
ℹ️ 프로젝트 개요
프로젝트 소개
2023년 9월부터 캡스톤디자인 프로젝트를 컴퓨터공학과 동기 세 명과 진행하게 되었는데, 많은 회의끝에 확정된 주제명은 다음과 같다.
ONCE : 카드 다보유자의 똑똑한 소비를 위해 결제 전 최대 혜택을 받을 수 있는 카드를 추천해 주는 AI 챗봇 서비스
프로젝트명은 우리의 프로젝트를 처음 들어본 제3자가 한눈에 이해하기 쉽게 작성하는 것이 좋기 때문에, 프로젝트명을 정할 때 많은 시행착오를 겪었다...! 😢
처음에는 Once : 개인 보유 카드 기반 카드 활용 컨설팅 AI 서비스 로 프로젝트명을 정했는데, 명사를 나열한 문장이라 보자마자 이해가 바로 되지 않는 문제가 있었다.
우리가 하려고 하는 프로젝트를 모르고 있는 주변 사람들에게 여러차례 물어가며 한 문장으로 우리의 프로젝트를 표현하기 위해 노력했다.
그 결과, ONCE : 카드 다보유자의 똑똑한 소비를 위해 결제 전 최대 혜택을 받을 수 있는 카드를 추천해 주는 AI 챗봇 서비스 라는 프로젝트명을 정하게 되었다.
ONCE 는 우리의 서비스를 사용하는 것만으로도 한번에, 한눈에 카드 혜택을 비교할 수 있다는 것을 강조하는 뜻을 담고 있는 서비스명이다.
구체적으로 어떤 프로젝트를 진행하려고 하는지 pain point 와 solution 관점에서 설명해 보자면,
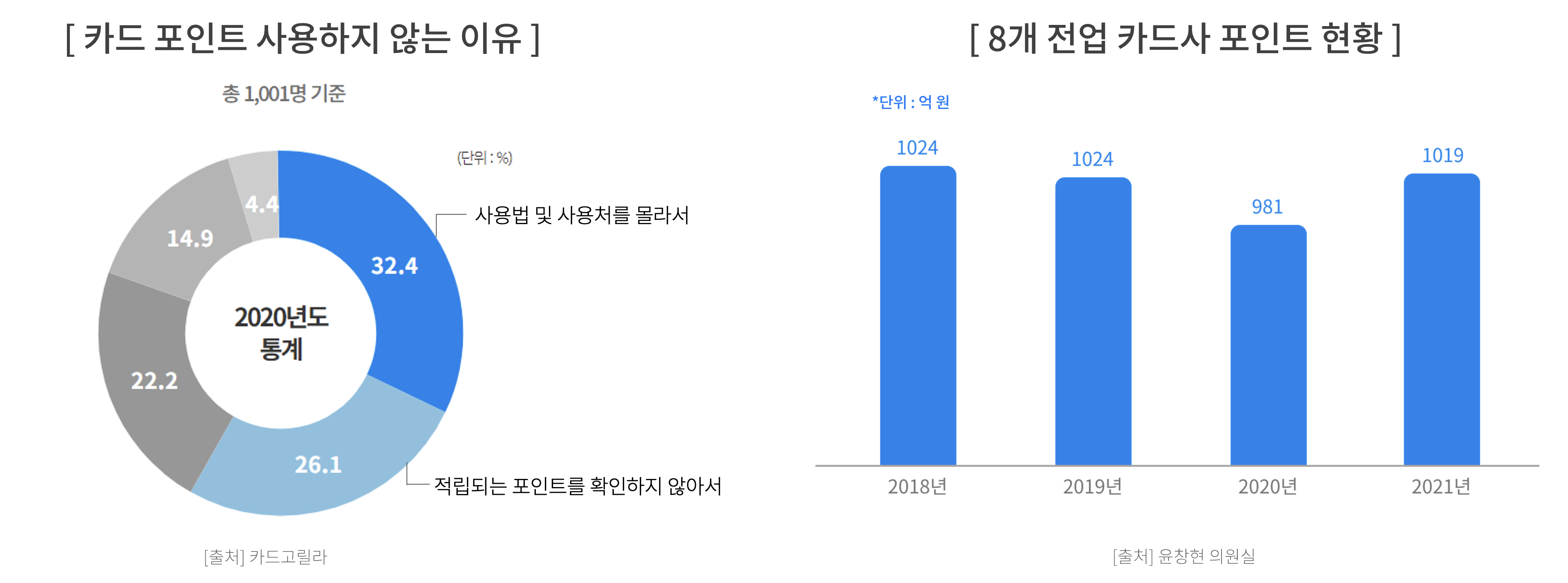
매년 쓰지 않고 사라지는 카드 포인트 1000억원과 카드사에서 제공하는 혜택을 소비자가 적절히 활용하기 어렵다는 문제를 페인 포인트로 발견했고, 우리 팀은 ONCE 애플리케이션을 통해 소비자들이 복잡한 계산 없이 카드사의 혜택 조건을 꼼꼼히 챙겨 현명한 소비를 할 수 있도록 솔루션을 제공하고자 한다.
본 블로그에서는 앞으로 2024년 6월까지 진행할 캡스톤디자인프로젝트 여정을 성공적으로 마무리하기 위해 그동안 공부했던 기술들에 대하여 알기 쉽게 설명해볼 것이다! 🙌🏻
프로토타입
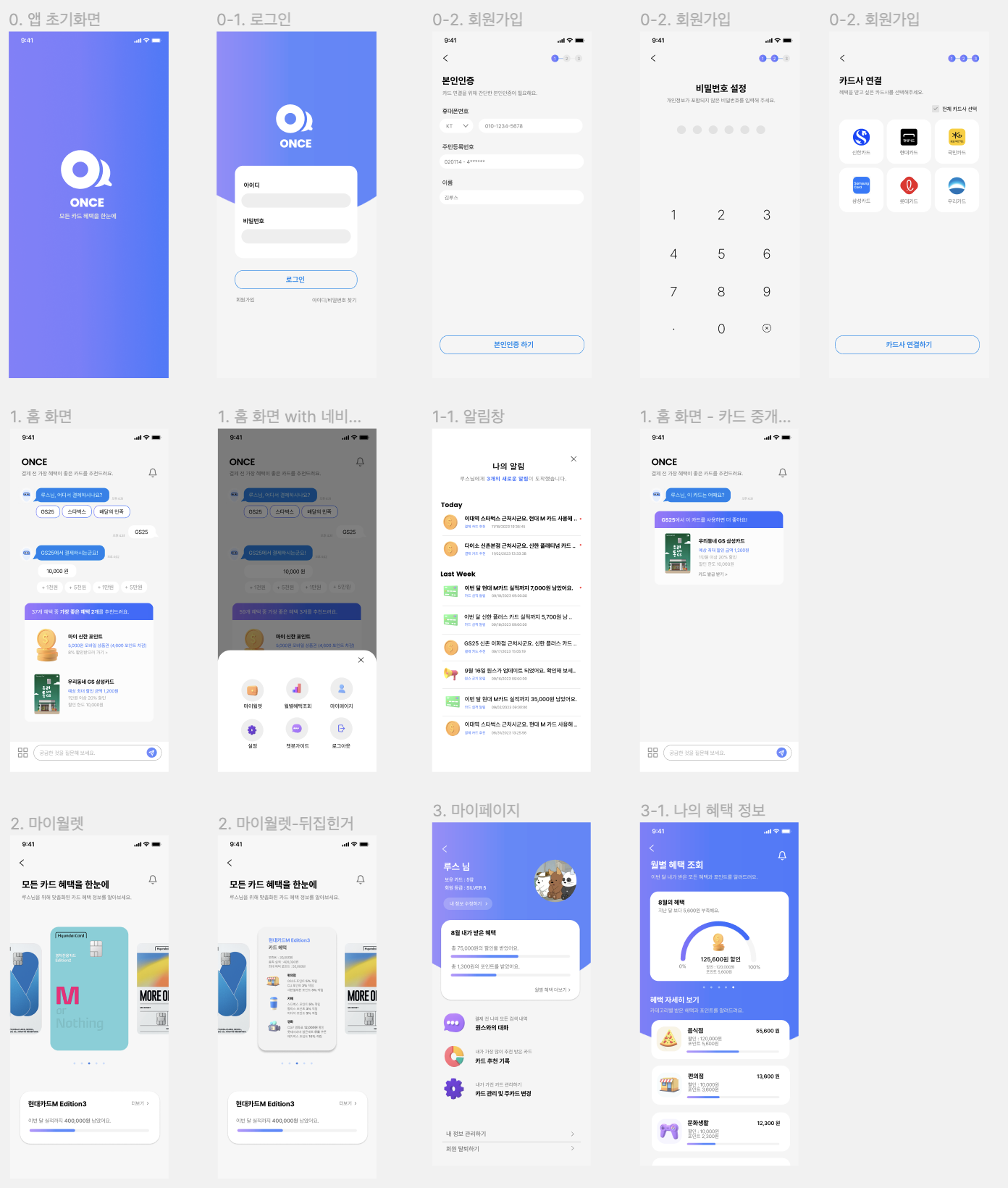
ONCE 애플리케이션의 핵심 기능은 홈 화면에서 챗봇에게 결제할 장소의 상호명을 입력하면, 보유한 카드 중에서 어떤 카드를 사용하면 좋을지 알려주는 것이다.
사용자에게 친근한 것은 검색을 통해 정보를 제공하는 것인데, 챗봇 UI를 선택하게 된 이유가 있다.
우리 앱을 사용할 사용자 시나리오를 생각해보았을 때, 검색 기능을 사용한다면 아래의 예시처럼 많은 단계를 거쳐야 한다.
핸드폰 잠금 해제 → 앱 접속 → 검색 폼 클릭 → 타이핑 → 검색 버튼(돋보기) 누르기따라서 사용자가 핵심 서비스를 이용하기까지 가장 최소한의 단계가 필요하다고 생각하여 챗봇 UI 를 홈 화면에 적용하게 되었다.
또한, 우리가 제공하고자 하는 서비스는 사용자가 결제할 타이밍 전에 우리 ONCE 앱에 접속해야 하는 것을 기억해줄 것을 기대해야 한다.
