
API 성능의 Bottleneck을 찾기 위한
삽질과정을 적어본 블로그 글입니다.
글을 쓰게 된 동기
저는 회사에서 일하는거 외 에도 아는분들과 함께 프로젝트를 진행하며 실제 배포를 하고 실사용자를 받고있습니다. 대충 MAU 50명? 정도 되는 서비스라 트래픽이 엄청 많은건 아니지만 실사용자들을 통해 생기는 문제들을 통해 많은걸 배우고 삽질 있습니다.
저는 팀에 DevOps개발자 로서 CI/CD, Infra, Monitoring, 등등을 맡아서 하고 있는데.... 그래서 제 블로그 글들이 다 그따구. 물론 백앤드 마이크로 서비스들 몇개 만들긴 합니다
최근에 Traefik 메트릭 대시보드를 보면서 조금 이상한 수치를 보았습니다...

어떤 endpoint에서 일어난 Delete인지는 모르겠지만 평균 2.45s와 최대 2.45s라는 말도 안되는 수치가 찍혀있는겁니다. 물론 Post 792ms도 정상은 아닙니다만...
그래서 이게 오류인지 아니면 진짜로 특정 엔드포인트에서 저런 말도 안되는 수치가 일어나는건지 확인을 해봐야하는데 확인할 방법이 없는겁니다. (응?)

저희 메인 Backend API Server (MSA 비스무리 하게 운영중이라 그 외 다른 api server들도 있긴 합니다) 는 Nest.js로 만들었는데 이 서비스에 엔드포인트 관련 duration time을 프로메테우스 메트릭으로 제공을 하지 않고 있었습니다. (울 백앤드 분들 일하세요!)
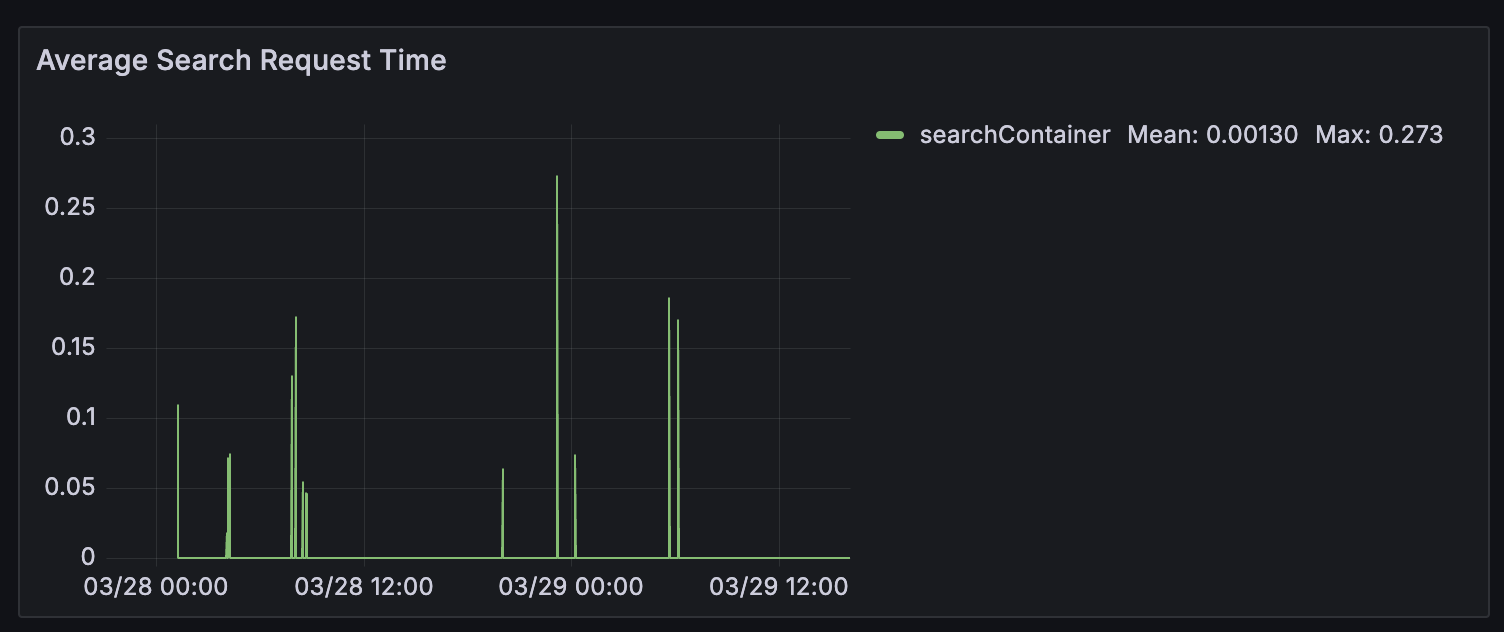
제가 만든 서치 엔진 API는 엔드포인트별 시간 메트릭 다 설정 해놨는데
뭐 하여튼 그렇다 보니 이참에 이 부분도 해결하고 DB 트랜잭션 시간이 얼마나 걸리는지 확인 하기 위해 Tracing을 도입하기로 했습니다.
