
주요 학습내용
1. Beautiful Soup 기초
2. 예제를 통한 Beautiful Soup 사용
1. Beautiful Soup
사용할 예제
soup = BeautifulSoup(page, "html.parser")
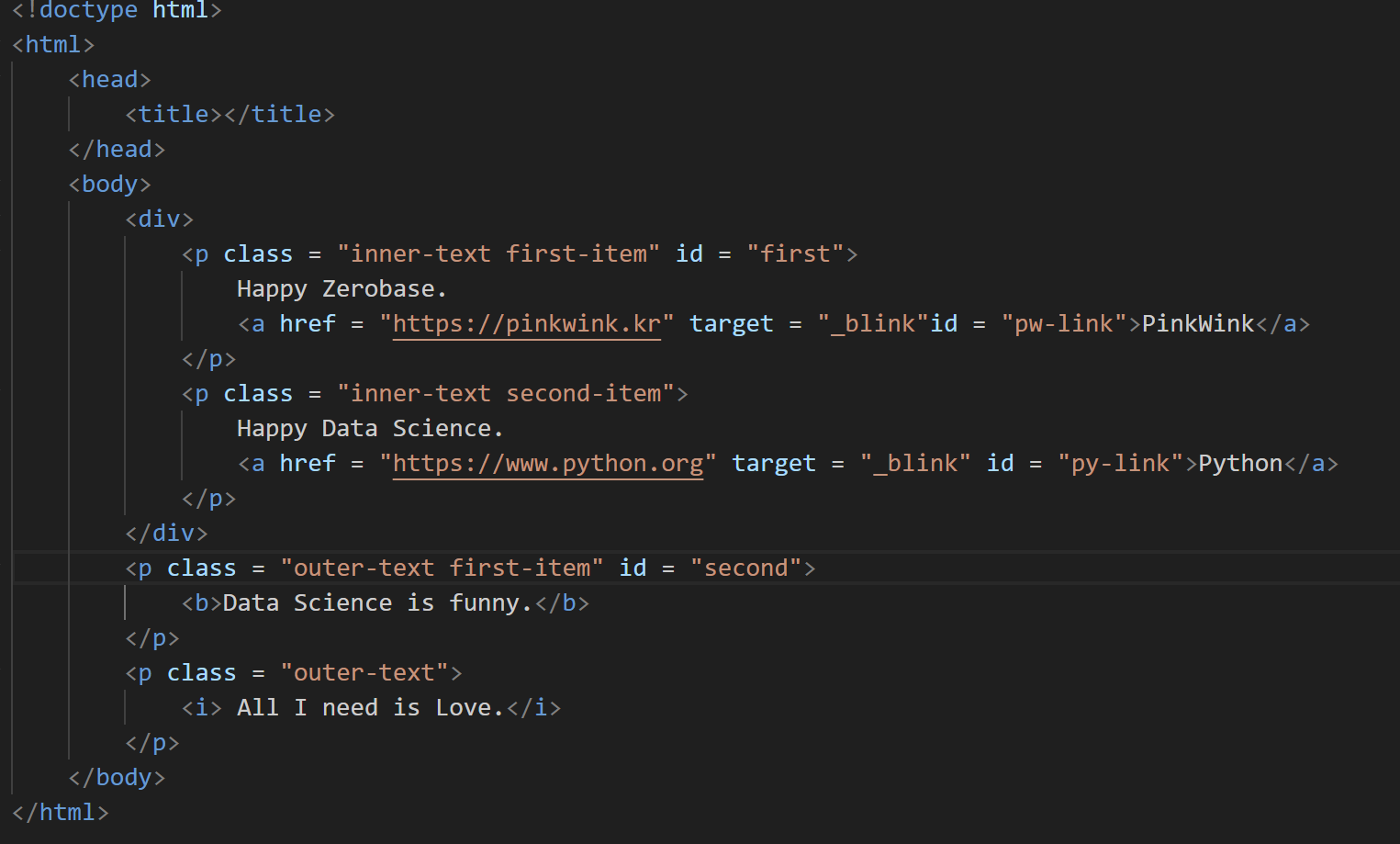
원하는 태그 불러오기
1) .불러올 태그 입력
- soup.head : head 태그 확인
- soup.body : body 태그 확인
- soup.p : p 태그 확인
2) .find()
find() : 처음 발견한 태그만 출력 됨
- soup.find("p/head/body")
- soup.find("p", class_="찾을 클라스 값 입력")
- class는 파이썬 예약어이므로, 'class_' 사용
- soup.find("p", {"class": "값 입력"})
- text 항목만 출력하고 싶은 경우, 마지막에 .text.strip()추가
- strip() : 공백 제거
- soup.find("p", {"class": "값 입력", "id": "값 입력"})
- 다중 조건일 경우
3) .find_all()
find_all() : 여러 개의 태그를 list 형태로 반환
- soup.find_all("태그")
- soup.findall(class="속성 입력"): 특정 속성을 기준으로 출력
- text 추출하는 방법
