건설현장 작업자 안전관리 AI 솔루션 연구
Vision AI
대학원 과정에서 진행한 딥러닝 활용 인공지능 연구제안 프로젝트 내용을 복기하는 차원에서 작성해보고자 한다. 부족한 부분이 많은 프로젝트였지만 스스로 사례를 찾아보면서 문제에 어떻게 접근해야하는지 감을 잠을 수 있었던 경험이었다.
해당 프로젝트는 주제 선정, 선행 연구, 최종 발표 순서로 진행하며 실제 AI 구현까지는 포함되지 않는다.
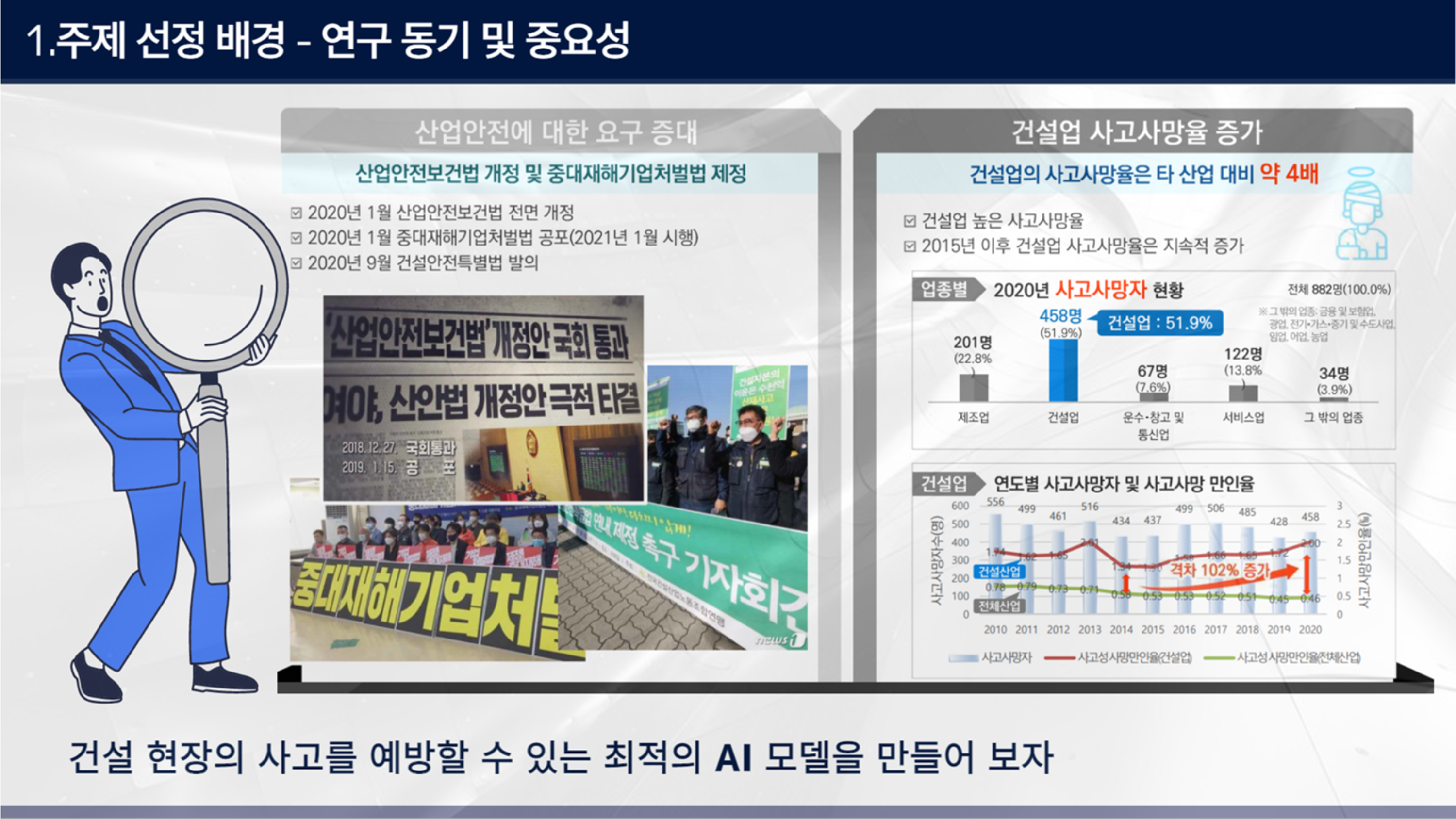
먼저 건설 산업에 대한 안전관리로 주제를 잡았는데 건설 산업이 안전과 관련해서 가장 필요한 분야라고 판단했기 때문이다.
