사이킷런 특징
- scikit-learn은 class(y)와 feature(X)로 데이터의 열이 구분되어야 한다.
- scikit-learn은 모든 feature가 숫자로만 구성되어야 한다.
X_train.Sex = X_train.Sex.map({'male': 1, 'female': 0})- scikit-learn은 결측값이 있는 feature를 사용할 수 없다.
경고메시지 숨기기
import warnings; warnings.filterwarnings(action='ignore') 데이터 분할
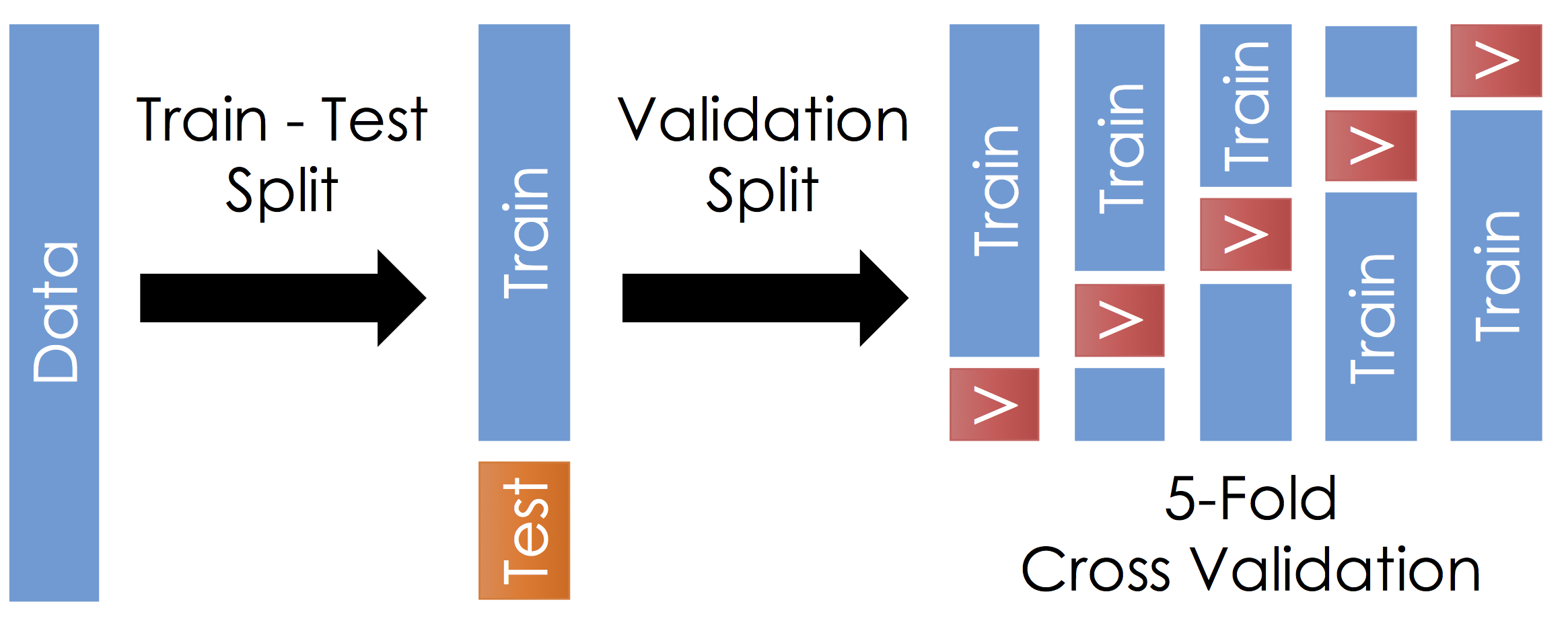
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0, stratify=y)
#classification을 다룰 때 매우 중요한 옵션값
#stratify 값을 target으로 지정해주면 각각의 class 비율(ratio)을 train / validation에 유지해 줍니다. (한 쪽에 쏠려서 분배되는 것을 방지합니다)
#만약 이 옵션을 지정해 주지 않고 classification 문제를 다룬다면, 성능의 차이가 많이 날 수 있습니다..jpg)
ML/DL swimmer