1) soup.find_all()[index#].text : 첫번째에서 text값 추출
2) soup.find_all()[index#].string- .string은 태그 안에 문자열이 단 하나 있을 경우에만 값을 가지고, 차일드 태그가 있거나 한 경우에는 None 반환
리스트 형태이기 때문에 find()처럼 바로 text사용하여 추출 불가능
find, find_all, select, select_one
- find & select_one : 단일 선택
- find_all & select : 다중 선택
4) for문 사용
- p 태그 리스트에서 텍스트 속성만 출력
- a 태그에서 href 속성값에 있는 값 추출
- get method 쓸 수 있고, 바로 href 추출도 가능
for each_tag in soup.find_all("p"):
print('='*50)
print(each_tag.text)
for each in links:
href = each.get("href") # each["href"]
text = each.get_text()
print(text + " => " + href)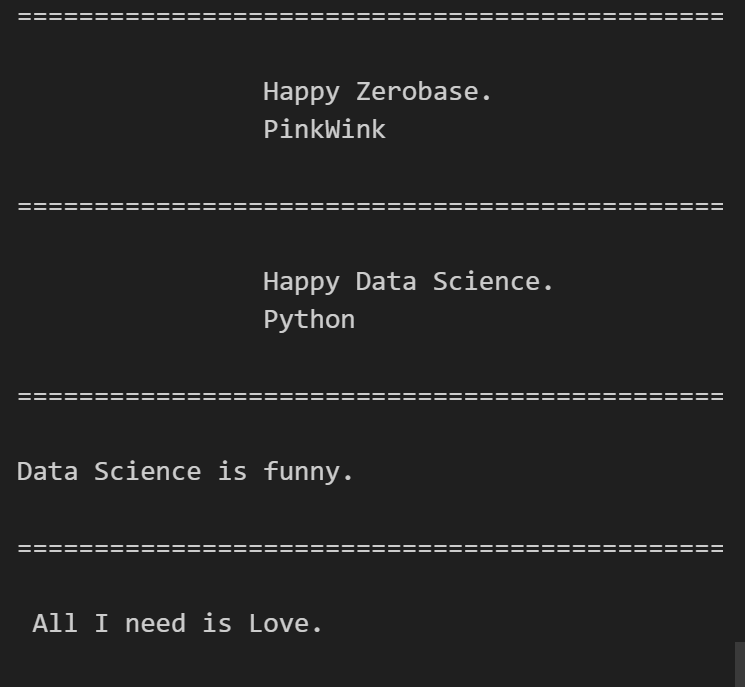 |  |
|---|
2. 예제를 통한 BeautifulSoup 사용
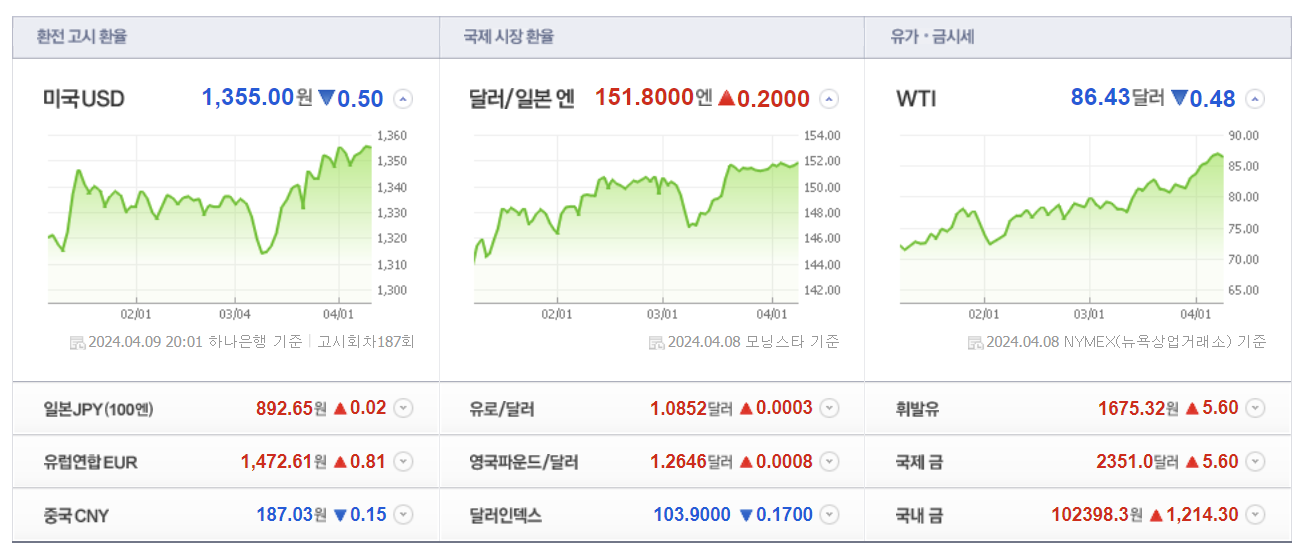
사용할 자료 출처
- 네이버 증권 시장지표
- https://finance.naver.com/marketindex/
