구름 클라우드 엔지니어링
1.[GoormPlay] 프로젝트 시작 전 알아두어야 하는 용어 정리

클라우드 엔지니어링 프로젝트 과정을 시작했다.오늘은 그 첫째날인 OT였다. 이전 기수는 판교에서 진행했다고 하던데... 이번 기수는 역삼에서 진행한다고 한다. 새롭게 단장한 사무실이라서 깨끗하고 정말 좋았다. 더 좋았던 점은 매니저님과 커리어 매니저님, 그리고 담당 강
2.[groom] 클라우드 엔지니어링 프로젝트 과정 2회차 - DAY 2

MSA의 개념, 도메인 분할 기준에 대해 배웠다. 개념적으로는 용어가 이해가 되는데 프로젝트 기획 단계에서 MSA를 적용하려고 하니 기능을 어떻게 분리해야할지 아직은 감이 잘 오지 않는다. 협업 도구로는 JIRA를 사용하게 되었는데 처음 사용해본다. 이번 기회에 JIR
3.[groom] 클라우드 엔지니어링 프로젝트 과정 2회차 - DAY 3
API에 ElasticSearch를 붙이기로 했다. ElasticSearch는 백엔드에서 관리하겠지만 데이터엔지니어 직무 역량으로도 ElasticSearch 사용 능력이 필요하다는 공고를 꽤 봤던 것 같다. 데이터 엔지니어는 Elasticsearch를 통해 효율적인 데
4.[groom] 클라우드 엔지니어링 프로젝트 과정 2회차 - DAY 4
사실 HDD와 SSD의 차이점에 대해 대략적으로 알고 있기는 했지만, 오늘 좀 더 실무적인 관점에서 그 차이를 이해해야 하는 이유에 대해 알게 된 것 같다. 영화 추천 사이트에 광고 도메인을 붙이기로 했다. 광고에 관련된 로그를 Google Analytics로 쌓고,
5.[groom] 클라우드 엔지니어링 프로젝트 과정 2회차 - DAY 5
