
주요 학습내용
Pandas기초
1. Series
2. DataFrame
Pandas
- Pandas는 데이터의 수집, 조작 및 분석에 활용되는 오픈 소스 라이브러리이다. Python을 기반으로 작동한다
- R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀이라고 받아들여도 됨
- 누군가 스테로이드를 맞은 엑셀로 표현함
- pandas는 통상 pd로 import하고
- 수치해석적 함수가 많은 numpy는 통상 np로 import한다
기초 사용법
1) 페이지 나누기/줄 생성 : "---" + esc + "m"

2) markdown : esc + "m"
3) # * 개수로 글자 크기 지정 변경 가능

I. Series
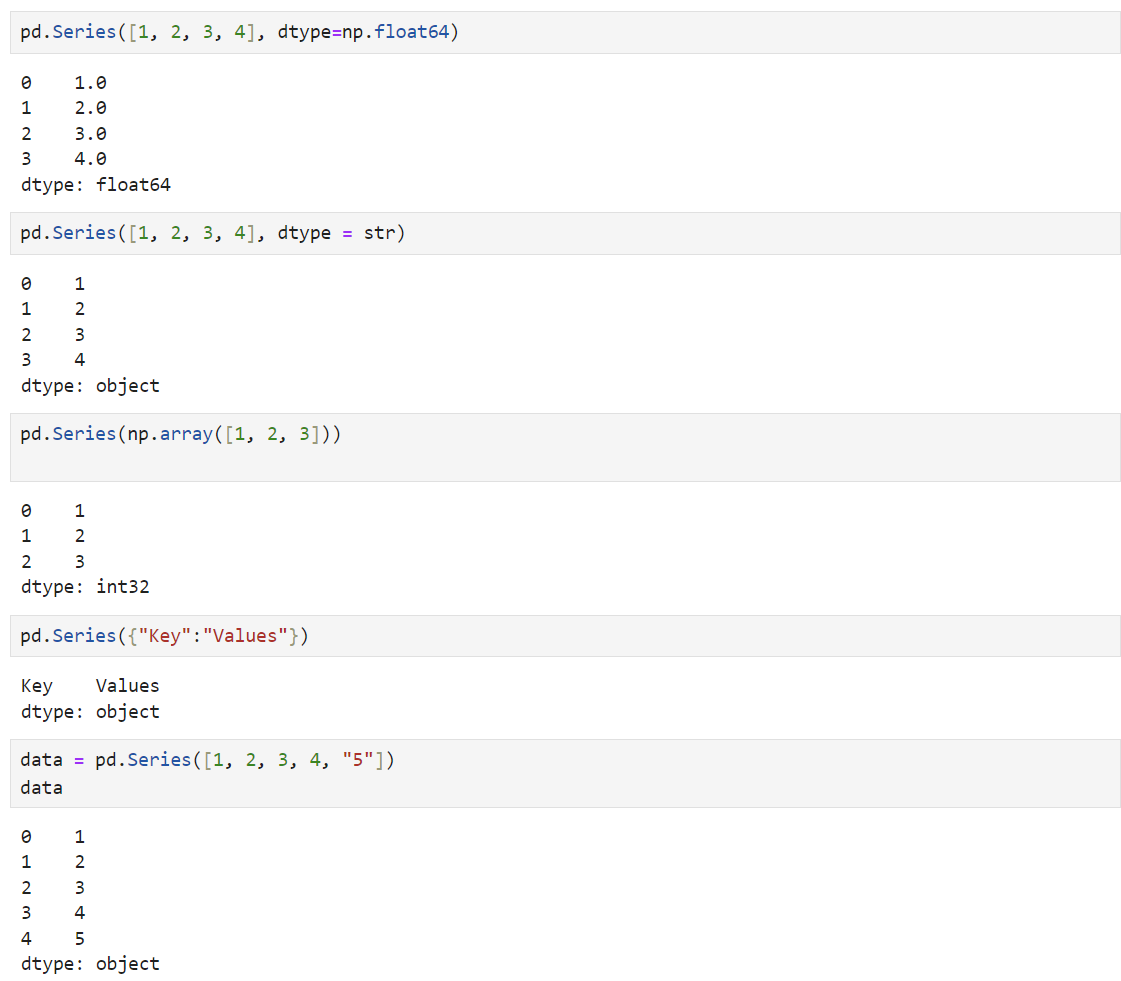
- Pandas의 데이터형을 구성하는 기본은 Series이다
- Pandas Series는 인덱싱된 데이터의 1차원 배열이다
- 명시적 인덱스를 사용할 수 있음
- (BUT) 명시적 인덱스를 사용하여도 묵시적 인덱스(정수형)를 사용해도 접근 가능
