컴퓨터 비전에는 크게 4가지의 과제가 존재한다.
1. Classification
2. Object Detection
3. Image Segmentation
4. Visual relationship
이 글에서는 Image Segmentation에 대해서 공부할 것이다.

Image Segmentation의 정의
머신러닝에서 Image segmentation이란 데이터를 개별 그룹으로 분리하는 프로세스를 의미. Deep learning에서 Image segmentation은 label이나 범주를 이미지의 모든 픽셀과 연결하는 segement map을 만드는 과정이 중요.
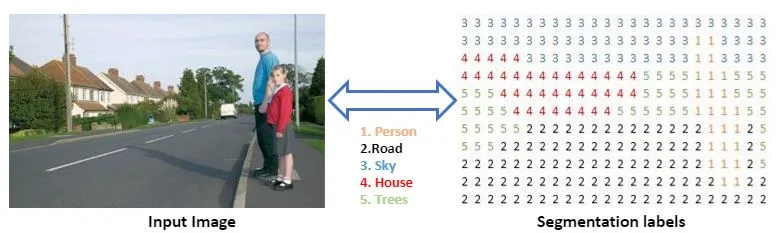
ex. 물체의 경계를 윤곽선으로 표시하여 해당 object, 물체가 있는 위치 찾아내기, 개별 object detection부터 이미지 속 여러 영역에 개별 레이블 지정
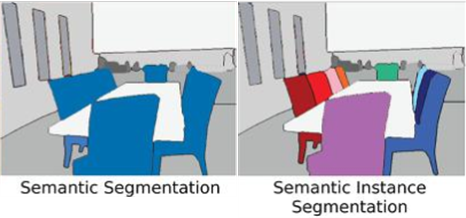 Image segmentation은 Image classification의 확장
Image segmentation은 Image classification의 확장
👉🏻 이미지의 영역을 분할해서 각 객체에 맞게 합쳐주는 것
👉🏻 분류 외에도 객체의 관계를 표현하여 해당 객체가 있는 위치를 정확히 가리킨다!
👉🏻 Image Classification은 이미지 전체에 대해 하나의 정보만 주고, Image segmentation은 이미지 내에 경계를 부여하고 + 해당 경계에 대한 독립적인 정보를 라벨링
Image segmentation의 종류
1. Semantic Segmentation
- 입력된 이미지의 모든 단일 픽셀에 해당 콘텐츠를 설명하는 클래스 레이블을 할당하는 것
- Supervised learning(지도 학습)과 Unsupervised learning(비지도 학습)으로 나뉨
- 지도 학습의 경우, 수동으로 semantic label을 붙인 이미지 데이터셋을 모델에 훈련시킨 후 작업 수행
- 비지도 학습의 경우, semantic label이 지정된 이미지 데이터셋 불필요. 다양한 방법을 통해 사전 지식 없이도 이미지의 레이블을 학습하는 방식
- Image classification 모델의 수정을 통해 구현! ➡ FCN(완전 컨볼루션 네트워크)에서 시작됨 ➡ DeepLab, FastFCN, DeepLabV3, Transformer-based models 등의 모델
2. Instance Segmentation
- 이미지의 개별 객체를 식별하고 분할. 이미지의 각 객체에 고유한 레이블을 할당하고, 각 객체의 경계 또한 식별 가능
