
2. 실전용 SQL 맛보기
2 - 1 데이터베이스 모델링
- 데이터베이스 모델링(Database Modeling은 테이블의 구조를 미리 설계하는 개념)
프로젝트에서도 데이터베이스 모델링이 잘 돼야 제대로 된 데이터베이스를 구축할 수 있음.- 데이터베이스 모델링(Database Modeling)이란 현실에서 사용되는 사물이나 작업을 DBMS의 데이터베이스 개체로 옮기기 위한 과정.
- (현실 세계)의 고객, 물건, 직원 등을 데이터베이스에 각각의 테이블이라는 개체로 변환 함.
(실체가 없는 '행동(Action)'도 테이블로 변환할 수 있음.)
데이터베이스 모델링에는 정답이 없다. 다만 좋은 모델링과 나쁜 모델링은 분명히 존재 함.
-
프로젝트를 진행하기 위해서는 대표적으로 폭포수 모델(Waterfall Model)을 사용
- 데이터베이스 모델링은 폭포수 모델의 업무 분석과 시스템 설계 단계에 해당
- 이 단계를 거치면 가장 중요한 데이터베이스 개체인 테이블 구조가 결정 됨.
-
프로젝트(Project)란 현실에서 일어나느 업무를 컴퓨터 시스템으로 옮겨놓는 과정
- (대규모 소프트웨어를 작성하기 위한 전체 과정)
- 소프트웨어도 절차에 따라 만들어야 함. 이러한 절차를 연구하는 분야가 소프트웨어 공학.
- 소프트웨어 개발 절차 중 하나로 폭포수 모델이 있다.
- 프로젝트 계획 -> 2. 업무 분석 -> 3. 시스템 설계 -> 4. 프로그램 구현 -> 5. 테스트 -> 6. 유지보수
- 장점 : 폭포수 모델은 각 단계가 구분되어 있어서 프로젝트의 진행 단계가 명확하다는 장점이 있음.
- 단점 : 문제가 발생할 경우 다시 앞 단계로 돌아가기가 어려움.
기본적인 용어와 정의
- 데이터(Data) : 단편적인 정보.
- 테이블(Table) : 데이터를 입력하기 위해 표 형태로 표현 한 것.
- 데이터베이스(Database, DB) : 테이블이 저장되는 저장소
테이블과 데이터베이스의 관계는 파일과 폴더랑 비슷한 개념 (데이터베이스 안에 테이블이 있다)- DBMS(Database Management System) : 데이터베이스 관리 시스템 or 소프트웨어
- 열(Column) : 테이블의 세로 (컬럼, 필드 라고도 함)
- 열 이름 : 각 열을 구분하기 위한 이름. (열 이름은 각 테이블 내에서는 서로 달라야 함)
- 데이터 형식 : 열에 저장될 데이터의 형식.
데이터의 형식은 테이블을 생성할 때 열 이름과 함께 지정 해줌- 행(Row) : 실질적인 진짜 데이터 (로우, 레코드 라고도 함)
하나의 행을 행 데이터라 하고 행의 개수가 데이터의 개수이다.- 기본 키(Primary Key) : 기본 키 열은 각 행을 구분하는 유일한 열
기본 키는 중복되어서는 안 되고 비어 있어도 안 됨. 또한 테이블에는 열이 여러 개 있지만 기본 키는 1개만 지정해야 하고 일반적으로 1개의 열에 지정 함- SQL(Structured Query Language) : SQL(구조화된 질의 언어)은 사람과 DBMS가 소통하기 위한 언어
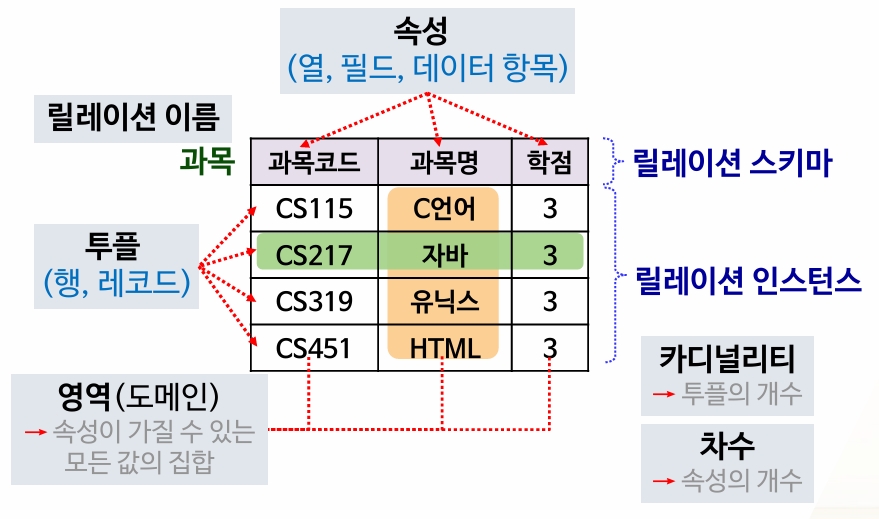
- 릴레이션(Relation) : 테이블을 의미 함. (행(튜플)과 열(속성)으로 이루어진 2차원 테이블 형태로 표현)
- 튜플(Tuple) : 릴레이션의 행을 의미 (하나의 레코드를 구성하는 데이터의 집합)