- pd.Series([데이터 입력])를 통해 생성 가능
- 📌 index와 value로 이루어져 있음
- 📌 여러가지 데이터를 입력을 할 수는 있지만 한가지 데이터 타입만 가질 수 있음
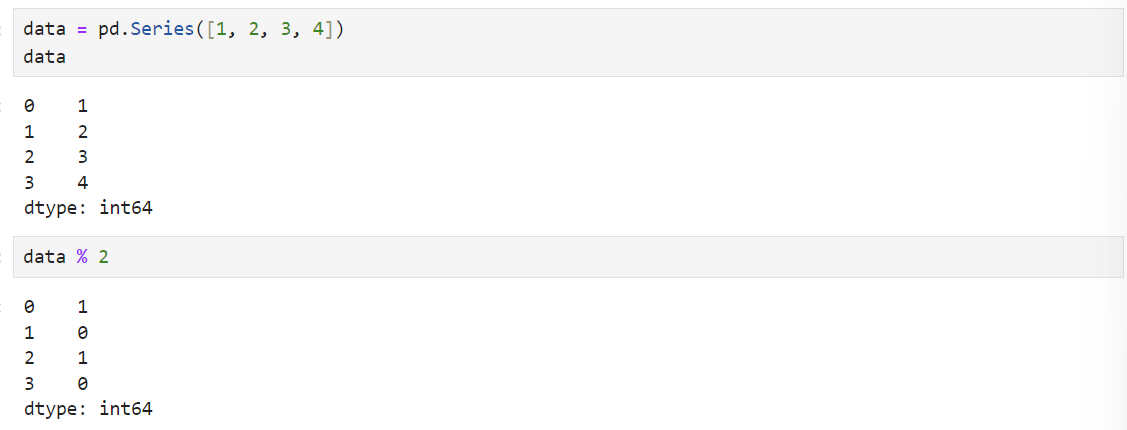
Case 1) 짝수를 찾고 싶을 경우:
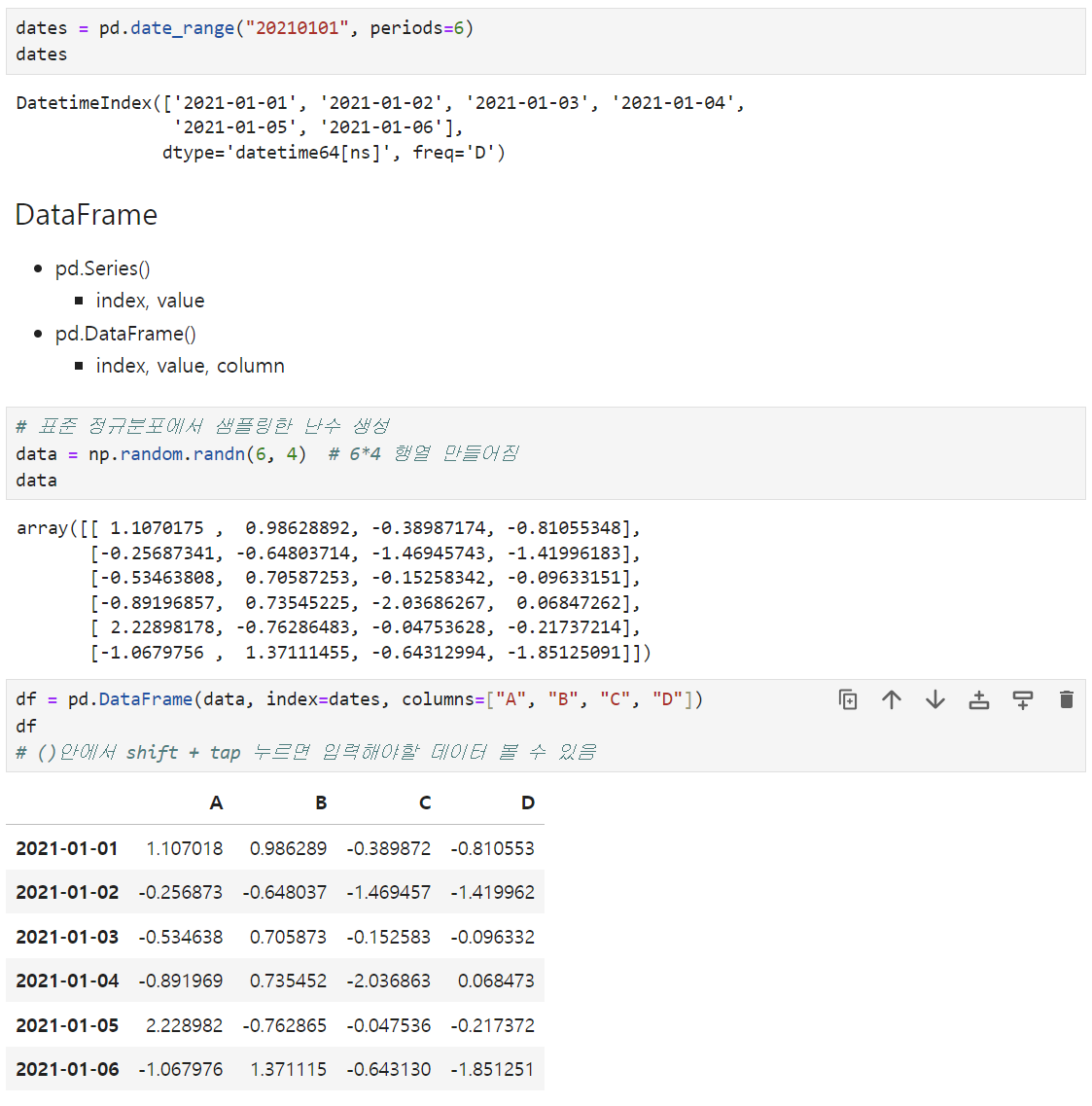
Case 2) 날짜 데이터 만들기
