이전 포스팅에서 다뤘던 DBinsert 3가지 방법 중에 마지막 방법인 LOAD DATA INFILE을 실습해 보려고 한다.
위 방식에서는 csv나 txt 같은 텍스트 기반 파일로 데이터를 로드 할 수 있지만 Binary 기반의 파일도 사용이 가능하다. 두 가지 파일 형식을 사용했을 때의 차이점을 먼저 알아보자.
텍스트 기반
텍스트 기반 파일은 사람이 읽기 쉽기 때문에 디버깅이나 테스트에 용이하고 Excel, Python 등 다양한 툴과 연동이 쉽다.
하지만 문자열을 숫자로 변환하는 등의 파싱 오버헤드가 있을 수 있고 텍스트 예외 처리(줄바꿈, 따옴표, 콤마 등)에 비용이 든다는 단점이 있다. 또한 대용량 데이터에서는 CPU 부하가 커질 수 있다.
운영 환경이 단순하거나 수동 관리가 잦은 경우 등 사람이 직접 파일을 확인/조작해야 하는 경우라면 텍스트 기반 DATA LOAD INFILE을 사용하는 것이 좋다.
Binary 형식
Binary 형식을 이용하면 데이터 변환이 필요 없기 때문에 파싱 비용도 들지 않고 속도가 빠르다. 또한 텍스트보다 크기가 작기 때문에 네트워크 전송 효율이 높다는 장점이 있다.
하지만 사람이 읽을 수 있는 형식이 아니고 포맷 오류 발생 시 전체 로딩 실패 가능성이 있다.
실시간 로깅 등 고속 처리가 필요하거나 대규모 데이터 적재가 필요한 상황에 사용할 수 있다.
Binary 파일에서는 csv처럼 눈에 보이는 구분자 대신 구조적으로 데이터를 구분한다. 데이터를 구분하는 방법에는 3가지가 있다.
- 고정 길이 포맷
각 필드가 정해진 바이트 수만큼만 차지 한다. 예를 들어 이름은 10바이트, 나이는 4바이트 등으로 설정할 수 있다. - 프리픽스 기반 포맷
각 필드 앞에 길이 정보를 추가한다. 예를 들어2바이트 길이 + N바이트 값으로 설정할 수 있다. - 구조체 연속
struct.pack또는 C 구조체를 그대로 메모리 덤프한 형식이다. 정해식 방식으로 데이터를 바이너리 형태로 메모리에 정렬한 후 그대로 파일을 저장하는 방법이다.
실습
LOAD DATA INFILE users.csv
도커로 띄운 MySQL에 LOAD DATA INFILE로 csv파일을 업로드해보자.
방법은 간단하다. 도커로 MySQL을 실행한다. MySQL에 테이블을 만들고 데이터 구조를 정의한 뒤 만들어 놓은 csv 파일을 업로드 하면된다.
MySQL 컨테이너 실행
$ docker run --name mysql-lab -e MYSQL_ROOT_PASSWORD=root \
-e MYSQL_DATABASE=testdb \
-p 3306:3306 \
-v $(pwd)/mysql-data:/var/lib/mysql \