Tracing? 트레이싱?
트레이싱을 처음 들어보는 분들도 있을겁니다.
트레이싱은 MSA가 유행을 하면서 같이 부상한 모니터링 방식입니다. 예전처럼 백앤드 서버가 한 개 였던 시절에는 병목 현상이 어디서 일어나는지 테스트를 하기도 편했고 모니터링 하기 쉬운 편이었습니다.
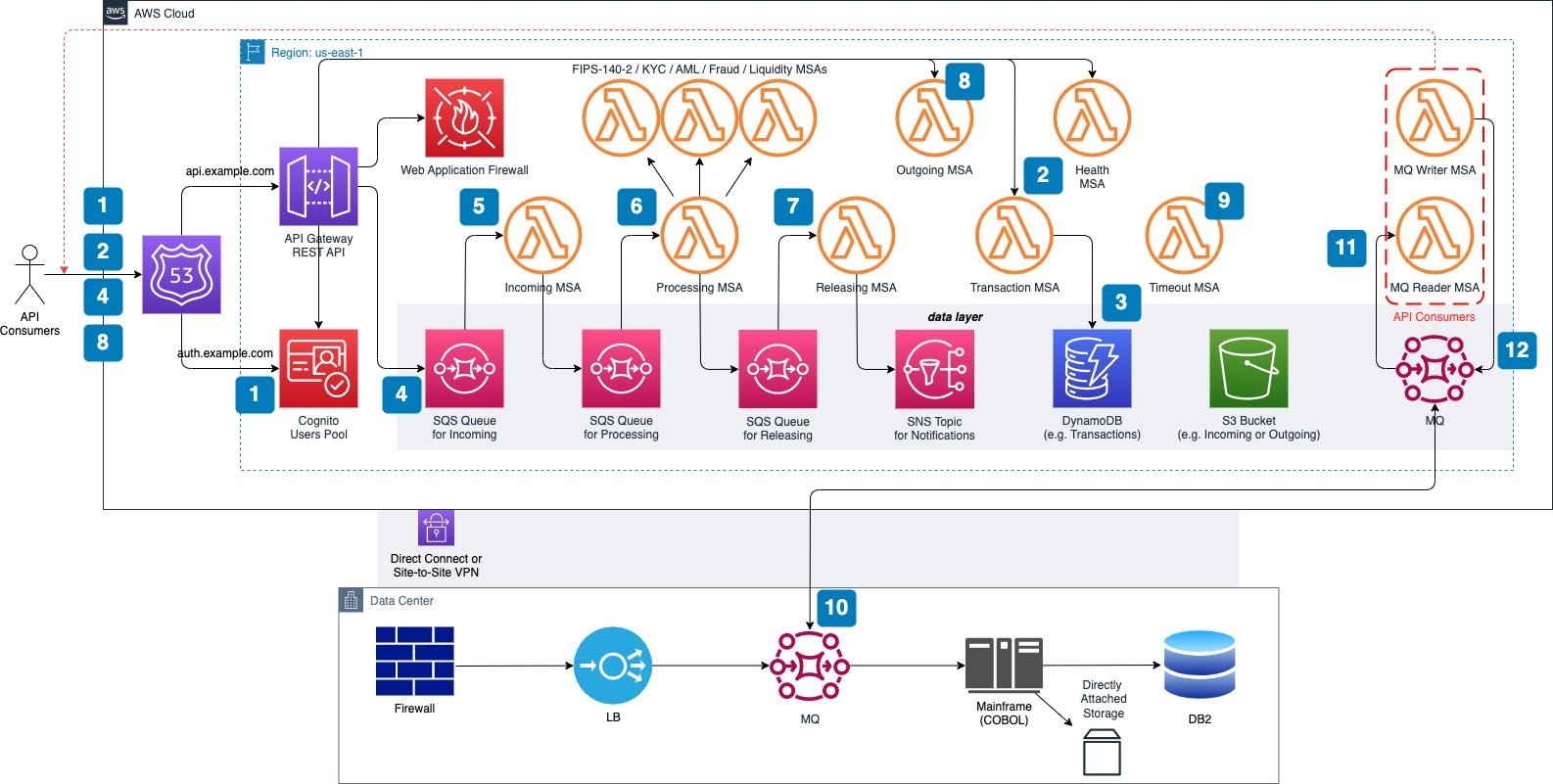
하지만 점점 Microservice Architecture, 그것도 Event Driven Architecture를 같이 사용하면서 수많은 서비스들이 kafka, sqs, rabbitmq, redis 등을 거치면서 일로갔다 저리로 갔다 하면 정확히 메시지가 어디에 있는지 모니터링 하기도 어렵고 정확히 어디서 병목현상이 일어나는지 확인 하기 어려운 세상이 됐습니다.