- 객체의 모양이나 컨텍스트에 따라 이미지의 개별 객체를 식별 및 세분화
- 일반적으로 Mask R-CNN Architecture 모델을 기반으로 제작
- 구현 방식 1. Bottom-up 방식 : 이미지의 개별 픽셀을 감지하는 것부터 시작해 이러한 픽셀을 함께 그룹화하여 객체 형성
- 구현 방식 2. Top-down 방식 : 이미지의 전체 장면을 감지하고 개별 객체를 식별한 뒤 세그먼트화
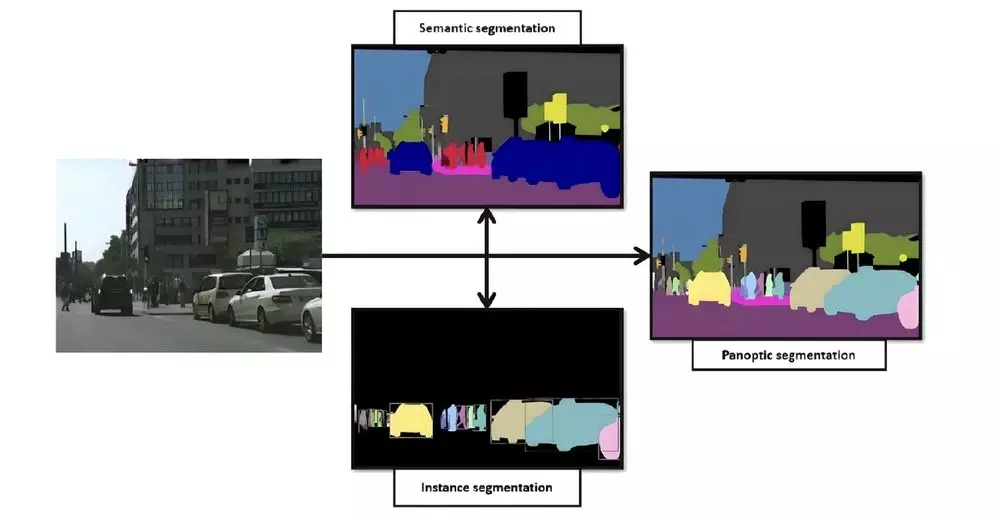
3. Panoptic Segmentation
- 단순히 객체를 구별하는 semantic segmentation과 객체의 경계를 이해하는 instance segmentation의 개념을 병합한 모델
- 이미지의 개별 객체를 식별하고 세분화 + 장면의 의미적 내용 식별
- semantic&instance segmentation이 상호 보완적이라는 원칙에 기반
- semantic segmentation을 통해 장면의 시맨틱 의미적 내용 식별
- instance segmentation을 통해 장면의 개별 객체를 식별 및 세분화
- 출력에 물건과 사물을 모두 포함하여 정확하게 표현하며, 셀 수 있는 대상(ex. 차량, 사람, 나무 등)과 셀 수 없는 대상(도로, 하늘 등)을 표현
4. 비교
| Semantic Segmentation | Instance Segmentation | |
|---|---|---|
| 개념 | 1. 각 픽셀별로 어떤 class에 속하는지 label을 구하고, One-Hot encoding으로 각 class에 대해 class 개수만큼 출력채널을 만듦.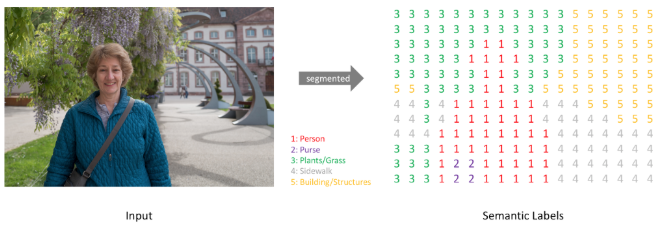 2. argmax를 통해 하나의 output 계산. 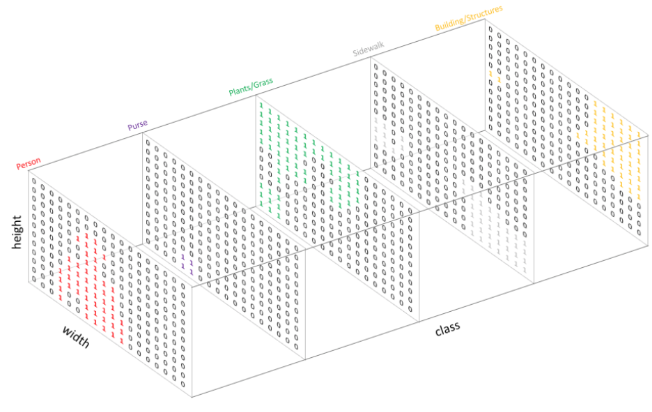 3. 각 픽셀들에 대해 그 클래스에 포함되는지 아닌지를 binary하게 값을 가짐  | 1. 각 픽셀별로 어떤 카테고리에 속하는지 계산하는 것이 아닌, 각 픽셀별로 object가 있는지 없는지 여부만 계산. 2. localize된 RoI마다 class의 개수만큼 binary mask 씌움. 3. RoI별로 class 개수만큼 ouput 채널이 존재하고 동일 class더라도 서로 다른 instance(=RoI가 focus하는 객체 부분)만 value를 갖도록 함. 4. 동일 클래스여도 서로 다른 객체인 경우 value를 갖지 않음. 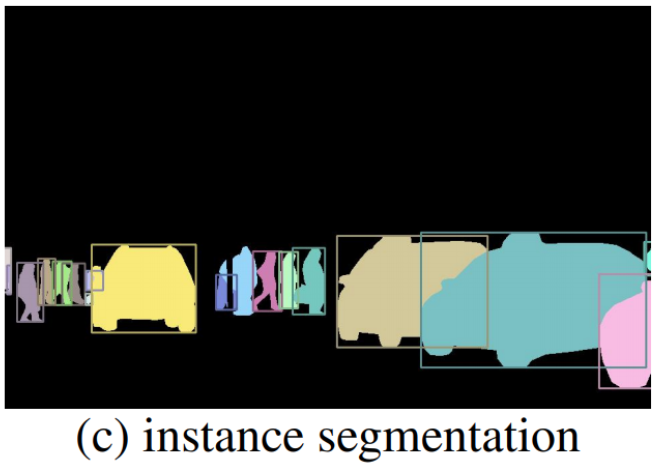 |