- pd.date_range("yyyymmdd(문자열형태의 날짜데이터)", periods=기간입력)

II. DataFrame
- 📌 index, values, column으로 이루어져 있음
- pd.DataFrame(data, index, columms)를 통해 생성 가능
1) 데이터 프레임 정보 탐색
-
df.head(디폴트값 = 5) : 상위 n개의 데이터 볼 수 있음
-
df.tail(디폴트값 = 5) : 하위 n개의 데이터 볼 수 있음
- df.tail()사용하여 전체 데이터의 수 파악 가능
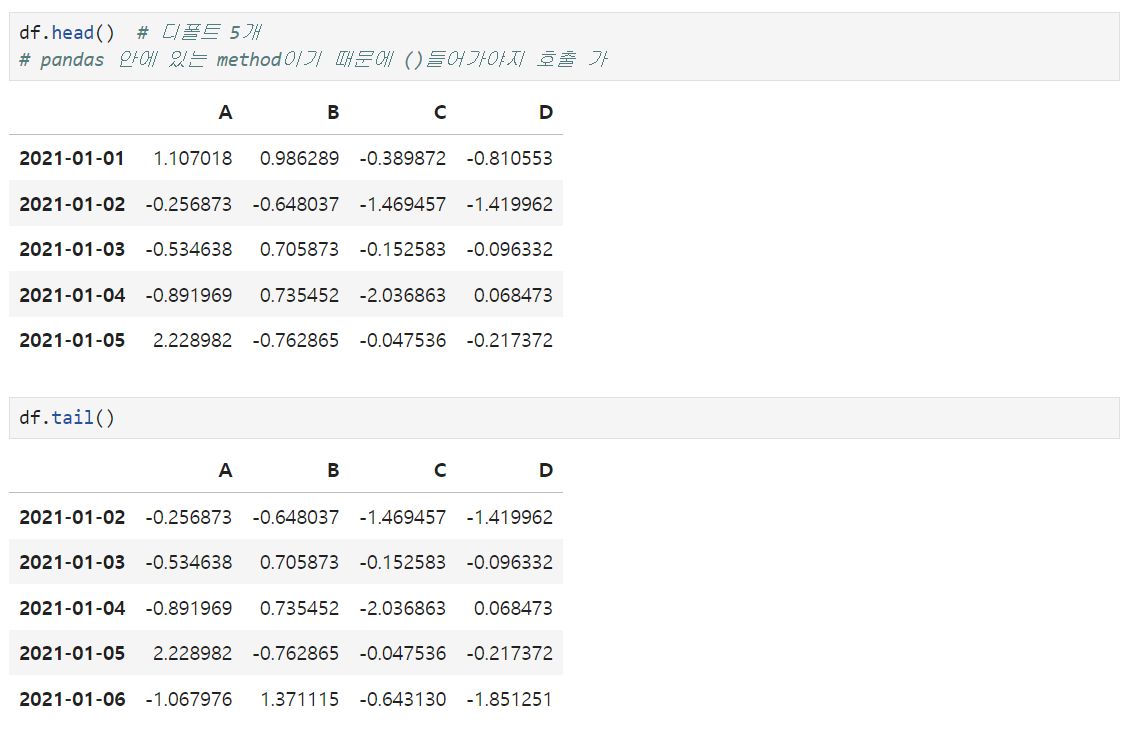
- df.tail()사용하여 전체 데이터의 수 파악 가능
-
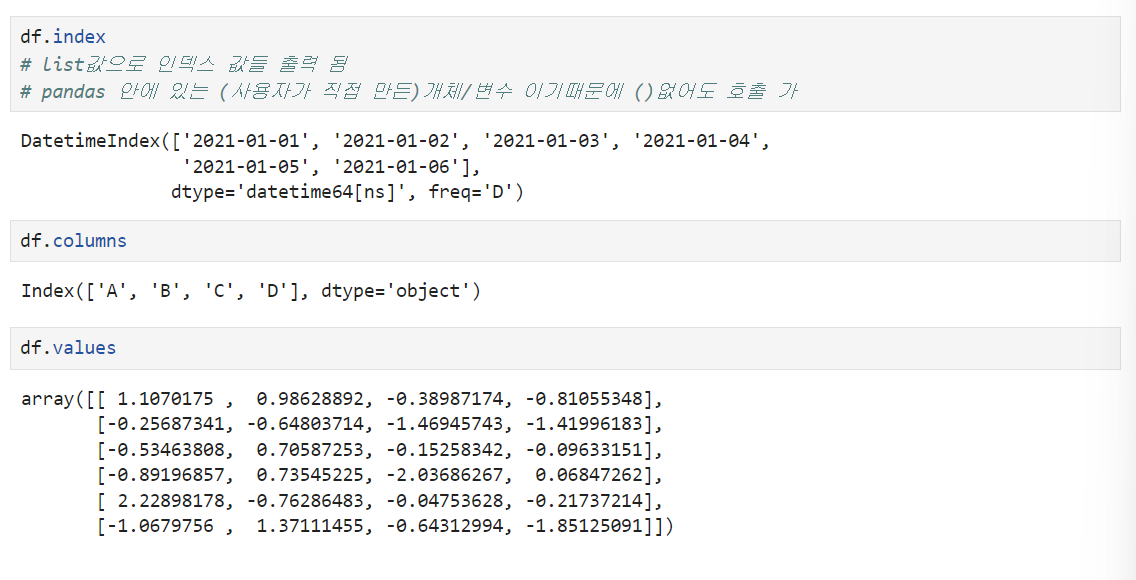
df.index : 인덱스 값 확인
-
df.dolumns : 컬럼 값 확인
-
df.values : 데이터 값 확인
-
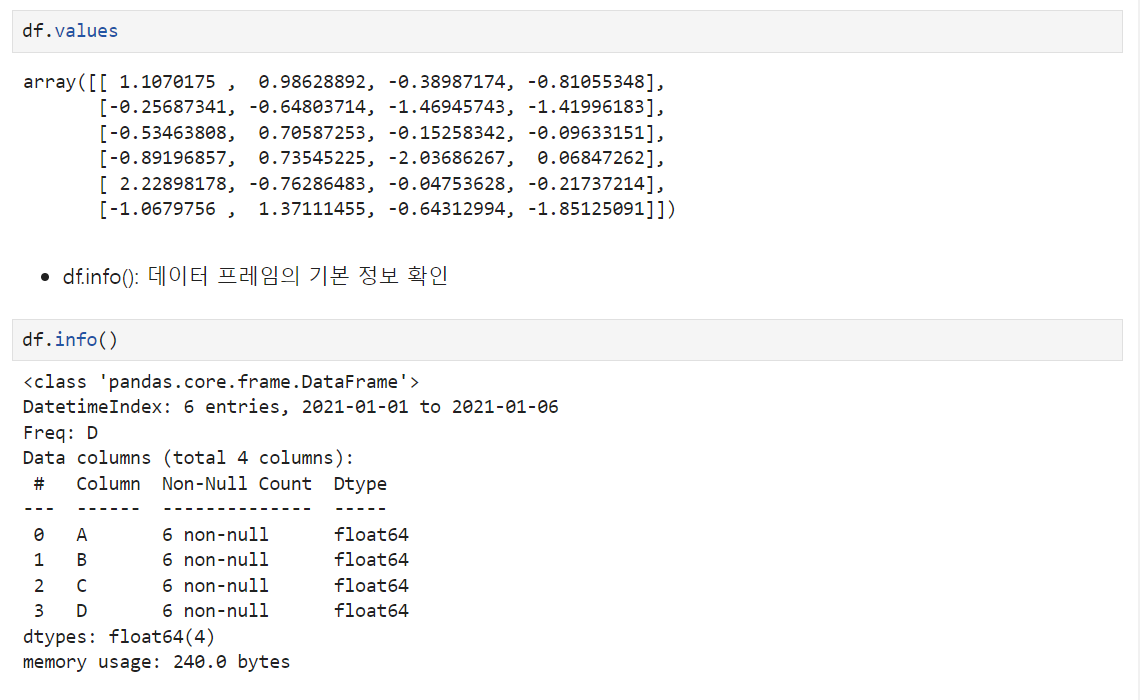
df.info() : 데이터 프레임의 기본 정보 확인
-