그래서 이걸 해결하려고 나온게 Tracing, 그 중 Distributed System Tracing(분산 시스템 트레이싱) 입니다.
트레이싱은 APM (Application Performace Monitoring)툴들을 사용해보셨으면 본적이 있을겁니다. Elastic APM, DataDog, Sentry, NewRelic등 APM을 사용해보시면 이런 페이지를 보신적 있을겁니다.
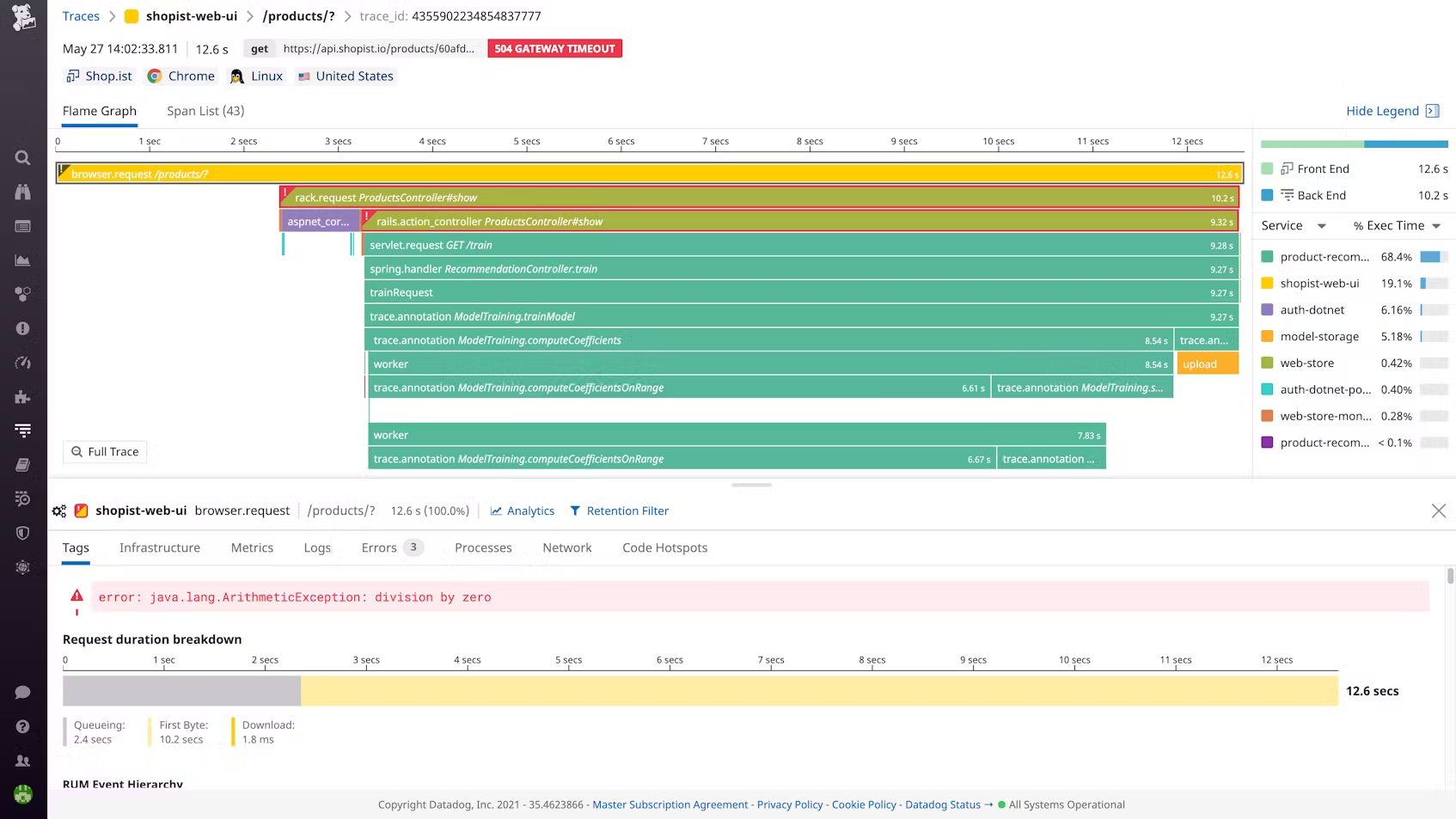
이렇게 트레이싱은 서비스 어디서 얼만큼 시간이 소요가 되고 트랜잭션을 처리 하기 위해 어디서 얼만큼 걸렸는지, 만약에 오류가 생겼으면 오류가 뭔지 를 트랙킹 해서 보여줍니다.