-v $(pwd)/mysql-files:/var/lib/mysql-files \
-d mysql:8.0 --secure-file-priv=/var/lib/mysql-filesMySQL 접속
$ docker exec -it mysql-lab mysql -u root -p
# 비밀번호: root테이블 생성
USE testdb;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
age INT
);샘플 데이터 파일 만들기(csv)
import random
import csv
first_names = ["Alice", "Bob", "Charlie", "David", "Eve", "Frank", "Grace", "Hannah", "Ivy", "Jack"]
last_names = ["Smith", "Johnson", "Williams", "Brown", "Jones", "Miller", "Davis"]
def random_name():
return f"{random.choice(first_names)} {random.choice(last_names)}"
with open("mysql-files/large_users.csv", "w", newline='') as f:
writer = csv.writer(f)
for _ in range(1000):
name = random_name()
age = random.randint(18, 70)
writer.writerow([name, age])MySQL에 데이터 적재
LOAD DATA INFILE '/var/lib/mysql-files/large_users.csv'
INTO TABLE users
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
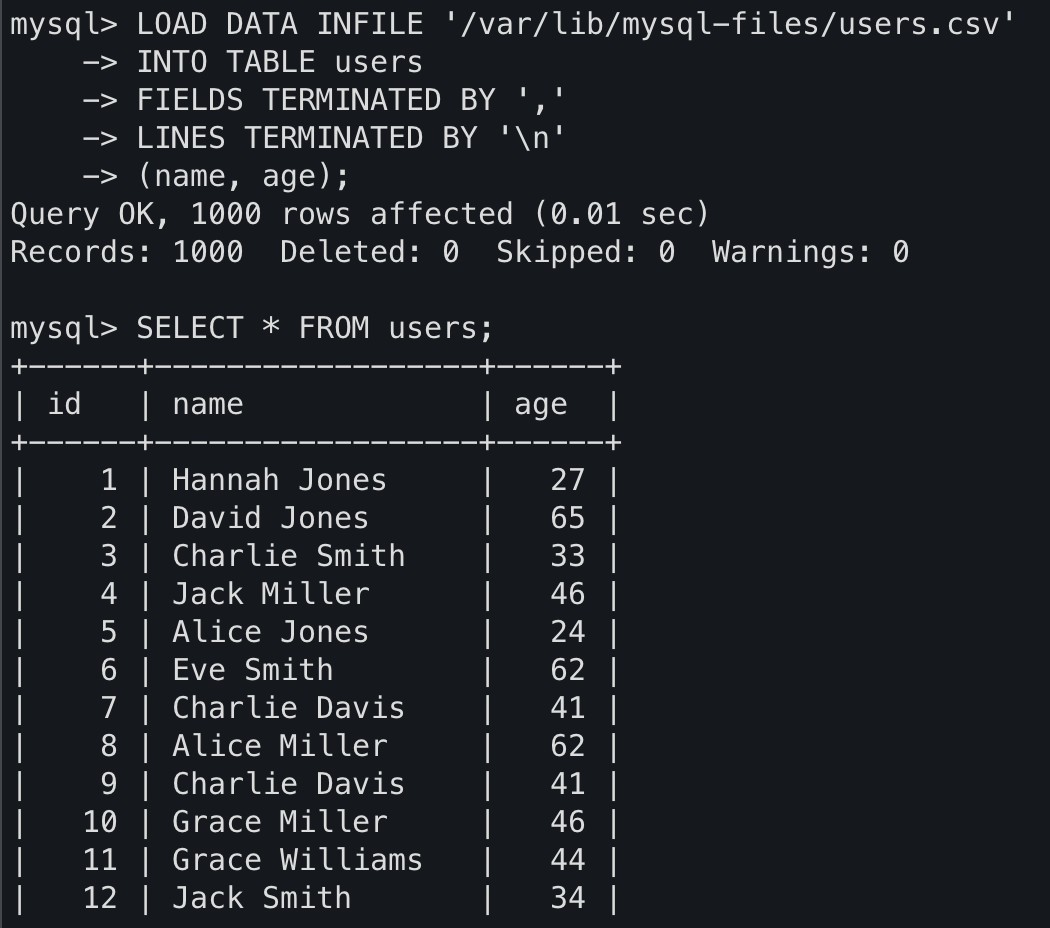
(name, age);샘플 데이터를 1000개로 만들어서 DB에 넣었는데 0.01sec의 아주 빠른 속도로 들어가 있는 것을 확인할 수 있다.
LOAD DATA INFILE users.dat
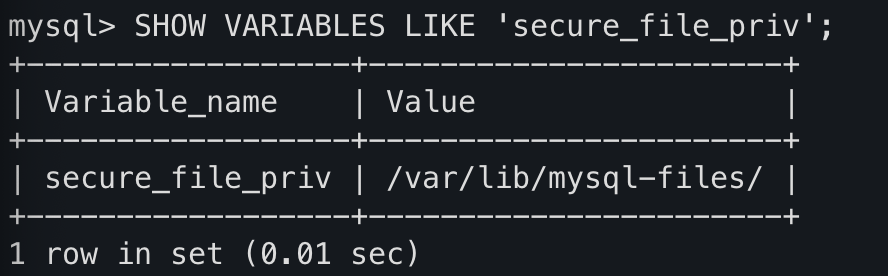
Binary 타입의 파일을 DB에 업로드 하기 전에 .dat 파일이 접근 가능한지 먼저 확인해봐야 한다. 컨테이너 접속 후 아래 명령어를 입력하고 이미지와 같은 결과가 나오면 해당 경로에만 파일이 접근 가능하도록 설정되어 있다는 뜻이다.
테스트를 위해 b_users라는 테이블을 먼저 만들고 샘플 데이터를 .dat 형식으로 만든다. 이번에는 파이썬 파일로 MySQL에 직접 연결하여 executemany를 사용하여 Bulk insert로 데이터를 업로드한다.
