오늘의 회고
ML
영화 추천 모델을 구축하려고 하는데 어떤 프레임워크를 사용하는게 프로젝트에 더 도움이 될지 찾아봤다.
Spark MLlib
Spark MLlib은 Spark 위에서 돌아가는 머신러닝 라이브러리이다. 전통적인 머신러닝 알고리즘(선형 회귀, 로지스틱 회귀, 트리 기반 모델 등)을 대규모 데이터셋에 대해 분산 처리를 할 수 있게 도와준다. 로그 데이터 분석, 대규모 추천 시스템이나 데이터 전처리와 머신러닝을 한번에 하고 싶은 경우에 적합하다.
PyTorch
PyTorch는 딥러닝을 위한 프레임워크이다. TensorFlow 보다 코드가 직관적이고 유연하다. 연구 중심 모델 설계나 GPU 가속이 필요한 복잡한 연산이 필요한 경우에 적합하다.
TensorFlow
TensorFlow는 딥러닝과 고급 수학 연산을 위해 만들어진 오픈소스 프레임워크이다. 기본적으로 신경망 모델을 설계하고 학습하는 데 최적화 되어있다. 딥러닝 모델을 빠르게 만들고 학습할 수 있다는 장점이 있다. 따라서 자연어 처리나 모델 서빙, 모바일 배포등에 적합하다.
LightGBM
LightGBM은 Microsoft에서 만든 트리 기반의 부스팅 알고리즘이다. 이탈자 예측, 클릭률 예측, 광고 타켓팅, 추천 시스템 등에 많이 사용된다.
이번 프로젝트에서는 영화 추천 모델과 이탈자 예측 모델을 함께 구축할 계획이지만, 딥러닝이나 모델 고도화보다는 데이터 파이프라인 자동화에 관련된 디테일이나 운영 안정성을 더 중요하게 다루는 프로그램이므로 ML관련 해서 너무 깊이 들어갈 필요는 없는 것 같다.
영화 추천 모델은 사용자 행동과 별점 등 콘텐츠 정보를 함께 고려할 수 있는 LightFM으로 구현할 예정이고 이탈자 예측 모델은 아직 구체적으로 결정된 것이 없다. 하지만 이탈자 예측에 많이 사용되는 LightGBM의 사용을 고려해 보는 것도 좋을 것 같다.
프로젝트
오전에 백엔드 코드 브리핑(?)을 짧게 듣고 이를 바탕으로 Java에 대해 이해하는 시간을 가졌다. 연휴에 Java에 대해 알아보긴 했는데 역시나 쉽지 않다.
내일부터는 서비스별로 역할을 나눠서 코딩을 진행할 것 같다. 이제부터는 더 바빠지겠지... 즐거웠다 연휴... 🫠🫠
데이터 파이프라인 아키텍쳐
파이프라인을 어떻게 설계하는게 좋을까, 어떤 스택을 사용하면 좋을까 고민이 많아서 이것저것 찾아보다가 오늘 데이터 파이프라인 아키텍쳐를 완성했다.
이번 프로젝트에서는 비정형 로그 데이터 수집부터 모델 학습 및 서비스 적용, 시각화까지 하나의 파이프라인으로 자동화하기 위해 아키텍쳐를 설계했다.