이런 대시보드가 있으면 병목현상이 어디서 일어났는지 쉽게 알수있겠죠?

사실 저희 서비스 프런트앤드에는 Sentry.io를 사용해 설정을 해뒀습니다. Sentry가 프리티어로 한개 까지는 괜찮더라구요.
그래서 비슷하게 하려다가... 사실상 표준이 되어가는 OpenTelemetry를 사용해 백앤드 Tracing을 구현 해보기로 했습니다!
OpenTelemetry

오픈텔레메트리(OpenTelemetry)는 트레이스, 메트릭, 로그 같은 텔레메트리 데이터를 생성하고 관리하도록 설계된 옵저버빌리티 프레임워크이자 툴 키트입니다. 출처
즉 오픈텔레메트리 (줄여서 Otel 오텔)는 데이터 모니터링 및 관측을 사용할때 사용하는 프레임워크가 아니고 데이터를 생성하거나 그 데이터를 관측할때 사용하는 서비스 (DataDog, Jaeger)등 한테 보내주는 역활을 합니다. 텔레메트리 데이터 파이프라인을 만들어준다고 생각하면 편할까요?
그러면 생기는 질문이 꼭 있습니다. Jaeger, DataDog, New Relic등을 사용하면 자체 SDK를 설치해서 데이터를 보내도 되는데 굳이 OpenTelemetry를 사용해야되나요?
OpenTelemetry를 사용하면 생기는 장점은 데이터를 가공할수도 있고 또한 DataDog, New Relic 등 SDK에 종속이 되지 않으면서 관리 할수 있게 도와줍니다.
만약에 DataDog을 사용하다가 다른 서비스로 옮기고 싶다고 가정을 해봅시다. 그러면 소스코드에서 SDK제거를 하는 등 많은 리팩토링이 필요하겠죠?
리팩토링을 결국 누가 하게 될까요?

하지만 OpenTelemetry를 사용하면 언제든지 다른 백앤드 서비스에서 사용할수 있고 심지어 여러 백앤드 서비스를 한번에 사용할수 있도록 해줍니다.
Jaeger

Jaeger (예거)는 트레이싱 데이터 수집 및 처리 백앤드 툴입니다. 분산 서비스 트랜잭션을 트레이싱 하는 오픈 소스 소프트웨어죠.
예거는 오픈텔레메트리 없이 자체적으로 사용을 할수도 있습니다. 자체 SDK를 대부분의 언어에서 제공을 하니까요. 하지만 오픈텔레메트리와 같이 사용을 해서 데이터 수집을 오픈텔레메트리에 맡기고 데이터 저장 및 조회를 예거한테 맡길수 있습니다.
다른 트레이싱 툴들, ZipKin, Tempo들 대비 좋냐고 하면 솔직히 저는 잘 모르겠습니다. 원래 이런 툴들은 자기가 좋아하는거 하나 골라서 사용하면 됩니다.
Jaeger는 기본적으로 인메모리 디비를 사용해서 트레이스 데이터를 저장합니다만... 이걸 프로덕션에서 사용하면 메모리 사용량 때문에 서버가 폭팔하겠죠?

