
💳 Once project
처음 졸업프로젝트를 시작한 2023년 9월에는 1년간 하나의 프로젝트를 잘 이끌어나갈 수 있을지 걱정이 많았는데, 어느덧 최종 발표만을 남겨두게 되었다!
기획 단계부터 개발까지 팀원끼리 의지하면서 열심히 몰입하였기에 이루어낸 성과라고 생각한다. 👍🏻
본 블로그에서는 스타트 과정부터 진행 중인 프로젝트 현황에 대해 소개하고, 구현된 기술들과 GPT를 파인튜닝하는 튜토리얼을 작성해 보려고 한다. 🙃
프로젝트 소개
Once : 카드 다보유자를 위한 결제 전 최대 할인 카드를 추천해 주는 AI 챗봇 서비스
Pain Point
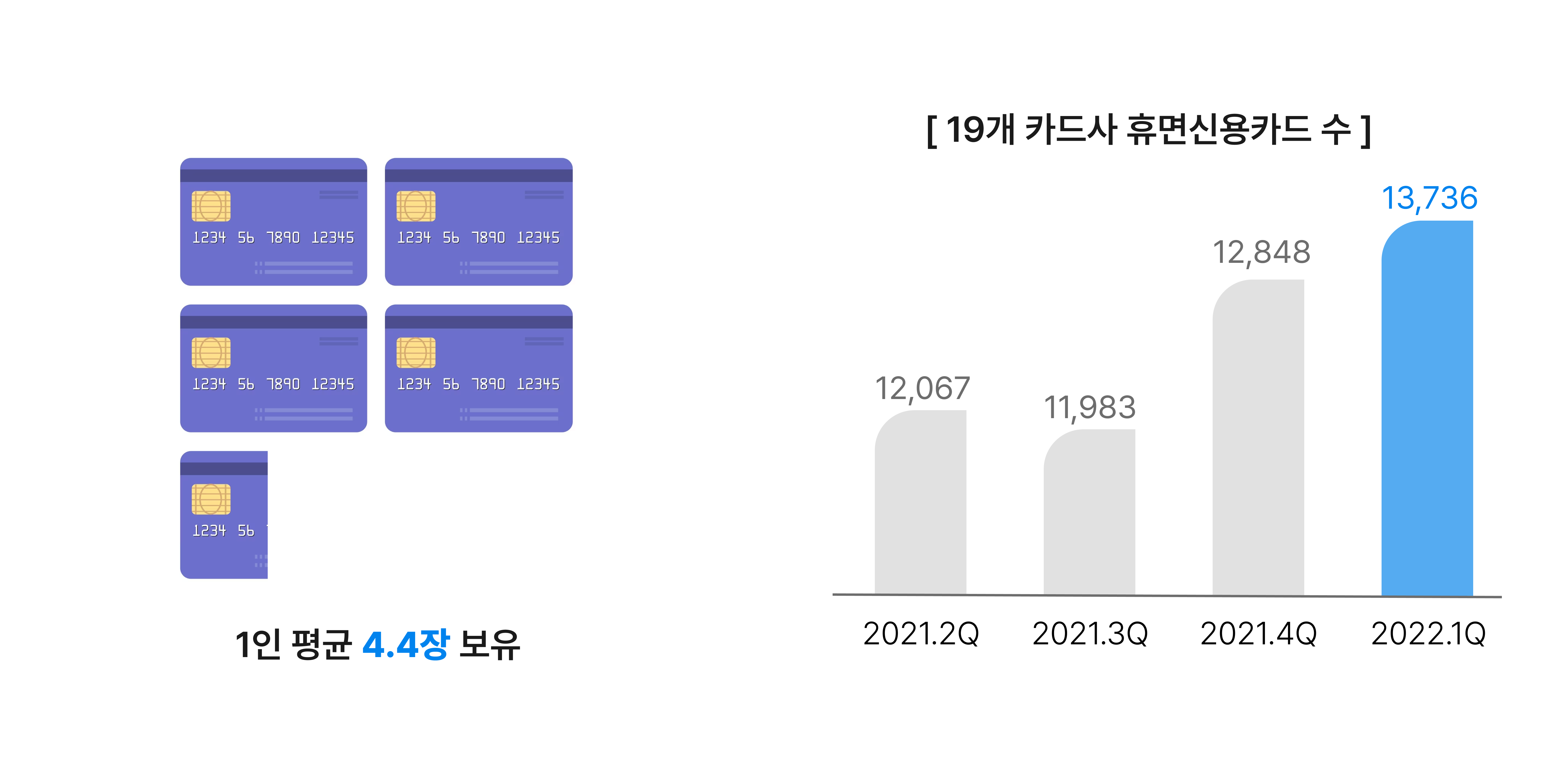
우리는 1인당 신용카드 보유 수는 4.4장이지만, 이와 반대로 1년 잠자는 휴면카드는 1373만장이라는 사실에 주목하여 프로젝트를 기획하게 되었다.
카드 발급량은 매년 늘어나지만, 실제 사용으로 이어지지 못해 휴면카드가 증가하는 이유는 무엇일까?
이는 소비자들이 다수의 카드를 보유하고 있지만, 모든 카드의 혜택을 충분히 파악하고 적절히 활용하는 데 어려움을 겪고 있음을 의미한다.
Solution
원스는 40-50대 카드 다보유자 및 20대 짠테크족을 타겟으로 하여 소비자들이 보유한 카드의 혜택 정보를 기반으로 특정 결제처에서 최대 할인을 제공하는 카드를 추천한다.
즉, 소비자가 모든 카드의 혜택을 최대한 손쉽게 활용할 수 있는 솔루션을 제공한다.
프로토타입
스타트 때에는 두 가지 주요 기능 (결제 카드 추천 & GPS 푸시 알림) 외에 부가 기능들이 그렇게 많지 않았는데, 보다 완성도 있는 서비스를 만들고 싶어 욕심을 부렸더니 이전보다 다양한 기능들이 많이 생기게 되었다...! 🤩
Once의 최종 프로토타입은 다음과 같다!
현재 모든 페이지에 대한 프론트엔드 구현이 완료되었으며, 이는 구현 기술 소개 부분에서 마저 이야기해 보려고 한다.
프로젝트 구조도
Once 프로젝트의 전체 SW Architecture는 아래와 같다.
프로젝트 구조를 3Tier (Presentation Tier, Application Tier, Data Tier)로 나누어 표현했다.
Once는 안드로이드 및 iOS 운영체제에서 모두 실행 가능한 크로스플랫폼 애플리케이션이다.
각 모듈 간 제어 흐름을 간단히 설명해 보면,
1️⃣ User - Client
유저는 Flutter 프레임워크로 개발된 클라이언트를 통해 애플리케이션과 상호작용한다.
2️⃣ Client - Server
클라이언트에서의 요청은 Spring Boot 로 개발된 백엔드 서버의 API 엔드포인트로 전달된다. 이때 클라이언트와 서버 사이의 통신을 보호하기 위해 HTTPS 프로토콜을 사용했다. 서버는 AWS 에서 호스팅 되며, EC2 인스턴스는 도커 컨테이너 내에서 Spring Boot 애플리케이션을 실행한다.
사용자 인증을 위한 토큰은 데이터베이스와 분리된 redis 를 사용하여 민감한 정보를 따로 관리하도록 했다.
3️⃣ Server - Database
데이터베이스는 AWS에서 호스팅 되는 RDS(MySQL)을 이용한다.