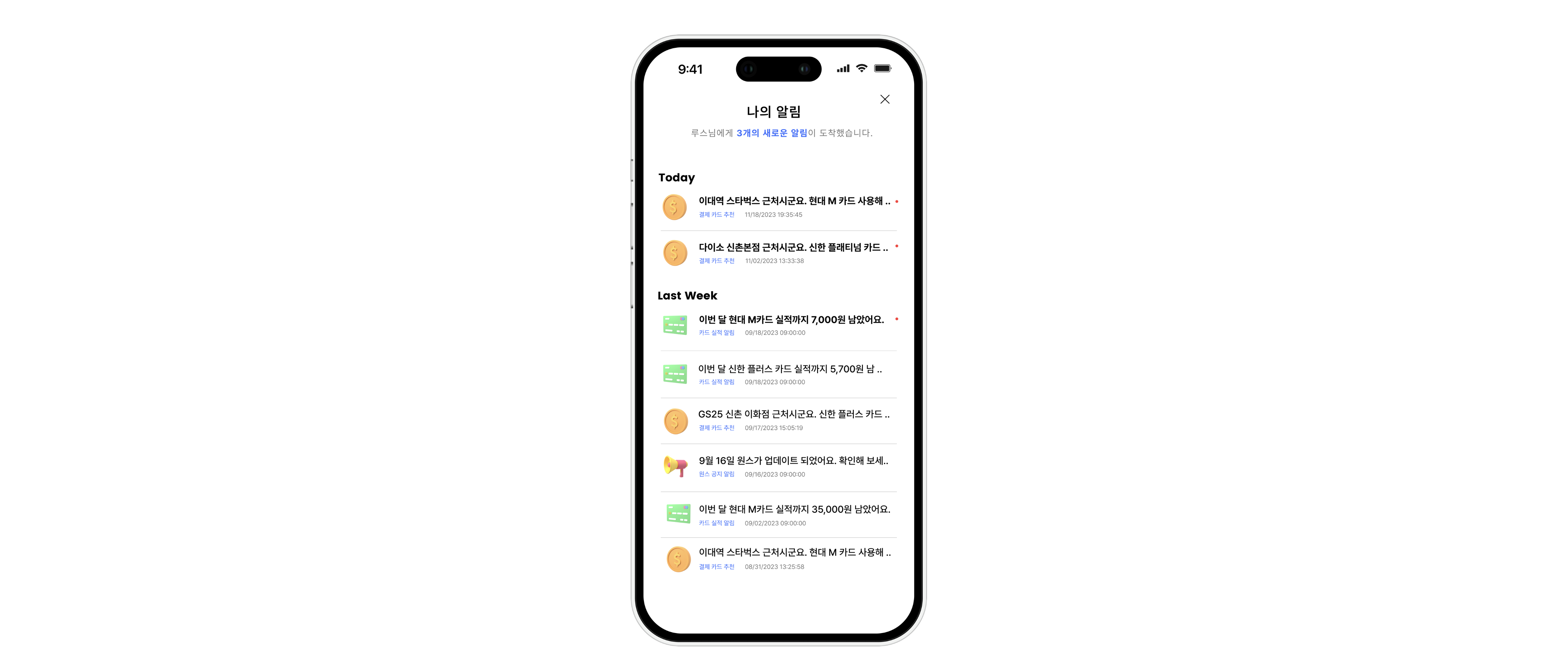
이러한 행위는 습관 형성이 필요하기 때문에, 사용자가 앱에 접속하지 않아도 GPS 기능 을 이용하여 푸시 알림 을 통해 결제할 카드를 미리 알려주는 서비스도 기획하게 되었다.
🛠️ 개발 환경
개발 환경
개발 환경을 7가지로 세분화하여 표현하면 다음과 같다.
1. Version Control

버전 관리는 git과 GitHub을 이용해서 하려고 한다.
2. Communication

우리 팀은 현재 노션을 활용하여 모든 회의록 및 프로젝트 관련 진행 사항을 기록하고 있으며, 비대면 회의는 디스코드로 진행하고 있다.
3. Development Tool

VSCode를 이용하여 크로링 파인튜닝을 진행하고, Android Studio 로 프론트엔드 개발을, IntelliJ를 이용하여 백엔드 개발을 진행하려고 한다.
4. Design Tool

앞서 언급한 프로토타입은 모두 Figma를 이용하여 설계했다.
5. Front-End

우리는 Flutter로 모바일 애플리케이션을 개발할 것이다.
Flutter는 iOS 와 Android 모두에서 동작하는 크로스 플랫폼 애플리케이션 개발이 가능하기 때문에 해당 프레임워크를 선택하게 되었다.
6. Back-End

백엔드 프레임워크는 Spring Boot를 이용할 계획이다.
그리고 클라우드 호스팅은 AWS 에서 제공하는 EC2, RDS, S3 를 사용할 것이다.

또한, 크롤링 라이브러리로 BeautifulSoup, Selenium, 파이썬에서 제공하는 Requests 모듈을 사용했다.
7. AI

카드 추천 모델은 OpenAI에서 제공하는 GPT3.5 모델을 Fine-Tuning하여 구현할 계획이다.
주요 기술
ONCE 애플리케이션의 주요 기술은 크게 세 가지가 있다.
- 스크래핑 기반 금융 API를 이용한 사용자 정보 조회
스크래핑이란 각 카드사와 통신하여 실제 데이터를 제공하는 것을 의미한다. 따라서 스크래핑 기반 금융 API인 CODEF API를 이용하여 사용자의 실제 카드 보유 목록 및 실적 충족 여부 데이터를 받아올 수 있다.
-
크롤링을 이용한 카드사 별 카드 혜택 정보 수집
파이썬 크롤링 라이브러리BeautifulSoup,Selenium,Requests등을 이용하여 카드사에서 제공하는 카드 별 상세 혜택 정보 데이터를 수집할 수 있다. -
파인튜닝 된 GPT 모델을 활용한 사용처에 맞는 카드 추천
OpenAI에서 제공하는GPT3.5모델을 Fine-Tuning 하여 결제처(input)에서 최적의 혜택을 누릴 수 있는 카드(output) 정보를 내놓는 모델을 구현할 수 있다.
📍 사용할 기술
지금부터는 ONCE 의 주요 기술 구현을 위해 그동안 내가 진행했던 부분에 대해 이야기해 보려고 한다.
크게 CODEF API 테스트, 카드 혜택 정보 크롤링, GPT3.5 파인튜닝, React Native 초기 환경 설정을 했다.
CODEF API
우리가 진행하려고 하는 프로젝트는 개인의 민감한 금융 정보를 사용하는 서비스이기 때문에 이번 학기(23-2)에 진행한 중간 발표나 창업경진대회에서 보안과 관련한 질문을 꽤 받았었다.
CODEF API 작동 방식을 설명하며 이 부분에 대한 답변을 하고자 한다.
먼저, CODEF API는 은행, 카드, 증권, 보험, 공공기관 등 다양한 기관의 데이터를 한곳으로 모아 쉽게 활용할 수 있는 방법을 제공해 주는 Data Aggregation Service이다.
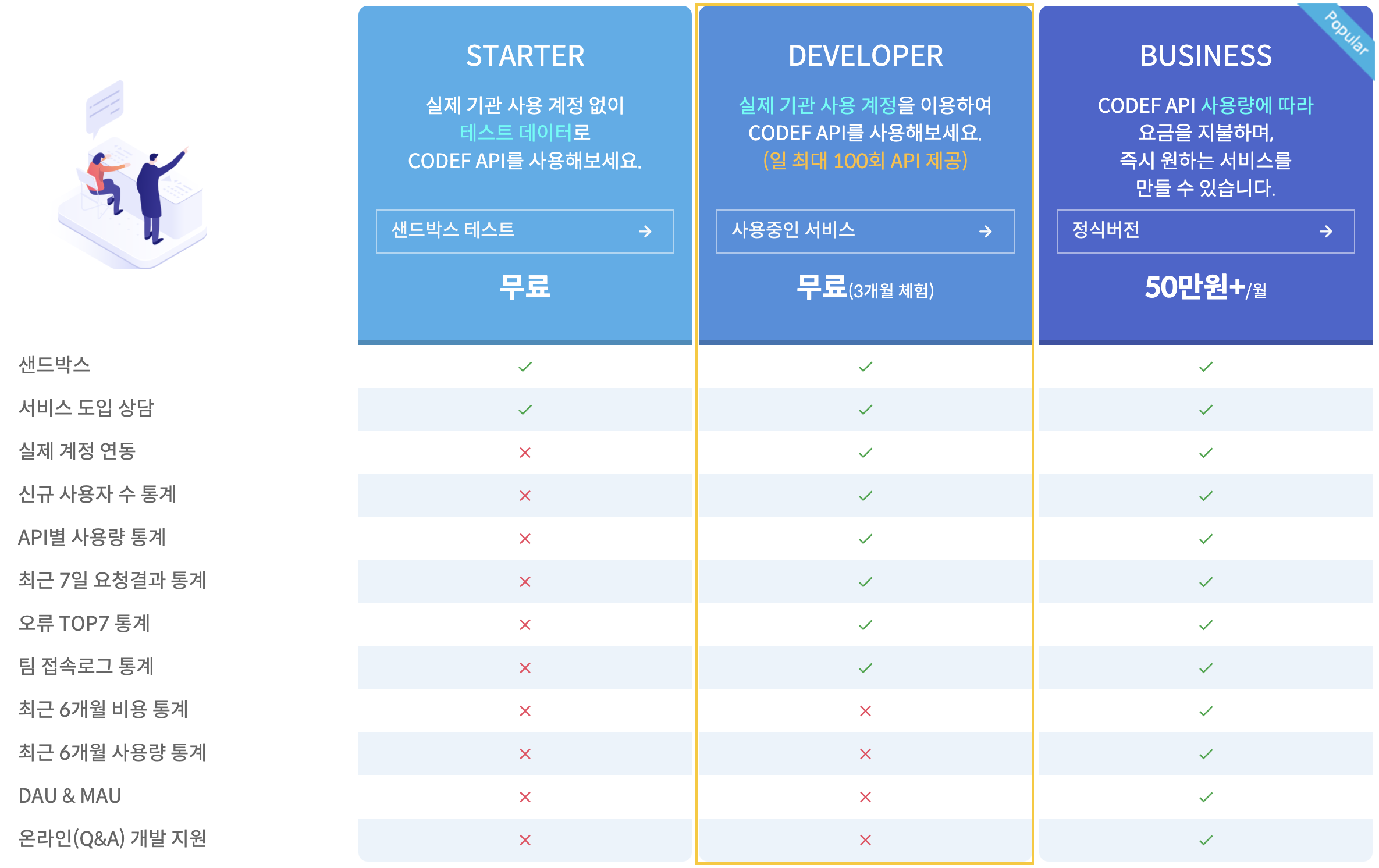
현재 기능 구현을 위해 실제 기관 데이터를 제공하는 DEVELOPER 버전의 API를 사용하고 있는데, 추후 ONCE 애플리케이션을 출시하게 된다면 BUSINESS 버전의 API를 사용할 예정이다!
CODEF API의 흐름도는 다음과 같다.
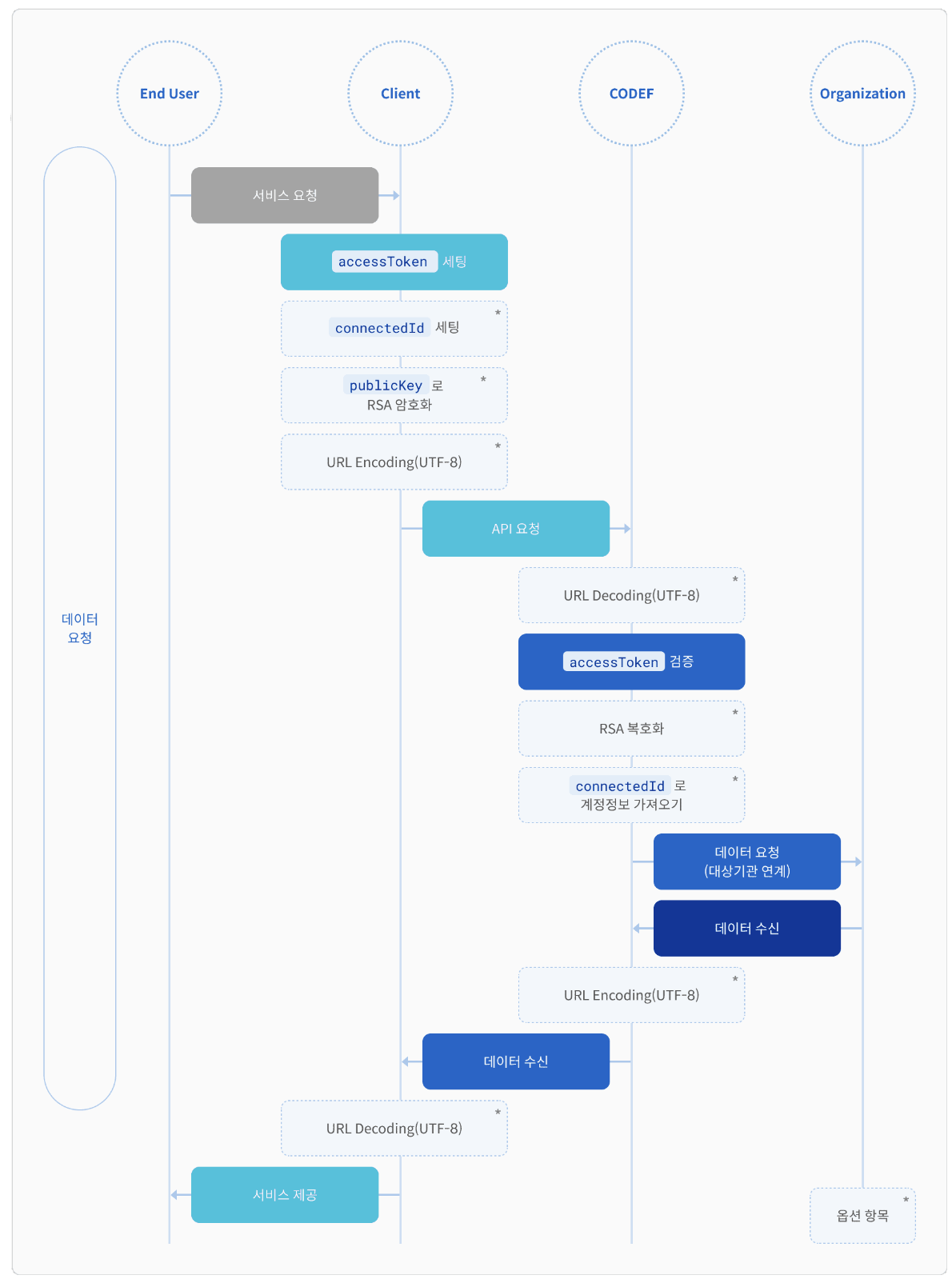
End User가 서비스를 요청하면 CODEF API 인증에 필수인 accessToken 을 발급받아야 하고, 이때 토큰을 발급받기 위해서는 개인마다 발급된 publicKey 로 RSA 암호화가 필요하다.
