SQL 튜닝으로 DB 성능 개선해야 하는 이유
DB 성능 저하의 원인은 크게 3가지가 있다.
- 동시 사용자 수의 증가
- 데이터 양의 증가
- 비효율적인 SQL문 작성
DB 성능을 개선하는 방법에도 여러가지가 있다.
- SQL 튜닝
- 캐싱 서버 활용 (Redis 등)
- 샤딩
- 스케일업 (CPU, Memory, SSD 등 하드웨어 업그레이드)
그럼, 많은 성능 개선 방법 중 SQL 튜닝을 먼저 고려해야 하는 이유는 뭘까?
- SQL 튜닝을 제외한 나머지 방법은 추가적으로 시스템을 구축해야 한다. 반면, SQL 튜닝은 기존의 시스템 변경 없이 성능 개선이 가능하다.
- SQL 자체가 비효율적으로 작성됐다면 시스템적으로 성능을 개선한다고 하더라도 한계가 있다.
성능 개선을 위해서는 MySQL 구조 파악이 필요하다. 전체 구조를 파악하여 어디서 성능이 저하되는지, 주된 원인이 무엇인지 파악할 수 있기 때문이다.
MySQL 구조
MySQL은 엔진 플러그인 구조이다. 따라서 SQL 레이어와 스토리지 레이어를 분리해서, 여러 종류의 스토리지 엔진을 사용할 수 있도록 설계되어 있다.
아키텍처를 보면 다음과 같다.
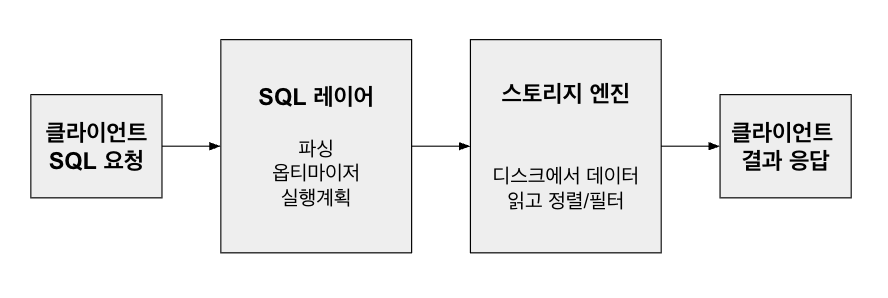
MYSQL 엔진 (SQL 레이어)
- 클라이언트가 SQL을 보내면, MYSQL 엔진이 이를 받아 처리한다.
파싱은 SQL 레이어에서 가장 먼저 수행되는 단계로 SQL 문장이 문법적으로 맞는지 검사하고, 논리적 구조(파스 트리)로 변환한다.옵티마이저는 비용 기반으로 실행계획을 세운다.
옵티마이저는 통계 정보(테이블의 row 수, 인덱스 selectivity 등)를 참고해서 실행 계획(Full Scan, Index Scan, Index Range Scan, Join 순서 등)을 세운다. 하지만 통계 정보가 부정확하거나, 복잡한 쿼리에서는 비효율적인 계획을 세우는 경우도 많다.
스토리지 엔진 (데이터 레이어)
- InnoDB와 같은 스토리지 엔진이 실제 데이터를 디스크에 읽고 쓰는 역할을 한다.
- 옵티마이저의 계획에 따라 데이터를 가져오고, 정렬 및 필터링 등 마지막 처리를 한 뒤 SQL 결과를 반환한다.
대표적인 스토리지 엔진:
InnoDB: 기본엔진, 트랜잭션, 외래키, ACID를 지원한다.MyISAM: 예전 기본 엔진, 빠르지만 트랜잭션 및 락을 지원하지 않는다.
SQL 튜닝의 핵심은 인덱스
MySQL 성능 문제의 대부분은 "스토리지 엔진에서 데이터를 느리게 가져오는 경우"에 발생한다.
- 테이블 전체를 읽거나 (Full Table Scan)
- 비효율적인 인덱스를 사용하거나
- 옵티마이저가 잘못된 실행 계획을 선택하는 경우
이런 병목을 줄이기 위해서는:
인덱스 생성: 자주 사용되는 조건 컬럼에 적절한 인덱스 설정커버링 인덱스: 쿼리 결과가 전부 인덱스에 있으면 디스크 접근 없이 처리 가능EXPLAIN/ANALYZE를 통한 실행 계획 분석 및 인덱스 활용 여부 확인
결국, 효율적인 인덱스 설계와 옵티마이저가 인덱스를 잘 쓰게 만드는 쿼리 작성이 SQL 튜닝의 핵심이다.