선행연구를 하면서 건설 산업이 타 산업 대비 사고 사망율이 약 4배가량 높고 조금씩 증가하고 있는 추세다. 또 중대재해처벌법이 제정되고 나서 건설안전특별법이 발의되었는데, 이는 발주부터 시공까지 모든 공사 주체들에게 안전 책무를 부여하는 것이라고 한다.
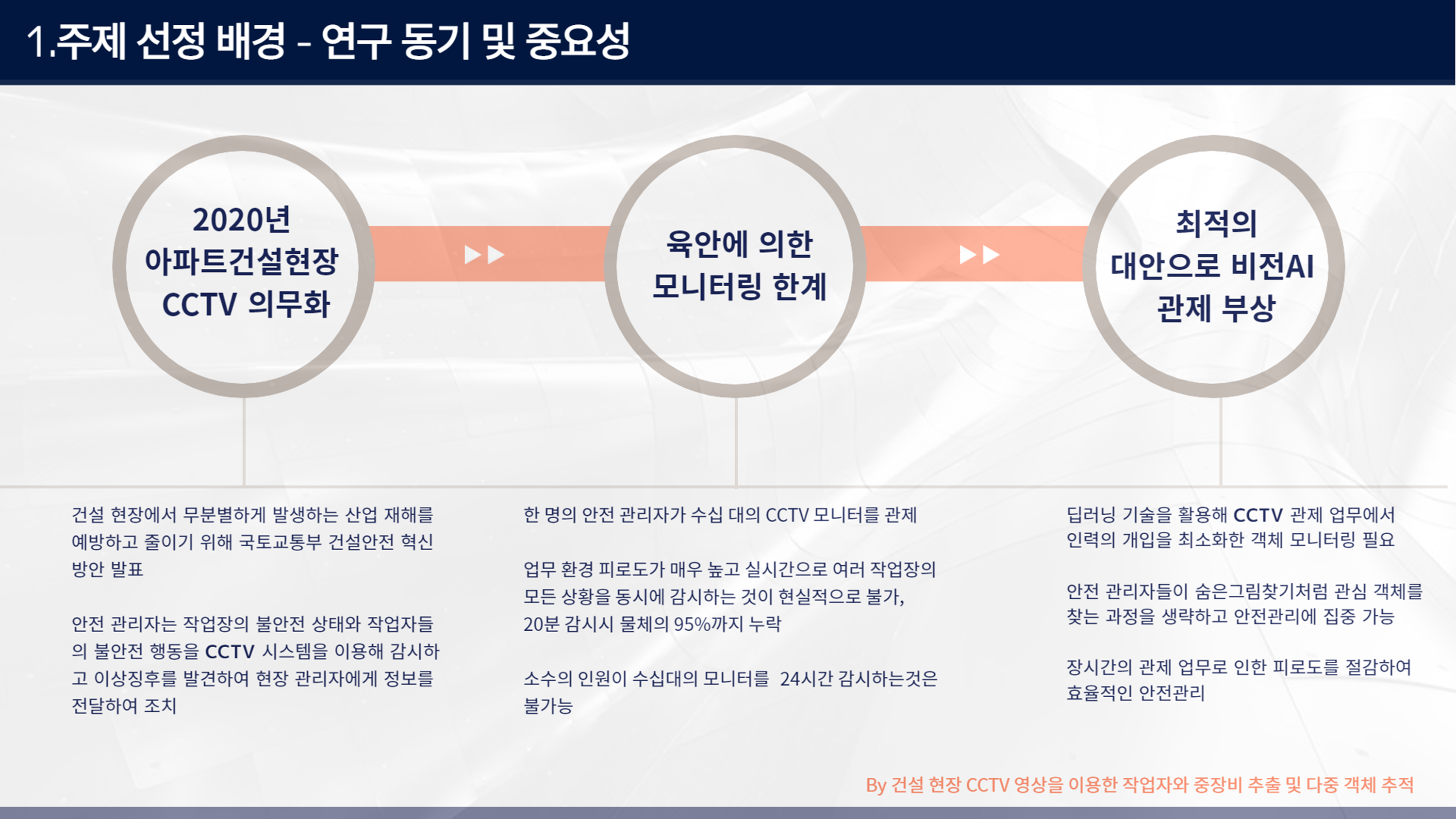
관련해서 국토교통부에서는 아파트건설현장에 CCTV의무화를 하도록 발표했다. 그러나 CCTV 설치를 하더라도 육안으로는 모니터링의 한계가 있기 때문에 이에 대한 대안으로 AI 기반의 안전관리 시스템에 대한 수요가 높아지고 있는 실정이다.
이러한 실정을 바탕으로 건설 현장의 사고를 예방할 수 있는 최적의 AI 모델을 만들어보자 라는 목표를 세우게 되었다.