그래서 다행이(?) 예거는 외부 데이터베이스를 사용할수 있게 해줍니다. 공식적으로 가능한 데이터베이스는 Cassandra와 ElasticSearch입니다만 (Cassandra 3.4+ and Elasticsearch 5.x/6.x/7.x) 카산드라와 일라스틱서치가 된다는 뜻은... 같은 API를 사용할수 있는 ScyllaDB, OpenSearch 등도 가능하다는거겠죠?

실제로 저는 ScyllaDB를 사용했습니다
실습
일단 제가 사용한 스택들은 아래와 같습니다.
- Traefik v3.0+
- ScyllaDB v6.0+
- Nest.JS Core v10.4.1+
- Prisma Client v6.5.0+
- Go v1.23+ (Otel v1.35+)
- jaeger-cassandra-schema v1.67.0+
- opentelemetry-collector-contrib v0.122.1
- jaegertracing/all-in-one v1.67.0
아키텍처를 보여드리자면 대충 이렇습니다.
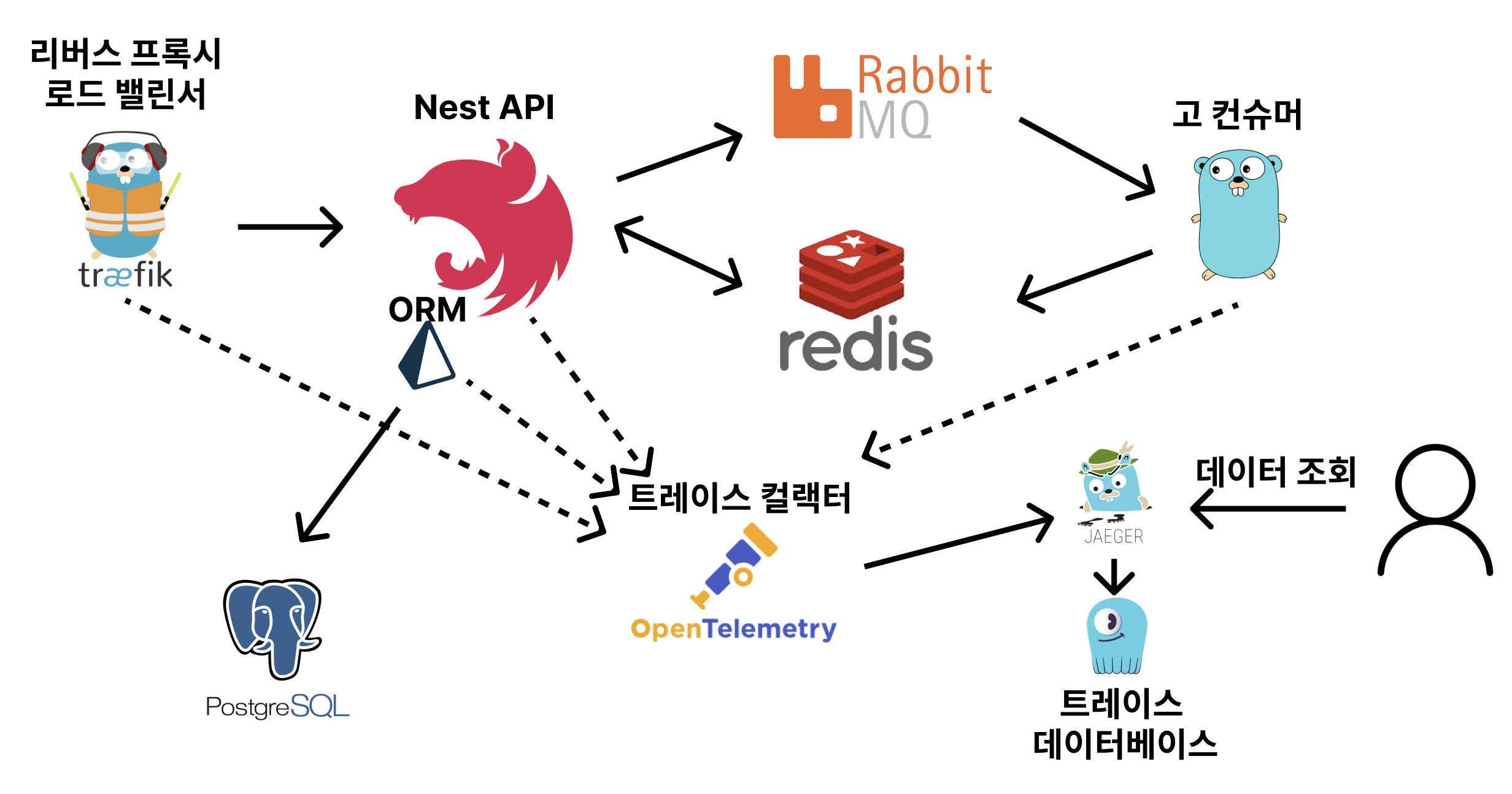
위 같이 아키텍처를 만들어서 사용을 해보니 아래와 같은 트레이싱 데이터가 잘 나오는걸 확인 했습니다.
