확률
맞지도 않고 틀리지도 않는 모호함을 다루는 언어가 바로 확률 불확실성의 언어
좀 더 나은 선택을 할 수 있게 도움이 되는 언어
데이터 분석가와 확률
버튼 색을 바꾸면 클릭률 올라갈 확률 - a/b테스트
추천시스템(머신러닝) 도입시 성공할 확률
이번 달 목표매출을 넘길 확률
<<<확률을 모른다면 데이터 분석 자체가 하기가 힘들다>>>
왜??? 데이터 분석가는 전략을 내세울 때 내 설득을 구체적인 수치화로 알려줘야 한다
사건/ 표본 공간
표본=샘플, 일부
결과: 실제로 관측이 된 딱 하나의 경우
사건: 그 결과들이 모여있는 집합/"어떤 조건을 만족하는 결과들의 모음(부분집합)”
표본 공간: 일어날 수 있는 모든 경우의 전체! 공간이니까 주로 {}로 표현
사건은 지도의 한 점
표본 공간은 지도전체의 모든 경우의 수

예시
구슬뽑기
사건 빨강 뽑기/(or) 하양뽑기
표본공간:{빨강,하양}
사건도 2개고 표본 공간도 2개의 결괏값만 가지는게 아니나?
표본 공간: {아이스/핫} {tall/grande} {샷추가/미추가}
사건 실제 선택 1개
표본 공간=가능한 메뉴 전체
분석가는 모든 경우의 수(표본 공간)를 정의하고 ->
실제 일어난 사건을 보고
-> 가설을 세워야한다.
즉 목표가 생기는 것
:표본 공간(모든 경우의 수: 확률의 첫 단추)를 잘못 정의하면 결론 왜곡이 됨
구매한 고객만 표본 공간에 넘으면 미구매 고객은 무시 내가 하는 분석이 많이 틀어지게 돼 신뢰 할 수 없음
분석하는 시간보다 분석 전 시간이 더 오래 걸림
그거를 보고 여러가지 문제점에 대한 가설을 적용해서 전략을 잘 짜기 위해선 확률을 잘 알아야한다.
첫 단추를 잘 못 끼우면 조건부 확률,독립성, 추론 전부 틀어짐
확률 p(A):사건 A가 일어날 확률
사건을 숫자로 표현하는 것
불확실한 사건이 일어날 가능성을 0~1 사이의 숫자로 나타냄
0=절대 불가능
1=절대 확실
그 사이= 가능성의 크기
이러한 확률의 값으로 데이터 분석가는 타깃팅 전략을 실시한다.
마케팅 팀: 30대 여성 고객 쿠폰 클릭 확률 12%
영업 팀: 20대 남성 고객의 쿠폰 클릭 확률 7%
데이버 분석가는 이 대상을 가지고 올릴까? 어떤 걸 서비스 개선을 빨리하냐?
즉 우리가 서비스를 개선할 거에 대한 서비스 리스트 업은 너무 많으니 이 우선 순위를 전략으로 짜줘야한다
전략을 짜주기위해 확률이 필요하다
확률 0.9 무조건 일어난다?(x)
확률 0은 절대 불가능 한건가??(x)
키가 170.0000이 있을 순 있으나 확률 0은 너무 너무 희박하다라는 얘기
아예 무조건 일어날 확률도 애매....
확률은 사건이 일어날 가능성의 크기를 숫자 백분율로 표현한것 (수치화)
보장도 예언도 아니다.
큰 수의 법칙(대수의 법칙)
표본이 너무 적으면 (즉 일부의 양(크기)가 너무 적으면) 요동이 너무 큼
표본의 양(크기)가 크면 평균에 가까워짐
(표본이 작으면 표본오차가 커져 결과가 요동한다.
표본이 커질수록 표본 평균(또는 비율)은 **모집단의 기댓값(확률
𝑝
p)
예시)
하루 맑음/비 일년 평균 강수량은 일정
주식 투자:하루 수익률을 널뛰지만, 장기 평균을 안정
확률 변수 : 어떠한 사건을 숫자나 값으로 바꿔 표현하는 것
-> 이걸 가지고 값들을 평균을 구하든 중앙값을 구하든 연산을 하기위해 바꿔야한다. 이거에 대한 데이터가 머신러닝에서 학습데이터로 사용하기 위해선 글자/텍스트들을 숫자로 바꾸어주어야만 컴퓨터가 이해를 하고 학습을 할 수 있다.
