머신러닝(Machine Learning)
인간의 학습 능력과 같은 기능을 컴퓨터에서 실현하고자 하는 기술 및 기법입니다.
기계 스스로 데이터의 특성을 학습하는 '기계 학습'이며 결국 최적의 매개변수 값을 찾는 문제이죠.
이 과정 중 기계가 데이터를 학습하는 방식에 따라 머신러닝의 종류가 나뉩니다.
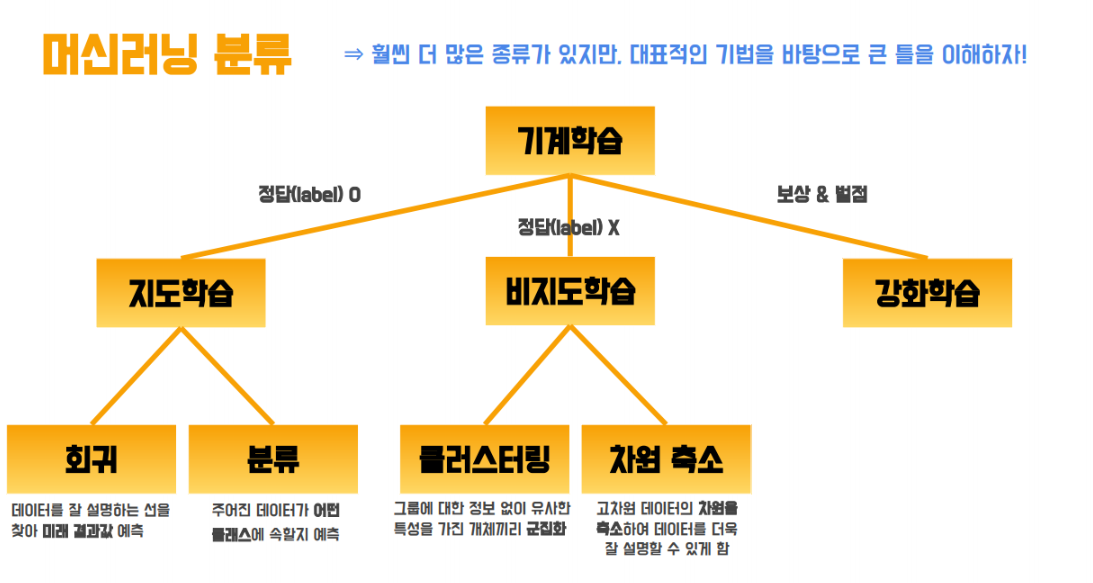
머신러닝 분류로는 두가지를 대표적으로 들 수 있는데,
바로 지도학습과 비지도학습입니다.
1. 지도 학습 (Supervised Learning) 이란?
-
정답이 주어진 상태에서 학습하는 알고리즘 (이미 분류가 존재한 상태에서 추가 데이터를 분류)
-
훈련 데이터(Training Data)로부터 하나의 함수를 유추해내기 위한 기계 학습(Machine Learning)의 한 방법
-
이렇게 유추된 함수 중 연속적인 값을 출력하는 것을 회귀분석(Regression)이라 하고 주어진 입력 벡터가 어떤 종류의 값인지 표식하는 것을 분류(Classification)라 합니다.
-
즉 지도학습의 목적은 회귀 생성(Regression)과 분류(Classification)라고 할 수 있습니다.
-
이를 달성하기 위해서는 학습기가 "알맞은" 방법을 통하여 기존의 훈련 데이터로부터 나타나지 않던 상황까지도 일반화하여 처리할 수 있어야 합니다.
2. 비지도 학습 (Unsupervised Learning) 이란?
-
정답이 주어지지 않은 상태에서 데이터의 특성을 학습하는 알고리즘 (분류가 안된 데이터들을 분류)
-
데이터가 어떻게 구성되었는지를 알아내는 문제의 범주에 속하는 기계 학습의 일종
-
이 방법은 지도 학습 혹은 강화 학습과는 달리 입력값에 대한 목표치(분류된 값)가 주어지지 않습니다.
-
비지도 학습은 통계의 밀도 추정(Density Estimation)과 깊은 연관이 있습니다.
-
데이터의 주요 특징을 요약하고 설명할 수 있습니다.