인덱스
인덱스(Index)
데이터를 빨리 찾기 위해 특정 컬럼을 기준으로 미리 정렬해 놓은 표라고 생각하면 편하다.
CREATE TABLE users(
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
age INT
);
SELECT * FROM users;
-- 높은 재귀 횟수를 허용하도록 설정
-- 더미데이터 개수와 맞춰서 작성하면
SET SESSION cte_max_recursion_depth = 1000000;
INSERT INTO users(name, age)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM cte WHERE n <1000000
) -- 생성하고 싶은 더미데이터 갯
SELECT
CONCAT('User', LPAD(n,7,'0')), -- 'User' 다음에 7자리 숫자로 구성된 이름 생성
FLOOR(1 + RAND() * 1000) AS age -- 1부터 1000 사이의 랜덤 값으로 나이 생성
FROM cte;
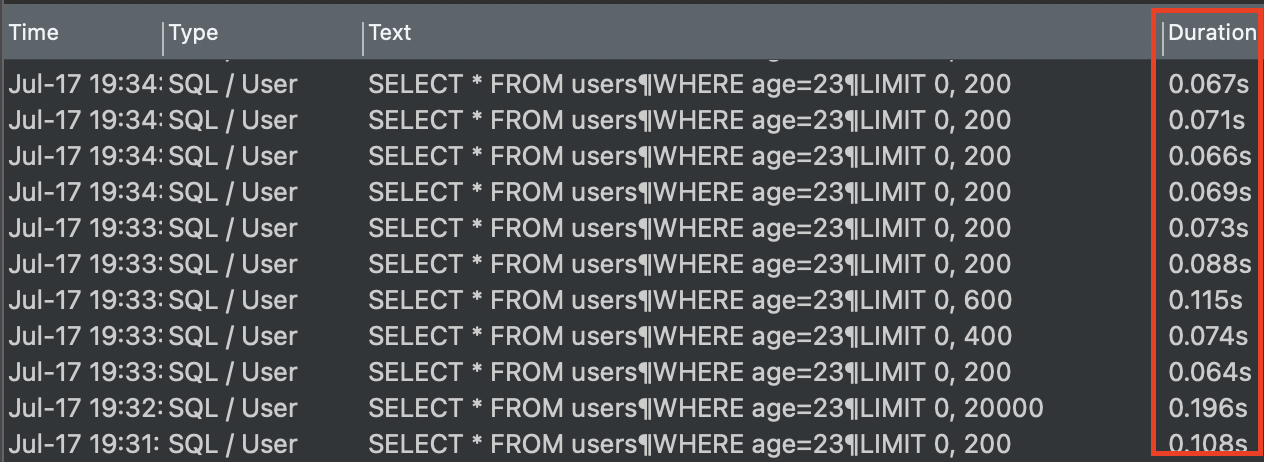
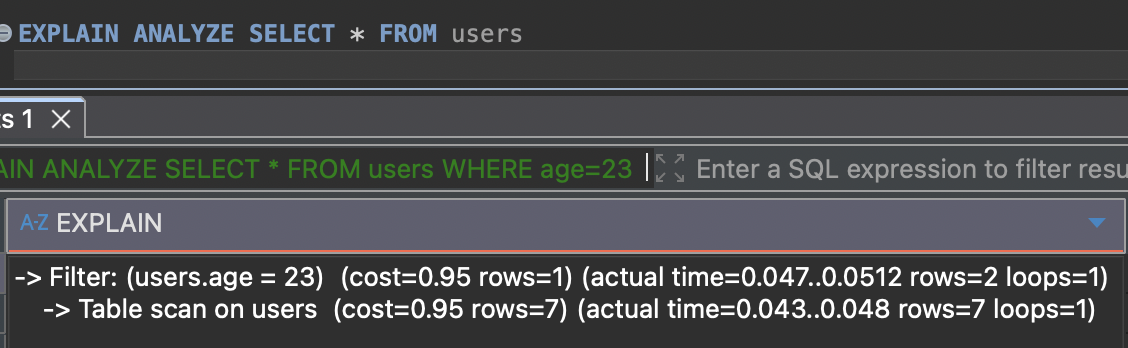
SELECT * FROM users
WHERE age=23;인덱스를 사용하기 전과 후의 쿼리 조회 시간의 변화를 통해 인덱스를 활용한 쿼리 성능 향상이 가능하다는 것을 알 수 있다.