| 단점 | 같은 클래스의 객체들에 대해 서로 구분지을 수 없음 | 각 픽셀별로 객체의 존재 여부만 계산 |
Image segmentation의 구조와 원리
1. Recognition + Localization
Image segmentaion 모델은 먼저 이미지에서 특징을 추출하여 객체를 인식(Recognition)하고 위치를 파악(Localization)한다. 여기서 추출하는 특징은 색상이나 텍스처, 모양 등이 있다. Image segmentation에 사용되는 모델은 이러한 feature 정보를 사용해 이미지를 부분적으로 구성하고, segment map을 만들어 픽셀 단위의 경계를 기준으로 정보를 정의한다.
Recognition : 이미지가 segment화되면 모델은 각 세그먼트를 객체 또는 배경으로 분류한다. 이 작업은 이미지에 포함된 객체로, 레이블이 지정된 이미지 데이터셋에 대해 학습한 Classification 기능을 사용해 수행한다.
Localization : 마지막으로 모델은 객체 주변의 bounding box(경계 상자)를 식별하여 객체의 위치를 찾는다. 경계 상자는 객체의 경계를 정의하는 4개의 좌표 집합을 의미한다.
2. Encoder + Decoder
컴퓨터 비전 분야에서 대부분의 image segmentation model은 Encoder-Decoder 구조로 구성된다. Decoder로부터 나온 segment map은 이미지에서 각 개체의 위치를 나타내는 일종의 지도이다.
- Encoder : 점점 더 좁고 깊어지는 일련의 필터를 통해 이미지를 추출하는 레이어. 입력된 정보를 취합/저장하는 역할. 주로 컨볼루션과 풀링과 같은 연산을 사용해 입력 데이터의 추상화된 특징을 추출하고 이를 저차원의 표현으로 변환.
- Decoder : 인코더의 출력을 입력 이미지의 픽셀 해상도와 유사한 세분화 마스크로 확장시키는 레이어 마스크. 인코더로부터 축약된 정보들을 풀어서 반환/생성해주는 역할. 주로 업샘플링과 같은 연산을 사용하여 저차원의 표현을 다시 고해상도의 출력으로 확장
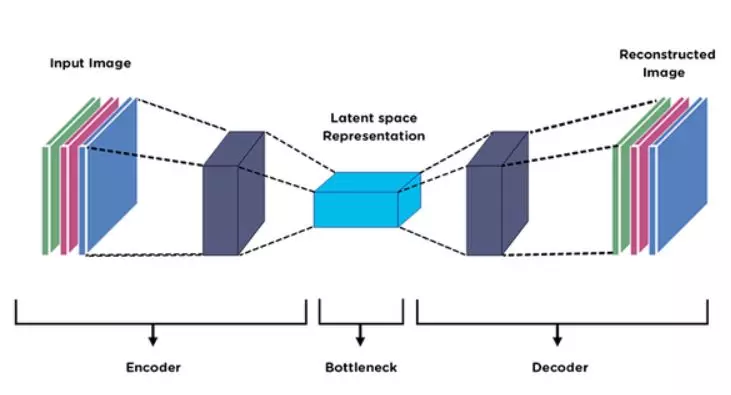
오토인코더의 개념
: 입력과 출력이 (거의) 동일한 값을 갖도록 만든 신경망 구조
- 레이어가 점점 줄어들다가 다시 커지는 형태
- 가장 중요한 목적은 차원 축소
➡ 인코더는 입력 데이터 x를 압축해 z를 만들고, 이 압축된 z를 Latent Vector(입력 데이터의 중요한 정보가 압축되어 있음. Hidden Representation, Feature라고도 부름.)라고 부른다.
