Machine Learning
1.sklearn basic
scikit-learn은 class(y)와 feature(X)로 데이터의 열이 구분되어야 한다.scikit-learn은 모든 feature가 숫자로만 구성되어야 한다.scikit-learn은 결측값이 있는 feature를 사용할 수 없다.
2.Feature Engineering_1

ML_1016_01_feature_engineering.ipynb6 Different Ways to Compensate for Missing Values In a Dataset결측치 비율에 따른 범주형 변수 처리 방법(권장)5~10% : 어떤 방법으로 하든 상관없음약
3.Feature Engineering_2
ML_1016_01_feature_engineering.ipynb6 Different Ways to Compensate for Missing Values In a Dataset
4.Model
특징 \- 이상치에 강한 모델임 \-tree를 분리하는 과정에서 feature selection이 자동으로 사용됨 \- 연속형과 범주형 변수를 모두 다루기 때문에 사전 데이터 준비가 많이 필요하지 않다 \- 결측값을 하나의 가지로 다룰 수 있기 때문에 이를 예측에
5.Model Tunning (Hyperparameter Optimization)
model_tuningfrom sklearn.model_selection import GridSearchCVfrom sklearn.model_selection import RandomizedSearchCVGrid Search와 Random Search는 이전까지의 조사
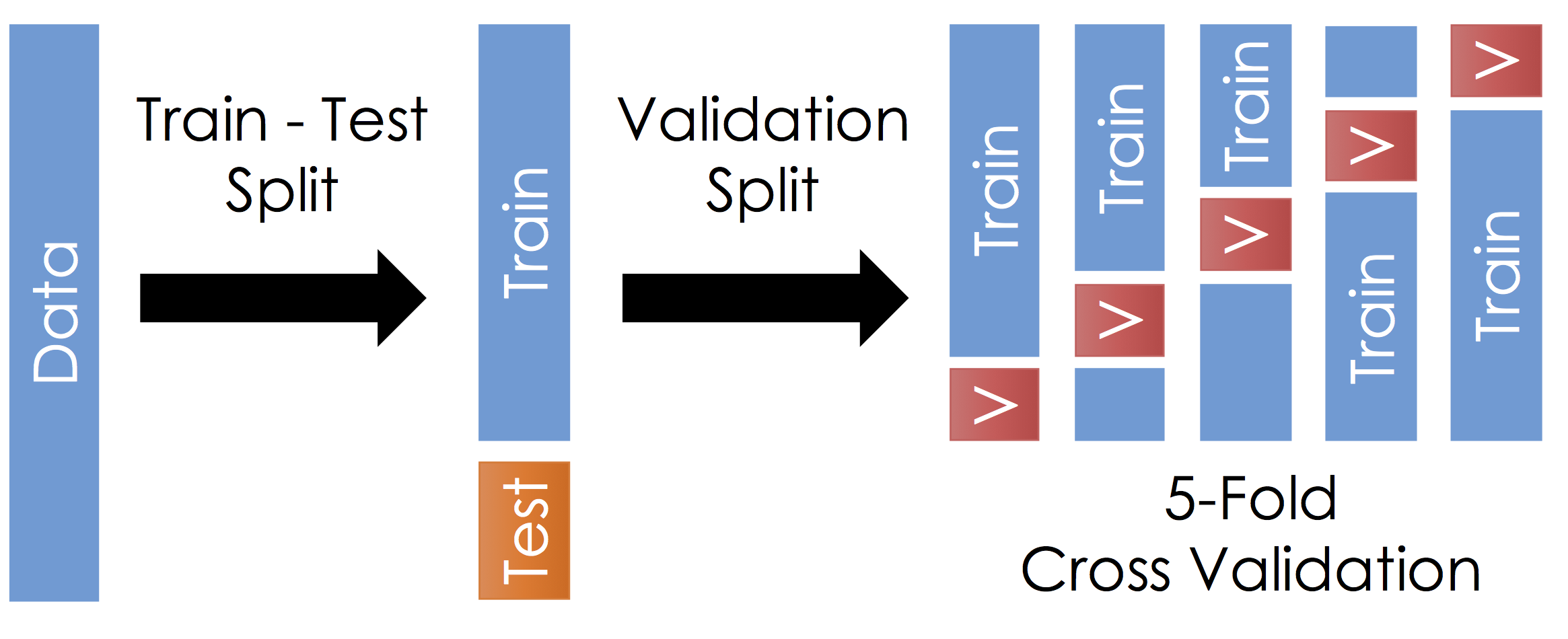
6.Cross Validation
shuffle_split
7.Eval Metrics
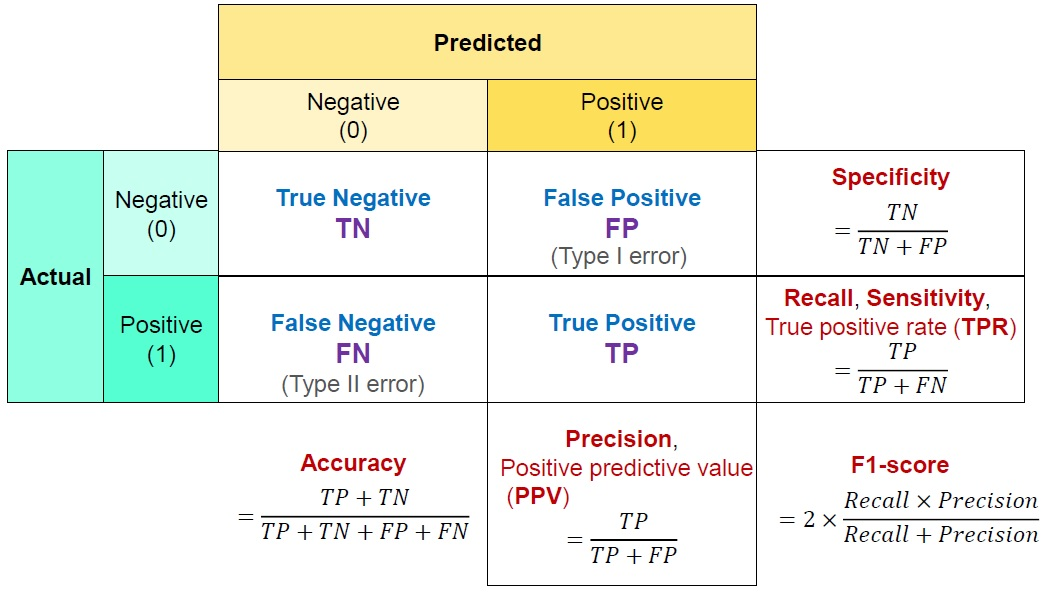
confusion_matrixconfusion_plotpr curveroc-auc
8.Ensemble
