
언어 모형 : 문장의 확률을 계산하기 위한 모형
- 확률의 연쇄 규칙
-
인과적 언어 모형(=언어모형) : 조건부 확률 형태의 언어 모형
- 인공신경망 등의 모형으로 구현하기 쉬움
- 단어를 순서대로 생성할 수 있음
-
n-gram 언어 모형 : 텍스트에서 최대 n개까지의 단어 조합의 빈도를 세서 언어 모형을 간단히 구현할 수 있음
- storage problem : n이 커질 수록 조합이 폭발적으로 증가하여 많은 저장 공간 필요
- sparsity problem : 텍스트가 충분히 많지 않으면 대부분의 조합은 빈도가 0
-
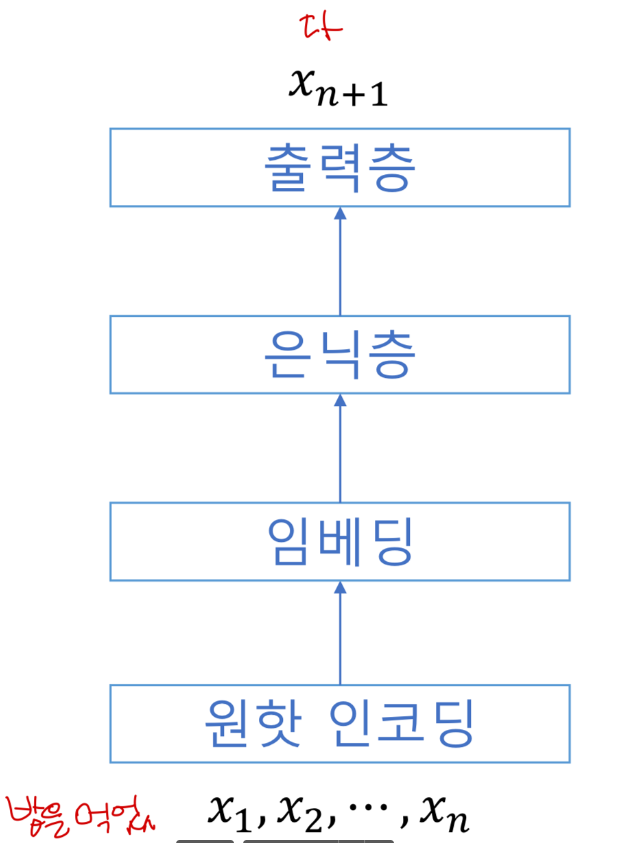
신경망 언어모형 (NNLM, Neural Network Langauge Model)
- 원핫 인코딩의 문제점: sparsity, 의미 무시
- 비슷한 단어는 비슷한 임베딩을 갖게 됨
- NNLM은 임베딩의 크기가 , 은닉층의 크기가 일 경우 의 파라미터만 필요
(↔ n-gram은 어휘의 종류가 개면 개의 조합을 저장) - NNLM의 한계
- n-gram과 마찬가지로 n개의 단어까지만 반영됨
- 단어의 위치에 따라 가중치가 달라짐
-
순환 신경망
- 사라지는 경사 또는 폭발하는 경사
-
LSTM
- 순차적으로 계산되기 때문에 병렬 처리가 어려움
- 문장이 길어질 수록 네트워크도 길어져서 학습시키기 어려움
-
주의 메커니즘
-
주의 메커니즘은 모든 단어를 비교해서 현재의 처리 단계에 필요한 정보를 바로 가져옴
-
순환신경망에 비해 계산량은 많으나, 병렬 처리가 쉬움
-
점곱 : 유사도(similarity)로서 특성을 가짐
⇒ 순환신경망 + 주의 메커니즘
-
.jpg)
ML/DL swimmer