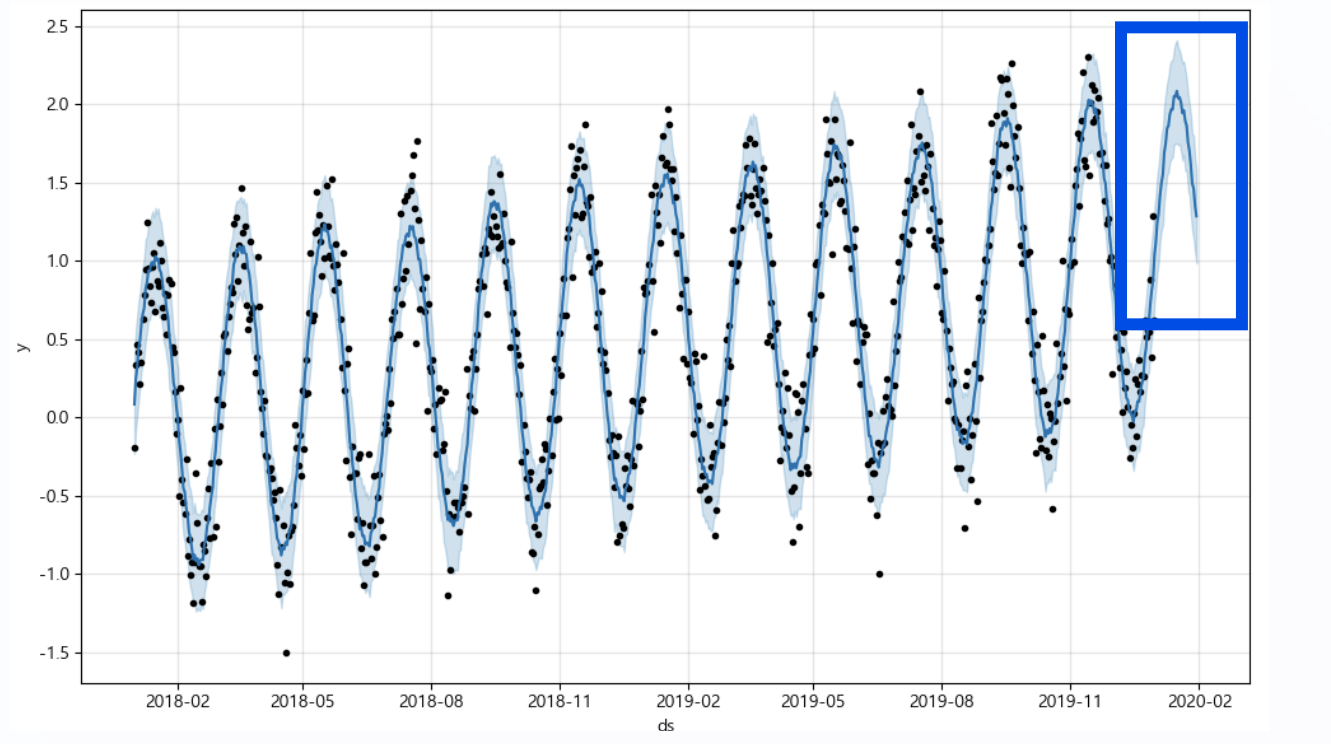
III. 방문자수 예측하기
- 사용자료 : pinkwink 블로그(https://pinkwink.kr/) 방문자 데이터
1) import module
import pandas as pd
import pandas_datareader as web
import numpy as np
import matplotlib.pyplot as plt
from prophet import Prophet
from datetime import datetime
# 그래프 그릴 것이기 때문에 아래도 추가
%matplotlib inline2) 데이터 읽어오기
pinkwink_web = pd.read_csv(
"../data/05_PinkWink_Web_Traffic.csv",
encoding = "utf-8",
thousands = ",",
names = ["date", "hit"],
index_col = 0
)
pinkwink_web.info()
- hit에 null값 있기 때문에 해당 부분 제외하고 재할당
pinkwink_web = pinkwink_web[pinkwink_web["hit"].notnull()]
pinkwink_web.head()
3) 전체 데이터 그려보기
pinkwink_web["hit"].plot(figsize=(12, 4), grid=True);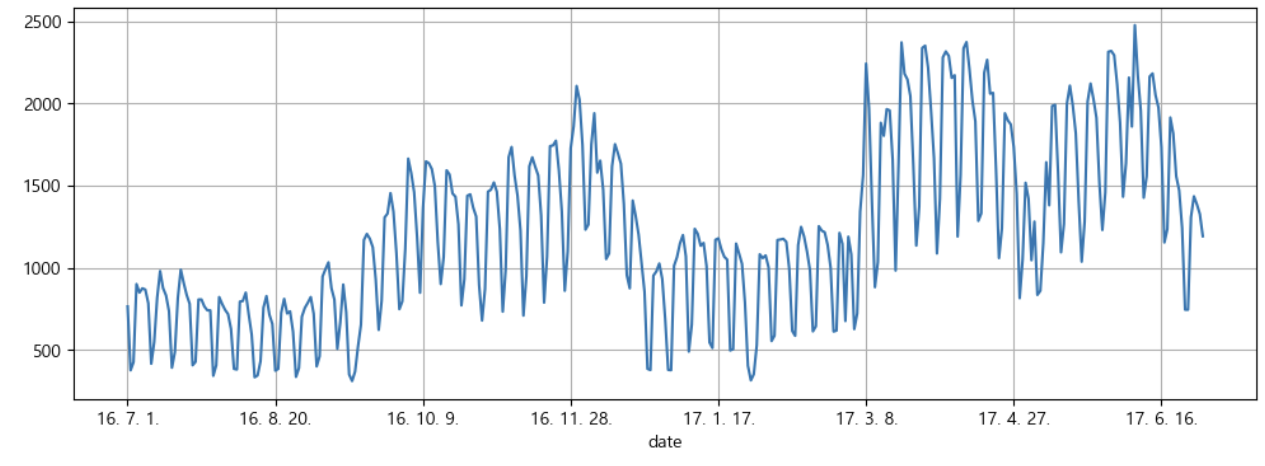
4) trend분석을 시각화하기 위한 x축 값 만들기
time = np.arange(0, len(pinkwink_web))
traffic = pinkwink_web["hit"].values
fx = np.linspace(0, time[-1], 1000)