CREATE INDEX idx_age ON users(age);
SHOW INDEX FROM users;
SELECT * FROM users
WHERE age=23;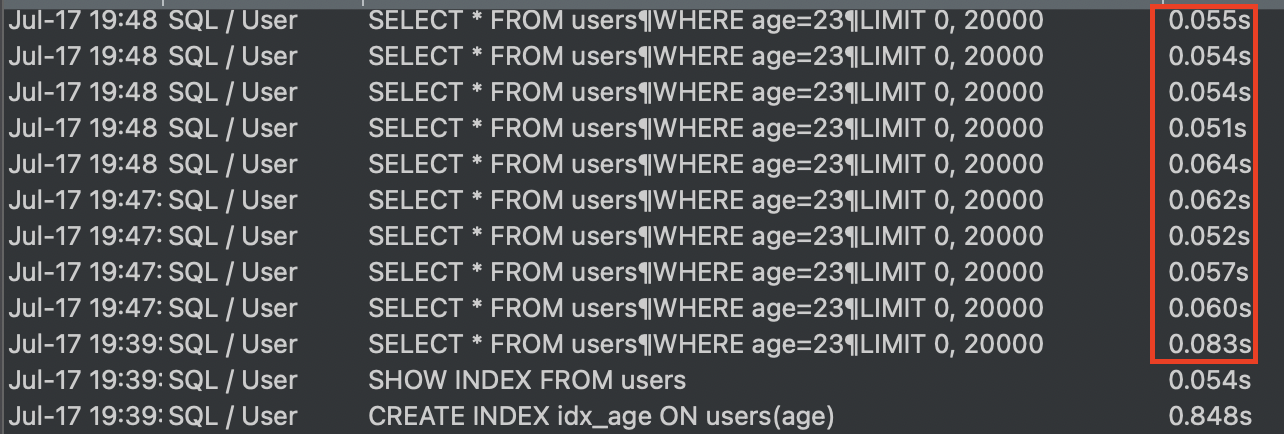
기본으로 설정되는 인덱스 (PK)
PK도 인덱싱의 한 종류이기 때문에 PK에는 인덱스가 기본적으로 적용된다. 클러스터링 인덱스라고도 부른다.