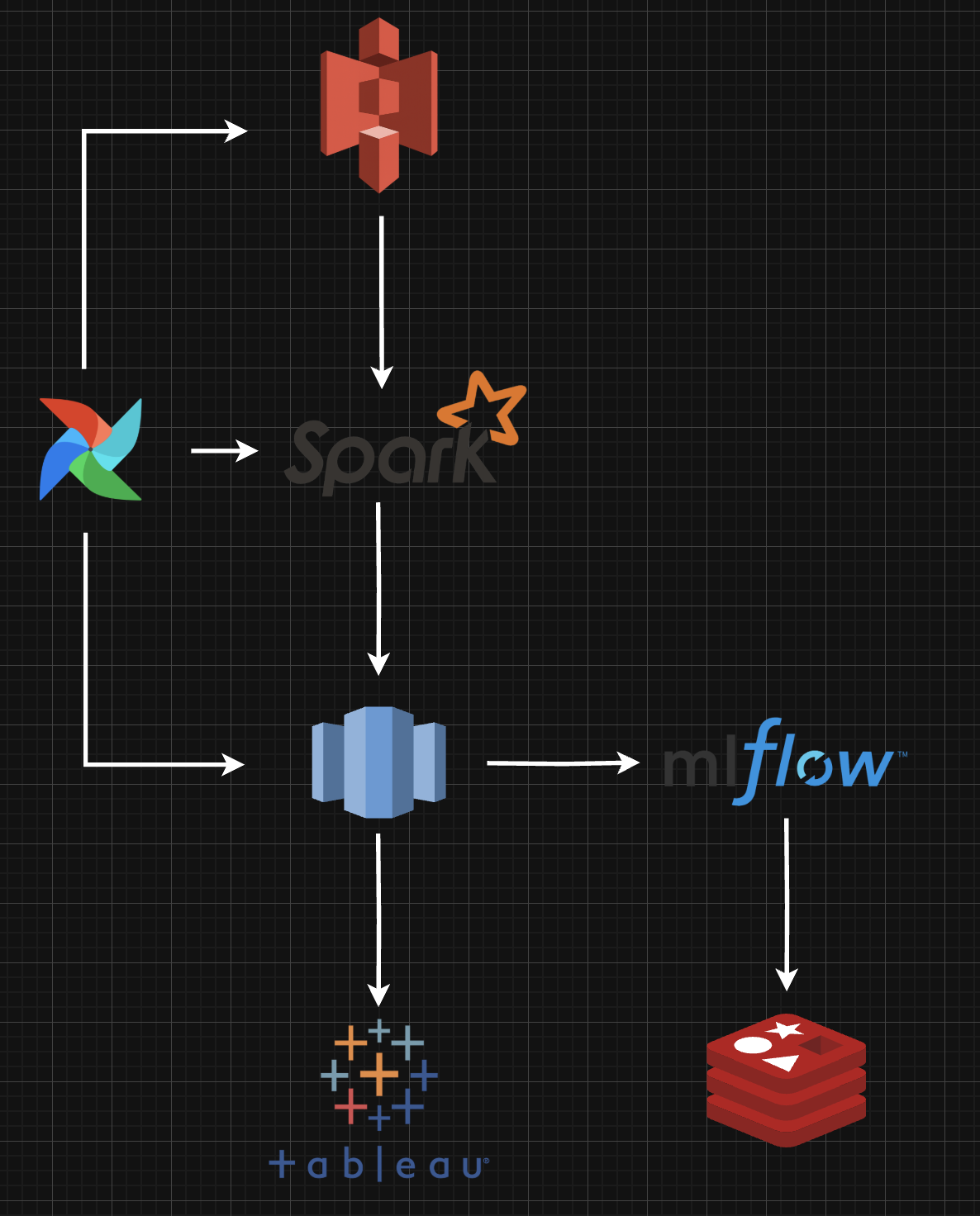
왜 이렇게 설계했을까
S3
S3는 비정형 데이터 저장에 적합하고 수백 GB에서 PB까지 자동으로 확장될 만큼 확장성이 높지만 비용은 적게 든다. 또한 Spark나 MLflow, Redshift 사용도 고려하고 있었기 때문에 연동이 용이하다는 점에서 로그 저장소로 S3를 선택했다.
Spark
S3에 저장된 raw log data는 Spark를 통해 전처리한다. Spark는 분산 처리 기반으로 대규모 로그도 안정적으로 처리가 가능하고 단순 SQL로는 힘든 대규모 데이터 전처리에 최적화되어 있다.
Redshift
Spark에서 처리한 데이터는 Redshift에 저장한다. 여기서 모델 학습, 추론 결과 저장, 시각화 등 다양한 작업의 중심이 된다.또한 Tableau나 MLflow 등과의 연동성이 좋기 때문에 Redshift를 데이터 레이크로 사용하려고 한 이유도 있다.
Airflow
전체 흐름은 Airflow로 자동화를 할 예정이다. 데이터 수집, 전처리, 저장 등 각 단계를 DAG로 정의하여 안정적이고 반복 가능한 배치 처리 환경을 구성한다.
MLflow
Redshift에 저장된 데이터를 기반으로 모델 학습을 수행하며, 이 과정에서 MLflow를 통해 성능, 버전 등을 관리할 생각이다.
Redis
Redshift는 추론 결과를 실시간으로 제공하는데 한계가 있어서 추론 결과는 Redis에 캐싱할 예정이다.
Tableau
최종적으로 Redshift에 저장된 데이터를 기반으로 Tableau를 통해 사용자 행동 분석, 추론 결과 비교 등의 시각화 대시보드를 구축할 예정이다.
페이지2에서 변경될 수도 있긴 하지만 일단은 어떤식으로 진행될지 머릿속에 그려놔야 설계가 변경되도 적응이 빠를 것 같다.
일단 Java로 서비스 구현 레츠고