# linspace : linear : 1차원 배열을 만듬5) Error 계산할 함수
def error(f, x, y):
return np.sqrt(np.mean((f(x)-y)**2))
f1p = np.polyfit(time, traffic, 1)
f1 = np.poly1d(f1p)
f2p = np.polyfit(time, traffic, 2)
f2 = np.poly1d(f2p)
f3p = np.polyfit(time, traffic, 3)
f3 = np.poly1d(f3p)
f15p = np.polyfit(time, traffic, 15)
f15 = np.poly1d(f15p)6) 시각화
plt.figure(figsize = (12, 4))
plt.scatter(time, traffic, s = 10)
plt.plot(fx, f1(fx), lw=4, label='f1')
plt.plot(fx, f2(fx), lw=4, label='f2')
plt.plot(fx, f3(fx), lw=4, label='f3')
plt.plot(fx, f15(fx), lw=4, label='f15')
plt.grid(True, linestyle="-", color = "0.75")
plt.legend(loc = 2)
plt.show()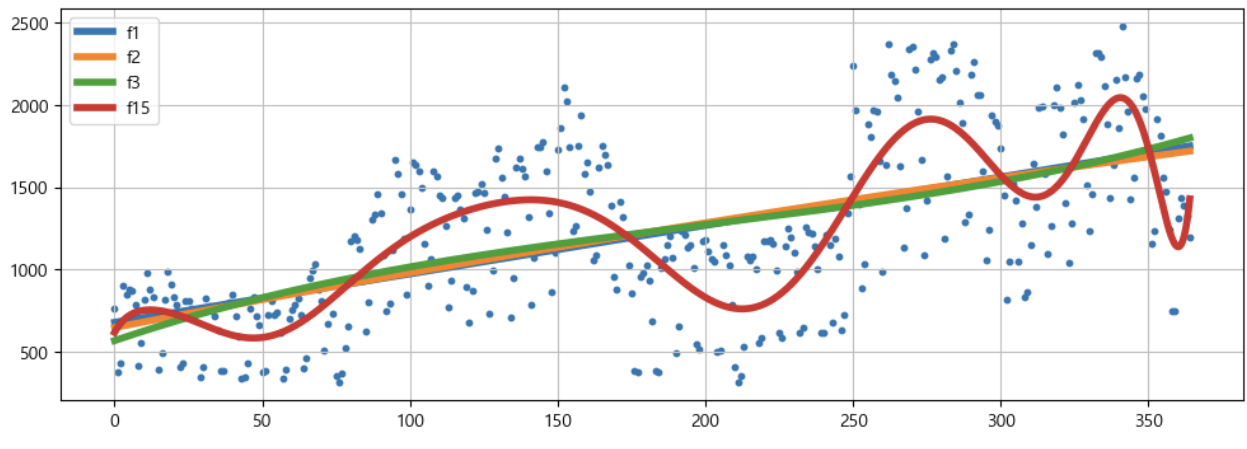
7) DataFrame 생성
df = pd.DataFrame({"ds": pinkwink_web.index, "y":pinkwink_web["hit"]})
df.reset_index(inplace = True)
df
- 날짜 형식 변경
# 날짜 형식 변경
df["ds"] = pd.to_datetime(df["ds"], format="%y. %m. %d.")