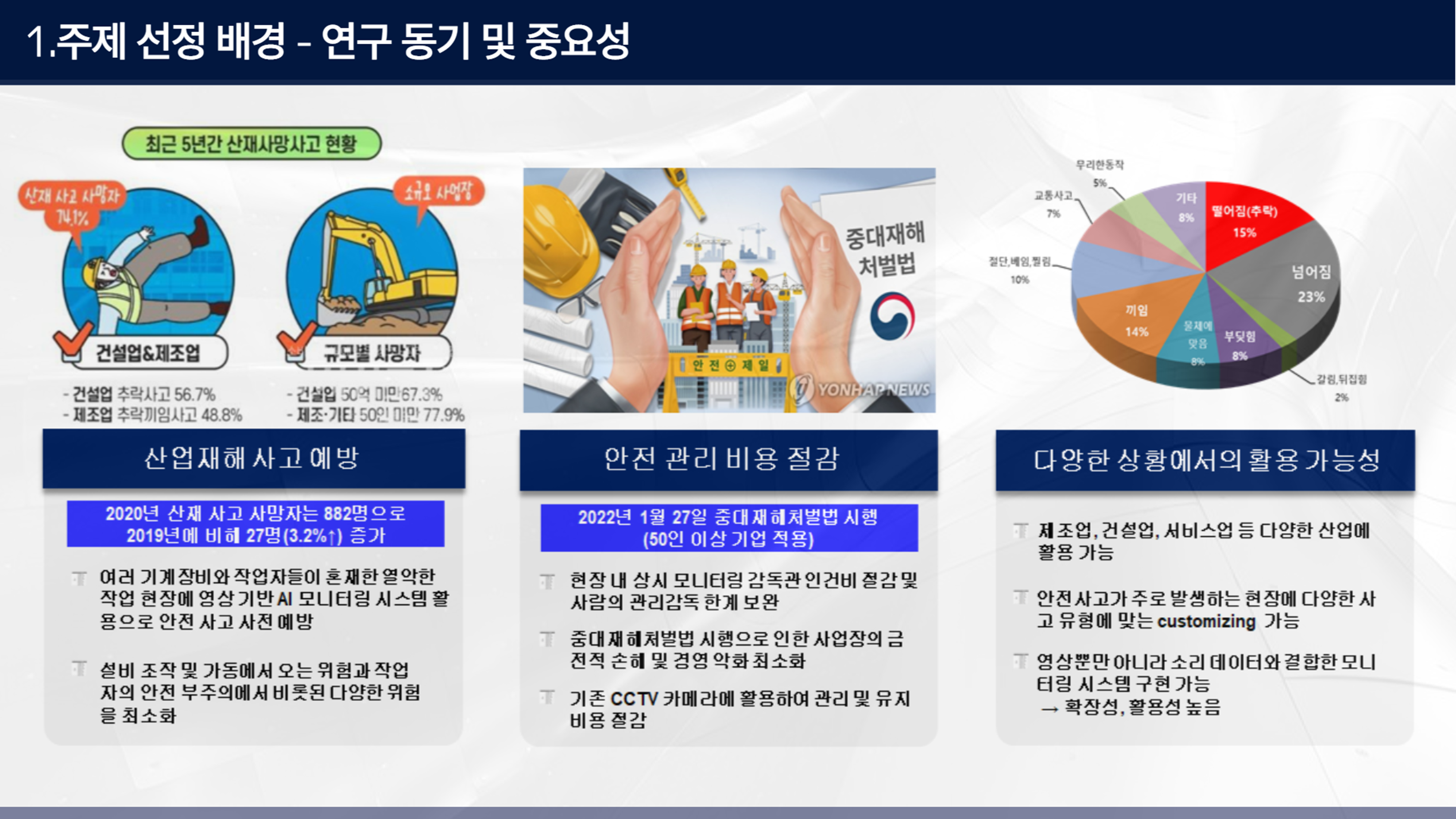
해당 주제에 대한 연구의 가치로는 다음과 같다.
먼저 산업재해 사고를 예방함과 동시에 안전관리 비용을 절감할 수 있다. 그리고 다양한 상황에서의 건설 현장뿐만 아니라 제조업 서비스업 등 다양한 산업과 상황에 맞게 적용될 수 있는 확장성이 높다.

활용할 데이터셋은 ai hub의 공사현장 안전장비 인식 이미지이다. 현장의 다양한 안전 보호구에 대해 실험할 수 있는데, 안전벨트, 안전고리, 안전화, 안전모 총 4가지 클래스이고 500만개가 넘는 이미지가 있다.
