Amazon Athena S3 데이터 로드 시 "Header Skip" 설정 방법
Data Engineering
Amazon Athena & S3
S3(Simple Storage Service)로 AWS를 대표하는 클라우드 서비스입니다. 객체 스토리지 (Object Storage)라는 형태의 서비스로 스토리지를 추상화한 형태로써 사용자는 데이터가 어느 블럭에 저장되는지 알 필요 없이 편리하게 사용 가능한 스토리지입니다. 물론 OS에 볼륨 마운트하여 사용도 가능합니다! 하지만 I/O 속도는 블럭 스토리지에 비하면 꽤 느린 편입니다. MiniO를 이용하여 객체 스토리지를 구현할 수 있습니다.
Athena는 Standard SQL을 이용하여 S3에 저장된 데이터를 간단하게 질의할 수 있는 대화형 쿼리 서비스입니다.
HDFS에서 Hive를 이용하여 SQL 질의하는 구조와 유사하구나~ 하고 이해하시면 좋습니다 🥳
Preface
Amazon S3에 저장된 여러 CSV 데이터를 Athena에서 테이블을 구성할 때, 1번 라인인 Header가 들어가는 상황을 대처해봅시다.
Pre-requirements
- Amazon Web Services 어카운트
- Amazon S3
- Amazon Athena
Header Skip 설정하기
Athena에서 테이블을 생성하고자 하는 버킷에 저장된 CSV 파일들을 먼저 살펴봅시다.
스키마가 전부 동일한가요?
그렇다면, 아래 파라미터를 추가하여 테이블 생성할 때 헤더를 생성할 수 있도록 설정합시다.
Ignoring Headers
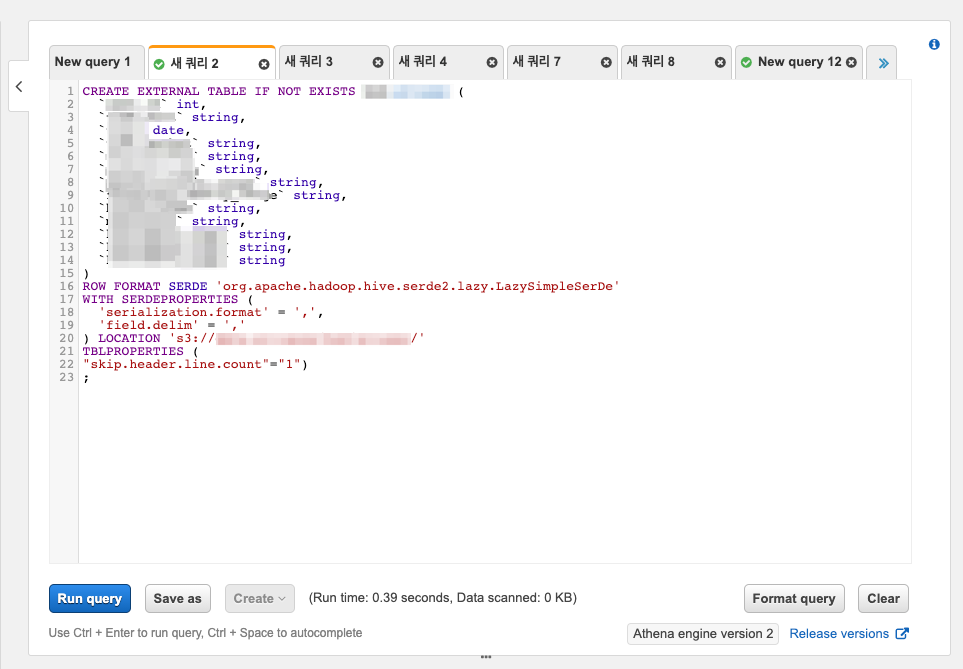
TBLPROPERTIES ('skip.header.line.count' = '1')파라미터를 입력하여 아래와 같이 입력합니다.
Query Sample
CREATE EXTERNAL TABLE IF NOT EXISTS [TABLE] (
`COLUMN_01` string,
`COLUMN_02` int,
`COLUMN_03` timestamp,
`COLUMN_04` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://athena-examples-myregion/flight/csv/';
TBLPROPERTIES (
'skip.header.line.count' = '1'
)Athena에서 External Table을 생성해서 테스트해봅시다.
더 이상 파일의 숫자만큼 Header값이 Row에 추가되지 않고 온전한 값이 들어가는 것을 확인할 수 있습니다.
Use case
참고 문서
AWS Athena Documents - LazySimpleSerDe for CSV, TSV, and Custom-Delimited Files - Ignoring Headers