4️⃣ Server - AI Module
사용자가 클라이언트에 카드 추천을 요청하면, 해당 요청은 백엔드 서버로 전달된다. 이후 서버는 파인튜닝 된 GPT-3.5 Turbo 모델을 이용하여 최대 할인을 제공하는 카드 추천 결과를 응답한다.
5️⃣ Server - CODEF API
서버는 스크래핑 방식으로 동작하는 CODEF API 를 이용하여 사용자 카드 정보 조회를 수행한다. 이 과정에서 사용자 보유 카드 목록, 실적 충족 여부, 카드 승인 내역을 조회한다.
📍 구현 기술
다음은 내가 개발에 참여한 부분에 대해 기술해 볼 것이다!
📱Front-End
먼저, 프로토타입은 Figma를 이용해서 설계했다.
통합 개발 환경은 안드로이드는 Android Studio를, iOS는 Xcode를 사용하여 개발했다.
크로스 플랫폼 애플리케이션 개발을 위해 Flutter 프레임워크를 프론트엔드 개발에 사용했다.
팀원 중에 다뤄본 사람이 없어 본격적으로 개발을 들어가기 전에 인스타그램 클론코딩 강의를 수강했다!
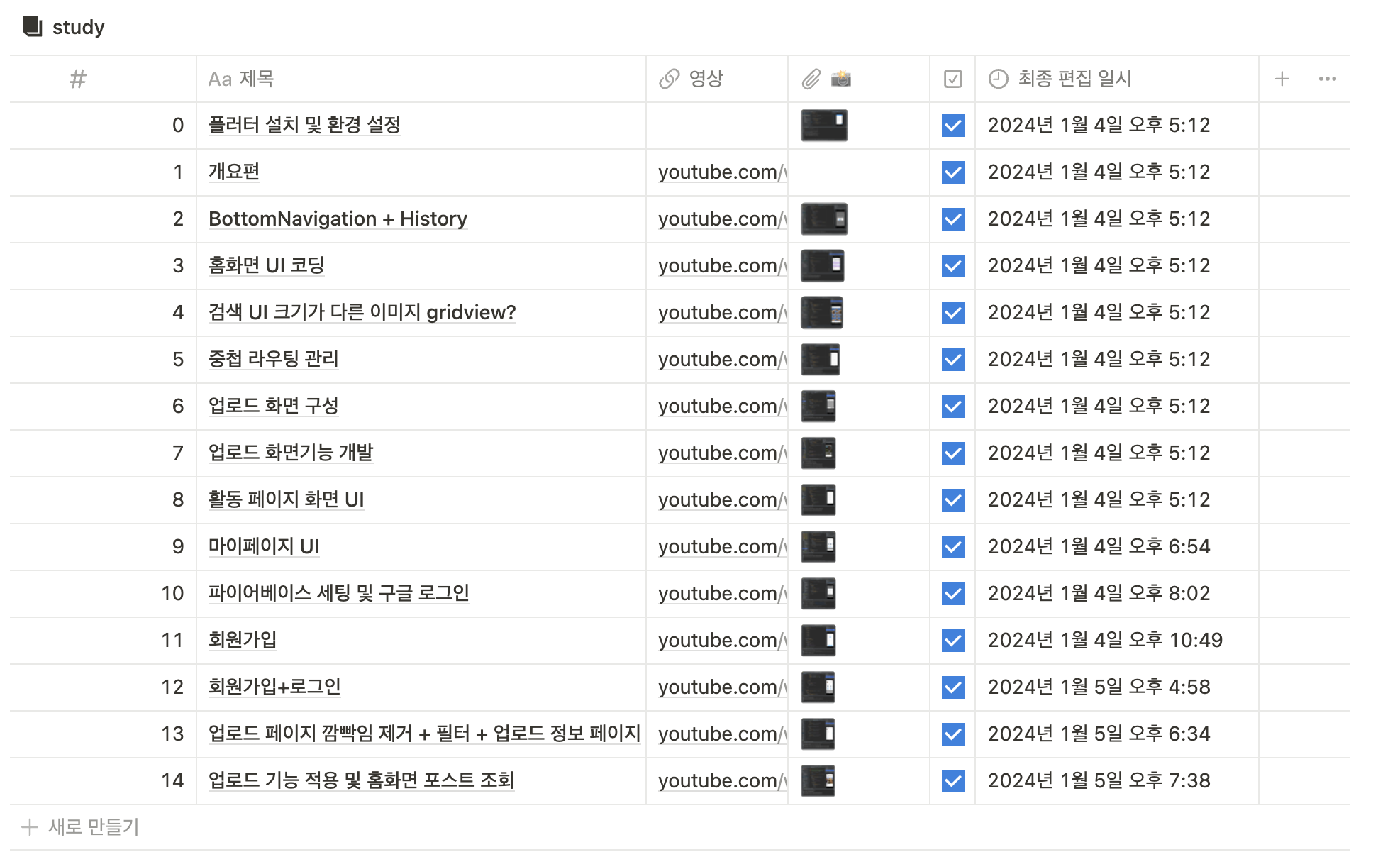
구현 현황
우선 아래처럼 역할분담을 한 후 각자 맡은 페이지를 구현했다. 프론트엔드 개발 현황은 깃허브에서 확인할 수 있다.
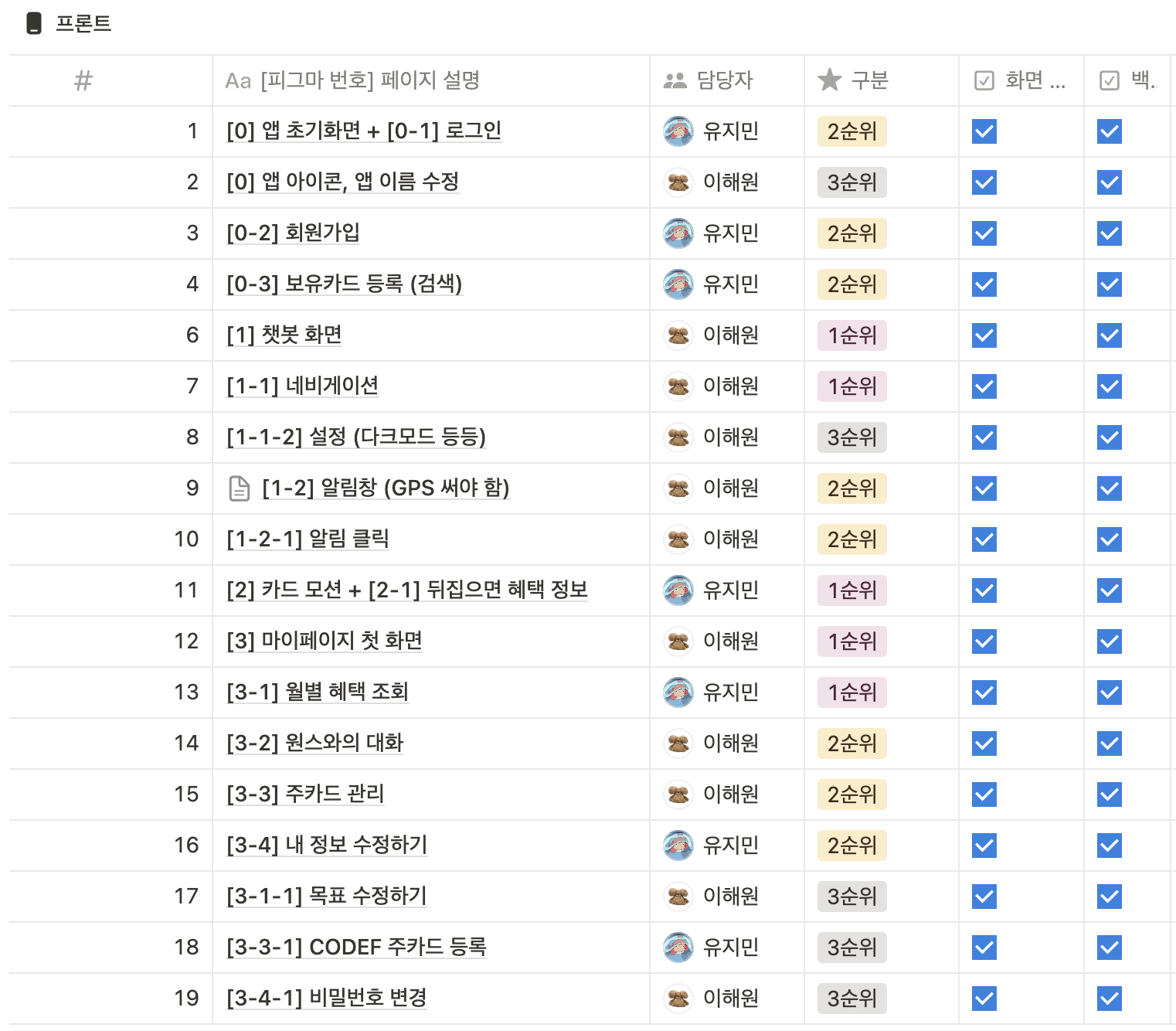
그중 일부 페이지에 대해 언급해 보려고 한다!