안전보호구뿐만 아니라 중장비, 구조물, 공구들과 사람이 현장 높은 곳에서 떨어지거나 넘어지고 부딪히는 이미지들도 있었다. 그런데 이 중에서 가장 중요한 것은 안전보호구 장착 여부라고 판단해서 해당 데이터셋으로 한정 했다. 현장에서 안전보호구만 착용해도 재해율을 많이 낮출 수 있다는 연구 결과가 있었고, 이미 사고가 발생하는 것을 탐지하기 보다는 사고를 예방하는 방향이 더 의미가 있다고 판단했기 때문이다.

안전보호구에 대한 이미지와 그에 따른 라벨링 데이터가 함께 있고, 어노테이션 방식은 안전벨트는 폴리곤, 나머지는 바운딩 박스로 처리되어 있다.

해당 주재의 선행연구 조사를 통해 하고자하는 연구 주제와 차이점과 한계점을 파악해보았다.
“작업자 안전을 위한 영상센서 활용인원 계수시스템 개발” 에서는 사람과 안전장비를 단계별로 탐지를 해서 속도 측면에서의 한계점이 있다고 판단을 했고, “산업현장 작업자 위험 상황 인식 및 분석에 관한 연구”에서는 데이터를 자체적으로 구축함에 따라서 학습량의 한계가 있었던 점, 자세 추정을 하는 과정에서 많은 수의 앵커박스 발생으로 탐지 속도가 저하되었다는 점이 파악되었다.

다음으로, “yolo-v3를 활용한 건설장비 주변 위험상황 인지 알고리즘 개발”에서는사람과 차량에 대한 인식만을 연구하였으며, “R-FCN과 Transfer Learning 기법을 이용한 영상 기반 건설 안전모 자동탐지”에서는(나머지 논문에서는) 데이터를 직접 촬영했지만 다양한 상황을 고려하지 못했다라는 점이 파악되었다.