➡ 차원축소가 제대로 되었는지 검증을 하는 과정이 디코더. Latent Vector를 다시 디코딩하여 x' 출력
➡ 인코더로 들어가는 입력 데이터 x와 디코더가 출력한 데이터 x'이 같아지도록 Autoencoder Network를 훈련해야 함!(인코더는 차원축소, 디코더는 생성모델 역할)
차원축소(=Manifold Learning)의 목적
1. 데이터 압축
2. 데이터 시각화
3. 차원의 저주(Curse of Dimension) 피하기
- 데이터 차원이 늘어날수록 공간의 부피가 기하급수적으로 증가하며, 같은 개수의 데이터 밀도는 급격히 희박해짐
- 차원이 늘수록 데이터의 분포분석 또는 모델추정에 필요한 데이터 개수가 기하급수적으로 늘어나므로 데이터 활용력이 떨어짐
- 유용한 특징 추출
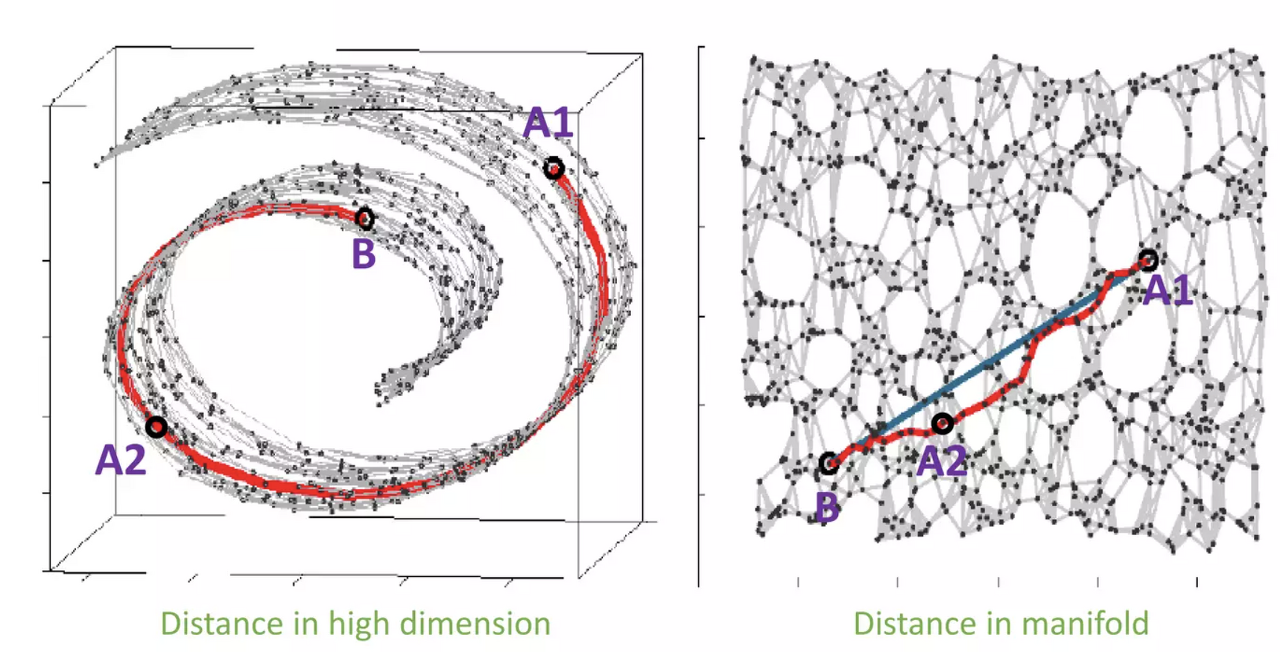
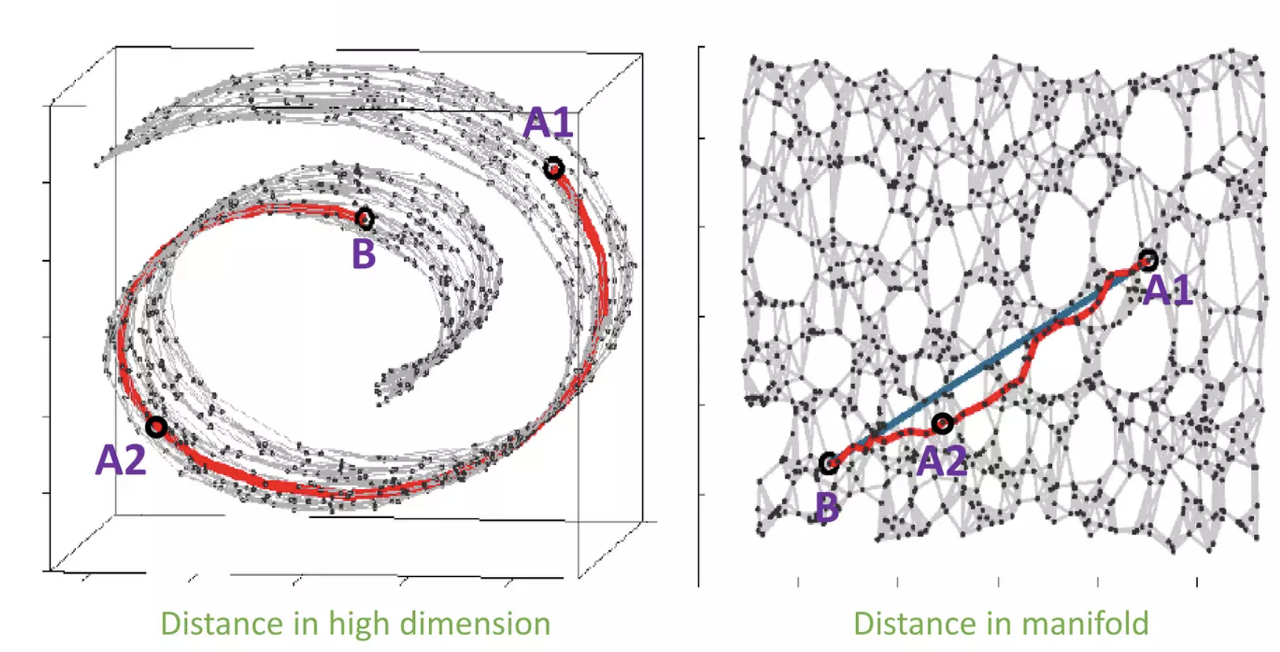
- Manifold(데이터가 있는 공간)를 찾았다는 것은 데이터에서 유용한 특징을 찾았다는 말과 같음.