평가지표가 accuracy, recall, precision 등일 경우 but 권장 안함, 시간이 너무 오래 걸림 평가지표가 roc-auc, logloss 등일 경우 사용 산술평균, 기하평균, 조화평균, 멱평균(power mean)ML_1030_02_power_mean
9.Regularization
early stoppingdropoutweight decayingL1 : 가중치를 0으로 만드는 경향L2 : 매끄럽게.. 소극적 반영L1L2batch normalization : 틀에 맞춘다.. → regularization(억제) 효과서로 다른 크기를 같은 scale
10.Clustering
초기 중심값에 민감(랜덤하게 부여하기 때문에) \- K-menas++초기 중심점 선정의 어려움을 해결하기 위한 방법실제 레코드(데이터포인트)를 초기 중심점 선정에 활용K-means 주요 파라미터인 init (default : k-means++)MiniBatchkMea
11.Dimension Reduction
미니배치로 PCA 수행, 미니배치 적용때마다 점진적으로 PCA성능 개선 레코드가 충분하면 Basic PCA와 거의 유사하나 메모리 사용량이 낮음 sparse는 자료해석의 용이함, 과대적합 방지 등에 효과가 있음alpha값이 클수록(희소성의 유지가 잘 될수록) 일부 입력
12.Linear Regression
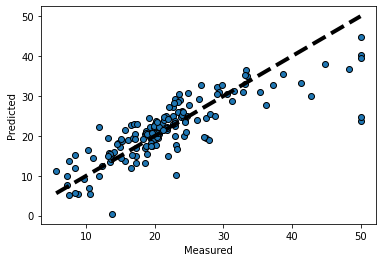
regression_result
13.Survival Analysis
생존 분석은 이벤트(사망, 고장 등) 발생까지의 시간을 분석하는 통계 기법입니다. 이때의 '이벤트'는 여러가지가 될 수 있으며, 이를 '사망'이라고 표현하는 것은 통계학에서의 관례입니다. 가장 널리 사용되는 생존 분석 모델 중 하나는 Cox의 비례 위험 모델입니다. 이
14.단변량 시계열 데이터 예측 모델 성능 비교(ARIAM, ETS, Prophet)
p,d,q 값 선정을 위한 테스트 ADF(Augment Dickey-Fuller) 테스트는 시계열 데이터가 정상성(stationary)을 갖는지 판별하기 위해 사용되는 통계적 검정 방법. ADF 테스트 결과 중 p-value값이 유의 수준(보통 0.05)보다 작을
15.SHAP
Tree 계열 모델kernel (SVM) 모델시간이 오래걸린다.