오늘의 회고 테스트 코드 테스트 코드의 중요성에 대해 들었다. 데이터 엔지니어링 과정 중에 API 만들때 pytest로 테스트 코드를 만들곤 했는데 그 당시에는 중요성을 알지 못했던 것 같다. 테스트 코드를 만들어야 하는 이유는 테스트 코드 없이 기능만 가지고 테스
6.[groom] 클라우드 엔지니어링 프로젝트 과정 2회차 - DAY 6
오늘의 회고
7.[groom] 클라우드 엔지니어링 프로젝트 과정 2회차 - DAY 8
오늘의 회고
8.[groom] 클라우드 엔지니어링 프로젝트 과정 2회차 - DAY 7
Redis 캐시로 몰려드는 트래픽을 견디다 — 토니모리 공식몰 성능 개선기토니모리 사례를 통해 시스템의 병목을 정확히 파악하고 캐시를 전략적으로 도입함으로써 성능과 안정성을 근본적으로 개선할 수 있다는 것을 배웠다. 데이터 분야에서도 마찬가지로 어떤 데이터가 자주, 반
9.[goorm] 클라우드 엔지니어링 프로젝트 과정 2회차 - DAY 9
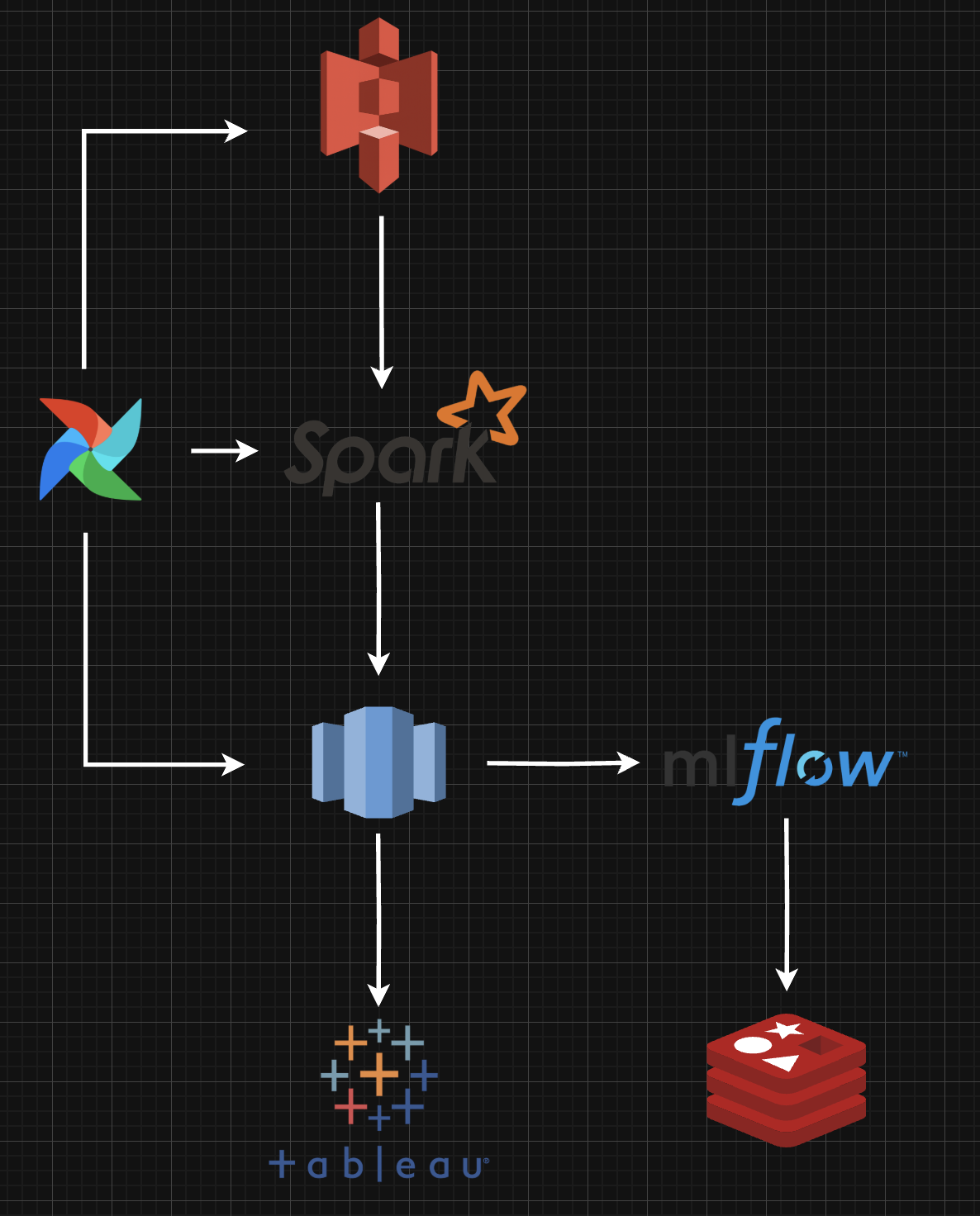
영화 추천 모델을 구축하려고 하는데 어떤 프레임워크를 사용하는게 프로젝트에 더 도움이 될지 찾아봤다. Spark MLlib은 Spark 위에서 돌아가는 머신러닝 라이브러리이다. 전통적인 머신러닝 알고리즘(선형 회귀, 로지스틱 회귀, 트리 기반 모델 등)을 대규모 데이터
10.[goorm] 클라우드 엔지니어링 프로젝트 과정 2회차 - DAY 10
DB Insert에는 3가지 방법이 있다. 이전 프로젝트에서 전처리된 데이터를 mongoDB에 적재하는게 정말 오래 걸렸는데 이번 프로젝트에서는 대용량 데이터의 적재 성능을 고려하여 Insert 전략을 개선하고 배치 기반 처리 또는 파일 기반 대량 삽입을 통해 DB 성