사건 데이터를 저장하기 위해 숫자로 바꾼다
이산형 확률 변수/ 연속형 확률 변수
이산형 변수에 확률이 들어난 것/ 연속형 변수에 확률이 들어난 것
확률 분포
확률의 흩어짐 정도
확률 분포란 어떠한 값이 자주 나오는지를 불확실성이 어떻게 퍼져있는지를 보여주는 것
이산형 분포
값이 뚝 뚝 떨어져있으니까 막대그래프로 그런 것
연속형 분포
예시
시험 점수 60-70에 몰림
키:170 부근에 많고 150,190은 드묾-> 종모양
배달 앱 주문 금액: 대부분 1~2만원, 가끔 20만원이 넘는 긴 꼬리 분포

숫자만 보이면 안 보이더 숲의 모양이 나타남
기댓값
주사위를 무수히 많이 던지면 평균적으로 몇이 나올 까? 3.5점
주사위의 눈이 1,2,3,4,5,6
기댓값이라 하는 아이가 소수점???
오랫동안 반복했을 때 수렴하는 값, 확률적으로 기대되는 평균값 평균값
즉 샘플 표본크기가 클수록 평균이 기댓값에 가까워짐
기댓값은 가장 그럴 듯한 평균 수준
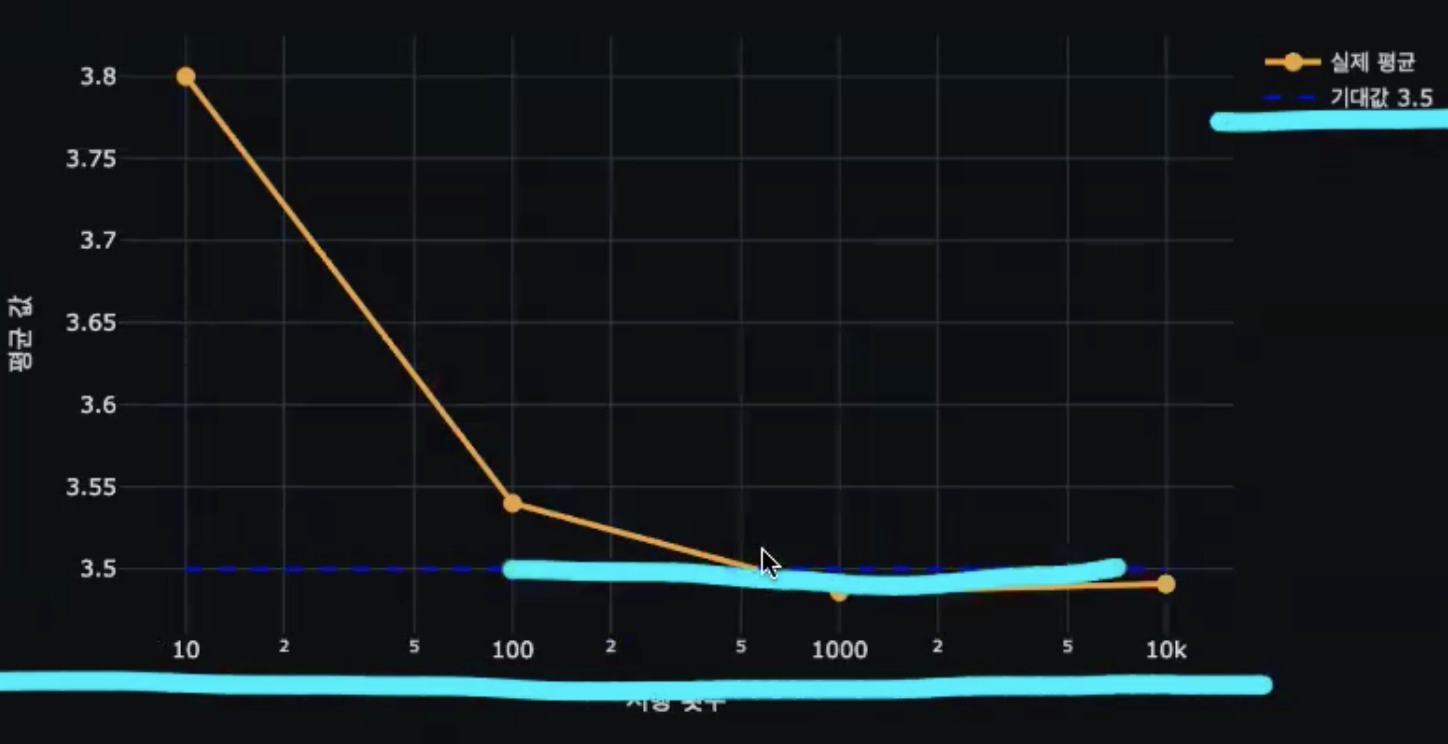
기댓값은 실제로 항상 나오는 값일까요? (x)
왜? 항상은 아니지만, 평균에 수렴한다고는 했지만 주사위가 3.5라는게 나올 수 있나?
