앞에서 미니콘다 설치가 완료됐다면 mediapipe를 위한 셋팅을 해봅시다.
$ python -m pip install mediapipe
$ pip install insightface
insightface가 아닌 원하는 라이브러리의 인스톨러를 실행하면된다.Insightface는 안면인식을 하는 모델로 상업적 서비스도 생성이 가능하다.
인스톨을 하면 ERROR: Failed building wheel for insightface 에러가 발생하는데 살펴보면 tools가 필요하다고 나옵니다.

에러 중간에 보면 end of output 에러 문구 상단의 주소로 들어가서 "Microsoft C++ Build Tools" 설치를 받아주면 됩니다.
메인화면은 C## 데스크톱 체크하고 우측 사이드바에 체크 박스를 두개만 체크 !
Mediapipe의 가이드에 따라 설정해주면 되는데
먼저, Mediapipe의 작업을 위한 가장 기본 모듈이다.
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
from mediapipe.tasks.python import text
from mediapipe.tasks.python import audioinsightface를 사용하기 위해서는 아래의 모듈을 임포트해주어야 합니다.
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
그리고 원하는 모델을 설치해서 가져오기 편한 경로에 위치시킵니다.
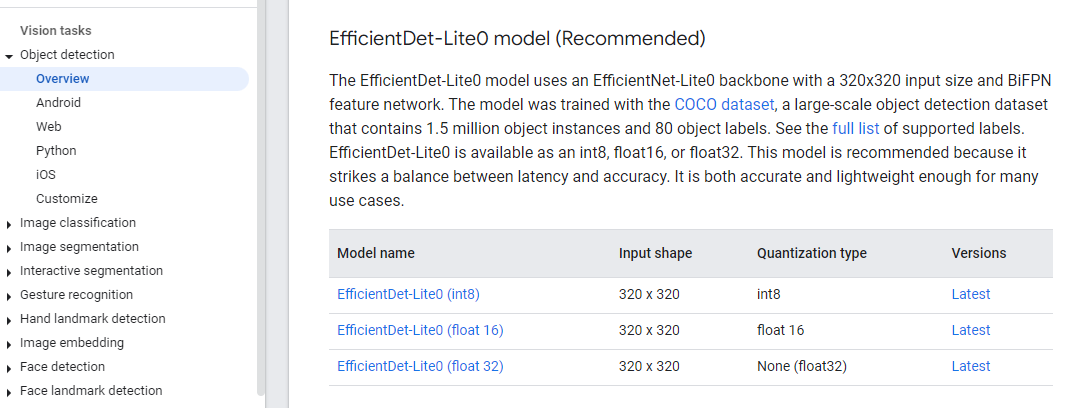
용량에 따라 정확도가 다르다. (다양한 테스트가 필요함)
모델의 경로를 읽어오기 위해 설정을 해주는데 윈도우와 맥에 따라 경로가 다른데, 아래는 윈도우 환경 경로 예시로 참고해주세요.
model_path = 'efficientdet_lite0.tflite'
vscode는 터미널과 코드에디터가 연동되있지 않기 때문에 연결을 해주어야 인식하므로 오류가 발생할 수 있기 때문에 당황하지말고 연결 후에 정상적으로 인식하는 것을 확인한다.
테스트를 위해 설정 후 이미지 파일이 정상적으로 열리는지 확인한다.
# 이미지 다운로드
#!wget -q -O image.jpg https://storage.googleapis.com/mediapipe-tasks/object_detector/cat_and_dog.jpg
IMAGE_FILE = 'image.jpg'
import cv2
from google.colab.patches import cv2_imshow
img = cv2.imread(IMAGE_FILE)
cv2_imshow(img)추론 실행 및 결과 시각화 과정 예시이다. 원하는 파일을 입력하고 추론결과를 확인해볼 수 있다.
# STEP 1: Import the necessary modules.
import numpy as np
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
# STEP 2: Create an ObjectDetector object.
base_options = python.BaseOptions(model_asset_path='efficientdet.tflite')
options = vision.ObjectDetectorOptions(base_options=base_options,
score_threshold=0.5)
detector = vision.ObjectDetector.create_from_options(options)
# STEP 3: Load the input image.
image = mp.Image.create_from_file(IMAGE_FILE)
# STEP 4: Detect objects in the input image.
detection_result = detector.detect(image)
# STEP 5: Process the detection result. In this case, visualize it.
image_copy = np.copy(image.numpy_view())
annotated_image = visualize(image_copy, detection_result)
rgb_annotated_image = cv2.cvtColor(annotated_image, cv2.COLOR_BGR2RGB)
cv2_imshow(rgb_annotated_image)import cv2
import numpy as np
MARGIN = 10 # pixels
ROW_SIZE = 10 # pixels
FONT_SIZE = 1
FONT_THICKNESS = 1
TEXT_COLOR = (255, 0, 0) # red
def visualize(
image,
detection_result
) -> np.ndarray:
"""Draws bounding boxes on the input image and return it.
Args:
image: The input RGB image.
detection_result: The list of all "Detection" entities to be visualize.
Returns:
Image with bounding boxes.
"""
for detection in detection_result.detections:
# Draw bounding_box
bbox = detection.bounding_box
start_point = bbox.origin_x, bbox.origin_y
end_point = bbox.origin_x + bbox.width, bbox.origin_y + bbox.height
cv2.rectangle(image, start_point, end_point, TEXT_COLOR, 3)
# Draw label and score
category = detection.categories[0]
category_name = category.category_name
probability = round(category.score, 2)
result_text = category_name + ' (' + str(probability) + ')'
text_location = (MARGIN + bbox.origin_x,
MARGIN + ROW_SIZE + bbox.origin_y)
cv2.putText(image, result_text, text_location, cv2.FONT_HERSHEY_PLAIN,
FONT_SIZE, TEXT_COLOR, FONT_THICKNESS)
return image