레코드(Record) : 튜플과 같은 의미로 사용. 데이터베이스에서 저장되는 데이터의 기본 단위- 필드(Field) : 릴레이션의 열을 의미 (하나의 속성을 구성하는 데이터의 단위)
속성(Attribute) : 필드와 같은 의미로 사용- 차수(Degree) : 속성의 개수
- 도메인(Domain) : 속성이 가질 수 있는 값의 집합
- 카디널리티(Cardinality) : 튜플의 개수
- 스키마(Schema) : 데이터베이스의 구조와 제약조건을 정의한 것. (데이터베이스의 전체적인 설계도를 의미)
- 인덱스(Index) : 데이터베이스에서 데이터를 빠르게 검색하기 위해 사용되는 자료구조. 데이터의 위치를 저장.
- 트랜잭션(Transaction) : 데이터베이스에서 수행되는 작업의 단위. 작업이 성공적으로 완료되거나 취소되어야 함
- 뷰(View) : 데이터베이스에서 사용자가 필요한 데이터만 추출하여 만든 가상의 테이블
- 관계(Relationship) : 두 개의 릴레이션 사이에서 데이터가 연결되는 방식을 의미
- 정규화(Normalization) : 데이터베이스의 구조를 개선하여 데이터의 중복을 제거하고 데이터의 일관성을 유지하는 과정
- 기본 키(Primary Key) : 테이블의 각 레코드를 고유하게 식별하는 필드 또는 필드의 집합. 프라이머리 키의 값은 테이블 내에서 유일해야 함.
- 외래 키(Foreign Key) : 한 테이블의 필드(또는 필드 집합)로서 다른 테이블의 프라이머리 키를 참조. 외래 키는 릴레이션 간의 관계를 정의하는데 사용.
하단에 세 개의 문단은 다른 교재 내용
키의 개념과 종류
- 튜플들을 유일하게 구별하기 위한 속성 또는 속성의 집합을 키(Key)라고 함.
키는 다음과 같은 성질을 만족함
- 유일성 : 키값으로 하나의 튜플을 유일하게 식별 한다.
- 최소성 : 키는 모든 튜플을 유일하게 식별할 수 있는 최소의 속성들로 구성된다.
관계형 모델에서 사용되는 키
- 슈퍼키(Super Key) : 키의 성질 중 기본 성질인 유일성을 만족하는 속성 또는 속성의 집합을 슈퍼키라고 함.
- 후보키(Candidate Key) : 슈퍼키 중에서 최소성을 만족하는 것.
모든 후보키는 슈퍼키지만 모든 슈퍼키가 후보키가 될 수는 없다- 기본키(Primary Key) : 후보키 중에서 DB설계자나 관리자에 의해서 기본적으로 사용할 키로 선택 된 것
- 대체키(Alternate Key) : 후보키 중에서 기본키로 선택되는 못한 것.
- 외래키(Foreign Key) : 다른 릴레이션의 기본키를 그대로 참조하는 속성 또는 속성의 집합을 의미. 이는 상호 관련이 있는 릴레이션 사이에서 데이터 일관성을 유지하기 위한 수단으로 사용
릴레이션의 개념과 특징 (릴레이션 = 릴레이션 스키마 + 릴레이션 인스턴스)
- 릴레이션은 릴레이션이 가지고 있는 모든 속성값의 모든 경우의 수에 대한 부분집합
- 릴레이션 스키마는 릴레이션의 이름과 속성으로 구성 되는 릴레이션의 논리적 구조 ( 시간과 무관하고 속성에 대한 타입을 지정 함)
- 릴레이션 인스턴스는 어느 한 시점에 릴레이션이 가지고 있는 튜플의 집합으로 삽입, 삭제, 갱신이 수행되며 시간에 따라 변하는 릴레이션의 값을 가리키는 것.
관계형 모델에서 릴레이션은 튜플의 집합이기 때문에 4가지 특징을 갖는다.