선행 연구에서의 대표적인 한계점으로는 해상도로 인한 객체 탐지 문제, 그리고 2개의 객체가 겹쳐진 경우 뒤의 객체가 인식이 안되는 문제가 있었다.
건설현장은 위 사진 처럼 작업자와 구조물, 장비등이 혼재되어있어 굉장히 복잡하다. 그리고 작업자나 구조물로 인해 가려지는 상황이나 카메라에서 객체가 멀리 있어서 매우 작게 잡히는 상황 등이 많다. 따라서 뒤에서 설명할 'YOLACT 알고리즘을 활용해서 건설현장에 적용한다면 실시간으로 객체를 탐지하면서도 위 한계점을 개선할 수 있을 것이다.' 라는 가설을 세웠다. 실제로 한 논문에서는 겹쳐진 객체의 인식률이 다른 모델에 비해 YOLACT가 뛰어나다고 밝힌 부분이 해당 가설을 세운 근거중 하나다.
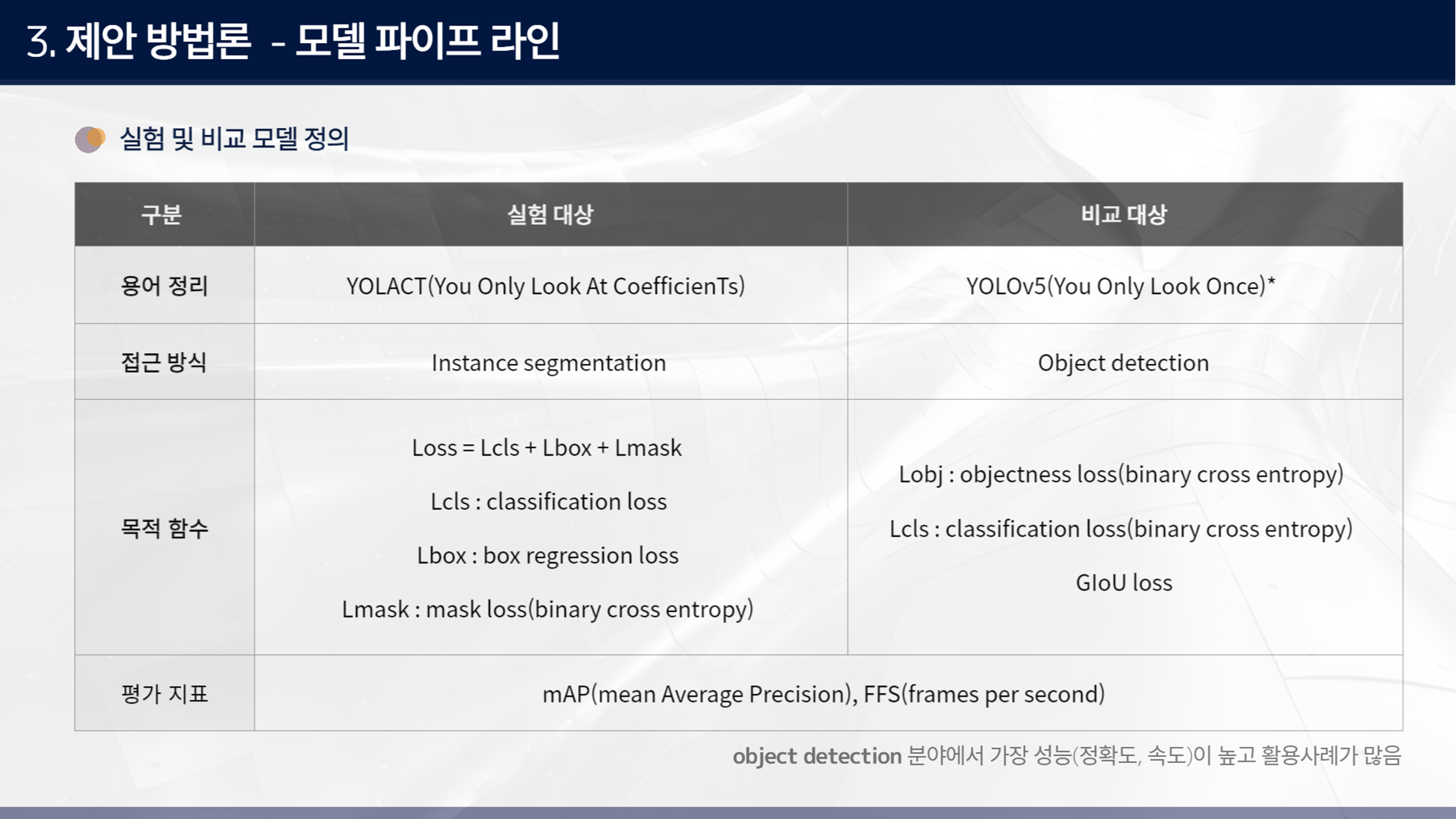
실험하고자 하는 방법론은 YOLACT이며 instance segmentation 방식이다. 이와 비교하고자 하는 방법론은 Yolo-v5로 object detection 방식이다. yolo-v5는 object detection 분야에서 가장 성능이 높고 활용 사례가 많아서 선정했다. 평가 지표로는 mAP, FFS 등이 있다. 두 방법론을 적용해서 건설현장에서는 실시간 instance segmentation 방식인 YOLACT가 더 적절한 방법론임을 확인하고자 한다.
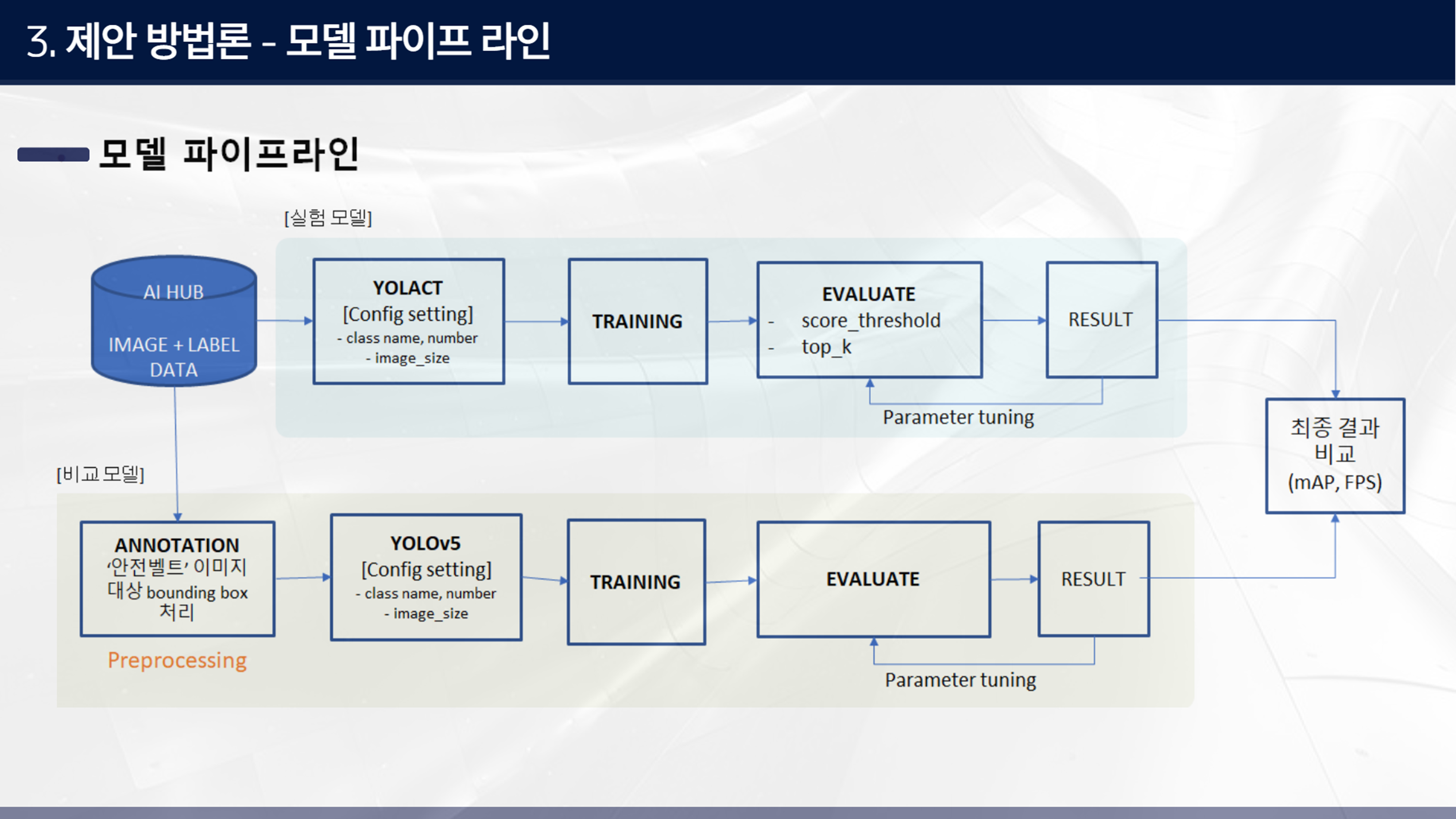
모델 파이프라인에서 실험 모델에서는 pre-trained 모델인 YOLACT를 불러와 학습하고자 하는 이미지에 맞게 환경설정을 하고 훈련과 평가를 통해 결과를 확인한다.