InnoDB 테이블은 반드시 하나의 클러스터형 인덱스를 가지며, PK가 없을 때는 UNIQUE NOT NULL 제약 조건이 붙은 인덱스 중 하나를 자동으로 선택한다.
그것도 없다면 내부적으로 숨겨진 rowid 컬럼을 생성해 클러스터 인덱스로 활용한다.
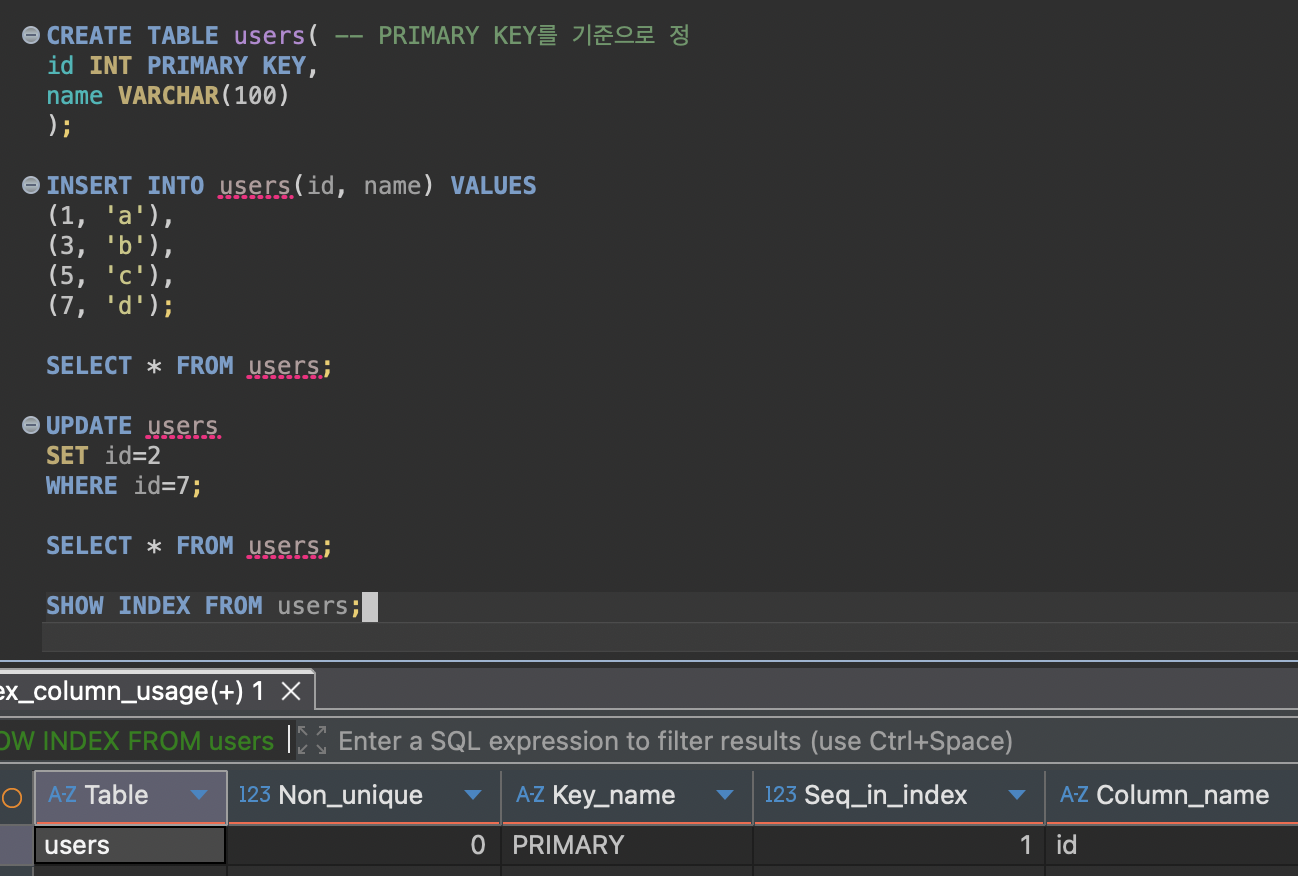
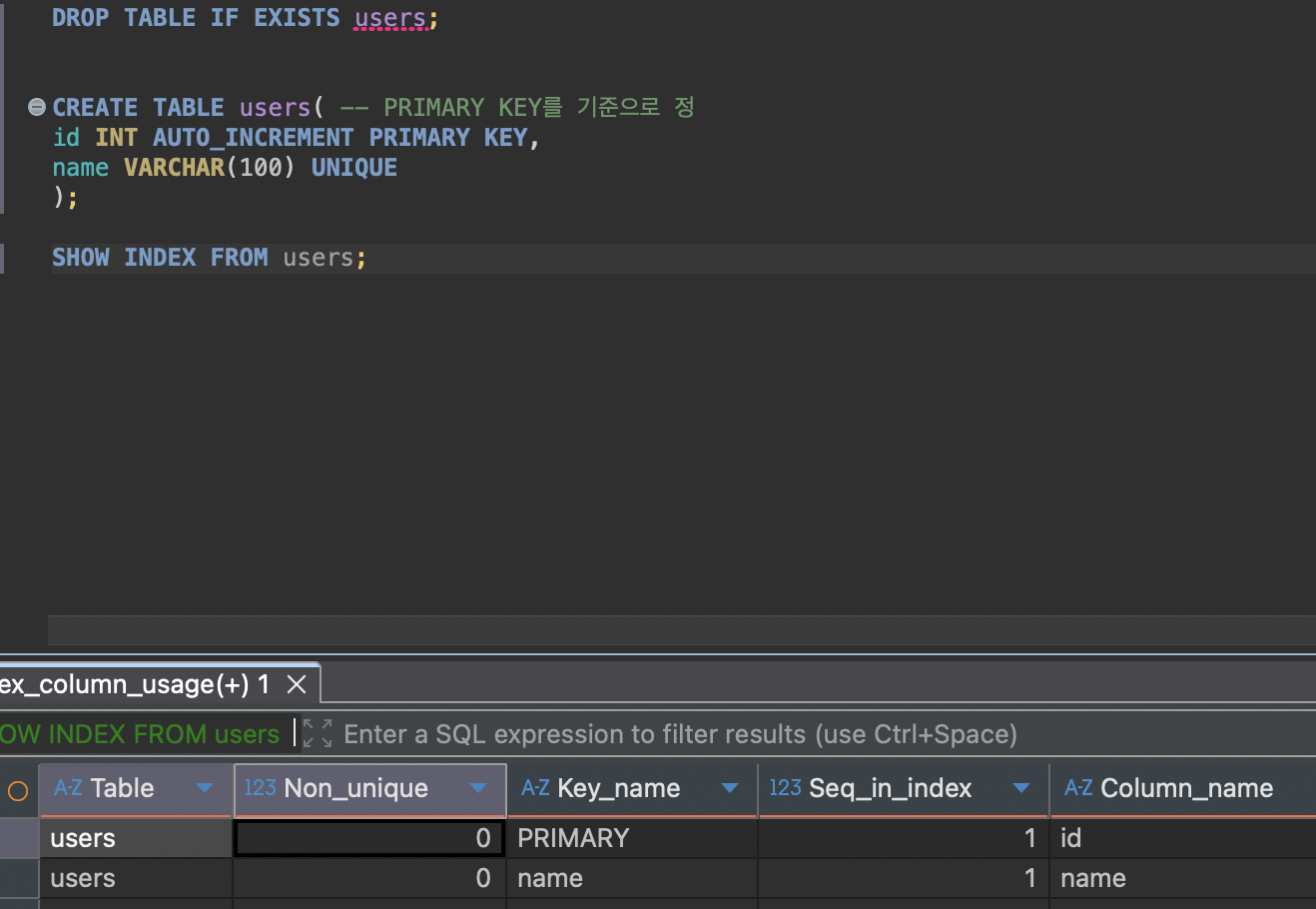
제약 조건을 추가하면 자동으로 생성되는 인덱스 (UNIQUE)
