VGG16 과 MFCC의 만남과 헤어짐
데이터 수집 부분에서 MFCC를 잠깐 소개한 적이 있다.
데이터 수집 챕터를 못 보셨거나 다시 일고 싶으시다면 아래 링크 클릭!
👉 데이터 수집(MFCC 설명 포함)
다시 간략하게 짚고 넘어가면 MFCC는 2d 형태인 데이터인데 Time Step마다 소리의 에너지(혹은 증폭)가 어떻게 변하는지 보여주는 오디오 Feature중에 하나이다.
우선 MFCC에 대해 처음 논의 됐을 때 2d 형태인 feature 였기 때문에 CNN으로 분류 task를 진행해 볼 수 있지 않을까 하는 의견들이 있었다. 그래서 이 가설로 VGG16으로 해보자고 합심하여 진행을 해보았다.
Sub-Chapter 1: 만남
처음에는 VGG16을 한 번 ‘image-net’ 으로 pretrained된 모델을 불러와서 진행해 보았다. 하지만 벌써 여기서부터 문제가 일어날 것을 이미 짐작이 될 것이라고 본다(하….).
첫 번째로 MFCC는 1 channel 데이터이기 때문에 3 channel 데이터를 입력 받는 ‘image-net’ pretrained VGG16 모델은 이미 첫 관문인 input에서 부터 MFCC와 헤어질 조짐이 보였다. 이렇게 짧은 시간 안에 헤어짐은 아쉬울 수 있기 때문에 우리 MFCC 친구를 위해 동료분께서 VGG16을 직접 구현하여 1 channel 데이터 input으로 맞춰주었다.
1 channel input VGG16 코드
train_X_mfcc[0].shape
>>> (20, 334, 1)
# 1 channel input VGG16
input_layer = tf.keras.layers.Input(shape=train_X_mfcc[0].shape)
x = tf.keras.layers.Conv2D(64,(3,3), strides=1, padding='same', activation='relu')(input_layer)
x=tf.keras.layers.Conv2D(64, (3, 3), strides=1, activation='relu', padding='same')(x)
x=tf.keras.layers.BatchNormalization()(x)
x=tf.keras.layers.MaxPool2D((2, 2))(x)
x=tf.keras.layers.Dropout(0.5)(x)
x=tf.keras.layers.Conv2D(128, (3, 3), strides=1, activation='relu', padding='same')(x)
x=tf.keras.layers.Conv2D(128, (3, 3), strides=1, activation='relu', padding='same')(x)
x=tf.keras.layers.BatchNormalization()(x)
x=tf.keras.layers.MaxPool2D((2, 2))(x)
x=tf.keras.layers.Conv2D(256, (3, 3), strides=1, activation='relu', padding='same')(x)
x=tf.keras.layers.Conv2D(256, (3, 3), strides=1, activation='relu', padding='same')(x)
x=tf.keras.layers.BatchNormalization()(x)
x=tf.keras.layers.MaxPool2D((2, 2))(x)
x=tf.keras.layers.Conv2D(512, (3, 3), strides=1, activation='relu', padding='same')(x)
x=tf.keras.layers.Conv2D(512, (3, 3), strides=1, activation='relu', padding='same')(x)
x=tf.keras.layers.BatchNormalization()(x)
x=tf.keras.layers.MaxPool2D((2, 2))(x)
x=tf.keras.layers.Dropout(0.5)(x)
x=tf.keras.layers.Flatten()(x)
x=tf.keras.layers.Dense(1024, activation='relu')(x)
x=tf.keras.layers.Dense(512, activation='relu')(x)
out_layer=tf.keras.layers.Dense(4, activation='softmax')(x)
model = tf.keras.Model(inputs=[input_layer], outputs=[out_layer])이러하여 결국 MFCC와 VGG16의 만남이 성사되길 기대하며 에폭을 돌려보는데…..
Sub-Chapter 2: 헤.어.짐
만약 모든 만물이 처음에 바로 완벽해진 다면 이거야 말로 우주 대사기극이 아닐까 싶다.
아니다 다를까 MFCC와 VGG16은 Train and Validation Loss 그리고 Accuracy 그래프에서 헤어질 조짐이 보였다.