비교 모델인 Yolo-v5에서도 과정은 동일한데, yolo-v5에서는 polygon annotation방식이 인식이 어렵다는 자료를 봐서, 기존에 polygon으로 어노테이션 되어 있는 안전벨트 이미지에 대해 bounding box 처리를 사전에 해준다. 이 부분은 오픈소스 프로그램 기반으로 annotation 작업한다.
그래서 최종적으로는 실험 모델의 결과와 비교 모델의 결과를 정량적 지표로 확인한다.
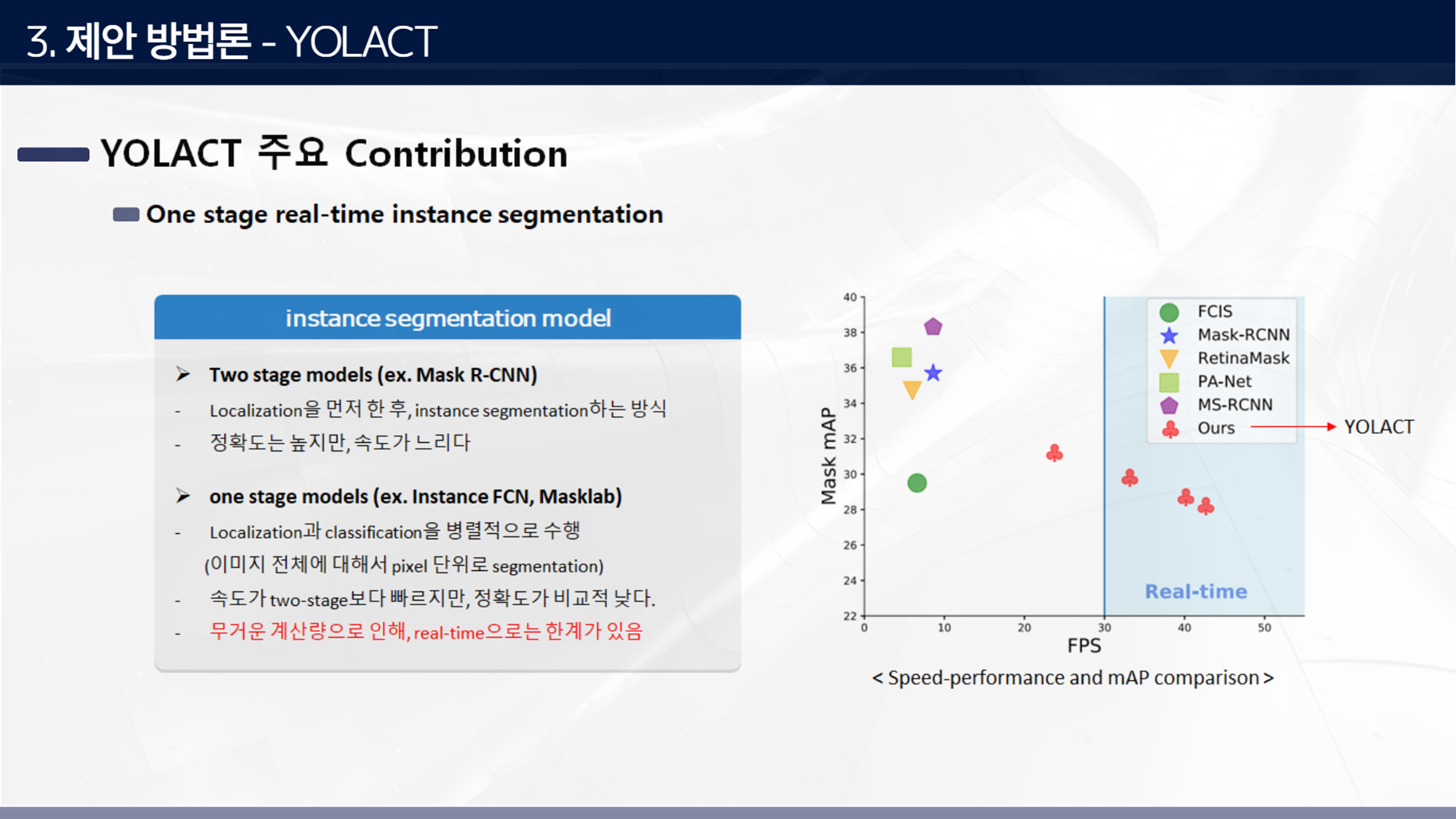
일반적으로 인스턴스 세그멘테이션 방식은 픽셀 단위로 객체의 윤곽까지 모두 인식하는것이기 때문에 일반적인 객체탐지 모델보다 굉장히 복잡하고 속도가 느리다고 알려져 있다.
인스턴스 세그멘테이션 방식은 객체 탐지 방식과 마찬가지로 two stage 방식과 one stage방식이 있는데,
two stage 방식은 localization을 먼저 한 후, instance segmentation을 하는 방식으로 정확도는 높지만 속도가 느리다는 특징이 있다. 반면 one stage 방식은 localization과 classification을 병렬로 수행해서 속도가 two-stage방식보다 빠르지만, 정확도가 비교적 낮다. 그러나 Yolact 모델은 구조가 더 간단하고 계산량이 적어서 real-time으로 적용이 가능하다고 한다.
옆 그림 처럼 two-stage 방식인 Mask RCNN대비 속도가 2~4배 이상 차이가 나는 것을 알 수 있다.