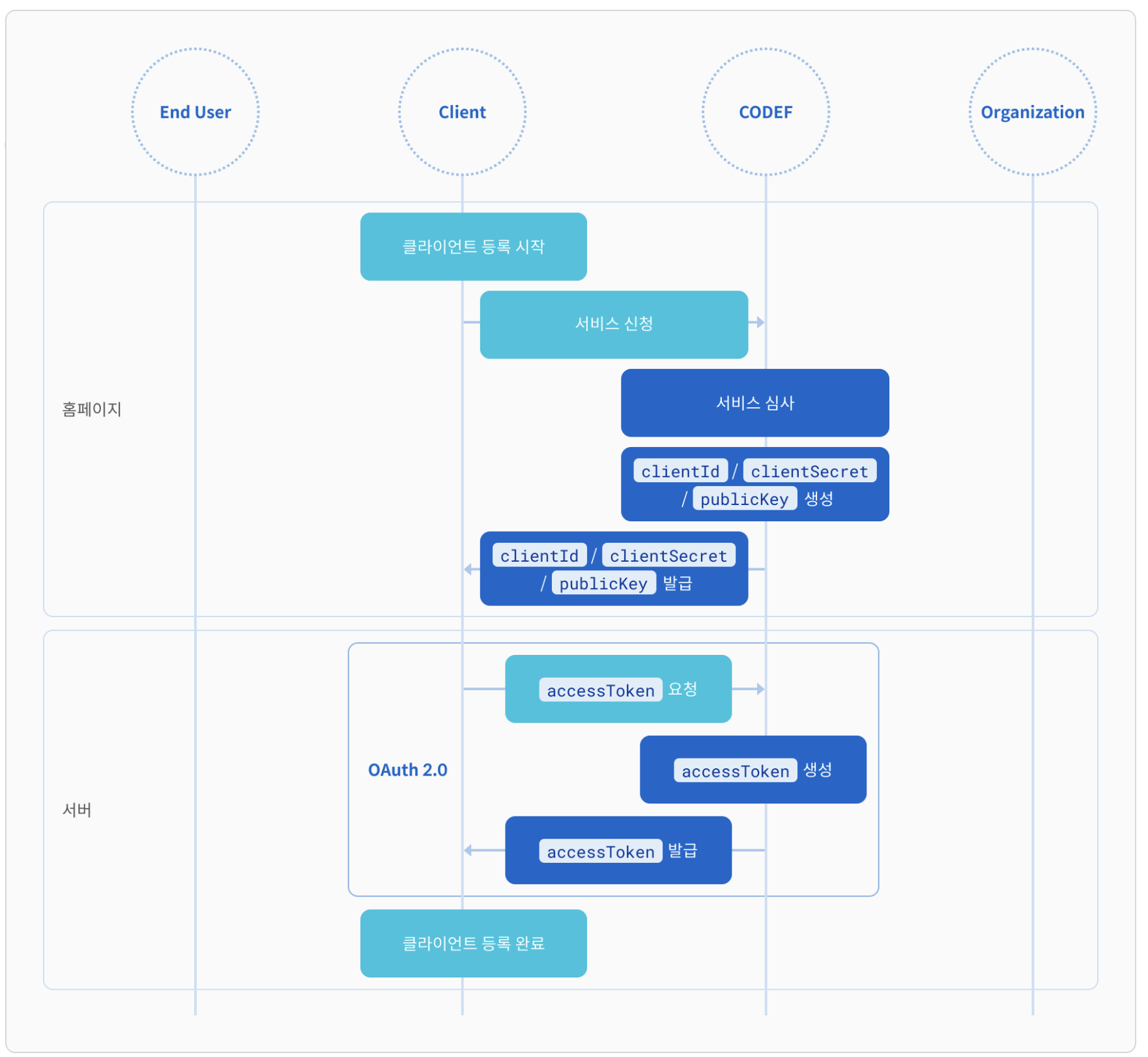
CODEF API를 사용하기 위해서는 발급된 accessToken 을 HTTP 헤더에 포함하여 요청해야 한다.
그리고 개인의 로그인 정보 (인증서, ID/PW)를 식별하기 위해서는 connectedId 발급이 필요한데, 은행•저축은행•카드•보험•증권 등의 API 상품을 이용할 때 connectedId를 통한 인증 과정이 필요하다.
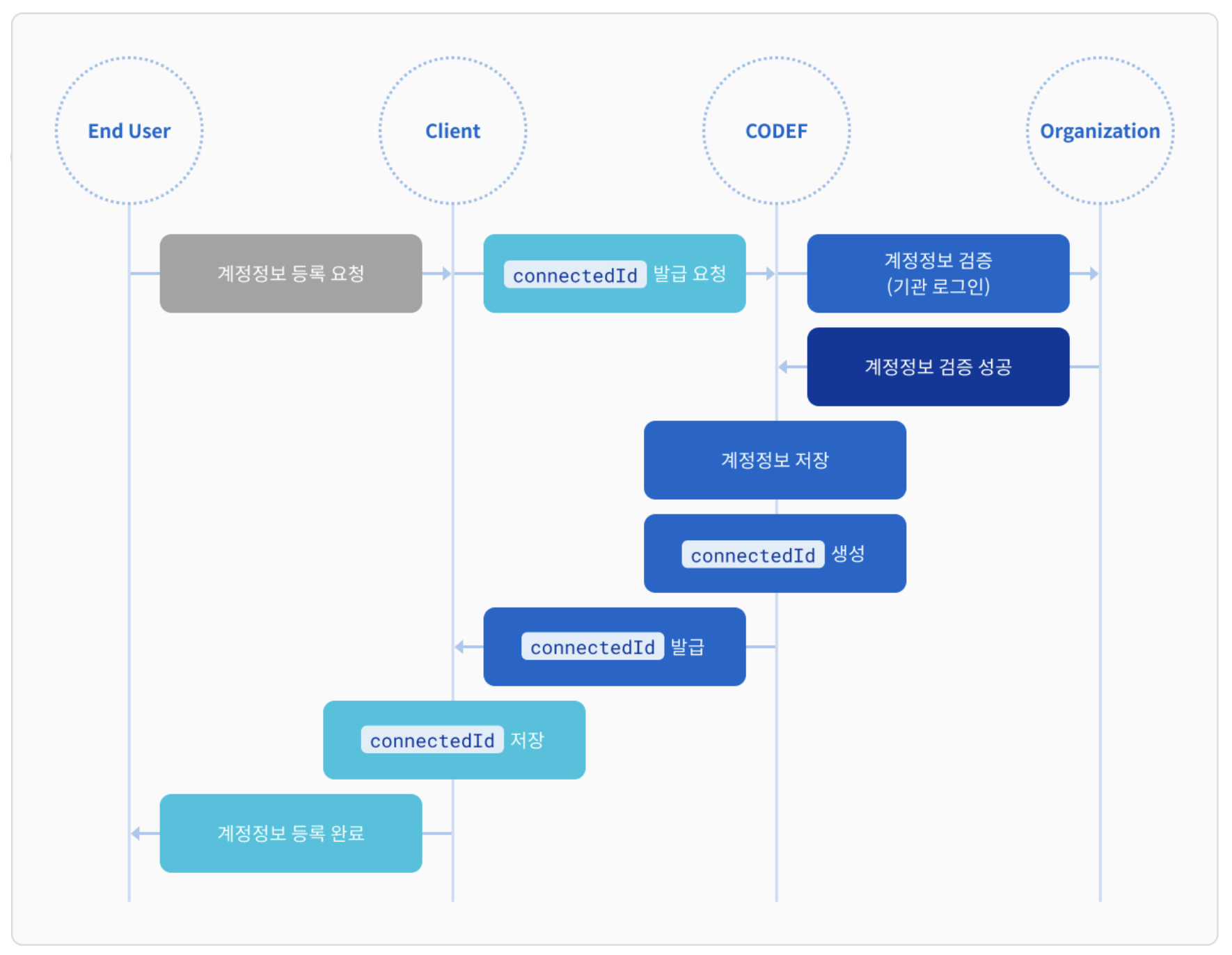
End User가 계정정보 등록을 요청하면 connectedId 발급 요청이 진행되는데, 이때 커넥티드 아이디로 End User에 정보에 대한 식별은 불가능하다. 왜냐하면, 개인정보는 모두 암호화가 되어 전달되기 때문이다.
(프로젝트 주제 확정 전에 기술적으로 구현이 가능한 것이 선행되어야 한다고 생각해서 카드 승인 내역 등 카드 거래 관련 실제 데이터를 제공하는 API를 많이 찾아보았는데, 사업자등록 없이도 테스트해볼 수 있는 것은 CODEF API가 유일했다. 혹시 우리처럼 금융 정보를 활용하는 프로젝트를 기획 중인 사람이 있다면 이 글이 도움이 되었으면 좋겠다!! 🤗)
크롤링
크롤링(crawling)이란 웹상에 존재하는 정보를 수집하는 작업을 의미한다.
주로 HTML 페이지를 가져와서 필요한 데이터만 추출하는 과정을 거친다.
웹 크롤링에서는 BeautifulSoup, Selenium, Requests 라이브러리를 사용한다.
각 라이브러리를 자세히 살펴보면 다음과 같다.
BeautifulSoup: 파이썬으로 HTML 웹문서 분석을 도와주는 라이브러리Requests: 파이썬으로 웹사이트 접속을 도와주는 라이브러리Selenium: 동적 웹 크롤링을 지원하는 라이브러리
ONCE 애플리케이션을 개발하기 위해서는 카드사에서 제공하는 카드별 상세 혜택 정보를 크롤링하는 과정이 필요하다.
처음에는 주요 카드사 6개 (신한, 현대, 국민, 삼성, 롯데, 우리)를 선정하여 카드사별로 5개의 카드씩 혜택 정보를 수집하려고 했는데, 사용자 맞춤형 서비스를 제공하기 위해 우선 MVP 개발을 목표로 다시 계획을 세우게 되었다.
우리 서비스의 주 타겟층은 40-50대 여성이므로, 각 카드사별로 쇼핑•백화점•마트 등에서 혜택이 많은 카드에 대한 정보를 우선적으로 크롤링하려고 한다.
본 블로그에서는 신한 Deep Store 카드의 혜택 정보를 수집해볼 것이다. 🙂
본격적으로 크롤링을 하기 전에 라이브러리 설치가 필요하다.