챗봇 화면
챗봇 화면은 Once의 주요 기능인 '결제처에서 최대 할인을 제공하는 카드 추천'을 나타내는 페이지이다.
가장 중요한 기능이기도 하고, 앱에 로그인하면 가장 먼저 보이는 홈 화면이기 때문에 제일 오랜 시간을 들여 개발하게 된 것 같다.
이 부분에서는 사용자에게 친근한 검색 형태가 아닌 챗봇 UI를 선택한 이유에 대해 언급하고 넘어가려고 한다.
우리 앱을 사용할 사용자 시나리오를 생각해보았을 때, 검색 기능을 사용한다면 아래의 예시처럼 많은 단계를 거쳐야 한다.
핸드폰 잠금 해제 → 앱 접속 → 검색 폼 클릭 → 타이핑 → 검색 버튼(돋보기) 누르기따라서 사용자가 핵심 서비스를 이용하기까지 가장 최소한의 단계가 필요하다고 생각하여 챗봇 UI 를 홈 화면에 적용하게 되었다.
또한, 지난 카드 추천 기록을 반영한 결제처 키워드를 미리 제공하는 등 사용자 경험(UX)도 고려했다.
알림 상세 조회
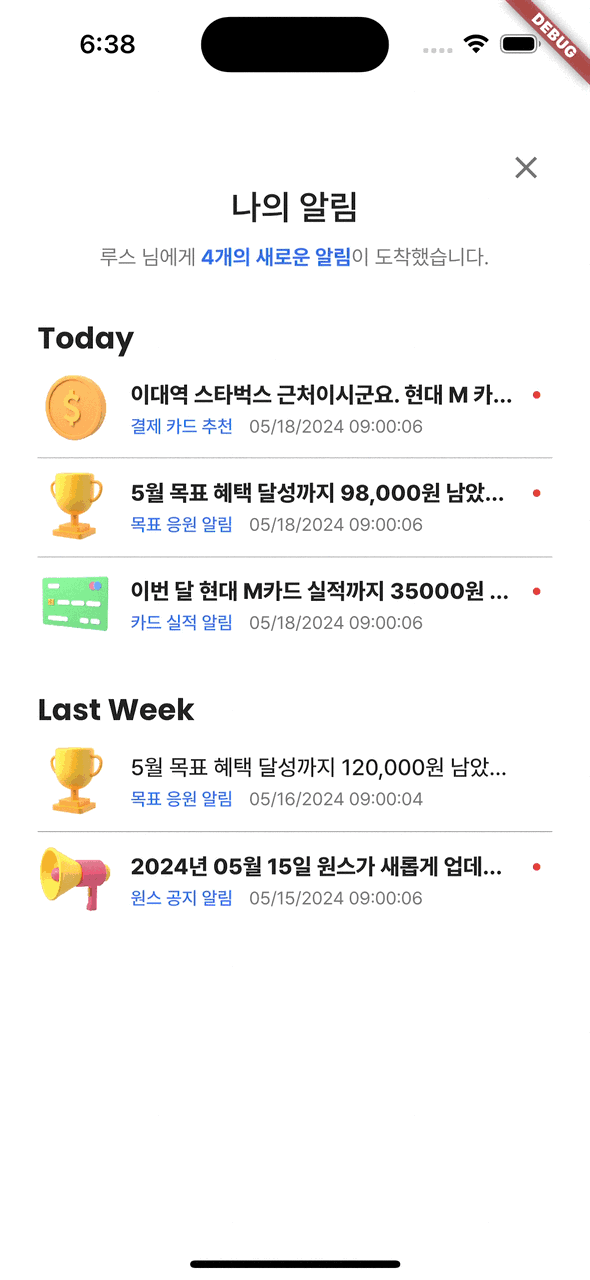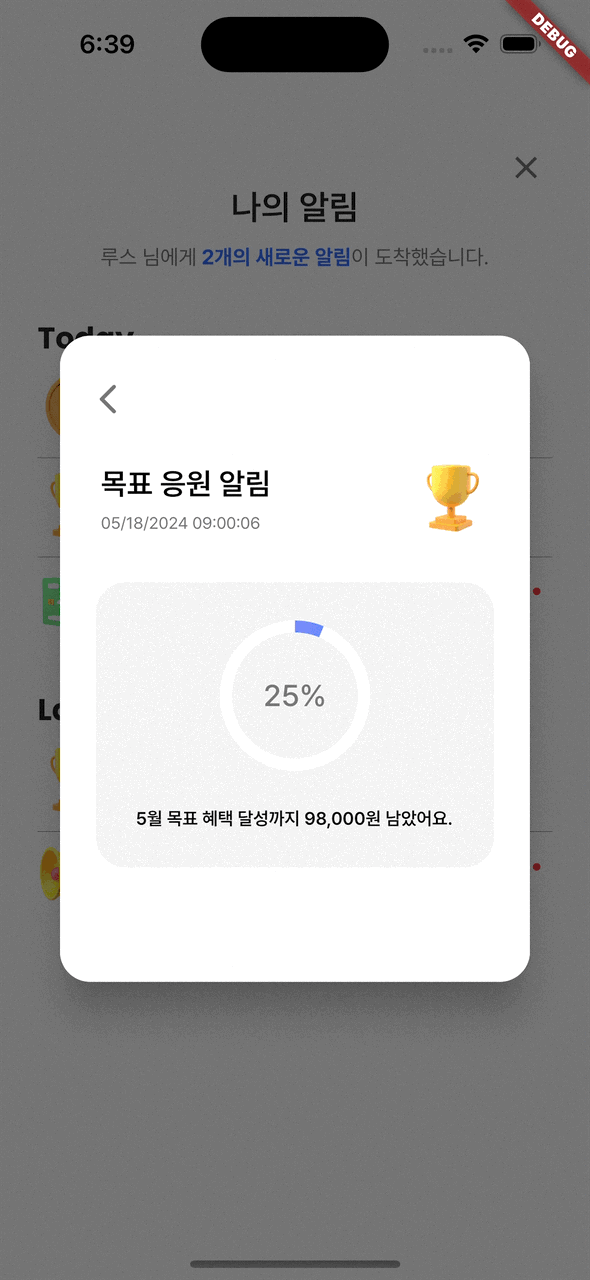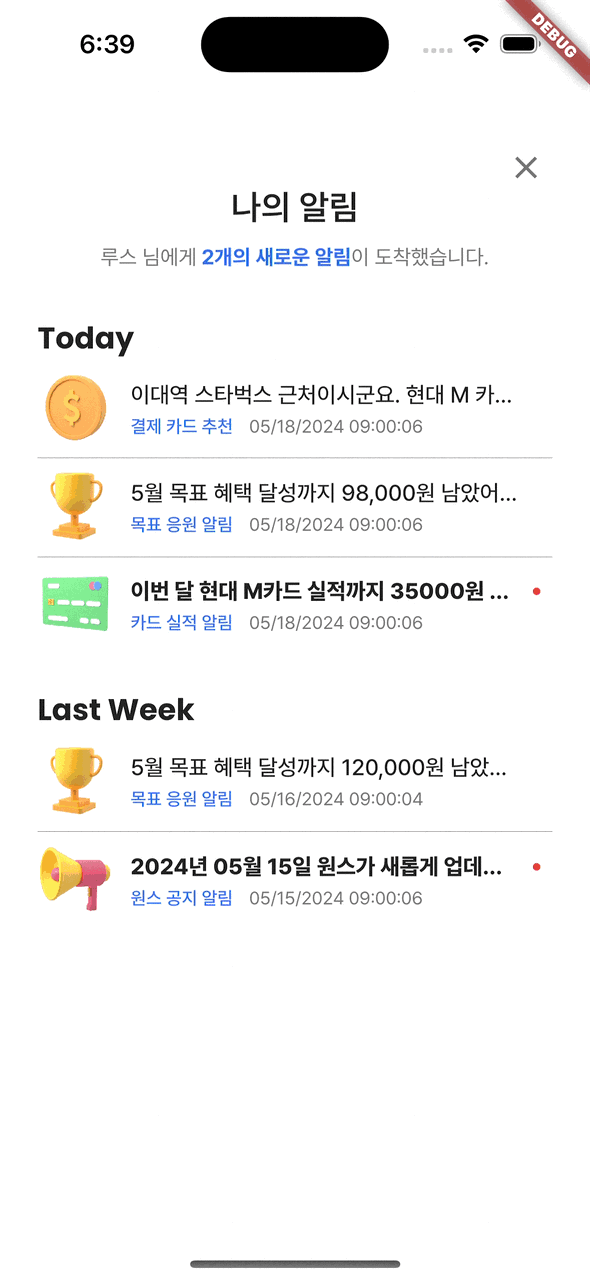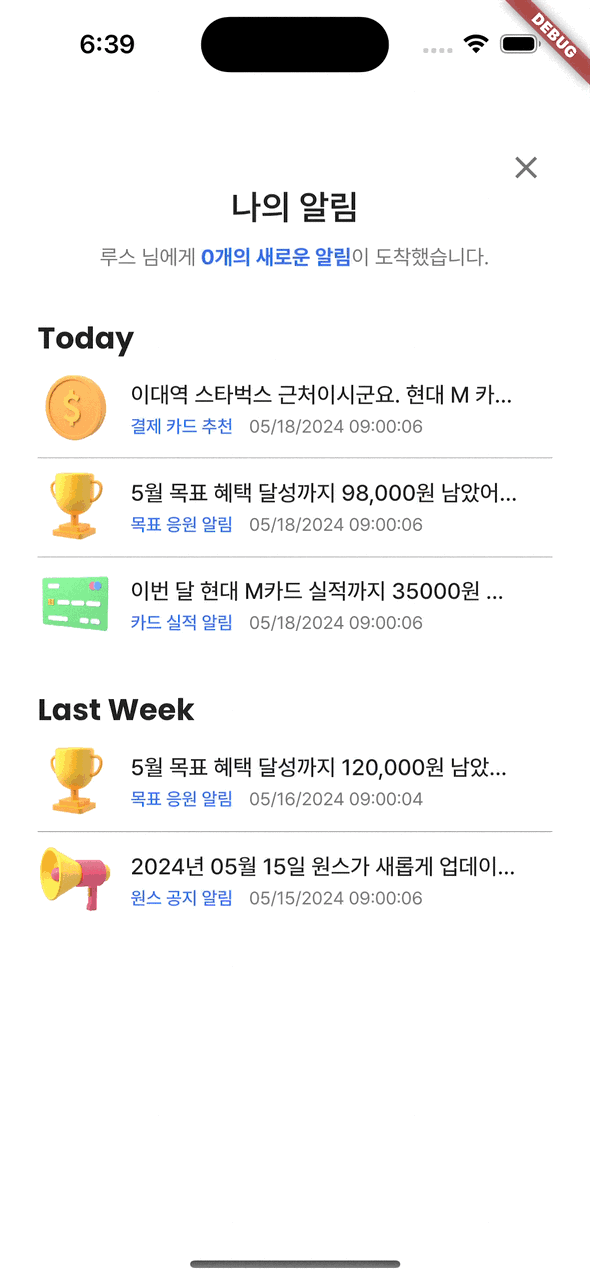
알림은 Once의 두 번째 주요 기능이다.
Beacon 및 GPS 기술을 이용하여 단골 매장 근처에서 최대 할인을 받을 수 있는 카드를 미리 알려주는 푸시 알림 서비스를 나타내는 페이지이다.