11.[goorm] 클라우드 엔지니어링 프로젝트 과정 2회차 - DAY 11
웹 페이지에 접속하면 가장 먼저 보이게 되는 첫 페이지는 거의 모든 사용자가 보게 된다. 이런 페이지는 자연스럽게 트래픽이 집중되고, 서비스 성능과 비용 효율성에 있어서 중요한 설계 포인트가 될 수 있다.1페이지 캐싱이 필요한 이유를 이해하려면 먼저 캐시와 DB 통신
12.[goorm] 클라우드 엔지니어링 프로젝트 과정 2회차 - DAY 12
레퍼러 방식과 UTM 파라미터 방식을 비교해 보면, 레퍼러는 단순히 URL 정보로 유입 경로를 추적하는 반면, UTM은 세부적인 캠페인과 매체별로 유입 정보를 분류하고 분석할 수 있다. 특히, UTM 파라미터 방식은 고급 캠페인 성과 분석과 리타겟팅에 유리하다.레퍼러
13.[goorm] 클라우드 엔지니어링 프로젝트 과정 2회차 - DAY 13
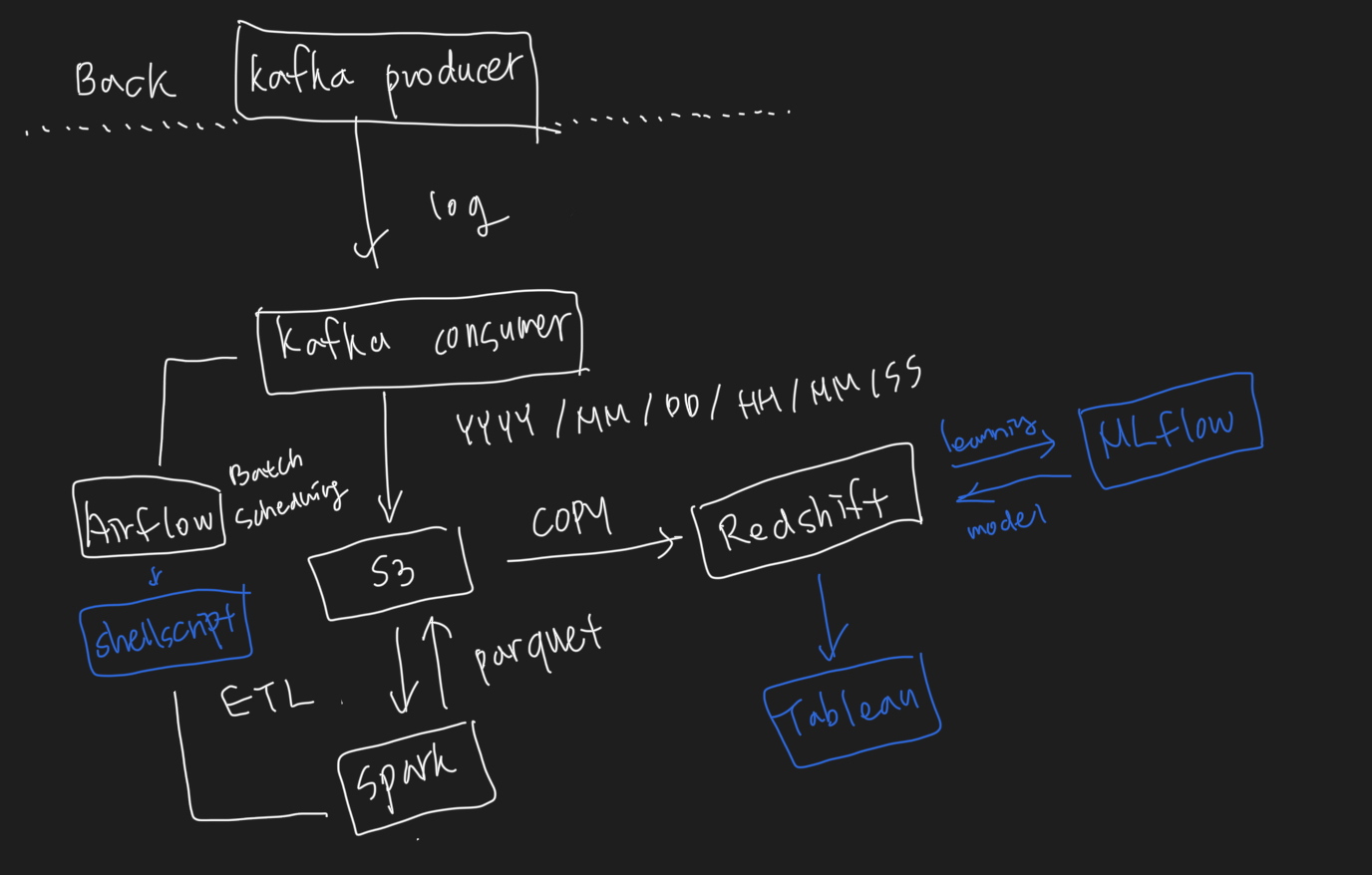
Firebase Studio를 오늘 처음 써봤는데 자연어 검색만으로 프론트를 그럴듯하게 만들어줘서 정말 놀랐다. 개인 프로젝트 진행할 때 프론트가 필요하더라도 Firebase Studio를 활용한다면 혼자서도 그럴듯한 프로젝트를 만들 수 있을 것 같다. 오늘 MinIO
14.[GoormPlay] EC2에 Minio, PostgreSQL, Kafka cluster 바이너리 설치 및 자동 실행 설정하기
EC2 인스턴스에서 MinIO, PostgreSQL, Kafka를 바이너리로 설치하고 systemd에 등록하여 인스턴스 재부팅 시 자동 실행되도록 설정한 과정을 정리했다. EC2 유저 데이터 스크립트로 자동화도 가능하지만, 테스트 결과 불안정한 부분이 있어 수동으로 설