NLP/Text Data Analysis
1.한국어 형태소분석

한국어 텍스트 분석을 위해서는 문장을 형태소 단위로 나누어 분석을 해줘야 한다. (띄어쓰기, 조사, 품사 등을 구분..) 이를 위한 라이브러리는 크게 4가지가 있다.konlpy : hannanum, kkma, okt, komoran 등 java 기반komoran은 상대
2.주제 분석(Topic Analysis)

주제 분석의 방법 중 행렬 분해에 의한 방법과 확률 분포에 의한 방법이 있다. 그 중 행렬 분해애 의한 방법은 크게 LSA(Latent Semantic Analysis)와 NMF(Non-Negative Factorization)로 나눌 수 있다. LSA는 잠재 의미를
3.단어 임베딩
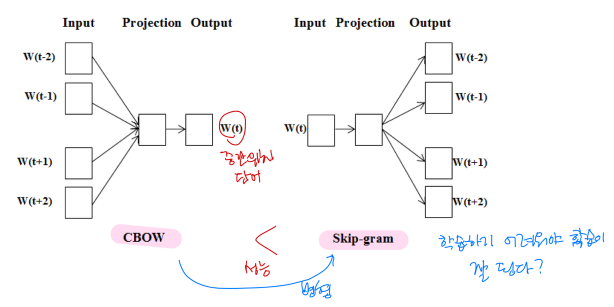
단어 임베딩 : 단어를 낮은 차원의 벡터로 나타내는 것원핫 인코딩은 sparse, 용량 많이 차지, 단어 의미 고려 안함단어의 의미를 좌표로 나타내는 것 또는 수치화 → 의미가 비슷한 단어들은 비슷한 값을 가짐단어 임베딩의 다차원 공간상에서 방향에 의미가 있어야 함단어
4.주제 다양도(topic diversity)

LDA와 같은 주제분석을 할 때 평가를 위한 지표로 Perplexity, 주제 응집도, 주제 다양도 등이 있다. (관련 내용에 대한 이전 블로그 글)주제 응집도는 주제를 구성하는 단어들이 서로 연관된 정도를 측정하는 것이 목적이다. 즉, 한 주제에 대해서 단어들이 얼마
5.자연어 처리

자연어 처리의 분야 2가지자연어 이해(듣기, 읽기) : 문서 분류, 토큰 분류, 문서 유사도, 질의 응답자연어 쓰기(말하기, 쓰기) : 다음 단어 예측, 빈 칸 채우기, 요약, 번역자연어 생성의 방법규칙 기반 (e.g. 일기예보)장점: 자연어 생성의 각 과정을 세세하게
6.언어 모형(Language Model)

확률의 연쇄 규칙 $P(x_1, x_2) = P(x_2|x_1)P(x_1)$ 인과적 언어 모형(=언어모형) : 조건부 확률 형태의 언어 모형 $P(xn|x_1, x_2, …, x{n-1})$ 인공신경망 등의 모형으로 구현하기 쉬움단어를 순서대로 생성할 수 있음n-
7.트랜스포머(Transformer)

개념주의 메커니즘만을 사용한 Seq2Seq 모형(like 번역기, 챗봇)문장 내, 문장 간 주의 메커니즘 적용모델 구조 Query-Key-Value하나의 입력값을 Query, Key, Value 세 가지 값으로 변환사전 검색과 비슷Query(질의, 검색어)와 비슷한
8.AI HUB 에세이 글 평가 데이터 Bert 예측 모델 만들기(1)

AI HUB 에세이 글 평가 데이터를 활용하여 간단한 score 예측 모델을 만들어 보고자 한다. 에세이 글 데이터에는 초등/중등/고등학생 전학년의 글들이 있으며, 11종의 세부 평가지표에 따른 점수와 관련 메타 데이터가 존재한다. AI HUB에 공개된 AI 모델
9.AI HUB 에세이 글 평가 데이터 Bert 예측 모델 만들기(2)

이전 글에 이어서 데이터 전처리와 모델링 과정을 정리하고자 한다. 4. 데이터 전처리 json파일로부터 필요한 데이터를 가져와 train, test에 넣어주었다. 데이터 전처리는 train, test 구분 없이 한번에 처리하기 위해 temp로 합쳤다. 나중에 학습할
10.Decoding and GPT

인코더와 디코더트랜스포머는 Seq2Seq 모형 (입력 시퀀스 → 출력 시퀀스)인코더 : 입력 시퀀스를 처리하는 부분(양방향 attention), 문장의 의미 이해디코더 : 출력 시퀀스를 처리하는 부분(단방향 attention), 새로운 문장 생성GPT : OpenAI에
11.챗봇 평가 방법

사람에 의한 평가 (Turing Test)생각할 수 있는 능력에 대한 테스트로는 문제가 있음짧은 시간 동안의 대화에서 인간 평가자를 속이기는 쉬움평가자 간의 차이, 시간과 비용, 다양성에 대해 평가혼란도(perplexity) (e.g. 혼란도 2라면 한 단어마다 2개
12.자연어 처리에서 데이터 증강 방법
단어 바꾸기문장에서 단어를 골라 유의어 사전이나 단어 임베딩을 이용해 유의어로 교체TF-IDF 점수가 낮은 단어로 교체 역변역(Back translation) 문장을 다른 언어로 번역 후, 원래의 언어로 다시 번역 의미를 보존하면서 표현을 바꿀 수 있음텍스트 표층 변