구글맵을 사용하여 '결제 카드 추천' 알림을 확인할 수 있는 상세 조회 페이지를 구현했다.
(위 gif는 앱 자체에 있는 알림 페이지이며, 실제로 푸시 알림 기능도 존재한다.)⚙️ Back-End
백엔드 구현은 API 개발과 크롤링 두 파트로 나눌 수 있다.
API 개발

통합 개발 환경은 IntelliJ를 사용했고, Spring Boot 프레임워크를 사용해서 API를 개발했다.
클라우드 호스팅은 AWS에서 제공하는 EC2, RDS, S3 등을 사용했다.
대략 38개의 API 명세서를 작성한 후, 3명의 팀원들과 역할을 나누어 API를 개발했다.
그중 마이페이지 관련 API와 Spring Boot에서 OpenAI에 요청을 보내 카드 추천 결과 응답을 받을 수 있는 결제 카드 추천 API 개발에 참여했다! 🤗
백엔드 개발 현황은 깃허브에서 확인할 수 있다.
Crawling

크롤링은 통합 개발 환경으로 VSCode를 사용했고, BeautifulSoup, Selenium, 파이썬에서 제공하는 Requests 모듈을 사용하여 크롤링을 수행했다.
Once 서비스 구현을 위한 사전 작업으로 크롤링에도 많은 시간을 쏟았던 것 같다.
카드사에서 제공하는 카드 혜택 정보를 가지고 있어야 이를 반영한 카드 추천 모델을 구현할 수 있기 때문에, 주요 카드사 6곳(국민, 현대, 삼성, 신한, 롯데, 하나)를 선정하여 카드 995개에 대한 혜택 정보를 수집했다.
이중 나는 신한카드와 하나카드의 크롤링 작업에 참여했다!
크롤링 개발 현황은 깃허브에서 확인할 수 있다.