df.describe() : 데이터 프레임의 기술 통계 정보 확인
2) 데이터 정렬
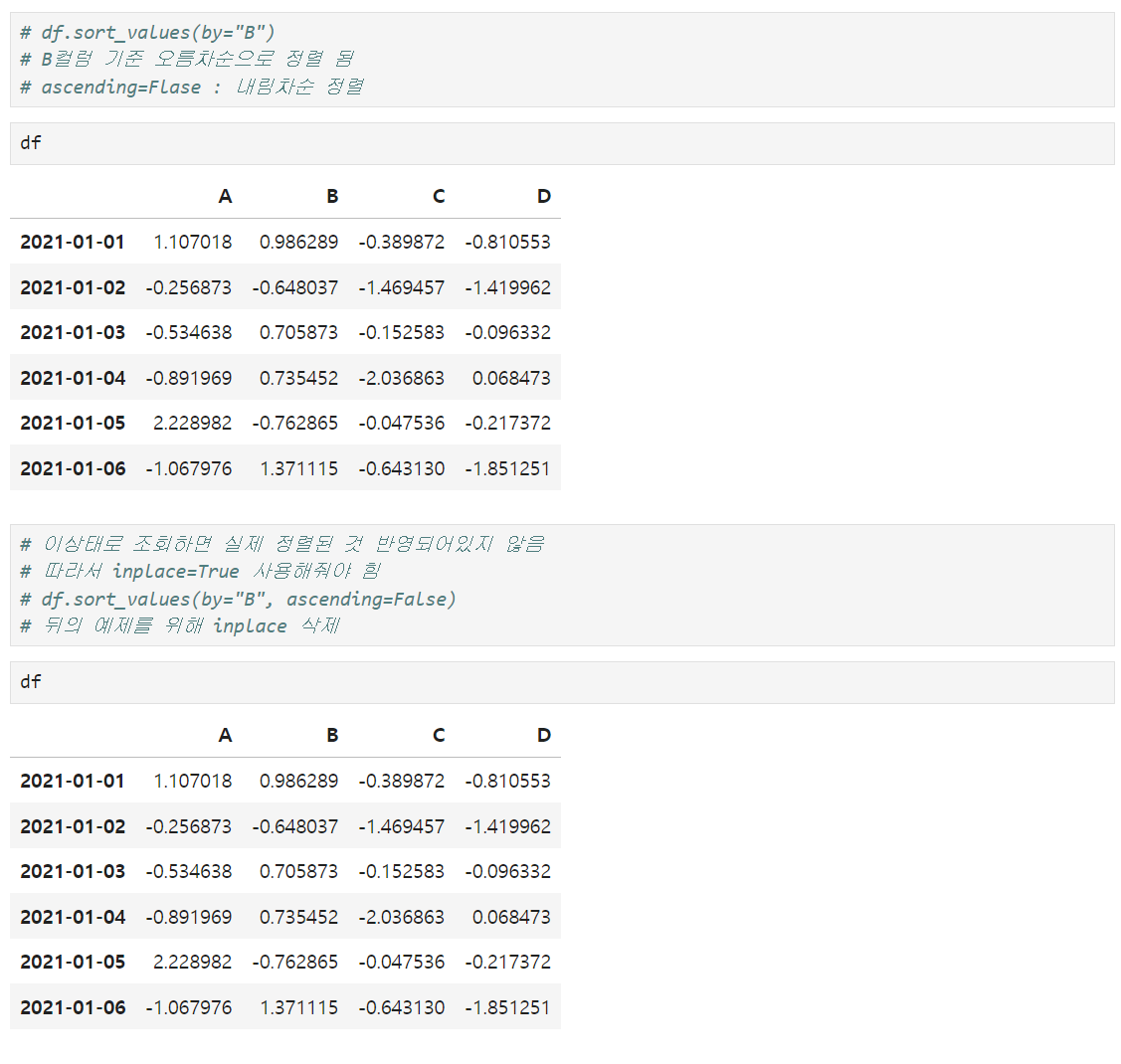
- sort_values(by="열", ascending=True(디폴트값, 오름차순)) : 특정 컬럼(열)을 기준으로 데이터를 정렬
- 정렬한 데이터를 저장하기 위해서는 마지막에 inplace=True 입력 해줘야함
3) 데이터 선택
- df["선택하고싶은 열"] : 1개열 선택
- 열 이름이 알파벳인 경우, []없이 df.열 로 작성해줘도 출력 가능