샘플 데이터 만들기(dat)
import struct
import struct
import random
import os
names = [b"Alice", b"Bob", b"Charlie", b"David", b"Eve"]
os.makedirs("mysql-files", exist_ok=True)
with open("mysql-files/users_bin.dat", "wb") as f:
for _ in range(1000):
name = random.choice(names).ljust(10, b'\x00')
age = random.randint(18, 70)
f.write(struct.pack("10sI", name, age))struct: Python에서 Binary 데이터를 다룰 때 사용하는 모듈이다. 여기서는 데이터를 고정된 포맷으로 패킹하여 바이너리 파일로 저장하는데 사용한다.ljust(10, b'\x00'): 선택된 일음을 10바이트로 맞추기 위해 뒤에\x00(널 바이트)를 채운다. 맨 마지막f.write부분에서 문자열 형식을 지정하기 때문에 그에 맞게 형식을 맞춰줘야 한다.struct.pack("10sI", name, age): 이름은 10바이트(10s)로 패킹되고 나이는 4바이트 정수(I)로 패킹된다. 여기서 name과 age가struct.pack()을 통해 바이너리 형식으로 변환된다.
바이너리 파일을 읽어서 Bulk insert로 MySQL에 데이터 적재
import struct
import mysql.connector
conn = mysql.connector.connect(
host="localhost",
user="mysql",
password="root",
database="testdb",
port=3306
)
cursor = conn.cursor()
with open("mysql-files/users_bin.dat", "rb") as f:
rows = []
while True:
chunk = f.read(16)
if not chunk:
print(f"Unexpected chunk size:{len(chunk)}")
break
name_b, age = struct.unpack("12sI", chunk)
name = name_b.decode("utf-8").strip("\x00")
rows.append((name, age))
cursor.executemany("INSERT INTO b_users (name, age) VALUES (%s, %s)", rows)
conn.commit()
cursor.close()
conn.close()f.read(16): 한 번에 16바이트씩 읽는다.name_bytes.decode("utf-8").strip("\x00"): 여기서 이름 데이터를 바이트 형식에서 문자열로 변환하고 뒤에 추가된 널바이트(\x00)을 제거한다.
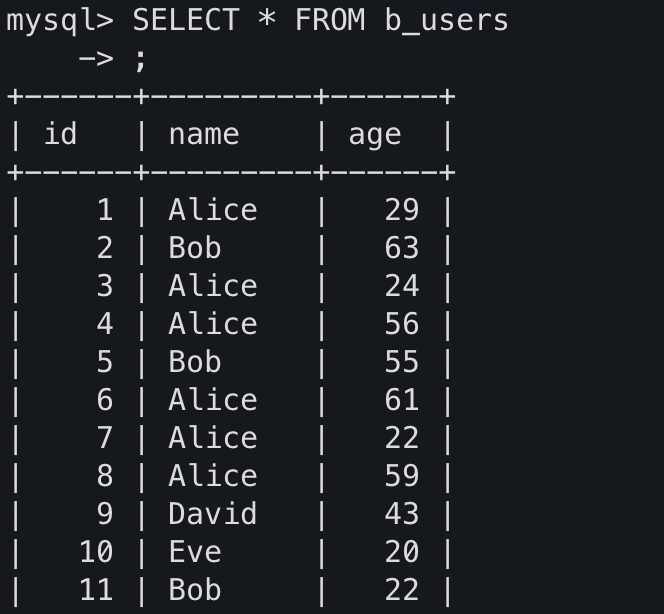
위의 파이썬 파일을 실행하면 DB에 데이터 적재가 잘 된것을 확인할 수 있다.
트러블 슈팅
MySQL 접근권한 문제
MySQL에서 해당 사용자에 대해 접근 권한이 없다는 오류가 났다.
File "/Users/jeongmieun/.pyenv/versions/note/lib/python3.11/site-packages/mysql/connector/connection_cext.py", line 360, in _open_connection
raise get_mysql_exception(
mysql.connector.errors.ProgrammingError: 1045 (28000): Access denied for user 'mysql'@'172.17.0.1' (using password: YES)당연했다. mysql을 사용자로 등록하지 않았기 때문이다. 아래 코드를 사용하여 사용자를 추가하고 docker IP로만 접근 가능하도록 수정했다.
CREATE USER 'mysql'@'172.17.0.1' IDENTIFIED BY 'root';
GRANT ALL PRIVILEGES ON *.* TO 'mysql'@'172.17.0.1';
FLUSH PRIVILEGES;데이터 크기 문제
처음에는 struct.unpack("10sI", chunk)으로 설정해서 DB에 데이터 삽입 테스트를 진행했는데 아래와 같은 오류가 발생했다.

그래서 샘플 데이터를 확인해봤더니 파일크기 16000이었다. 샘플 데이터를 생성할 때 struct.pack("10sI", name, age)로 데이터 타입을 규정해서 만들었으면 파일 크기가 14000이어야 맞는건데 아무리 찾아봐도 왜 이렇게 된건지는 모르겠다.

아무튼 테스트를 진행해야 하니 코드를 16바이트 기준으로 변경해서 다시 시도해보니 데이터 적재에 성공했다.