Once는 사용자가 모든 카드의 혜택을 손쉽게 활용할 수 있도록 돕기 위해 최신 카드 혜택 정보를 제공한다.
따라서 주 1회 기본 카드 혜택을 크롤링하고, 일 1회 이벤트성 혜택을 크롤링한다.
이는 스프링 부트의 @Scheduled 스케줄러를 이용하여 구현했는데, 매주 월요일 자정에 국민 → 하나 → 삼성 → 신한 → 롯데 → 현대 순서로 크롤링을 수행하는 Python 스크립트를 실행하도록 했다.
@Service
@Slf4j
@RequiredArgsConstructor
public class CrawlingService {
// 매주 월요일 00:00 카드 혜택 크롤링
@Scheduled(cron = "0 0 0 ? * 1")
public void cardCrawling() throws CustomException {
String[] cardCompanyList = {"Kookmin", "Hana", "Samsung", "Shinhan", "Lotte", "Hyundai"};
for (String cardCompany : cardCompanyList){
crawling(cardCompany);
}
}
private static void crawling(String cardCompany) throws CustomException{
LOG.info(cardCompany+" 크롤링 시작");
executeFile(cardCompany+"/credit.py");
executeInsertData(cardCompany,"Credit");
executeFile(cardCompany+"/debit.py");
executeInsertData(cardCompany,"Debit");
}
private static void executeFile(String path) throws CustomException {
try {
ProcessBuilder pb = new ProcessBuilder("python3", "-u", "/crawling/"+path);
pb.redirectErrorStream(true);
Process p = pb.start();
BufferedReader br = new BufferedReader(new InputStreamReader(p.getInputStream()));
String line;
while ((line = br.readLine()) != null) {
// 실행 결과 처리
LOG.info(line);
}
p.waitFor();
} catch (Exception e){
throw new CustomException(ResponseCode.CARD_BENEFITS_CRAWLING_FAIL);
}
}
}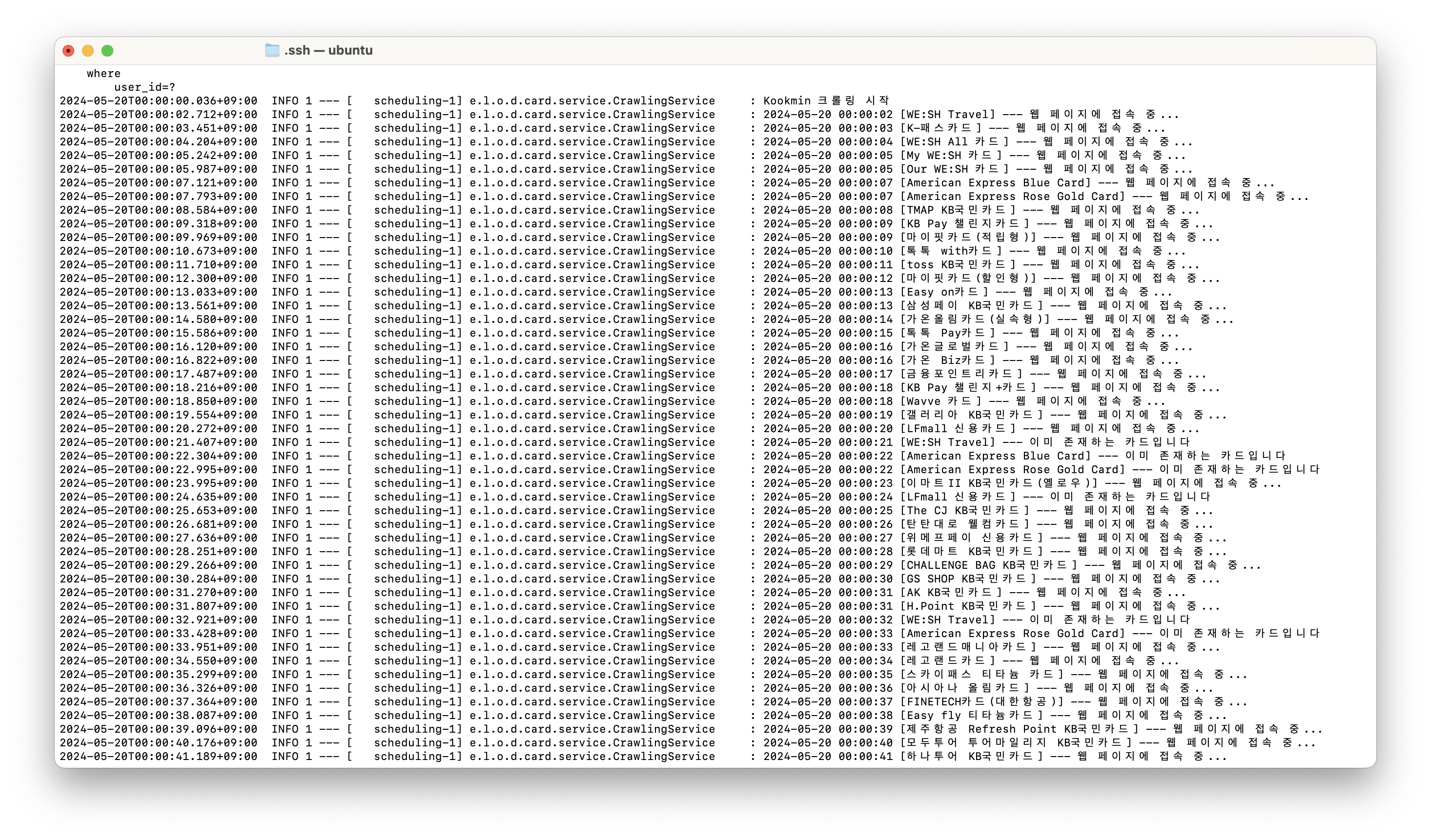
위 이미지는 실제로 월요일 자정에 크롤링 작업이 실행될 때 출력된 로그이다!
🤖 카드 추천 AI 모델
이번에는 카드 추천 AI 모델을 구현하기 위해 진행한 세 가지 기술 검증 과정에 관한 내용이다. 특히, 세 단계를 거쳐 최종적으로 파인튜닝 기술을 선택하게 된 과정을 성능 측면에서 비교 분석해 보려고 한다!
기술 검증
1️⃣ end-to-end로 서비스 구현한 경우
먼저, '결제 카드 추천 서비스' 구현을 위해 카드 혜택 요약 같은 전처리 과정 없이 클라이언트에서 결제처와 결제 금액 정보를 포함한 요청을 아래와 같이 주면, 바로 프롬프트를 작성해 OpenAI / Gemini 에 요청을 보낸 후 그 응답을 다시 클라이언트에 주는 방식을 사용했다.
GET /home?keyword=GS25&paymentAmount=10000즉, 요청 과정을 그림으로 표현하면 다음과 같다.
이때 언어 모델은 GPT-3.5 Turbo 모델과 Gemini 모델을 활용했다.
GPT-3.5 Turbo 의 최대 토큰 수가 16486 tokens로 제한되어 있어, 요약되지 않은 여러 개의 카드 혜택 정보를 한번에 입력하는 것이 불가능한 문제가 있었기에, 토큰 부족 문제를 해결하고자Gemini 모델의 도입을 고려하게 되었다.

그러나, 최대 토큰 수가 30720 tokens인 Gemini 모델은 여러 카드 혜택 정보를 수용할 수 있지만 GPT-3.5 Turbo 모델에 비해 같은 프롬프트에 대해 매번 다른 응답 결과를 주는 등 카드 추천의 정확도가 떨어지는 것을 확인할 수 있었다.