- 튜플의 유일성 : 하나의 릴레이션에는 중복되는 튜플이 없고 하나의 키값으로 하나의 튜플을 유일하게 식별.
- 튜플의 무순서성 : 한 릴레이션에 포함된 튜플들은 순서를 가지고 있지 않음.
- 속성의 무순서성 : 한 릴레이션을 구성하는 속성들 사이에는 순서가 없고 이름과 값을 쌍으로 구성.
- 속성값의 원자성 : 모든 속성의 값은 분해가 불가능한 하나의 값인 원자값만을 갖는다. (null값도 원자값으로 취급)
관계 데이터 모델의 제약 조건
- 데이터베이스 내에 저장된 데이터는 데이터의 의미를 보존하고 정확성을 유지하기 위해 일정 조건을 만족해야 하는데 이런 조건을 제약 조건(Constraints)이라 한다.
관계 데이터베이스 스키마에 명시할 수 있는 제약 조건은 모든 릴레이션 인스턴스들이 만족해야 하는 조건 4가지
- 도메인 제약 조건(Domain Constraints) : 각 속성 A의 값은 반드시 A의 영역에 포함되며 원자값이어야 한다.
- 키 제약 조건(Key Constraints) : 어떤 릴레이션에 속하는 서로 다른 두 튜플도 모든 속성에 대해서 같은 속성값을 조합으로 가질 수 없으며 적어도 하나의 키가 모든 튜플을 유일하게 식별할 수 있어야 함.
- 개체 무결성 제약 조건(Entity Integrity Constraints) : 어떠한 기본키값도 널값이 될 수 없다는 제약 조건. 기본키값은 한 릴레이션 내의 각 튜플을 식별할 때 사용되는데 기본키값이 널값이면 튜플을 식별할 수 없기 때문.
- 참조 무결성 제약 조건(Referential Integrity Constraints) : 한 릴레이션에 있는 튜플이 다른 릴레이션에 있는 튜플을 참조하려면 반드시 참조되는 튜플이 해당 릴레이션에 존재해야 하는 제약 조건. 이는 연관된 두 릴레이션의 튜플들 사이에 일관성을 유지하기 위한 것으로 외래키는 자신이 참조하는 릴레이션에 기본키값으로 존재해서 참조 가능한 값만 가져야 함.
2 - 2 데이터베이스 시작부터 끝까지
- 데이터베이스는 데이터를 저장하는 공간.
- 테이블은 2차원의 표 형태로 이루어져 있으며 각 열에 해당하는 데이터를 한 행씩 입력할 수 있음.
데이터베이스 구축 절차
1. 데이터 베이스 만들기 -> 2.테이블 만들기 -> 3. 데이터 입력,수정,삭제하기 -> 4. 데이터 조회/활용하기
-
데이터베이스 모델링이 완료되면 절차에 따라서 데이터베이스를 구축할 수 있음.
-
스키마(Schema)와 데이터베이스는 동일한 용어.
-
테이블을 생성하기 위해서는 설계가 필요
- 테이블을 설계한다는 것은 테이블의 열 이름과 데이터 형식을 지정하는 것.
-
Null은 빈 것을 의미, 널 허용 안 함(Not Null, NN)은 반드시 입력해야 한다는 의미
-
열 이름을 영문으로 만들 때 띄어쓰기는 하지 않는 것이 나음 (문법 불편해짐) -> 보통 언더바 ' _ '로 구분
-
INT : Integer의 약자로 소수점이 없는 정수를 의미하고 DATE는 연, 월, 일을 입력
-
기본키로 설정한 열이 기준이 되어 오름차순으로 자동정렬 됨.
-
SQL에서 데이터베이스를 활용하기 위해 주로 SELECT문을 사용하고 가장 많은 비중을 차지 함.
-
SELECT의 기본 형식은 SELECT 열이름 FROM 테이블이름 (WHERE 조건)이고 ' * ' 는 모든 열을 의미한다
-
커서가 있는 1개의 SQL문을 실행 시키려면 (Ctrl+Enter)
Ctrl + shift + Enter + (마우스 드래그) : 마우스 드래그한 영역에 쿼리문 실행 -
SQL은 대소문자를 구분하지 않음, SQL의 제일 뒤에는 세미콜론(;)이 꼭 있어야 된다고 기억하자 (가끔 없어도 된느 경우가 있긴 함)
-
여러 개의 열 이름을 콤마(,)로 구분하면 필요한 열만 추출 됨
정리
- 스키마는 MySQL 안의 데이터베이스를 말함. (데이터베이스와 동일한 용어로 생각)
- 데이터형식은 문자형(CHAR), 정수형(INT)등과 같이 열에 저장될 데이터의 형식을 말함
- 예약어는 SELECT, FROM, WHERE와 같은 기존에 약속된 SQL
- 기본키는 열에 지정하며 각 행을 구분하는 유일한 값
- 입력 : INSERT
- 수정 : UPDATE
- 삭제 : DELETE
- 조회 : SELECT
- 조건 : WHERE
CRUD - DML(데이터 조작어)
create - insert
read - select
update - update
delete - delete- 세미콜론(;) : SQL의 끝을 표시하는 기호
2 - 3 데이터베이스 개체
-
테이블은 데이터베이스의 핵심 개체다.