UNIQUE 옵션을 설정하면 인덱스가 자동으로 같이 생성되기 때문에 조회 성능 향상된다. 이런 특징 때문에 고유 인덱스(Unique Index)라고도 부른다.
멀티 컬럼 인덱스(Multiple-Column Index)
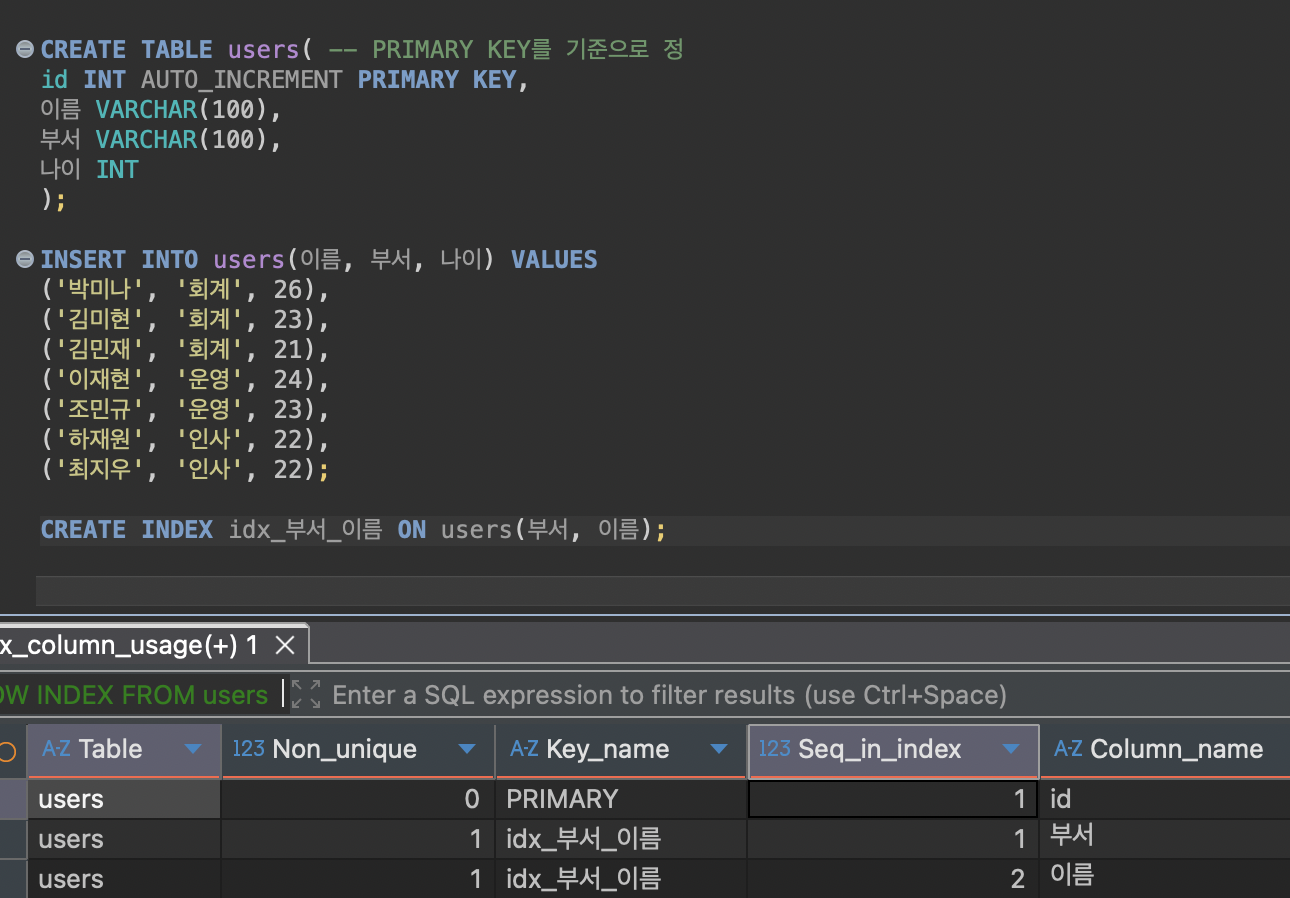
멀티 컬럼 인덱스란, 2개 이상의 컬럼을 묶어서 설정하는 인덱스를 뜻한다. 즉, 데이터를 빨리 찾기 위해 2개 이상의 컬럼을 기준으로 미리 정렬해놓은 표이다.