2️⃣ 프롬프트 엔지니어링으로 서비스 구현
첫 번째 기술 검증 과정에서 요약 없이 카드 혜택 정보를 프롬프트에 작성하면 end-to-end로 응답을 전송하는 과정이 8초 이상 걸리는 문제를 발견했다.
Once는 사용자가 결제 전이라는 짧은 시간 안에 카드 추천 결과를 응답해야 하는 서비스이므로, 1번 방식은 요구사항을 충족하지 않았다.
따라서 두 번째 방법으로 카드 혜택 데이터를 요약하는 전처리 과정을 거친 후, 프롬프트 엔지니어링 방식을 사용하여 카드 추천 서비스를 구현했다.
GPT-3.5 Turbo 모델은 JSON 형식의 데이터를 이해하는 것에 강점을 가지고 있기 때문에, 카드들의 혜택 정보를 요약하여 JSON 포맷으로 전달하는 방식을 채택했다.
이때 혜택 요약은 GPT-3.5 Turbo 모델에 요약을 위한 프롬프트를 작성하는 프롬프트 엔지니어링 방식을 사용하였고, 최대 토큰 길이 이상이거나 주어진 출력 형식에 맞지 않는 결과를 반환하는 경우에는 gpt-4-turbo-preview 를 이용해 요약을 다시 수행하도록 했다.
요약 과정은 다음과 같다.
즉, 요약한 카드 혜택을 이용한 카드 추천 과정을 그림으로 표현하면 다음과 같다.
1번 방식에서 Gemini의 정확도가 GPT-3.5 Turbo 모델에 비해 떨어진다는 것을 검증했으므로 Gemini 모델은 사용하지 않기로 결정했다.
이번에는 같은 프롬프트에 대하여 GPT 두 모델, GPT-3.5 Turbo 모델과 GPT-4 모델을 사용하여 응답 시간을 비교해보았다.
GPT-3.5 TUrbo 모델의 경우 응답 시간이 3.3초 정도, GPT-4 모델의 경우 응답 시간이 5.15초 정도 걸리는 것을 알 수 있었다.
GPT-3.5 Turbo가 GPT-4에 비해 응답 시간이 짧게 걸리기 때문에 최종적으로 GPT-3.5 Turbo 모델을 사용하게 되었다.
3️⃣ 파인튜닝으로 서비스 구현 (✅ 최종 선택)
마지막으로 카드 추천이라는 downstream task에 적합한 모델을 생성하기 위하여 GPT-3.5 Turbo 모델의 파인튜닝을 진행했다.
아래 세 단계를 거쳐 Once의 주요 서비스를 구현했다.
데이터셋 구축 → 파인튜닝 → 파인튜닝 결과 확인1) 데이터셋 구축
총 100개의 데이터셋 중 training dataset : validation dataset : test dataset = 6 : 2 : 2 의 비율로 나누어 파인튜닝에 사용했다.
정확도가 높은 파인튜닝 모델을 위해 특정 결제처와 관련된 혜택을 가진 카드들을 비교하여, 가장 많은 할인을 제공하는 카드를 직접 선택하는 방식으로 데이터셋을 구축했다.
1인당 신용카드 보유 수는 평균 4.4장이므로, 각 데이터마다 3-5장의 카드를 가지도록 데이터셋을 생성했으며, 이때 실제 카드 사용자들이 많을 것으로 예상되는 6개 카드사 인기 카드들의 비중을 높게 설정했다.
다음은 직접 구축한 데이터셋의 일부이며, 최종 발표 전까지 카드 추천 모델의 정확도 향상을 위해 더 많은 데이터셋을 구축할 계획이다.
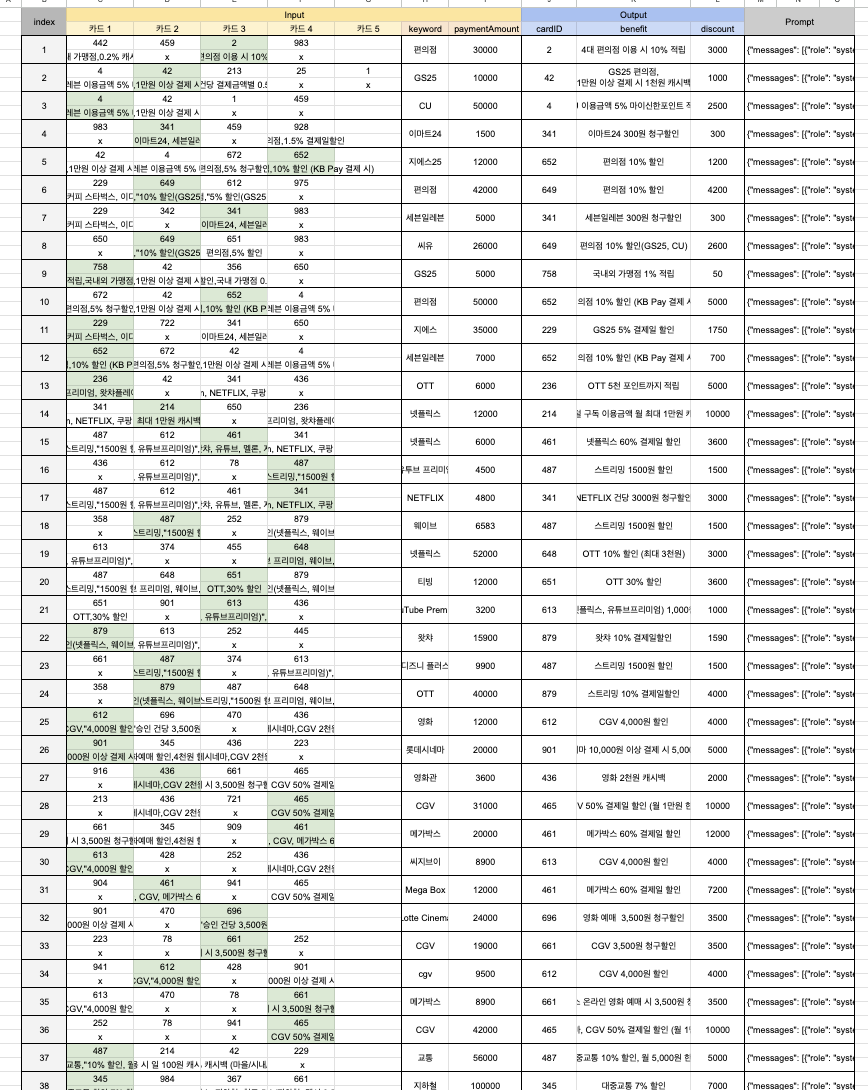
2) 파인튜닝
위에서 준비한 training dataset과 validation dataset을 이용해 모델 학습을 위한 json 파일을 생성했다.
생성한 파일을 OpenAI에 등록하면 Storage에서 다음과 같이 업로드된 파일을 확인할 수 있다.