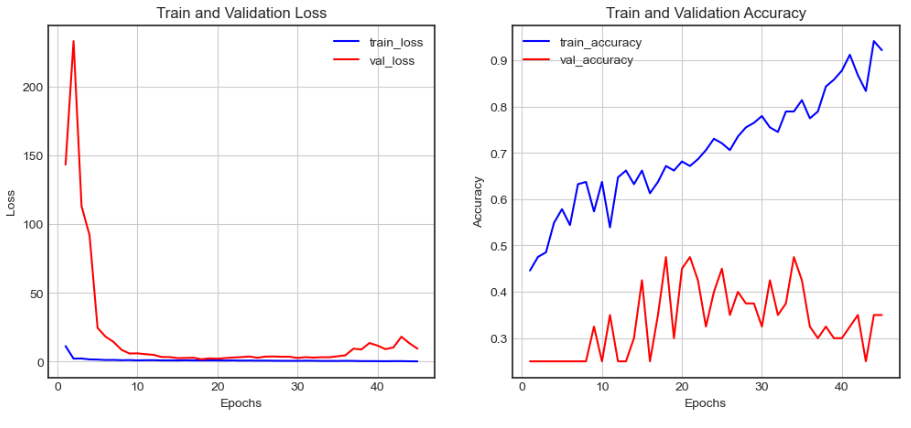
그리고 역시 확실한 종지부를 찍은 Test Accuracy 는 예상되었던 조짐과 크게 벗어나질 않았다.

미안하다 나의 벗 MFCC여…
개선 방안
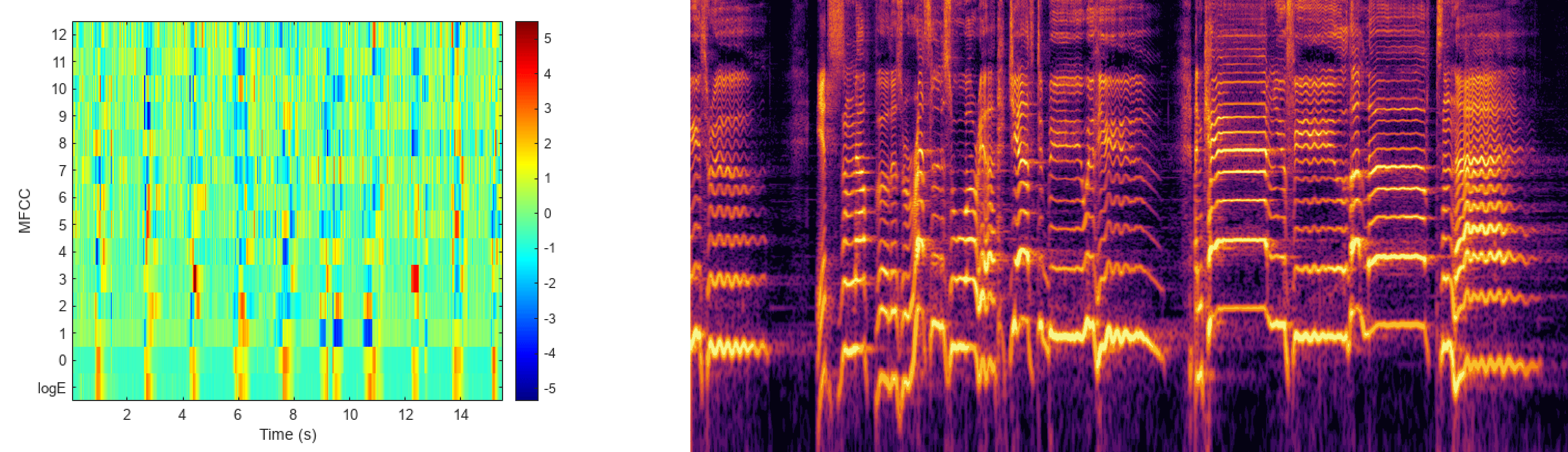
우선 MFCC는 아래 그림처럼 특정한 모양을 띄진 않는다. 그저 바코드 같은 모양을 띄기 때문에 오른쪽에 있는 파형의 이미지처럼 특정 모양 패턴을 육안으로 확인하기는 힘들다. 그저 색이 어떻게 바뀌는지만 볼 수 있다.