# python 3.9 버전 사용
$ pip3 install requests
$ pip3 install bs4
$ pip3 install selenium간단한 예제로 크롤링에 대해 살펴본 후, 신한 Deep Store 카드의 혜택 정보 수집 과정을 설명하고자 한다.
신한카드 홈페이지 접속 후, 원하는 글자 가져오기
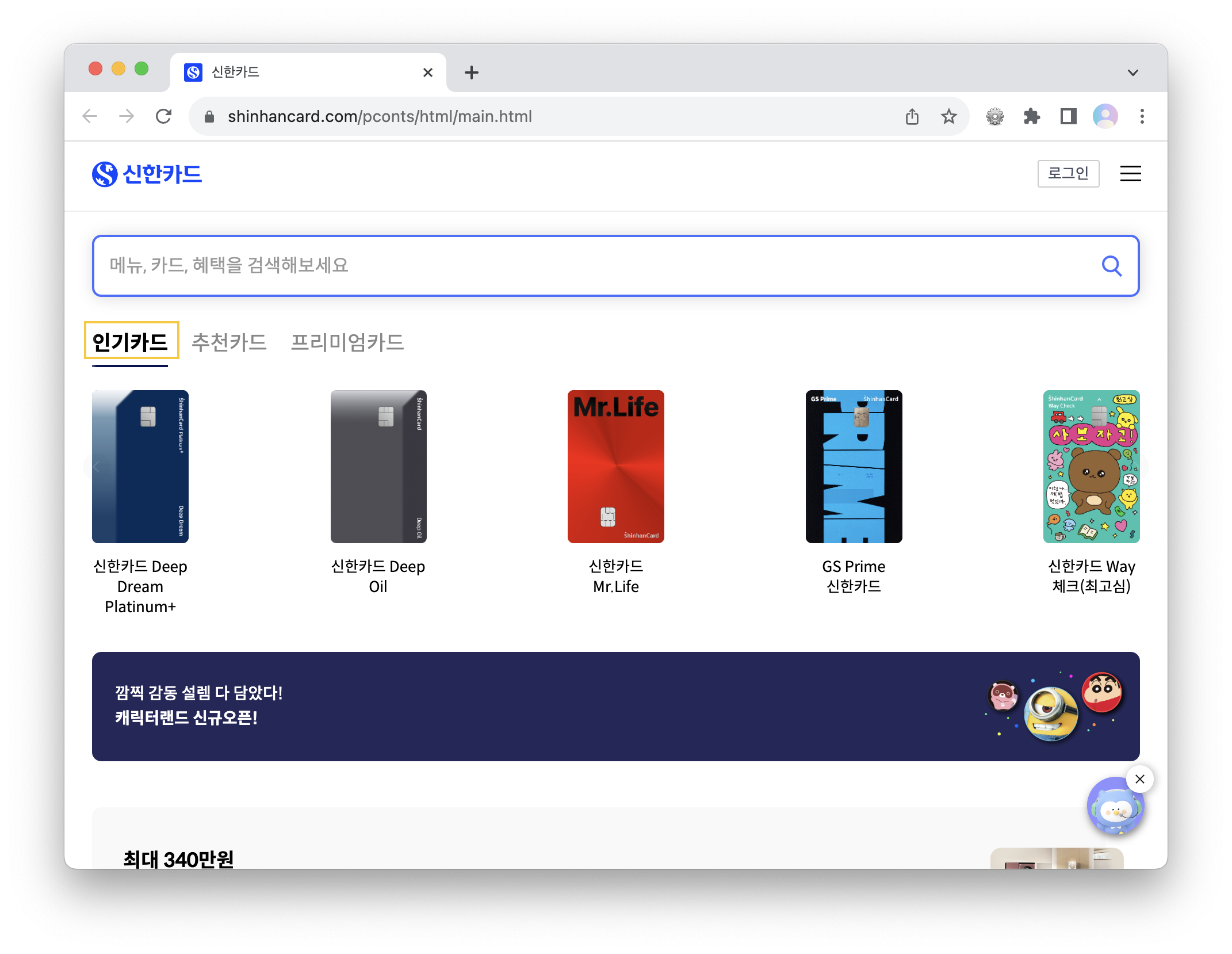
신한카드 홈페이지에 접속한 후, 위의 사진에서 노란색 박스로 표시한 '인기카드' 글자를 가져오는 코드를 작성해 보자.
먼저, Requests 라이브러리를 통해 웹사이트에 접속할 수 있다.
import requests
data = requests.get('https://www.shinhancard.com/pconts/html/main.html')
print(data.status_code) # 200이면 접속이 제대로 된 것200data.status_code 가 200이라면 성공적으로 접속되었음을 의미한다.
크롤링을 할 때는 개발자도구에서 페이지 요소를 분석하는 것이 중요하다. 왜냐하면, BeautifulSoup 라이브러리는 HTML 태그를 파싱해서 필요한 데이터만 추출하는 함수를 제공하기 때문이다.
우리가 추출하고자 하는 '인기카드'라는 글자는 아래 이미지에서 볼 수 있듯이 페이지요소에서 어느 태그에 속해있는지 찾을 수 있다.
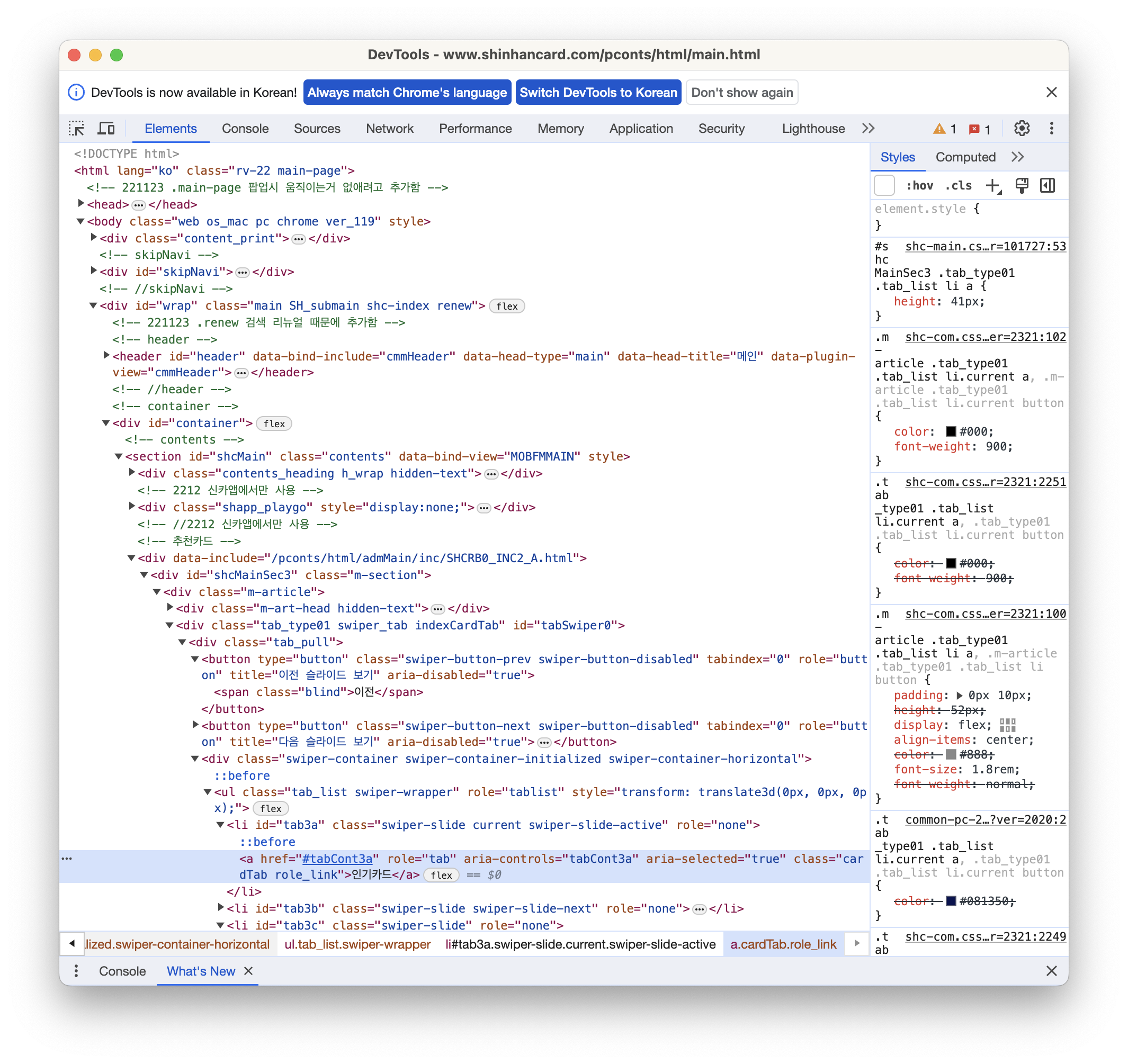
BeautifulSoup 라이브러리의 select_one()은 하나의 html 요소를 찾는 함수인데, css 선택자를 활용하여 쉽게 찾을 수 있다. 페이지 요소에서 내가 추출하고 싶은 글자가 있는 부분을 우클릭해서 css 선택자를 복사할 수 있다.
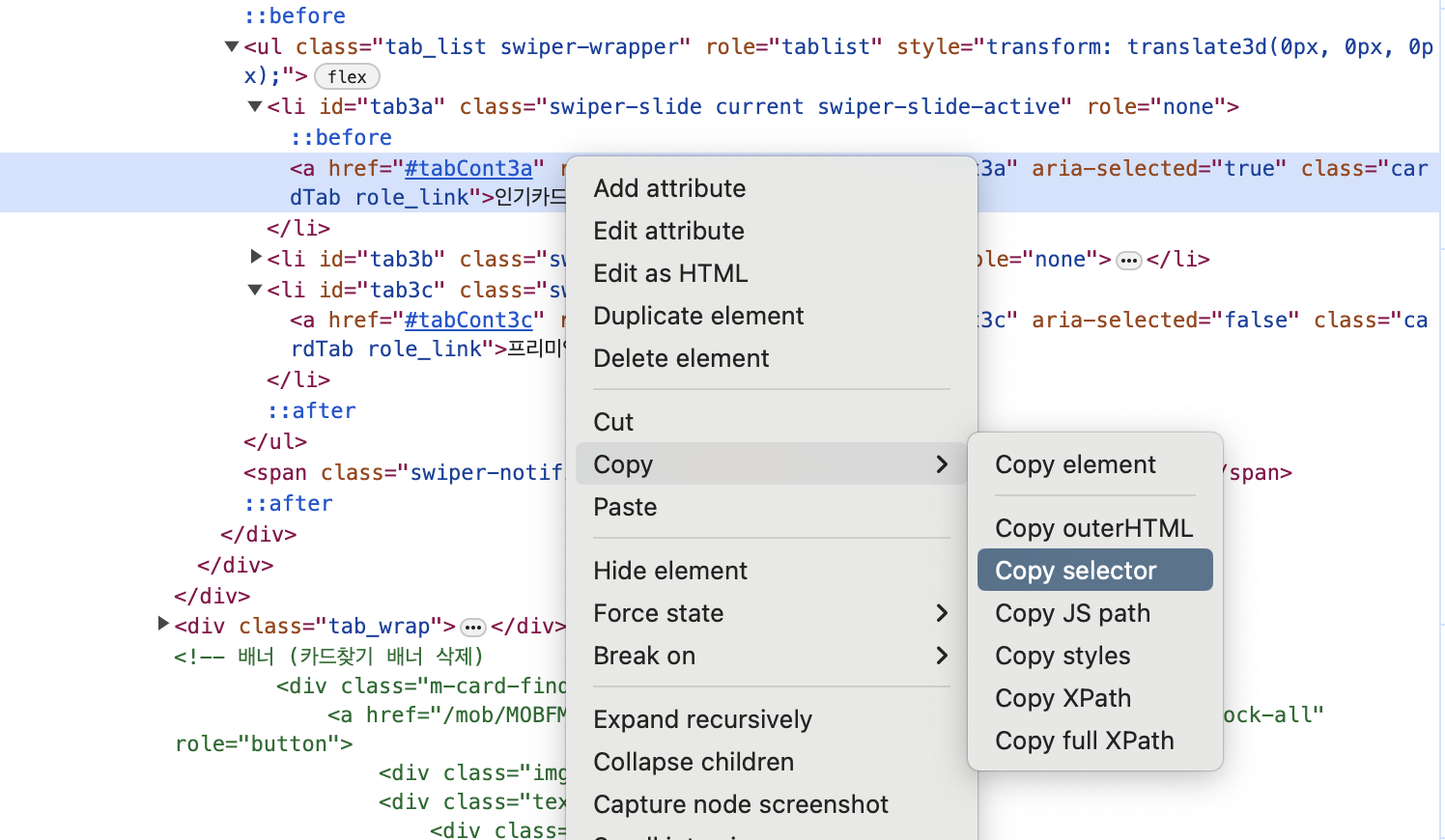
이렇게 복사한 css 선택자를 select_one() 함수 안에 넣어주면 된다.
import requests
from bs4 import BeautifulSoup
data = requests.get('https://www.shinhancard.com/pconts/html/main.html')
soup = BeautifulSoup(data.content, 'html.parser')
print(soup.select_one('#tab3a > a'))None 그런데 이렇게 크롤링을 하면 None 이라는 결과가 출력되는데, 이는 해당 요소가 동적으로 생성되는 경우이기 때문이다.