Python 환경에서 GPT-3.5 Turbo 모델의 파인튜닝을 진행했고, 구체적인 파인튜닝 과정은 아래 📚 파인튜닝 튜토리얼에서 구체적으로 다뤄볼 것이다! 🙌🏻
3) 결과 확인
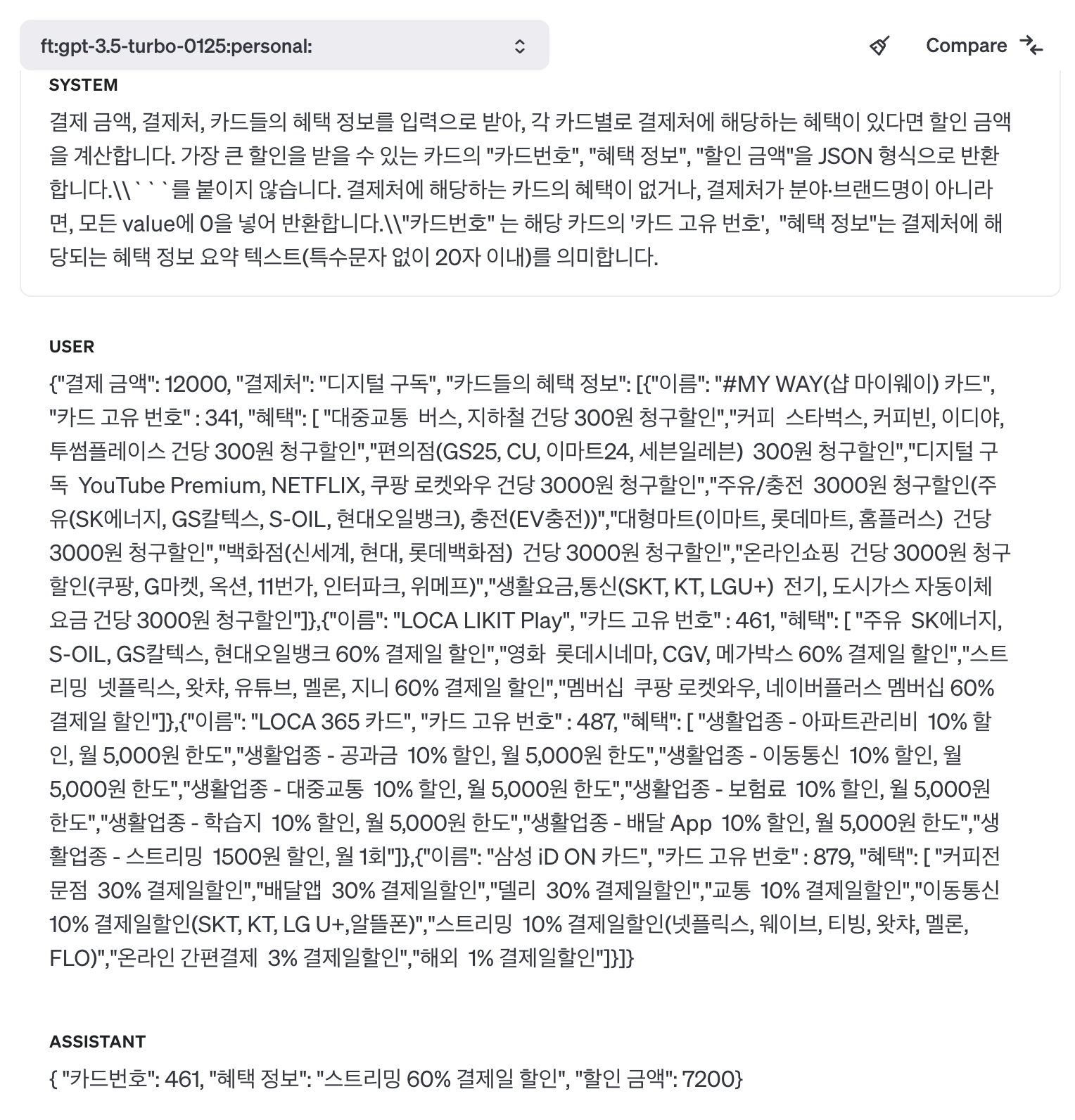
위 이미지처럼 OpenAI의 Playground에서 앞서 파인튜닝한 모델의 id를 사용해서 해당 모델을 테스트해 볼 수 있다.
보유 중인 '#MY WAY(샵 마이웨이) 카드', 'LOCA LIKIT PLAY', 'LOCA 365 카드' '삼성 iD ON 카드' 중에서 '디지털 구독'과 관련된 혜택을 찾은 후, 'LOCA LIKIT PLAY' 를 사용하면 가장 많은 할인을 받을 수 있다는 결과가 반환되었다.
'LOCA LIKIT PLAY' 카드의 혜택 중 '스트리밍 넷플릭스, 왓챠, 유튜브, 멜론, 지니 60% 결제일 할인' 혜택을 사용하면 12000원을 결제했을 때 7200원의 할인을 받을 수 있다.
원스의 주요 기능을 개발하기 위해 파인튜닝된 GPT-3.5 Turbo 모델을 사용하기로 최종 선택하였으며, 현재는 성능을 향상시키기 위해 추가 데이터셋을 생성하는 중이다.
📚 파인튜닝 튜토리얼
파인튜닝이란 특정 작업에 대한 적합성을 높이기 위해 이미 훈련된 대규모 언어 모델에 특정 데이터셋을 사용하여 추가적인 학습을 수행하는 작업이다.
Once의 경우에는 '결제처에서 최대 할인을 제공하는 카드 추천' 이라는 작업에 대해 적합성을 높이기 위해 GPT-3.5 Turbo 모델에 Once가 독자적으로 구축한 데이터셋을 사용하여 추가적인 학습을 진행했다.
학습 데이터 준비
일반적으로 학습을 위한 데이터는 아래와 같이 role , content 를 가진 메시지들의 리스트로 구성된다.

이때 role 을 이용하여 메시지의 역할을 지정할 수 있는데, 각 용도에 따라 system, user, assistant 로 구분된다.
각 역할에 대해 간단히 설명하면 다음과 같다.
system: 구체적인 행동 방침 및 출력 포맷 지정user: 사용자의 질문assistant: user 질문에 대한 답
따라서 Once 서비스를 위한 파인튜닝 모델을 생성하기 위해 학습 데이터를 다음 형태로 구성했다.

파란색으로 표시한 system의 content는 목적에 맞는 행동 방침을 지정하면 된다.
이때 여러 번 테스트해 보면서 가장 적합한 system 내용을 찾는 것이 중요하다!
그리고 서버에서 card 관련 정보 조회(카드 이미지, 카드 이름, 카드 혜택)가 필요하므로 편리성을 위해 assistant가 cardId 를 반환하도록 했다.
데이터 파일 등록
파인튜닝을 위한 데이터 파일은 jsonl 파일로 작성된다.
JSONL은 JSON Lines를 의미하며, 각 라인이 독립된 JSON 객체로 구성되기 때문에 각 줄에 위에서 생성한 messages를 작성하면 된다.
이때 training dataset과 validation dataset을 각각 등록하여 각 단계에 활용할 수 있다.
from openai import OpenAI
client = OpenAI()
training_file_name="./ex_tran.jsonl"
validation_file_name = "./ex_val.jsonl"
training_data = client.files.create(
file=open(training_file_name, "rb"), purpose="fine-tune"
)
validation_data = client.files.create(
file=open(validation_file_name, "rb"), purpose="fine-tune"
)
print(training_data)
print(validation_data)위 코드를 활용하면 OpenAI에 학습을 위한 데이터 파일을 등록할 수 있다!
목적을 "fine-tune" 으로 설정했고, 출력 결과는 다음과 같다.
FileObject(id='{your_training_data_id}', bytes=201119, created_at=1716208904, filename='ex_tran.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)
FileObject(id='{your_validation_data_id}', bytes=72031, created_at=1716208905, filename='ex_val.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)위 출력 결과에서 {your_training_data_id} 와 {your_validation_data_id} 는 다음 단계에서 사용되므로 기억해 두자!