| 고차원상 중앙값을 이용한 합성 | Manifold 안에서 중앙값을 구한 합성 |
|---|---|
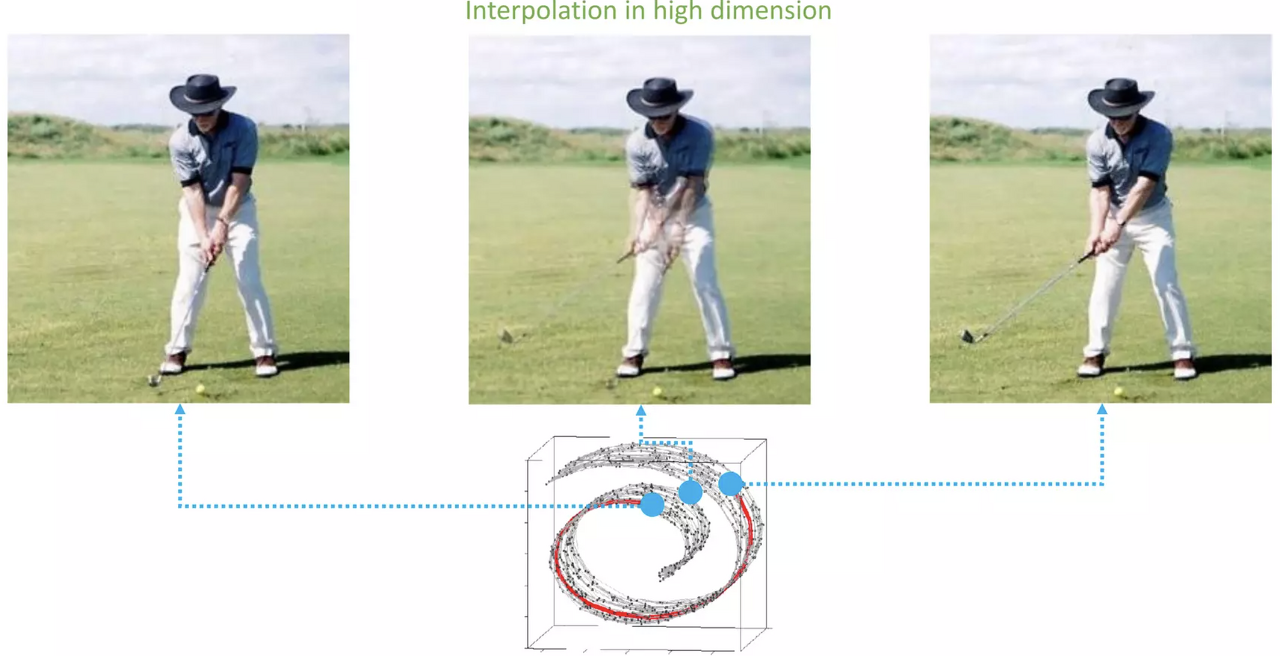 | 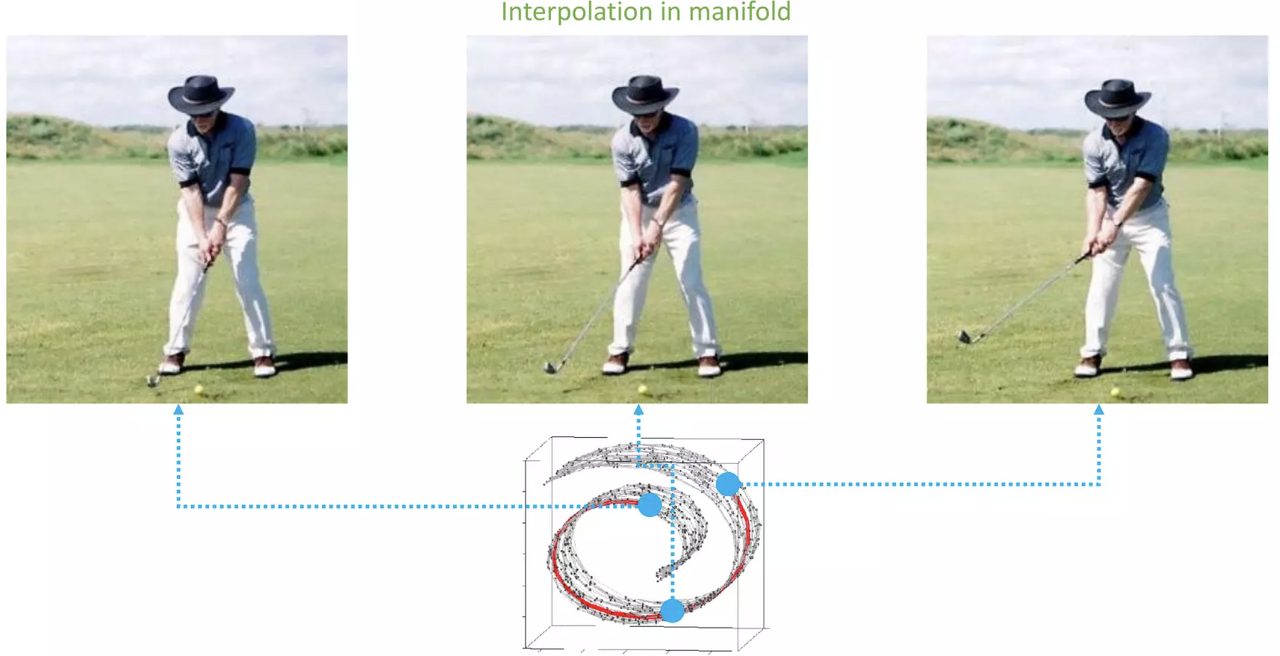 |
논리회로에서의 인코더, 디코더
-
디코더는 한마디로 정의해서 Minterm Generator(최소항 생성기)로, n개의 입력이 디코더로 들어가게 되면 개의 입력이 출력으로 나온다.