이렇게 real-time이 가능한 부분은 크게 2가지 인데 아래 두 task를 병렬적으로 수행하는 방식으로 속도를 높였다. 전체 이미지에 대해 추출된 feature map을 바탕으로 k개의 proto-type mask 를 생성하는 것과 각 instance별 mask coefficient를 예측해서 최종적으로 가장 적합한 instance 하나만을 추출하는 단계로 구성되어 있다.
추가로 속도향상에 기여하는 기법이 Fast NMS 이다. NMS는 non-maximum suppression의 약자로 동일한 인스턴스에 집중한 여러 앵커박스 중에서 컨피던스가 가장 높은 박스 한 가지만 남기고 나머지를 제거하는 과정이다. 기존의 NMS방식은 연속적으로 앵커박으를 지워나가는 반변, Fast NMS는 지워진 앵커박스가 다른 앵커박스를 지우기위해 다시 비교군에 들어가면서 병렬 연산을 진행한다. 이렇게 병렬로 앵커박스를 지워나감으로써 속도를 더 높였다고 한다.

YOLACT의 주요 contribution은 간단하게 말하자면
- 객체의 윤곽을 robust 하게 인지할 수 있다.
- 해상도가 좋은 프로토타입을 얻을 수 있다.
- 그래서 작은 객체를 잘 탐지할 수 있다.
이 부분은 더 deep한 feature map으로부터 feature extraction을 하는 방식이라고 설명하고 있다. 기존 방식은 feature map이 점점 깊어질 수록 이전 정보를 무시하는 경향이 있었는데, YOLACT의 구조에서는 5층의 feature 피라미드에서 이전 해상도의 feature map의 정보를 담기위해서 피처맵을 더하는 과정이 있어서 더 로버스트하고 해상도에 강한 마스크가 생성 가능하다라고 설명하고 있다. 위 그림처럼 더 선명한 엣지를 확인할 수 있다.