따라서 우리는 Selenium 을 이용하여 동적으로 웹 크롤링을 수행할 수 있도록 해야 한다.
from selenium import webdriver
url = 'https://www.shinhancard.com/pconts/html/main.html'
driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(10)셀레니움에서 webdriver을 import 한 뒤, 접속하고 싶은 url로 get(url) 함수를 사용하면 된다.
이때 driver.implicitly_wait(10) 는 요소가 안 보이면 최대 10초 기다리도록 하기 위해 사용했다.
아래 사진처럼 셀레니움을 사용하면 왼쪽 상단에 'Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다.' 라는 문구가 뜬다!!
from bs4 import BeautifulSoup
from selenium import webdriver
url = 'https://www.shinhancard.com/pconts/html/main.html'
driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(10)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
print(soup.select_one('#tab3a > a').text) 인기카드 셀레니움을 사용하지 않았을 때는 None 이라는 결과가 출력되었지만, 이번에는 우리가 원하던 글자가 정상적으로 출력되었다.
이번에는 신한 Deep Store 카드의 혜택 정보를 수집해 보자.
신한 Deep Store 카드 혜택 정보 추출
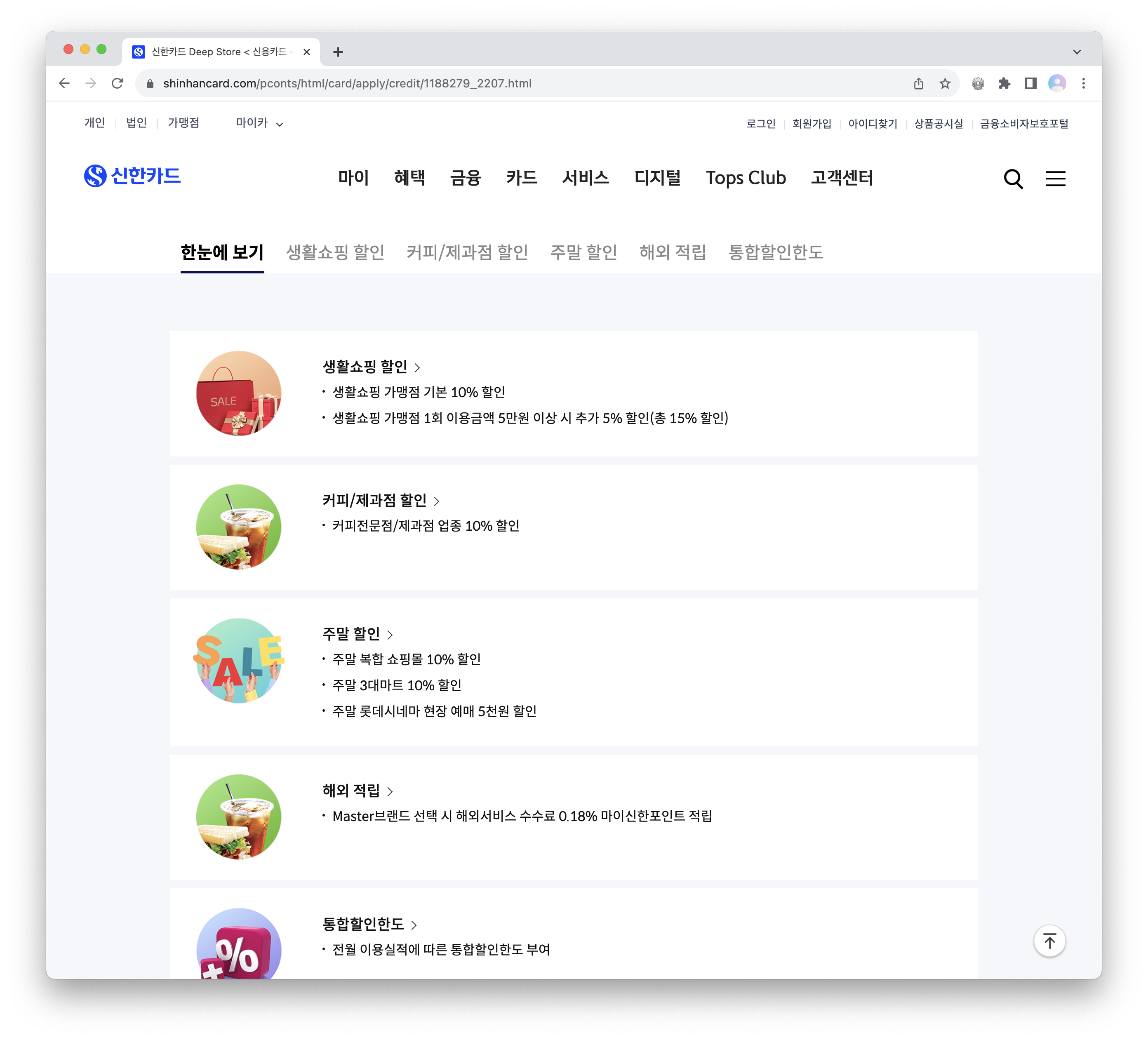
위의 이미지에서 '한눈에 보기' 탭에서 제공되는 5가지 할인 혜택 정보를 추출하려고 한다.
먼저, 5가지 할인 혜택 정보가 어느 태그 안에 있는지 페이지 요소를 분석해야 한다.
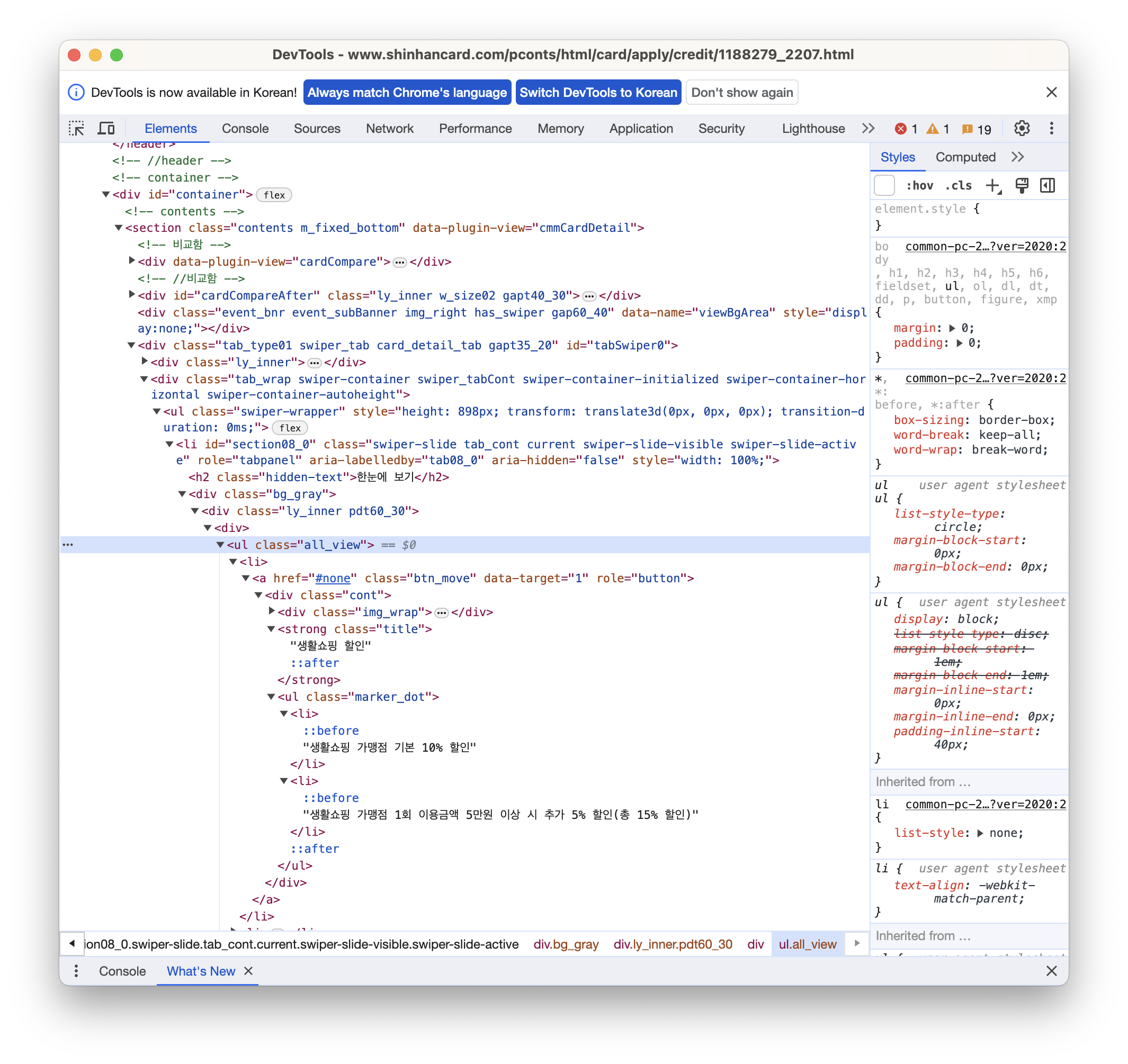
<ul> 태그의 all_view 라는 이름의 클래스에 속하므로, 5가지 혜택 정보가 담긴 html은 all_view = soup.find('ul', {'class':'all_view'}) 로 가져올 수 있다.
페이지 요소를 조금 자세히 살펴보면, '생활쇼핑 할인', '커피/제과점 할인', '주말 할인' 등과 같은 혜택의 제목은 <strong> 태그에 있다.
따라서 혜택 제목 리스트를 find_all() 함수를 통해 추출한 후, 그 리스트에서 각각 상세 혜택 정보를 추출할 수 있도록 반복문을 이용해서 코드를 작성했다.
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
# 신한 Deep Store 카드
url = 'https://www.shinhancard.com/pconts/html/card/apply/credit/1188279_2207.html'
driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(10)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
all_view = soup.find('ul', {'class':'all_view'})
strong_list = all_view.find_all('strong') # 혜택 제목 리스트
for i in range(len(strong_list)):
print(f'{i + 1}. ' + strong_list[i].text)
ul_tag = strong_list[i].find_next('ul', class_='marker_dot')
li_tags = ul_tag.find_all('li')
for j in range(len(li_tags)):
print(' - ' + li_tags[j].text)
1. 생활쇼핑 할인
- 생활쇼핑 가맹점 기본 10% 할인
- 생활쇼핑 가맹점 1회 이용금액 5만원 이상 시 추가 5% 할인(총 15% 할인)
2. 커피/제과점 할인
- 커피전문점/제과점 업종 10% 할인
3. 주말 할인
- 주말 복합 쇼핑몰 10% 할인
- 주말 3대마트 10% 할인
- 주말 롯데시네마 현장 예매 5천원 할인
4. 해외 적립
- Master브랜드 선택 시 해외서비스 수수료 0.18% 마이신한포인트 적립
5. 통합할인한도
- 전월 이용실적에 따른 통합할인한도 부여 출력 결과를 보면 우리가 추출하려고 했던 정보가 텍스트 형태로 출력되었음을 확인할 수 있다!