- 숫자, 문자열로 저장된 숫자 x
- type(df["열"]) = 타입 출력
- df[["열1", "열2"]] : 두개 이상의 열 선택
4) 컬럼 추가/변경
- 기존 컬럼이 없으면 "추가"
- 기존 컬럼이 있으면 "수정"
- df["추가하고자 하는 컬럼명"] = ["값1", "값2", "값3"]
- 입력 개수는 인덱스의 개수와 같아야 함
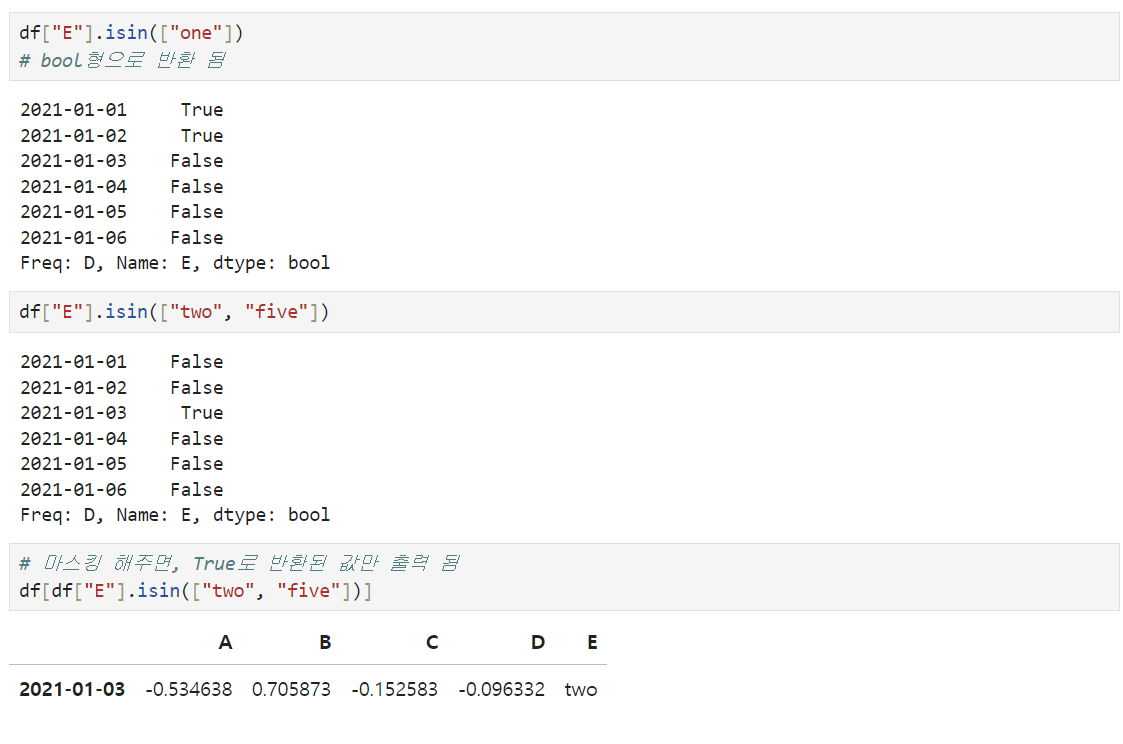
5) 특정 요소 있는지 확인