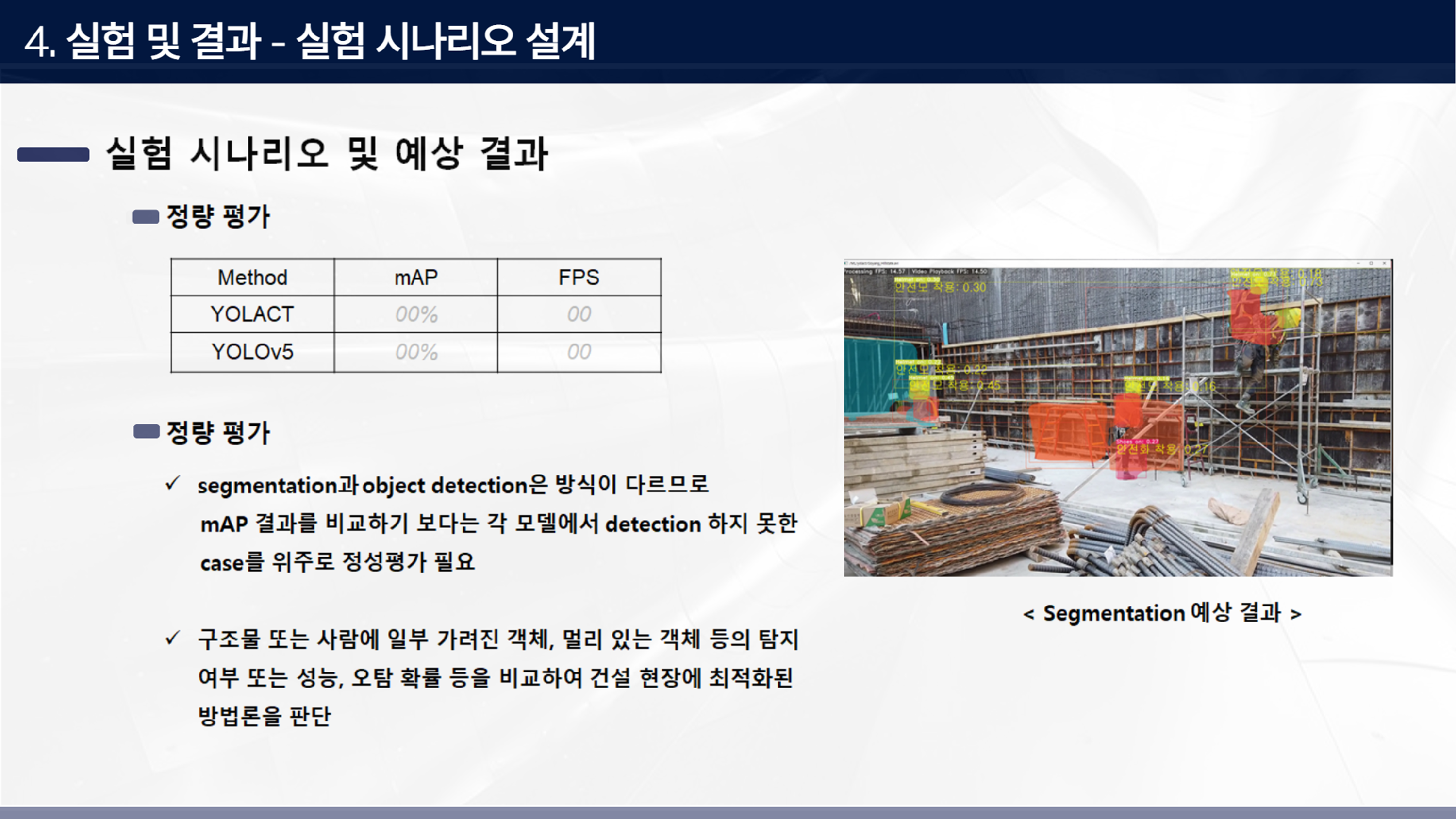
실험 시나리오에 대한 예정 결과로 먼저 주요 지표로 정량 평가로 수치를 비교해볼 수 있다. 그러나 segmentation과 object detection은 방식 자체가 다르므로 mAP결과를 비교하기 보다는 각 모델에서 detection하지 못한 case를 위주로 정성평가가 필요하다고 판단했다. 예를 들어, 구조물 또는 사람에 일부 가려진 객체, 멀리 있는 객체 등의 탐지 여부 또는 성능, 오탐 확률 등을 고려하여 건설 현장에 최적화된 방법론을 판단할 필요가 있다.
결론을 예측해보자면, 속도 측면에서는 Yolo-v5가 더 높을 것으로 예상되고 mAP 측면에서는 두 모델이 유사하지만, 구조물 또는 사람에 일부 가려진 객체, 멀리 있는 객체의 탐지율은 YOLACT가 더 우수할 것으로 예상된다. 또한, wrong detection 가능성 측면에서도 두 모델을 비교/분석 할 수 있을 것이다.

기대 효과로는, 건설현장의 안전 요구를 대응할 수 있으며, 건설 현장의 CCTV 영상을 이용한 효율적인 안전관리를 실현함으로써 건설시장의 디지털라이제이션이 가능할 것이며, 안전사고를 줄임에 따른 사회적 비용 절감효과가 있을 것으로 기대된다.
.jpg)