기댓값은 미래를 정확히 예언합니까?(X)
많은 시도를 했을 때 즉 표본의 크기가 충족되었을 때 그거의 평균
기댓값은 한번의 결과가 아니라 많은 시도의 평균을 의미한다.
기댓값은 이다
-> 하지만 단기 불확실성은 따로 고려해야한다.(분산,표준 편차로 보완)
이 수치를 보았을 때 이미 쌓여온 데이터(히스토리 경험)를 보고 개선을 어떻게 해야할지 고민을 해야한다.(평균 뿐만 아니라 표준편차 분산도 같이 봐야함)
조건부 확률과 독립성
이러한 확률에 대해 조건이 붙으면 확률이 달라진다.
조건 하나로 확률값이 달라진다.
갑자기 시험본다 커피를 마실 확률이 높아지는 것처럼
독립성
: 조건을 줘도 변하지 않는다. =독립적
주사위를 굴렸을 때 동전이 앞면이 나올 확률은 같다 즉 동전과 주사위는 서로 독립
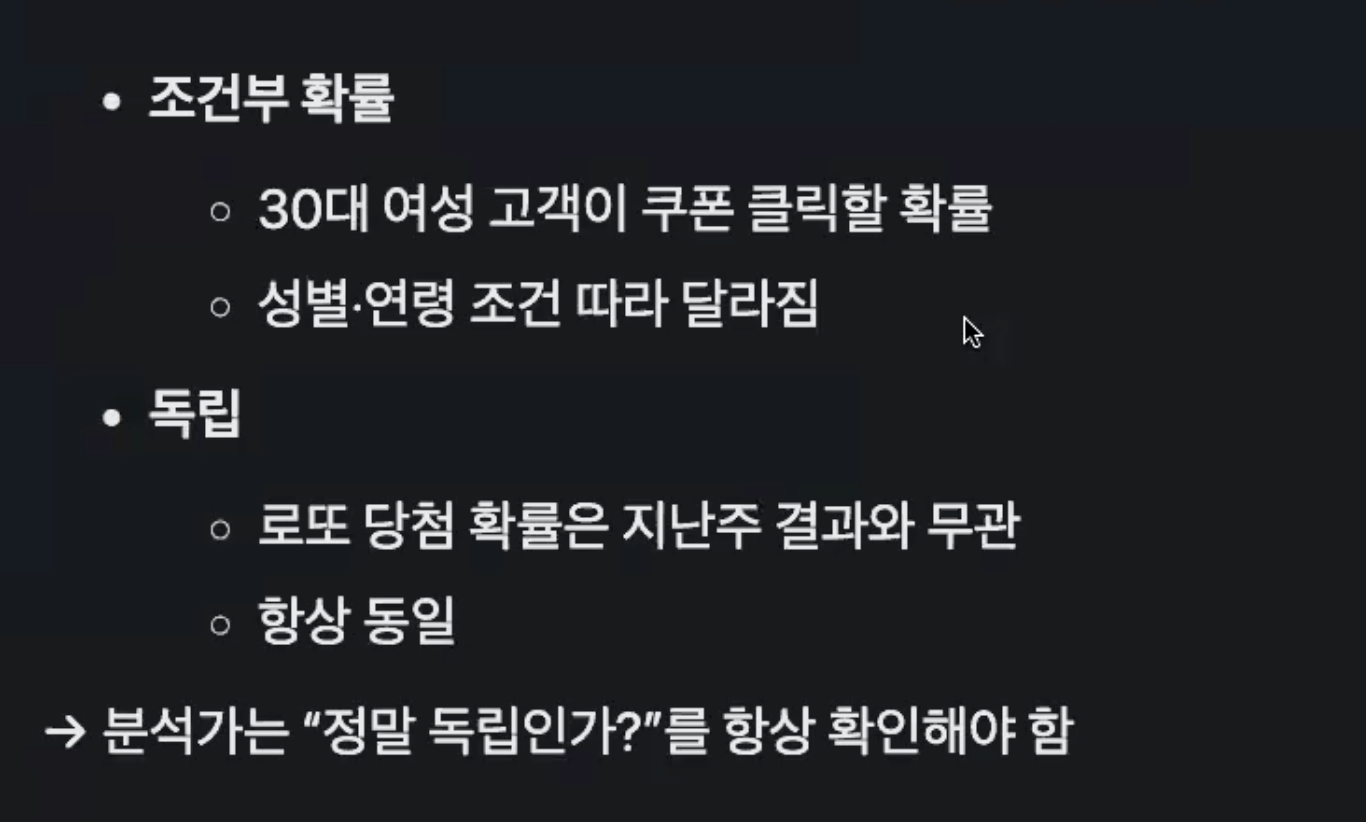
분석가는 정말 독립인가(조건인지를 독립인지를)를 항상 확인해야함
어떠한 변수가 있는데 다른 변수의 영향을 받는지 아닌 지에 대해서도 알고 있어야함
독립을 유지하다가 어떠한 특수한 케이스에서 깨졌다고 하면 그게 분석의 포인트가 될 수있다.
어떠한 이벤트가 발생했다는 거니까 그 이벤트를 찾아야한다.
현실데이터는 대부분 독립이 아니다. 아니면 원래 독립이지만 환경때문에 깨질 수 있음
그래서 분석가는 늘 정말 독립일까라는 질문을 습관처럼 던져야한다.
예) 갑자기 운동선수가 잘한다? 뭐때문인지를 생각해봐야한다.

어떤게 사건인지에 따라 방향이 달라진다.
이걸 잘 고민해서 판단해야한다.