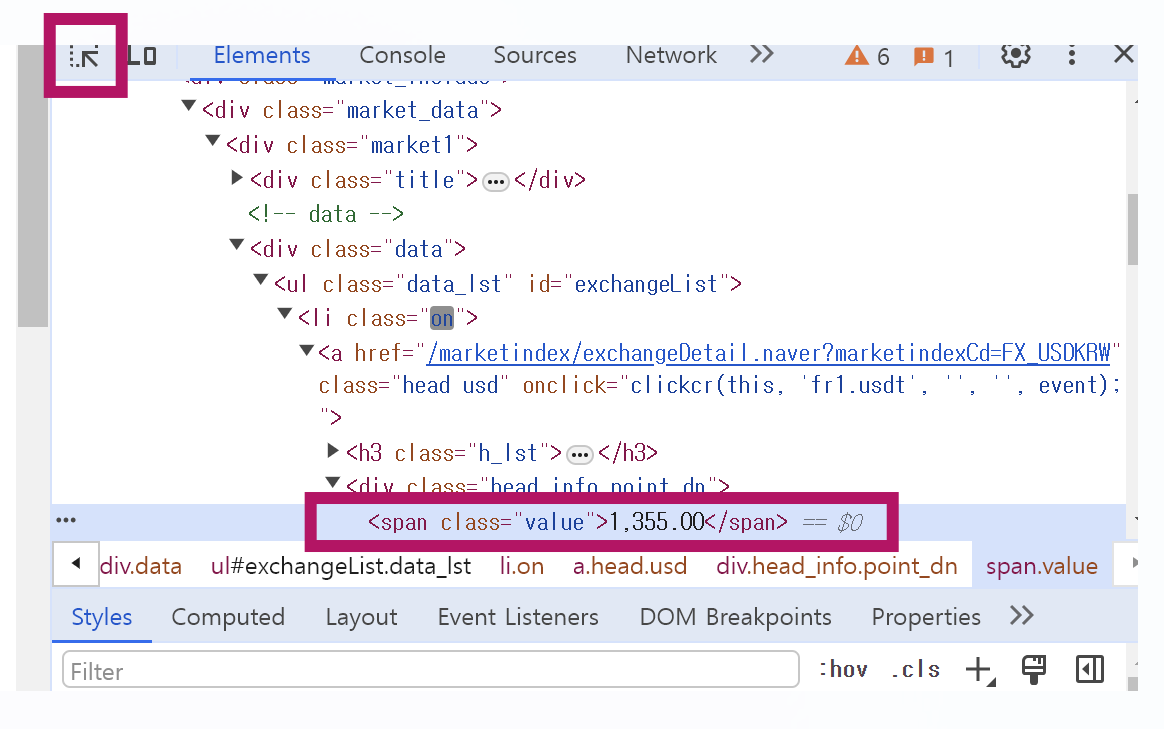
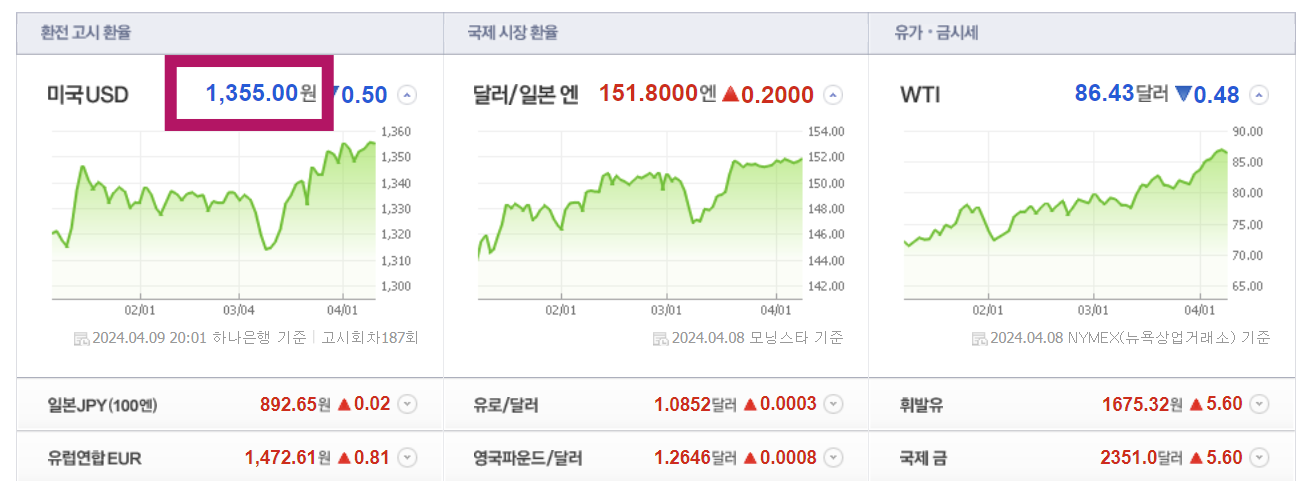
1. 개발자도구 사용하기
- 페이지 우측상단 클릭 → 도구더보기 → 개발자도구
- 표시된 화살표 부분 클릭 → 원하는 정보 클릭 → 해당하는 태그로 이동됨
 |  |
|---|
2. 원하는 데이터 추출하기
- 사용할 lib
- urllib.request, bs4
# import
from urllib.request import urlopen
from bs4 import BeautifulSoup1) 네이버 증권 url open
방법 1
url = "https://finance.naver.com/marketindex/"
page = urlopen(url)
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())방법 2
url = "https://finance.naver.com/marketindex/"
response = urlopen(url)
response.status
soup = BeautifulSoup(response, "html.parser")
print(soup.prettify())
- request -> response 로 받기
- response.status를 실행시키면 200이라는 값이 출력되는데, 해당 값은 http 상태코드로 200번대는 정상적으로 코드가 작동됨을 나타낸다.