파이썬으로 이용 가능한 머신러닝 라이브러리는 여러가지가 있지만
이번 시간에는 싸이킷 런(Scikit-learn)이라는 라이브러리를 다뤄보도록 하겠습니다
scikit-learn이란?
-
scikit-learn은 2007년 구글 썸머 코드에서 처음 구현됐으며 현재 파이썬으로 구현된 가장 유명한 기계 학습 오픈 소스 라이브러리
-
아나콘다에서 기본적으로 제공하는 라이브러리 중 하나로
-
장점 : 라이브러리 외적으로는 scikit 스택을 사용하고 있기 때문에 다른 라이브러리와의 호환성이 좋다.
내적으로는 통일된 인터페이스를 가지고 있기 때문에 매우 간단하게 여러 기법을 적용할 수 있어 쉽고 빠르게 최상의 결과를 얻을 수 있습니다.
- 라이브러리의 구성은 크게 지도 학습, 비지도 학습, 모델 선택 및 평가, 데이터 변환으로 나눌 수 있습니다
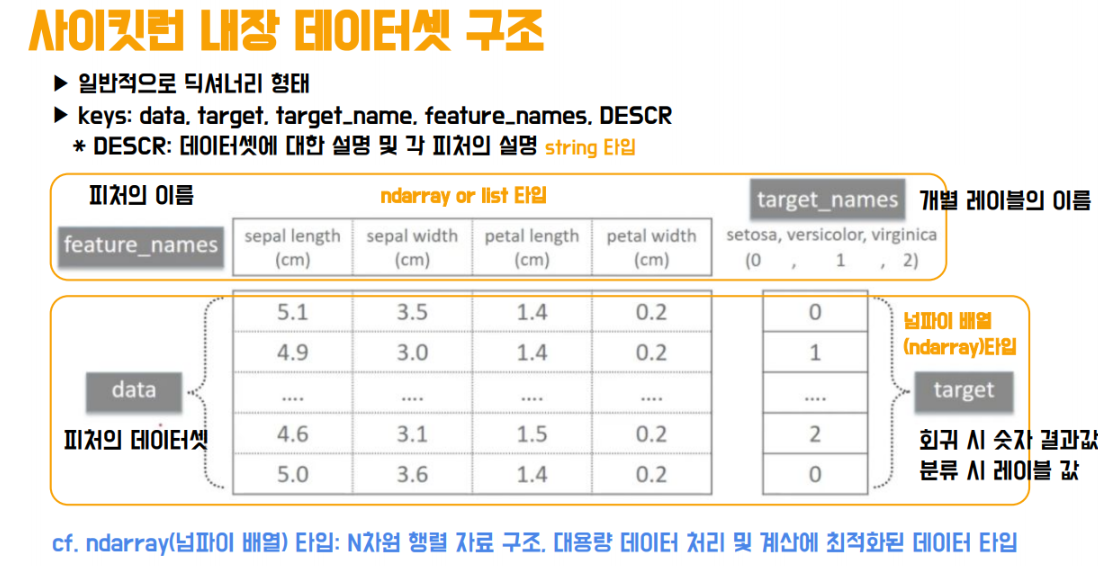
사이킷런에는 머신러닝에 사용할 수 있는 여러 내장 데이터셋들이 있는데
저희는 그 중 붓꽃 데이터를 사용해보도록 하겠습니다.
붓꽃 품종을 예측해봅시다😀
데이터 셋은 사이킷런의 iris 붓꽃 데이터셋을 이용했으며
꽃잎의 길이, 너비, 꽃받침의 길이, 너비를 이용해 붓꽃 데이터의 품종을 분류(Classification)하는 문제입니다.
데이터를 분류하려면 아래와 같은 프로세스를 거칩니다
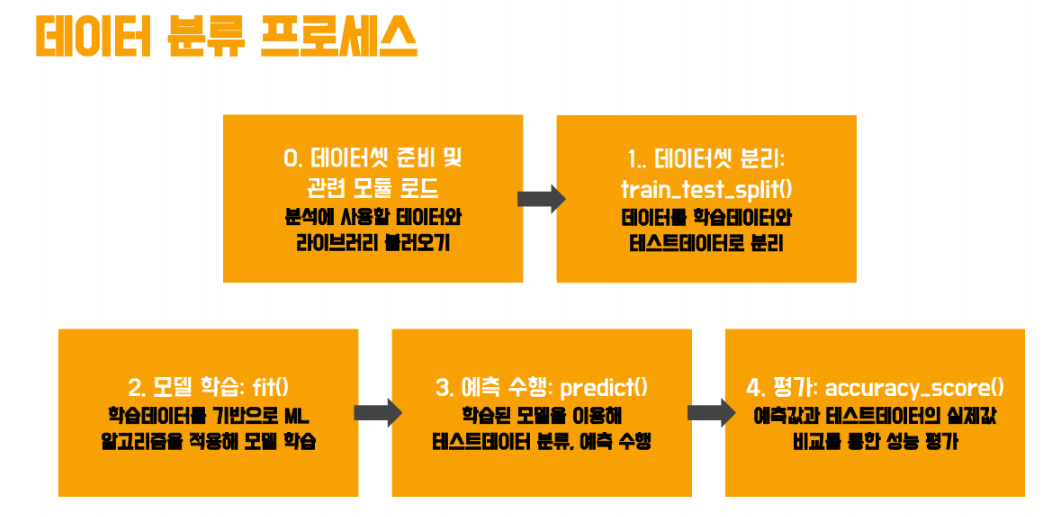