데이터베이스에서는 테이블 외에 인덱스, 뷰, 스토어드 프로시저, 트리거, 함수, 커서 등의 개체도 필요- 인덱스 : 데이터를 조회할 때 결과가 나오는 속도를 빠르게 해줌
- 뷰 : 테이블의 일부를 제한적으로 표현할 때 주로 사용
- 스토어드 프로시저 : SQL에서 프로그래밍이 가능하도록 해줌
- 트리거 : 잘못된 데이터가 들어가는 것을 미연에 방지 하는 기능
- 모든 데이터베이스 개체는 독립적으로 존재하는 것이 아니라 테이블과 상호 연관이 있음.
-
인덱스(Index) : 테이블을 조회할때 데이터가 많아질수록 결과가 나오는 시간이 늘어남
- 인덱스는 이런 경우 결과가 나오는 시간을 대폭 줄여줌
- 인덱스(Index)란 책의 제일 뒤에 수록되는 '찾아보기'와 비슷한 개념
- 인덱스는 이런 경우 결과가 나오는 시간을 대폭 줄여줌
인덱스는 열에 지정 함.
SQL의 마지막에 ON member(member_name)의 의미는 member 테이블의 member_name 열에 인덱스를 지정하라는 의미
- 인덱스 생성 전
- Execution plan(실행 계획) -> Full Table Scan (테이블 처음부터 끝까지 전체를 검색)
- 인덱스 생성 후
- Execution plan(실행 계획) -> Non-Unique Key Lookup (Key Lookup은 인덱스를 통해 결과를 찾음)
: 이런 방법을 인덱스 검색(Index Scan)이라 부름.
결과는 동일하지만 찾는 방법이 달라졌음 (인덱스 생성 여부에 따라서 결과가 달라지는 것은 아님)
- 뷰 : 테이블과 상당히 동일한 성격의 데이터베이스 개체
뷰(View)를 한마디로 정의하면 '가상의 테이블'
일반 사용자의 입장에서는 테이블과 뷰를 구분할 수 없음.
일반 사용자는 테이블과 동일하게 뷰를 취급하면 됨.
but 뷰는 실제 데이터를 가지고 있지 않으며 진짜 테이블에 링크(Link)된 개념이라 생각하면 됨.
-> 뷰는 실체가 없으며 테이블과 연결되어 있는 것. 뷰의 실체는 SELECT 문
- 테이블을 사용하지 않고 뷰를 사용하는 이유
- 보안에 도움이 된다
- 긴 SQL문을 간략하게 만들 수 있다.
- 스토어드 프로시저 : 스토어드 프로시저를 통해 SQL안에서도 프로그래밍 언어처럼 코딩을 할 수 있음.
프로그래밍 로직을 작성할 수 있어서 때론 유용하게 사용 됨.- 스토어드 프로시저(Stored Procedure)란 MySQL에서 제공하는 프로그래밍 기능
- 여러 개의 SQL문을 하나로 묶어서 편리하게 사용할 수 있음
- 연산식, 조건문, 반복문 등을 사용할 수도 있음.
- 스토어드 프로시저 만들기
-> 첫 행과 마지막 행에 구분 문자라는 의미의 delimiter //delimiter ; (스토어드 프로시저를 묶어주는 약속)
-> begin과 end 사이에 SQL 문을 작성
ex) create procedure myproc() : 스토어드 프로시저 이름 지정- 스토어드 프로시저 호출
-> Call 문을 실행
ex) call myproc();
- CREATE문과 DROP문
create(개체 생성문) : 개체를 생성할 때 사용하는 예약어
drop(개체 삭제문) : 개체를 삭제할 때 사용하는 예약어- 테이블, 인덱스, 뷰, 스토어드 프로시저 등의 데이터베이스 개체를 만들기 위해서는 CREATE 개체 종류 개체 이름 ~~ 형식을 사용
- 데이터베이스 개체를 삭제하기 위해서는 DROP 개체 종류 개체 이름 형식을 사용
-> ex)DROP PROCEDURE myProc