GPT-3.5 파인튜닝
GPT
GPT란 Generative Pretrained Transformer의 약어로, 그대로 직역하면 생성하는 사전학습 된 트랜스포머 모델을 의미한다.
우리에겐 2022년 11월에 출시된 ChatGPT 로 더 친숙한 모델이다.
ChatGPT 는 지도 학습과 강화 학습을 활용해 GPT-3.5 를 기반으로 세밀하게 조정되어, 다양한 지식 분야에서 상세한 답변을 제공한다.
이미 정교한 응답을 제공하는 ChatGPT 가 존재하는데, 그렇다면 우리는 왜 Fine-tuning이 필요할까?
그 전에 먼저 OpenAI 홈페이지에서 API 키를 발급 받고, 간단한 예제를 통해 Fine-tuning이 필요한 이유를 살펴보자.
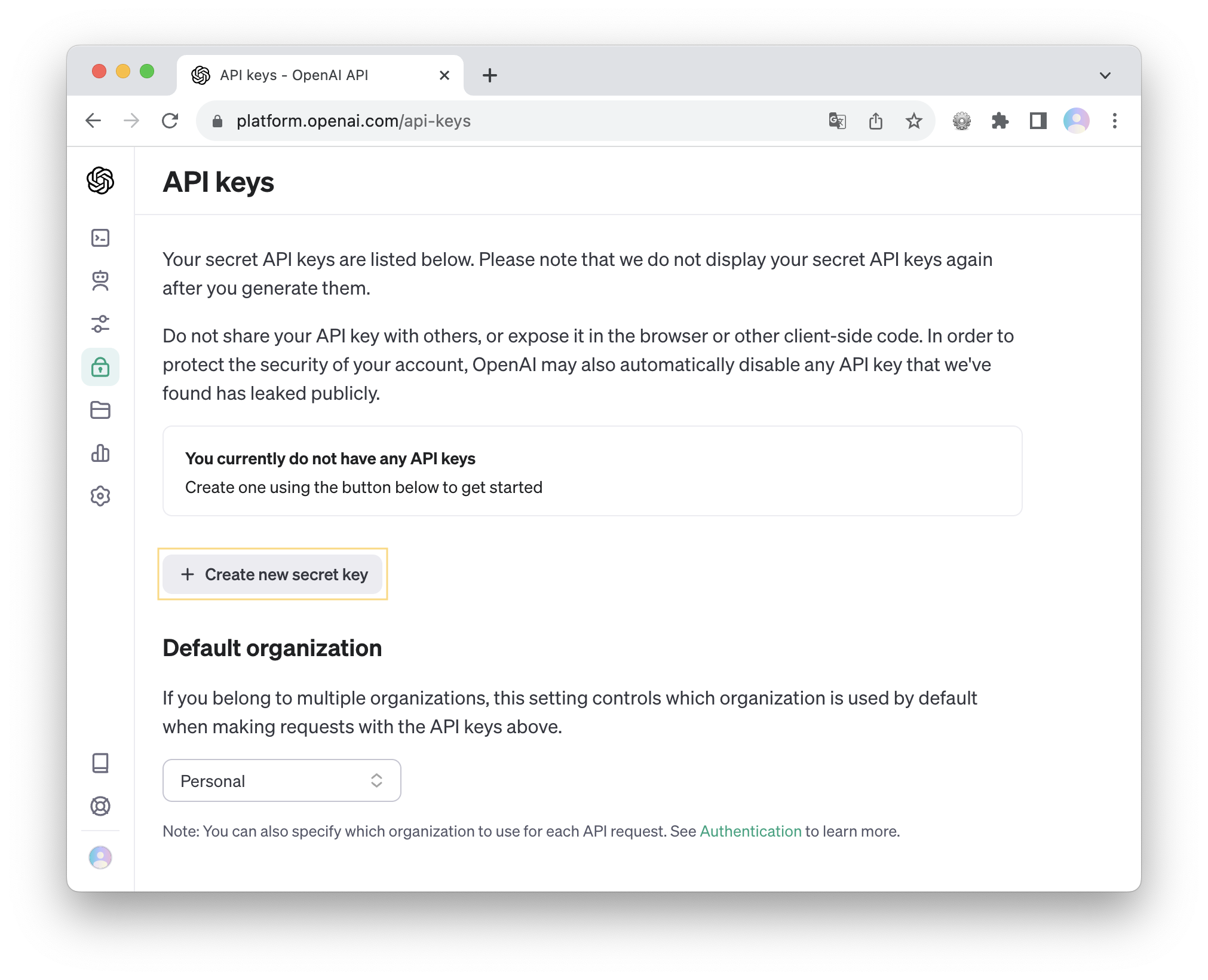
위의 사진에서 노란색 박스로 표시한 'Create new secret key'를 클릭하면 API 키를 발급 받을 수 있다.
또한, 파이썬 환경에서 openai 패키지를 설치하는 코드는 다음과 같다.
$ pip3 install openai
$ pip3 install python-dotenvAPI key 값은 보안이 중요하기 때문에 테스트 코드 파일이 있는 디렉토리에 .env 파일을 생성하여 코드상에서 노출되지 않도록 했다.
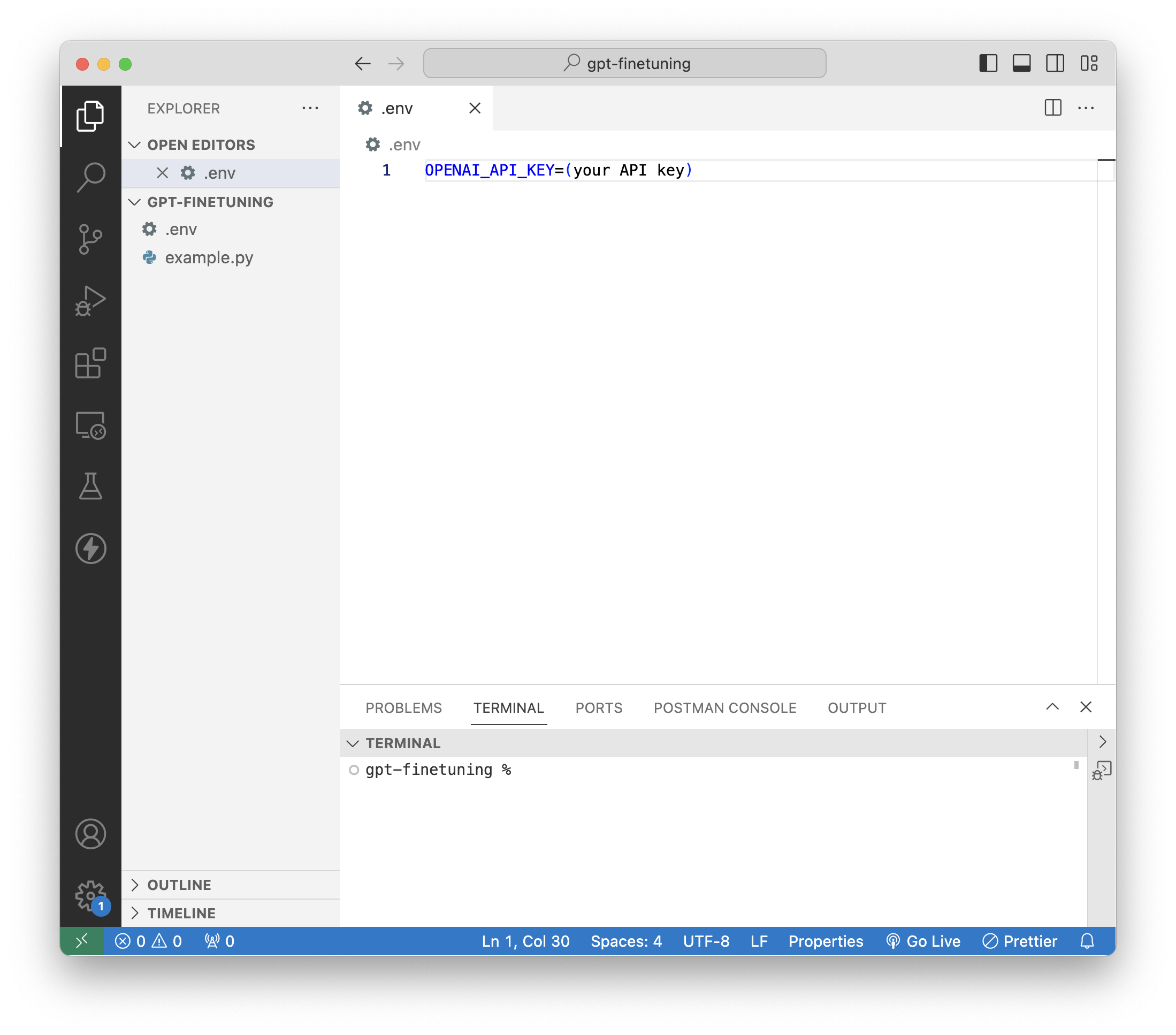
그리고 코드를 작성할 때, 다음과 같이 작성하면 API key를 불러올 수 있다.
import os
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")한 가지 예제로, ChatGPT 의 전신인 GPT-3.5를 기준으로 만들어진 모델인 text-davinci-003 모델에게 프롬프트 입력으로 질문을 던져보자.
import os
import openai
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Completion.create(
model = "text-davinci-003",
prompt = "2022년 동계 올림픽 1등 팀은? \nA:",
temperature = 0,
max_tokens=100,
top_p = 1,
frequency_penalty = 0.0,
presence_penalty = 0.0,
stop = ["\n"]
)
print(response)
print(response.choices[0].text.strip()) # 응답위의 코드를 통해, 2022년 동계 올림픽 1등 팀이 누구인지 질문을 던졌다.