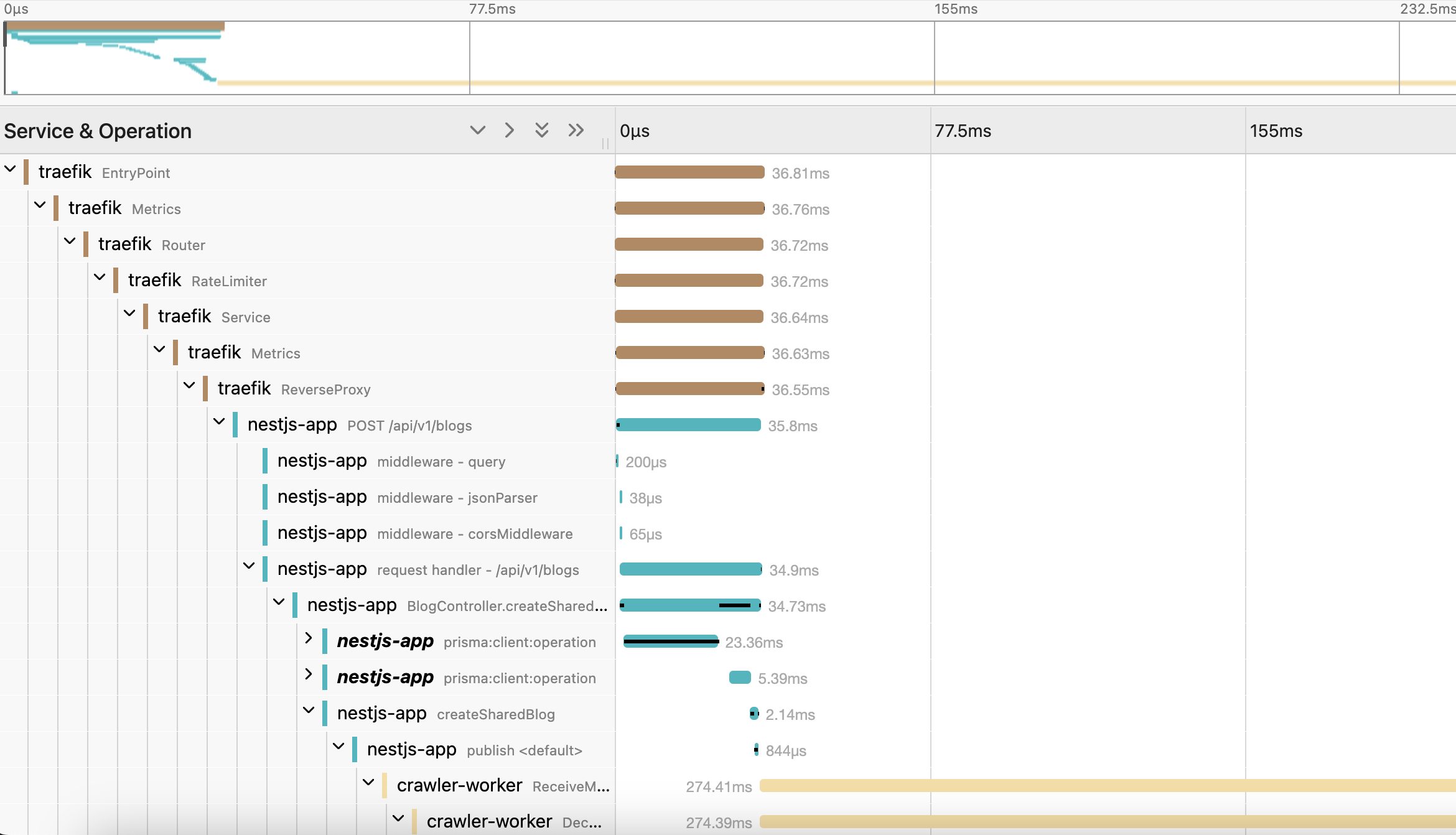
서비스/프레임워크 별 설정법은 추후 다른 블로그 글로
곧올라갈 예정입니다.