-
인코더는 디코더의 반대개념으로 개의 입력이 주어졌을 때 n개의 출력이 생성된다. 8개의 입력이 주어지면 각 입력은 인코더를 통해 암호화되어 출력으로 나가고, 이 암호화된 형태는 형태이다. 이를 디코더를 이용해 해독할 수 있다.
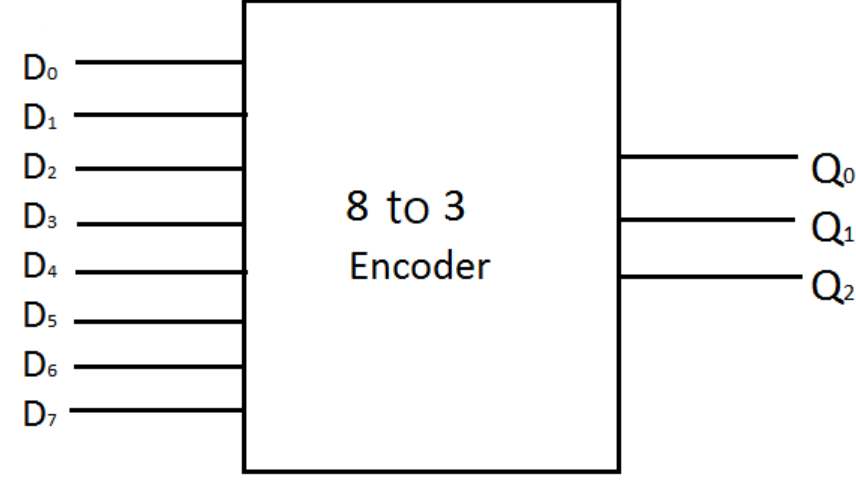
-
디코더와 인코더의 관계
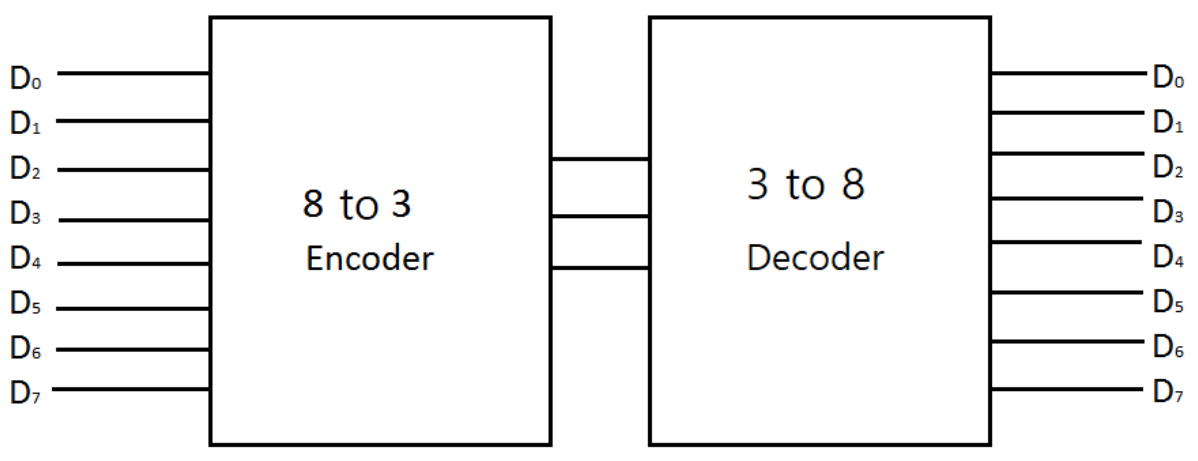
참고자료
Image Segmentation 이란? - 정의, 종류, 응용분야, 딥러닝, 트렌드
Semantic segmentation과 Instance segmentation의 차이
컴퓨터 비전 - 7. 오토인코더(AutoEncoder)와 매니폴드 학습(Manifold Learning)