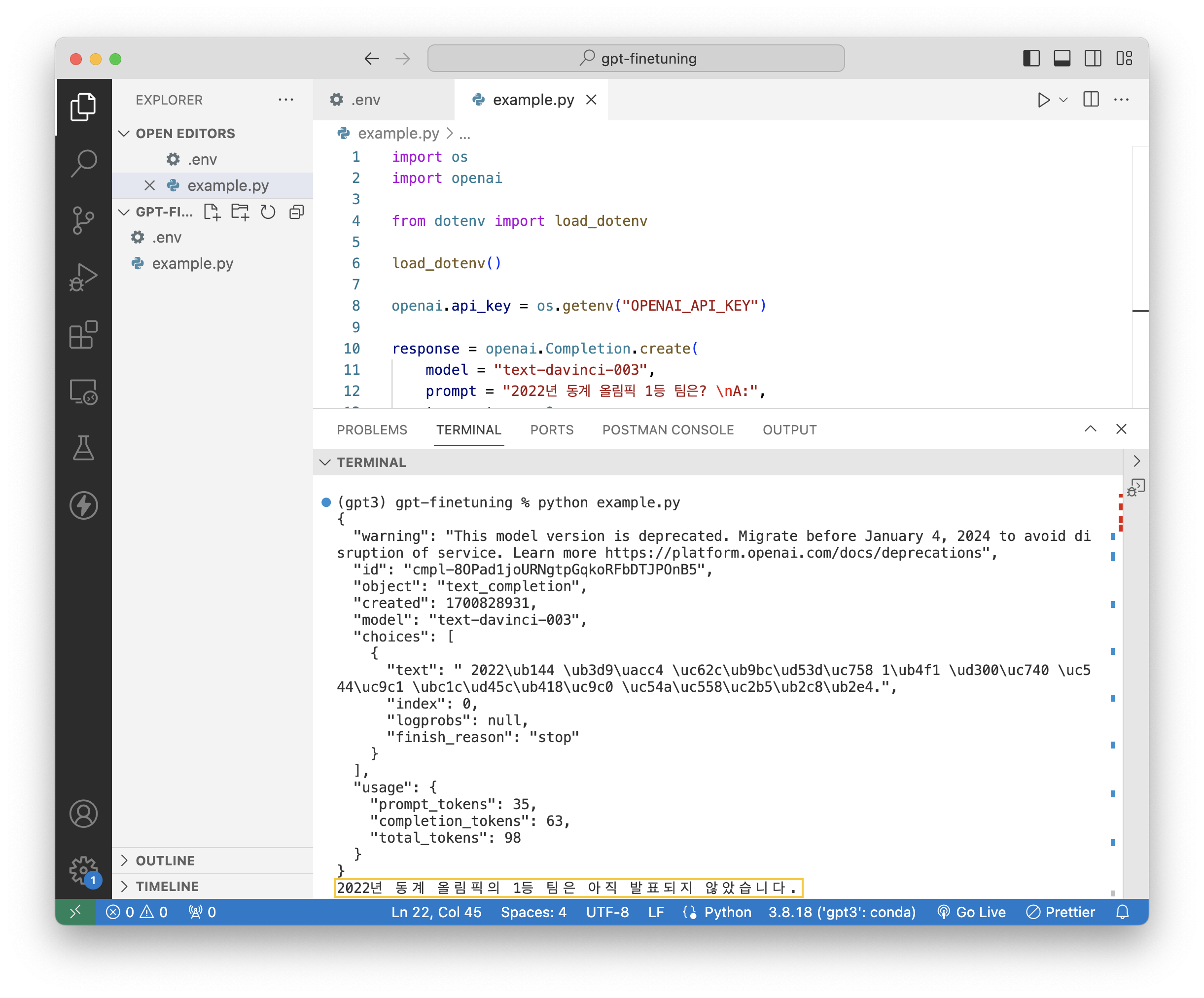
실행 결과를 보면, 2023년 11월인 현재는 결과가 발표되었는데 아직 1등 팀이 발표되지 않았다고 답하는 것을 볼 수 있다.
이처럼 text-davinci-003 모델은 2021년까지의 데이터로만 학습이 되어 있기 때문에 저런 답을 하는 것이다.
따라서 우리는 우리가 원하는 형태의 답을 얻기 위해서 Fine-tuning 과정을 통해, 답을 알려주거나 원하는 포맷으로 답이 나오도록 유도해야 한다.
(혹시 예제 코드를 실행했을 때, openai.error.RateLimitError: You exceeded your current quota, please check your plan and billing details. 가 발생한다면, 결제 정보에 카드가 등록되지 않아서 생긴 에러이다!
Billing settings 에서 Payment method를 등록하면 해결된다.)
GPT-3.5 Fine-tuning Process
GPT 모델을 파인튜닝하는 과정은 크게 3가지 단계로 이루어 진다.
- 데이터 준비
- 모델 생성
- 모델 활용
각 단계를 하나씩 살펴보자.
1️⃣ 데이터 준비

파인튜닝을 위한 데이터는 JSONL 타입의 데이터이며,
{”prompt” : “<prompt text>”, “completion” : “<ideal generated text>”} 형태로 내용이 구성되어야 한다.
나는 위의 사진처럼 데이터를 준비했다.
날씨 정보와 이름 정보를 준 후, 날씨에 따라 답 형태를 다르게 답변하도록 설정했다.
이렇게 생성한 example.jsonl 파일은 파인튜닝을 할 수 있도록, 다시 데이터를 생성해야 한다.
다음 명령어를 사용할 수 있다.
$ openai tools fine_tunes.prepare_data -f example.jsonl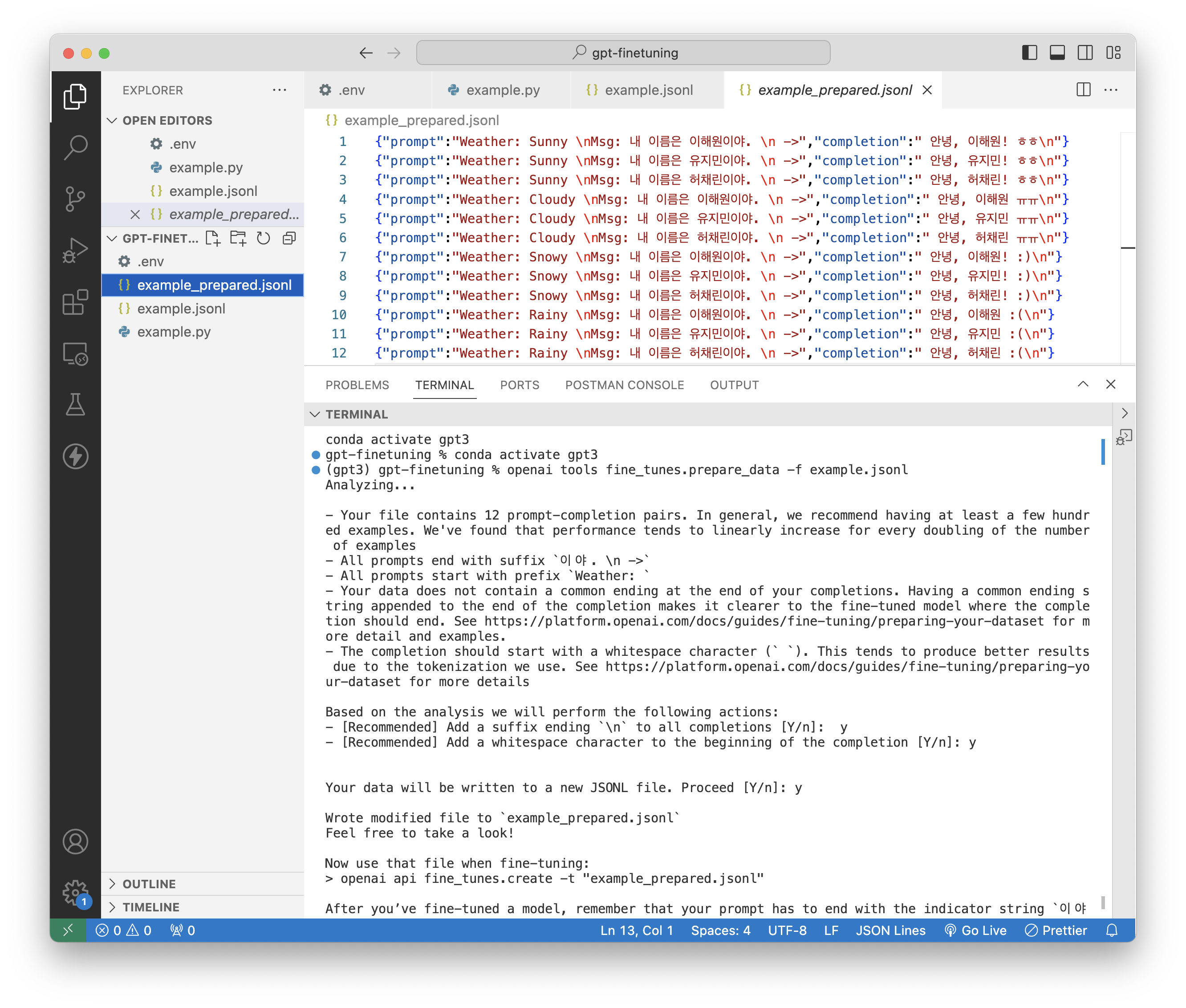
명령어를 수행하고 나면, 파인튜닝에 활용할 수 있도록 example_prepared.jsonl 파일이 새로 생성된다.
2️⃣ 모델 생성
파인튜닝을 할 수 있는 모델은 OpenAI에서 제공하는 base model을 활용할 수 있다.
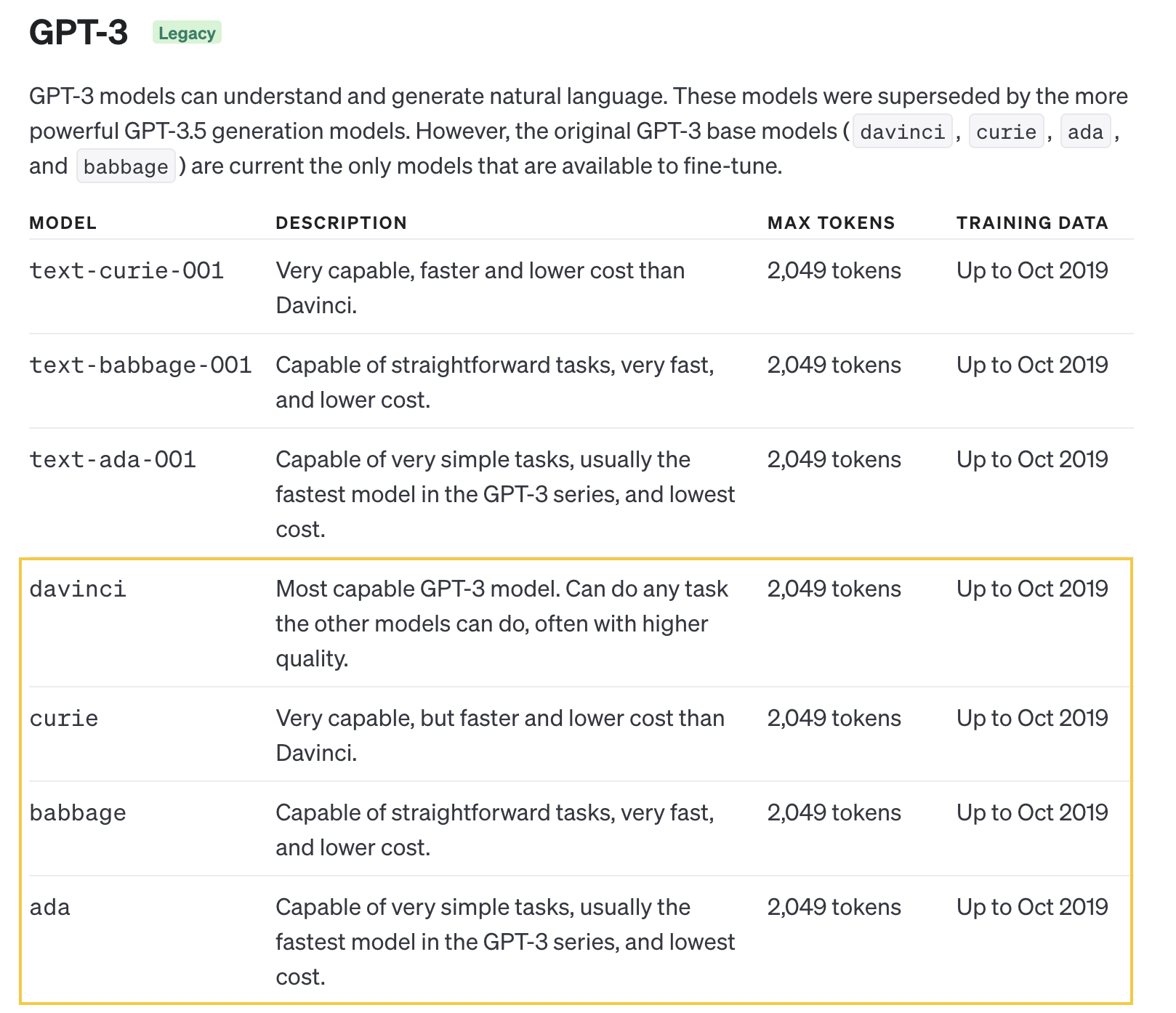
Base model에는 ada, babbage, curie, davinci 가 있는데, 더 자세한 정보는 공식문서에서 확인할 수 있다. 🤗
파인튜닝을 하기 위한 코드는 다음과 같다.