숫자엔 모양이 있다.
정규분포
서로 다른 단위를 공정하게 비교해주는 표준화(Z점수)
숫자더미->종모양(정규)-> z로 비교
Q. 우리 반 키에서 180cm 얼마나 드문가?
Q. 국어 80점 vs 수학 85점, 어디가 더 잘 본 거임??
-> 이 질문에 답하는 언어가 바로 정규 분포와 Z점수
이론적 확률분포&파라미터
확률분포라는 지문을 보면 집단의 특징이 나타남
숫자 더미만 보면 복잡하지만 분포와 파라미터를 보면 성격이 보인다.
파라미터θ: 분포의 모양을 정하는 상수(미지)

파라미터=지도 설명서
축적, 방향 표시없으면 지도 해석 불가
평균과 표준편차가 없으면 분포 해석 불가
확률분포는 데이터 집단의 지문
파라미터(뮤,시그마)는 그 지문을 읽게해주는 설명서이다
정규분포

Q 왜 종모양이 흔하냐?
원시데이터를 보았을 때 많은 작은 요인들이 합쳐질 때 자연스럽게 종 모양 발생
숫자 원시데이터가 어떠한 특징 특성을 두개의 파라미터로 알수 있다.
모수는 파라미터!! 비모수는 파라미터가 아닌다 거기에 따라서 검정하는 방법이 다르다
Q. 모수 즉 파라미터가 있다는 정규분포는 모수인가 아닌가?
정규분포는 모수이다.
모수냐 비모수냐를 나누는 여러가지가 있는데 그 중 정규분포가 맞냐 아니냐로 보는 것이 있다.
표준분포에서 벗어나는게 불량일 수 있다.
68,95,99
대부분 데이터는 평균 근처에 몰리고,멀리 벗어날 수 있도록 드물다.
68.95,99법칙:
흔한 값과 드문값을 빠르게 가르는 직관적 기준
내가 알고 싶은 값이 어디에 있냐?