- isin()
6) 특정 요소 제거
- del df[column]
- df.drop([column/index], axis = 1 or 0)
- axis = 0 (가로)
- axis = 1 (세로)
7) 일괄적으로 적용해주기
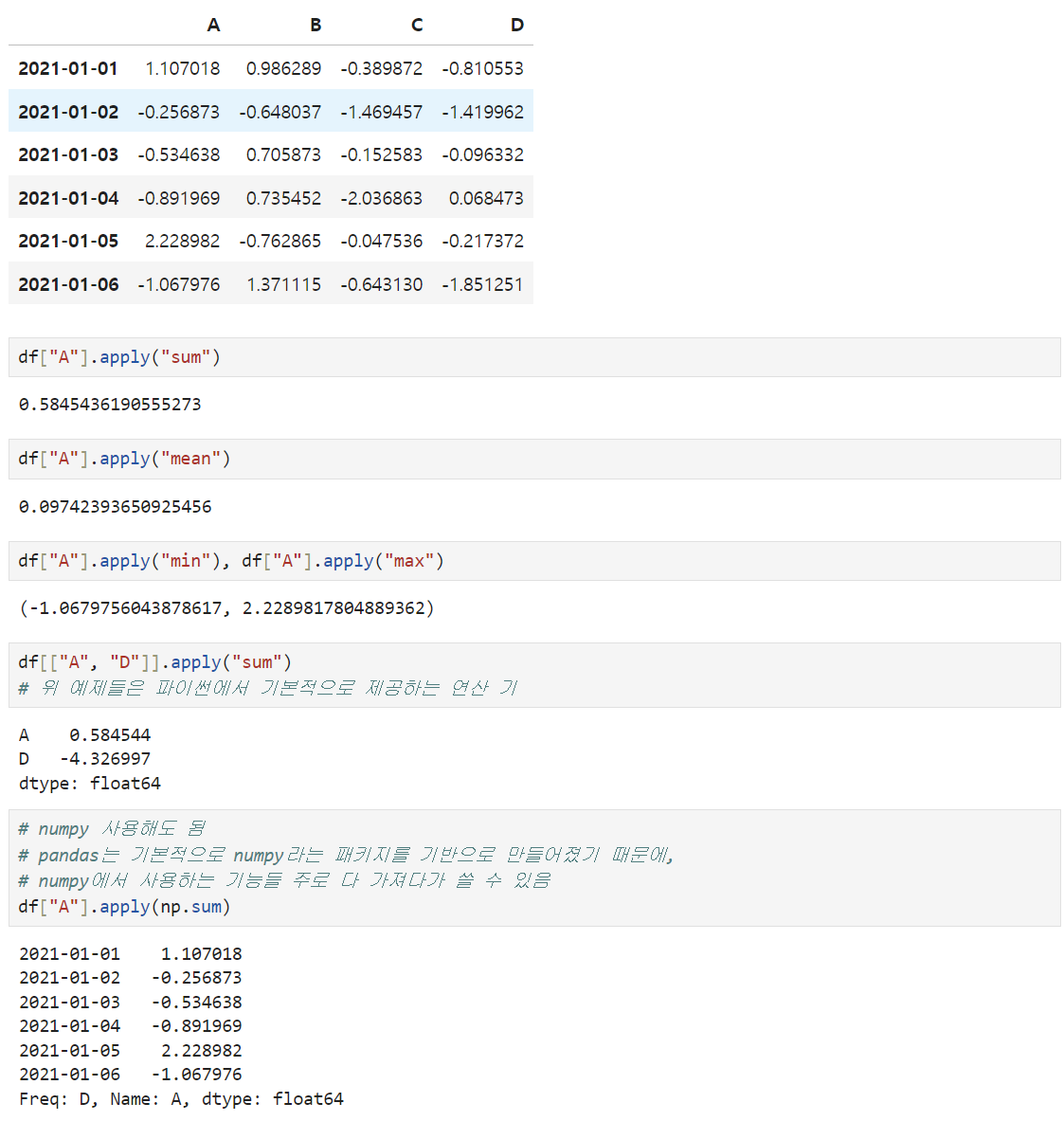
-
df[column].apply(적용해줄 내용)
-
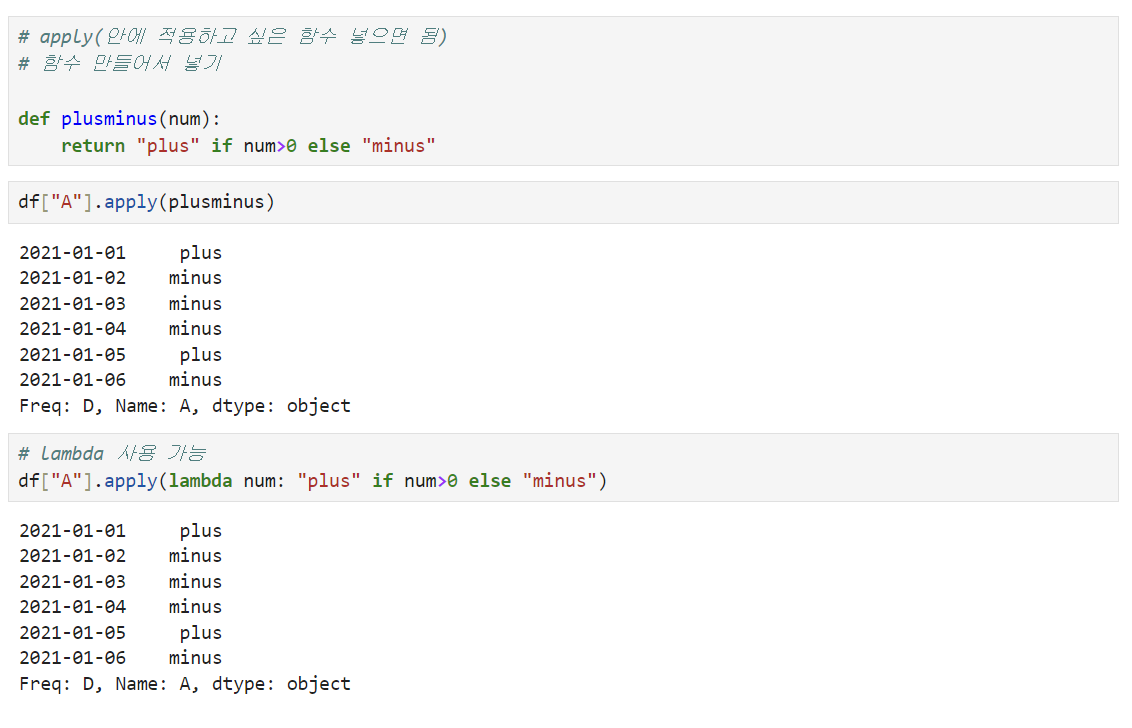
함수 자체 생성 후 적용해줘도 가능

할 거면 제대로 하자