먼저, OpenAI에 데이터 파일을 등록해야 한다.
import openai
openai.File.create(
<file=open("example_prepared.jsonl", "rb"),
purpose='fine-tune'
)파일을 등록하면, 아래와 같이 file id를 응답으로 받게 된다.
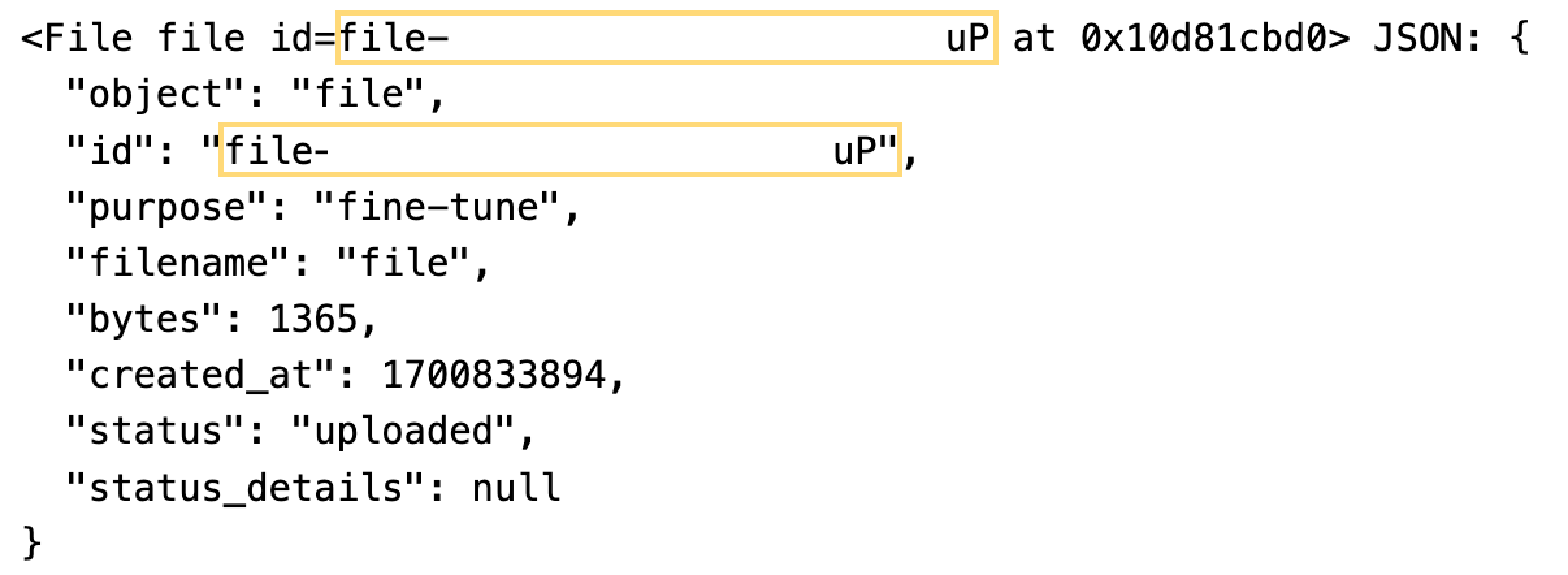
그리고 file id를 아래의 코드의 <FILE_ID> 부분에 넣어서 파인튜닝 작업을 요청해 주면 된다.
openai.FineTuningJob.create(training_file="<FILE_ID>", model="davinci-002")파인튜닝이 완료되면 OpenAI에 가입한 이메일 계정으로 파인튜닝이 성공적으로 완료되었다는 메일이 오게 된다!
파인튜닝 작업을 요청하면 작업 id 를 응답으로 받게 되는데, 파인튜닝 작업 진행 상황을 확인하고 싶다면 아래의 코드를 사용하면 된다.
openai.FineTuningJob.retrieve("ftjob-xxxxxxxxxxxxxxxxxx") # 작업 ID3️⃣ 모델 활용

생성된 파인튜닝 모델은 OpenAI 홈페이지에서 확인할 수 있다.
노란색으로 표시한 부분이 davinci-002 모델을 파인튜닝한 모델명인데, 이를 활용해서 내가 파인튜닝한대로 잘 동작하는지 테스트해 볼 수 있다.
import os
import openai
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Completion.create(
model = "ft:davinci-002:personal:: ", # 모델명 입력
prompt = "Weather: Sunny \nMsg: 내 이름은 이해원이야. \n ->",
temperature = 0,
max_tokens=100,
top_p = 1,
frequency_penalty = 0.0,
presence_penalty = 0.0,
stop = ["\n"]
)
print(response)
print(response.choices[0].text.strip()) # 응답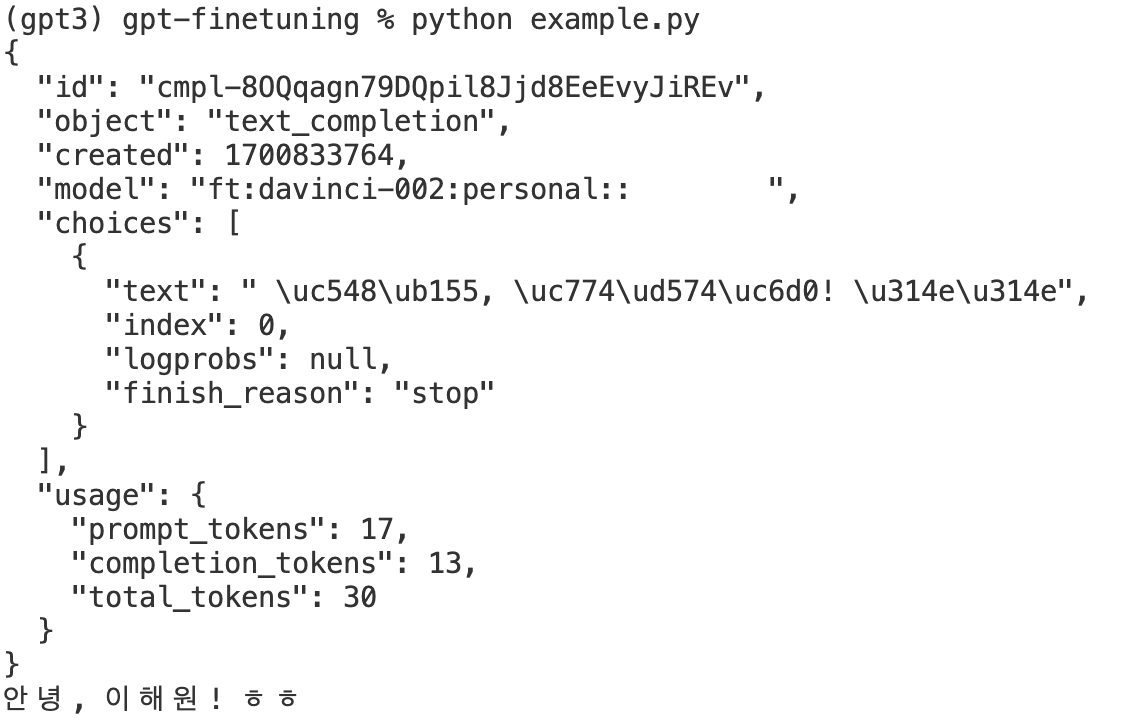
출력 결과를 보면, Sunny 날씨에 맞게 ㅎㅎ 글자를 포함하여 답을 한 것을 확인할 수 있다.
이름과 날씨를 바꿔 한 번 더 질문을 해보면, 다음과 같은 결과가 나온다.
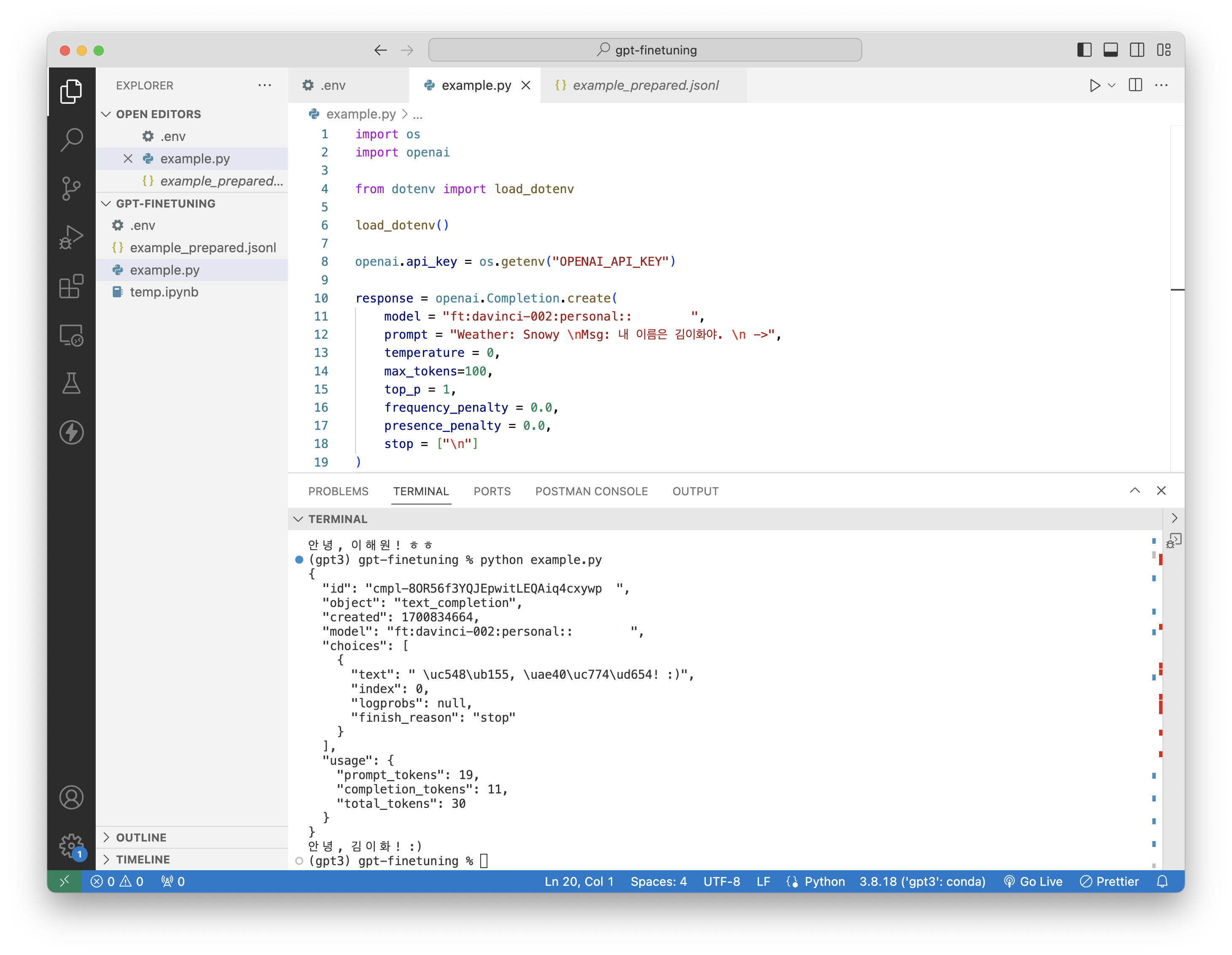
이렇게 해서 나만의 파인튜닝 모델을 만드는 과정이 끝이났다. 🙃
졸업프로젝트로 개발 예정인 ONCE 애플리케이션의 카드 추천 모델을 GPT-3.5 Turbo 모델을 파인튜닝하여 구현할 계획이다.
앞으로 남은 기간동안 카드 혜택 정보도 더 많이 수집하고, 파인튜닝에 대해 더 열심히 공부해서 꼭 기능 구현에 성공하고 싶다!
남은 학기도 화이팅 🙌🏻