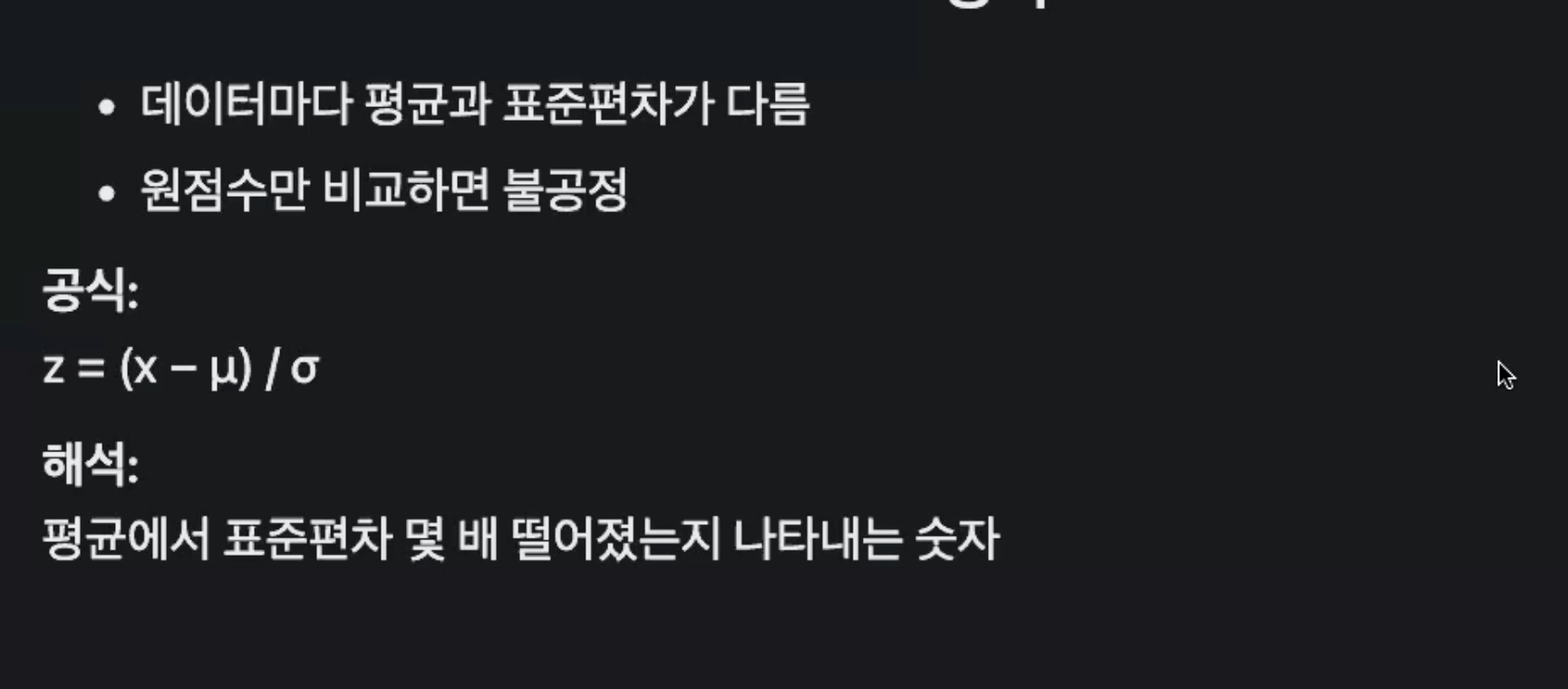
Z점수: 평균에서 표준편차 몇 배 떨어졌는지 나타내는 숫자(표준화 점수)
-> 정규분포일 떄 직관적

Q 절대적이 우열은 아니다? 정규가 아닐 경우 떨어진다 뭐가?
정규분포는 강력한 무기
Z 값은 평균에서 표준 편차 몇 배 떨어졌는가를 보여주는 공정한 눈금자.
->단위가 달라도 분포가 달라도 가능함
무엇이 정규인가? 비정규인가?

극단적인 그래프가 있을 수있다.
예를 들어 놀이터의 평균 연령은 30살이라하자 평균은 30살인데 실제 연령대는 어린아이가 오고 보호자 분들이 온다.