실제로 OpenAI의 Storage에 데이터가 등록된 것을 확인할 수 있다.
파인튜닝 수행
client.fine_tuning.jobs.create(
training_file="{your_training_data_id}",
validation_file="{your_validation_data_id}",
model="gpt-3.5-turbo"
)위에서 생성한 {your_training_data_id} 와 {your_validation_data_id} 를 입력해 주면, 파인튜닝 작업이 요청된다.
모델은 gpt-3.5-turbo 를 사용했다.
파인튜닝 과정은 OpenAI의 Fine-tuning 탭에서 확인할 수 있다!
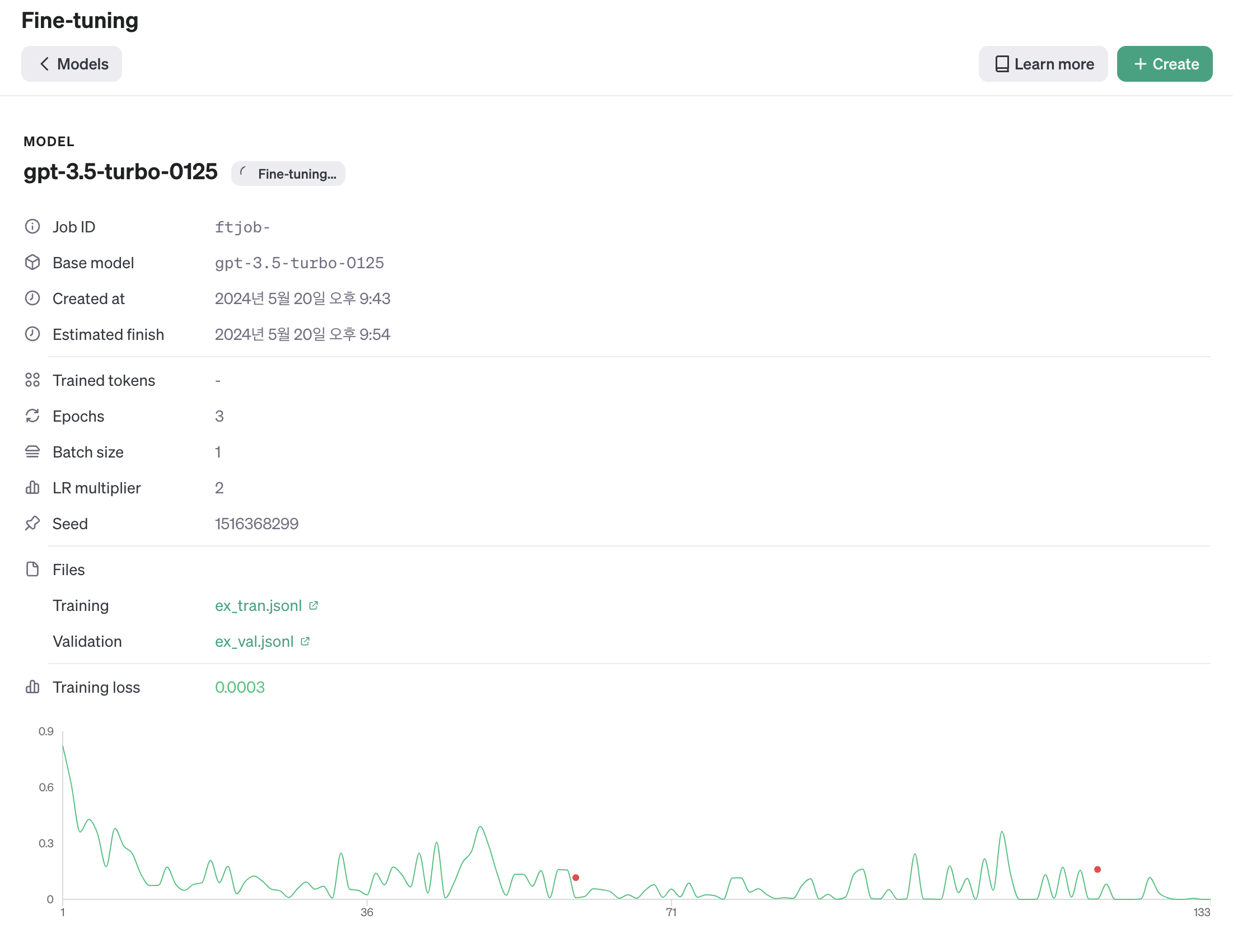
파인튜닝이 완료된 이후에는 아래 이미지처럼 파인튜닝 모델의 id 가 생성되는데 이 값을 통해 모델을 사용할 수 있다.
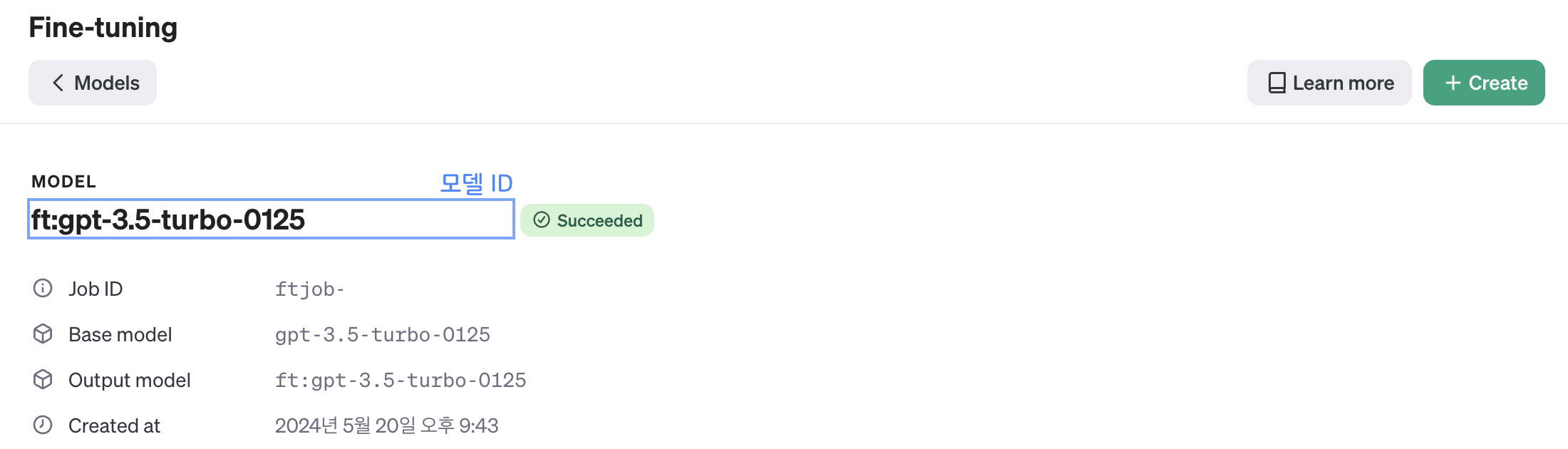
이렇게 하면 프로젝트에서 사용하기 위한 특정 목적에 적합한 파인튜닝 모델이 간단하게 생성된다! 🤗
1년동안 정말 열심히 했던 졸업프로젝트 남은 기간도 화이팅해서 잘 마무리할 수 있었으면 한다! 🙌🏻
우리 팀 채린 지민이 모두 수고했어 🤍