HTTP 응답 상태 코드는 특정 HTTP 요청이 성공적으로 완료되었는지 알려줍니다. 응답은 5개의 그룹으로 나누어집니다: 정보를 제공하는 응답, 성공적인 응답, 리다이렉트, 클라이언트 에러, 그리고 서버 에러. 상태 코드는 section 10 of RFC 2616에 정의되어 있습니다.
2) 미국 환율 데이터 불러오기
- 방법 1
soup.find_all("span", "value"), len(soup.find_all("span", "value"))- 방법 2
soup.find_all("span", class_="value"), len(soup.find_all("span", class_="value"))- 방법 3
soup.find_all("span", {"class": "value"}), len(soup.find_all("span", {"class": "value"}))3) text 값만 추출하기
# 원하는 항목의 text만 추출하기
# 미국 데이터 추출
soup.find_all("span", "value")[0].text,soup.find_all("span", {"class": "value"})[0].string, soup.find_all("span", class_="value")[0].get_text()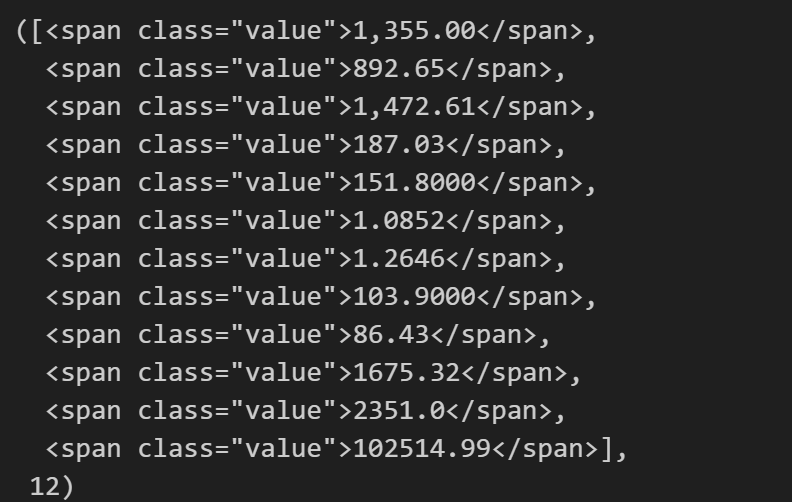


할 거면 제대로 하자