- 데이터 셋 준비 및 관련 모듈을 로드해줍니다
(분석에 필요한 데이터와 라이브러리가 필요하겠죠?)

- 데이터 셋을 분리해줍니다
(사용할 데이터셋 중 학습용/ 테스트용 데이터를 어느정도 비율(test size)로 나눌지 결정하는 코드입니다. random_state는 난수 값을 결정하기 위해서 사용합니다)
- 모델을 학습시킵니다
머신러닝 분류 알고리즘 중 의사 결정 트리를 이용하였습니다

그리고 모델을 학습시키기 위해 생성된 분류 알고리즘 객체에 fit 메소드를 이용해 학습을 수행합니다

- 이후 예측을 수행합니다
학습 데이터가 아닌 다른 데이터인 테스트 데이터를 사용합니다

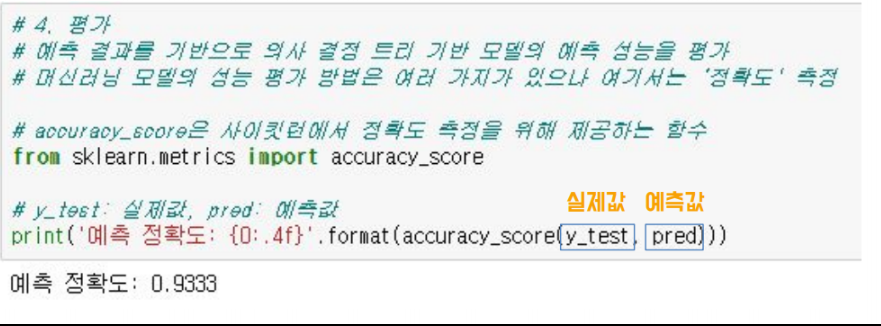
- 마지막으로 평가를 수행해줍니다
머신러닝 분류 모델의 성능 평가 지표 중 Accuracy(정확도)를 이용하겠습니다