멀티 컬럼 인덱스 생성 시 주의사항
멀티 컬럼 인덱스의 특징을 이해하고 생성해야 효과적으로 사용할 수 있다.
- 멀티 컬럼 인덱스는 일반 인덱스처럼 활용할 수 있다.
- 멀티 컬럼 인덱스를 일반 인덱스처럼 활용하지 못하는 경우도 있다.
- 멀티 컬럼 인덱스를 구성할 때 순서를 주의해야 한다.
멀티 컬럼 인덱스에서도 배치한 컬럼의 순서대로 데이터를 탐색한다.(이름, 부서)의 순서대로 멀티 컬럼 인덱스를 구성했다면 먼저 일치하는이름을 찾은 뒤, 일치하는이름에서부서를 찾는 식으로 처리한다.
따라서 멀티 컬럼 인덱스를 구성할 때는 데이터 중복도가 낮은(카디널리티가 높은) 컬럼이 앞쪽으로 오는 게 좋은 경우가 많다.
(항상 그런 건 아니니 실행 계획과 SQL문 실행 속도를 측정해서 판단하도록 하자.)
커버링 인덱스(Covering Index)
SQL문을 실행시킬 때 필요한 모든 컬럼을 갖고 있는 인덱스를 커버링 인덱스(Covering Index)라고 한다.
인덱스의 무분별한 사용
인덱스를 사용하면 데이터를 조회할 때의 성능이 향상된다. 하지만 무분별한 인덱스의 사용은 오히려 쓰기 작업(삽입, 수정, 삭제)의 성능을 저하시킬 수 있다.
인덱스를 추가한다는 건 인덱스용 테이블이 추가적으로 생성된다는 뜻이다. 따라서 쓰기 작업을 하게 되면 원장 테이블과 인덱스용 테이블 모두에 데이터를 넣어야 한다. 인덱스의 개수가 많아지면 많아질 수록 작업을 해야하는 테이블은 더 많아지기 때문에 성능은 더 느려질 수 밖에 없다.
인덱스가 사용되지 않는 경우
인덱스가 있는 컬럼이라도 해당 컬럼을 가공해서 조건에 사용하면 인덱스를 사용할 수 없고, 전체 스캔이 일어나 오히려 성능 저하를 유발할 수 있다.
변경 전 - 컬럼 가공
-- 인덱스가 있는 created_at 컬럼
CREATE INDEX idx_users_created_at ON users(created_at);
-- 인덱스가 사용되지 않는 경우
SELECT * FROM users
WHERE DATE(created_at) = '2025-07-22';변경 후 - 함수나 연산을 우변으로 이동하거나 범위 조건으로 바꿔야 함
-- 인덱스 사용 가능 (created_at에 가공 없음)
SELECT * FROM users
WHERE created_at >= '2025-07-22 00:00:00'
AND created_at < '2025-07-23 00:00:00';위에서 인덱스를 알아봤다. 대충 인덱스를 왜 사용해야 하고 인덱스를 사용했을때 성능이 좋아진다는 것을 시각적으로 확인할 수 있었다.
다음 포스팅에서는 실행 계획을 사용하여 쿼리 성능을 향상하는 방법을 알아보자.