df
- 첫 date column삭제
del df["date"]
df.head()
8) 학습시키기 + 데이터 예측(periods = 60)
m = Prophet(yearly_seasonality = True, daily_seasonality = True)
m.fit(df);
future = m.make_future_dataframe(periods = 60)
forecast = m.predict(future)
forecast[["ds", "yhat", "yhat_lower", "yhat_upper"]].tail()예측 결과는 상한/하한의 범위를 포함해서 얻어진다
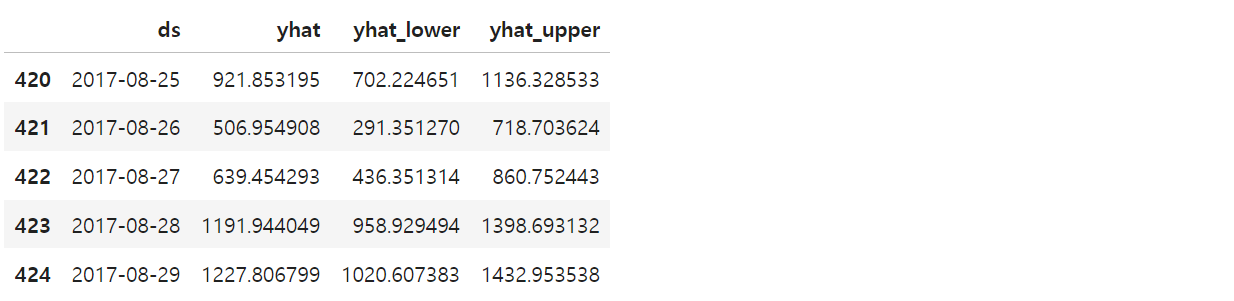
9) 그래프로 나타내기
m.plot(forecast)
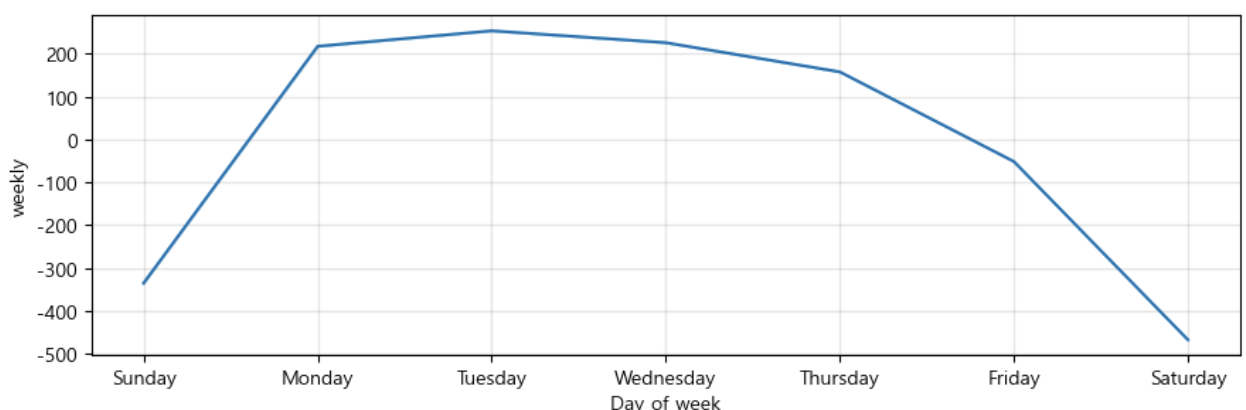
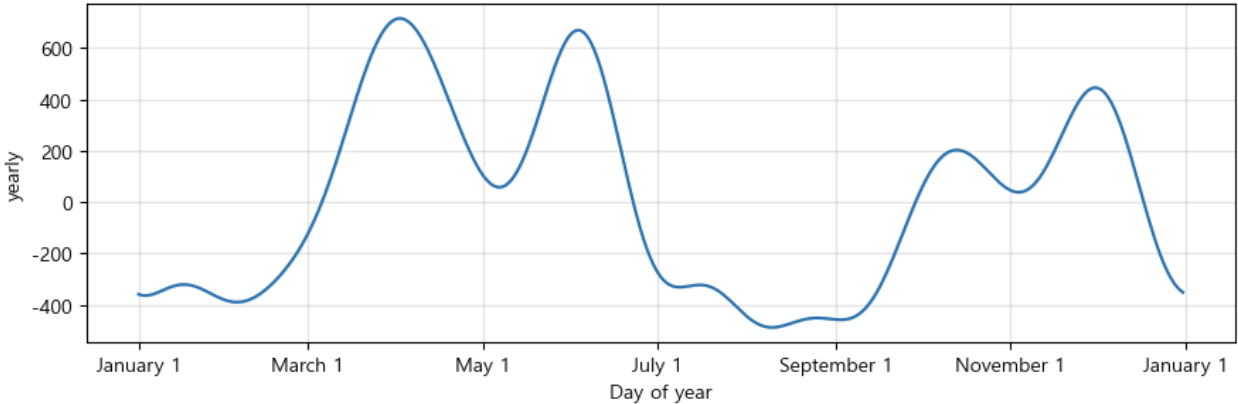
m.plot_components(forecast);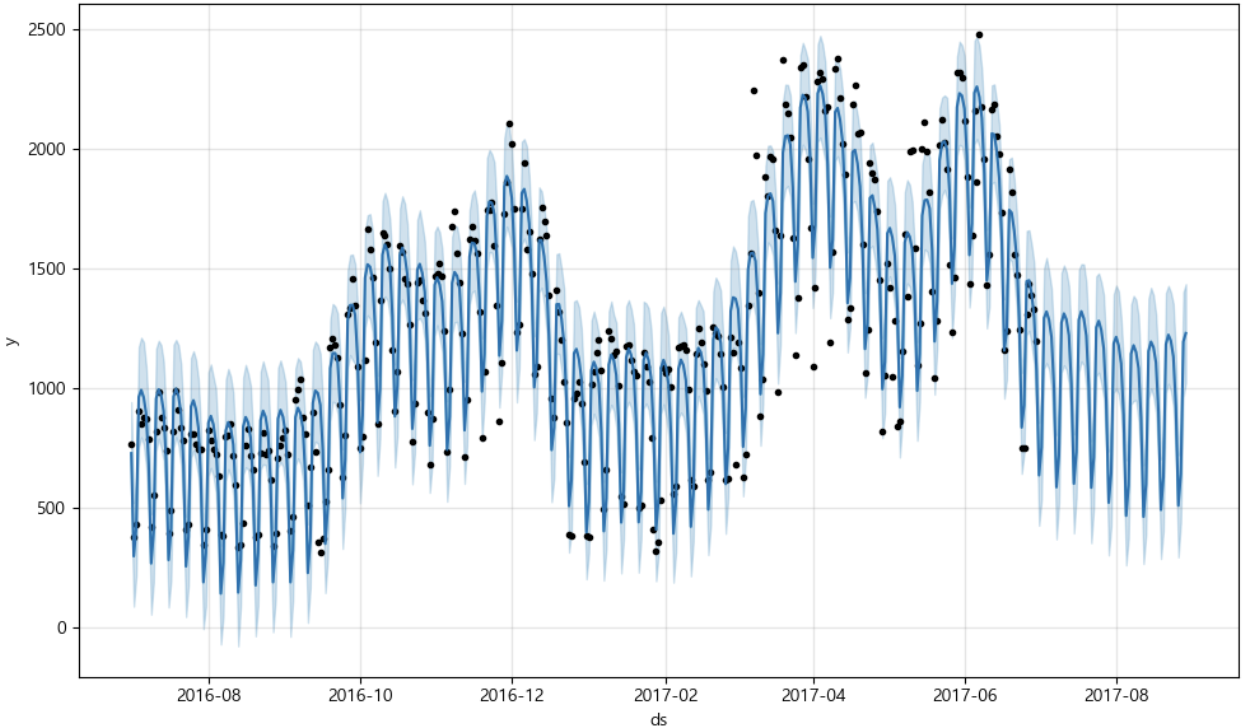

할 거면 제대로 하자