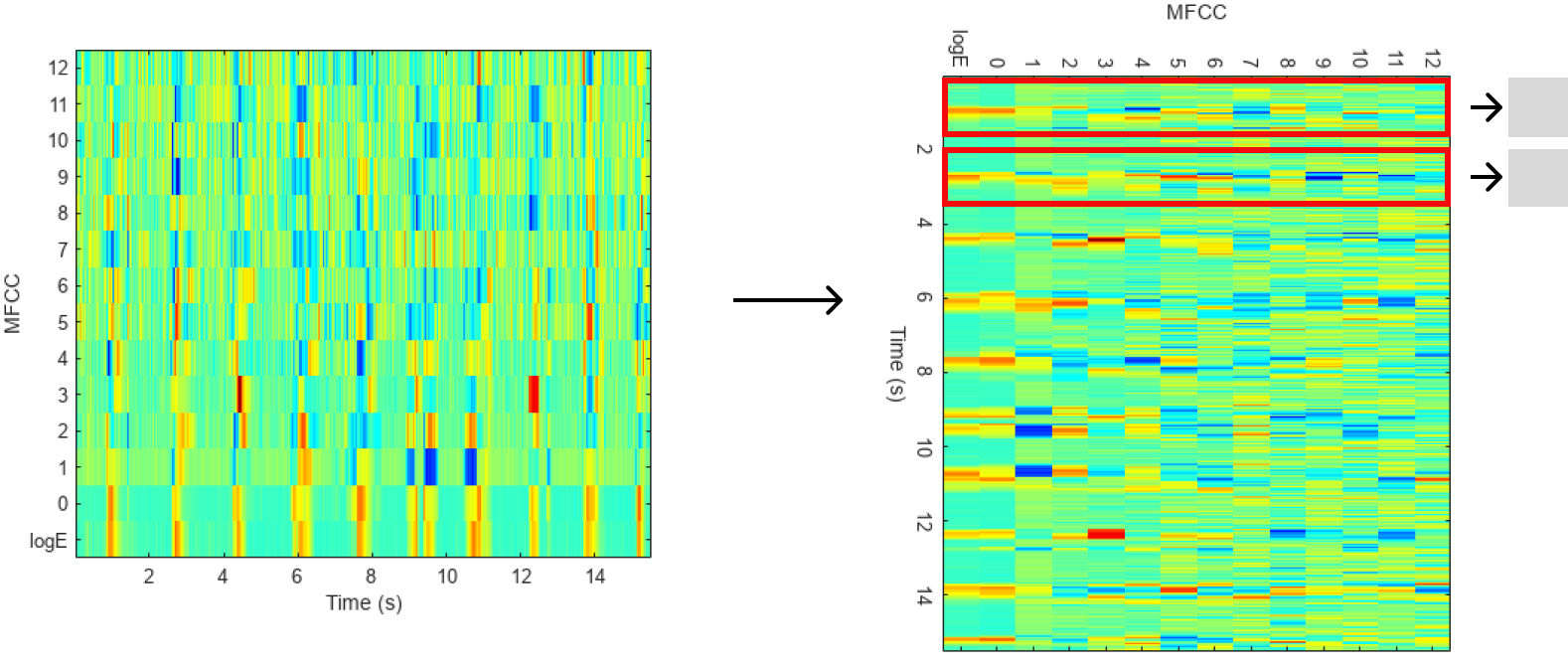
그래서 VGG16 처럼 색뿐만 아닌 모양도 Feature Map에 녹여내는 CNN모델들은 MFCC와 적합하지 않았나 생각이 들었다. 만약 CNN을 쓰더라도 kernel sized와 stride를 time step에 맞게 지정해서 Convolution 연산을 해보는 게 더 적합해 보인다. 가령 아래 그림처럼 말이다.
물론 MFCC 에 맞게 CNN을 맞춰서 classification task를 진행해 보는 것 도 좋으나 기본 중의 기본인 데이터셋가 사이즈가 받쳐줘야 의미가 있지 않나 싶다.
👉👉 다음 챕터 읽으러 가기
