작성 계기
어젯밤, 친구에게로부터 과제 도움 요청을 받았다. 평소에 친구들 과제 도와주는 것을 좋아하던 터라 흔쾌히 도움을 주겠다고 했고, 들어본 적은 있지만 사용해본 적은 없는 R 언어와 Selenium이라는 프레임워크를 이용한 과제였기에 흥미로워 도움을 주는 것이 재미있을 것 같았다.
그리고 이 포스팅을 하면서 문제 해결을 했던 과정들을 남겨보려고 한다. 내가 R 언어로 쓰인 코드를 이번 과제를 도와주면서 처음 봤음에도 불구하고 문제 해결에 도움을 줄 수 있었던 이유는 아무래도 문과생인 친구보다는 컴퓨터 공학을 공부한 내가 문제가 되는 코드 한 줄을 찾는 과정과 노하우를 더 잘 알기 때문이다. (나도 초보 수준이긴 하지만,,)
학창시절, 친구들의 코딩 과제를 도와주면서 느낀 것이 있는데 코딩을 처음 해보는 친구들 중 처음부터 잘하는 친구들도 있긴 했지만 대부분은 자신이 작성한 코드에 문제가 생기면 어디서부터 문제가 시작되는 지를 잘 파악하지 못했다는 것이다. 그러다 보니 문제 해결을 위한 검색도 더 넓은 범위에서 시작하게 되어 해결에 오랜 시간이 걸리는 것 같다. 내가 이번 포스팅에서 강조하고 싶은 것은 문제의 시작점을 찾기 위해 문제가 발생된 영역을 점점 좁혀 나가는 방법이다. 비록 초보적인 수준이긴 하지만 코딩을 접한지 얼마되지 않은 사람들에게는 충분히 도움이 될 수 있을 것 같다.
문제 설명
필요 배경 지식
문제를 설명하기 전에 R 언어와 Selenium이 무엇인지에 대해서 먼저 설명이 필요할 것 같다. 내가 과제 도움 요청을 받기 전에도 R과 Selenium에 대해서 들어본 적은 있기 때문에 대충은 알고 있었다. 아래의 설명은 내가 아는 선까지만 얘기를 하고 자세한 설명과 정의는 WIKI백과를 이용하거나 검색을 하여 찾기를 바란다.
R 언어 : 주로 통계 및 데이터 분석에 자주 사용되는 언어, 스크립트 언어라 굳이 컴파일을 안해도되고 한줄한줄씩 실행해서 결과를 볼 수 있다.
Selenium : 웹페이지를 방문하여 웹페이지의 조작을 자동화 해주는 소프트웨어 프레임워크. 웹 페이지에서 데이터를 자동으로 수집하는(이것을 웹 크롤링이라고도 한다.) 프로그램을 만드는 데 사용될 수도 있고, 어떤 사람은 Selenium을 사용해 잔여백신을 자동으로 확인해주는 프로그램을 만든 것도 본 적이 있다.
문제 상황
친구가 하려던 과제는 R 언어와 Selenium을 활용해 Youtube 웹페이지를 방문하여 동영상의 제목, URL, 조회수, 댓글수 등의 데이터를 모아서 하나의 csv 파일에 쓰는 것이었다.
Code 분석
문제를 찾아달라는 코드는 아래와 같았다.
for(i in 1:length(trending_yt$URL)){
remDr$navigate(trending_yt$URL[i])
Sys.sleep(10)
page <- remDr$getPageSource()[[1]]
html <- read_html(page)
channel <- html %>% html_node(xpath='//*[@id="text"]/a') %>% html_text()
subscriber <- html %>% html_node(xpath='//*[@id="owner-sub-count"]') %>% html_text()
view <- html %>% html_node(xpath='//*[@id="count"]/ytd-video-view-count-renderer/span[1]') %>% html_text()
date <- html %>% html_node(xpath='//*[@id="info-strings"]/yt-formatted-string') %>% html_text()
comment <- remDr$findElement(using = "xpath", '//*[@id="count"]/yt-formatted-string')$getElementText()[1][[1]]
trending_yt$Channel[i] <- ifelse(str_detect(channel, "[[:alnum:]]"), channel, NA)
trending_yt$Subscriber[i] <- ifelse(str_detect(subscriber, "[[:alnum:]]"), subscriber, NA)
trending_yt$View[i] <- ifelse(str_detect(view, "[[:alnum:]]"), view, NA)
trending_yt$Date[i] <- ifelse(str_detect(date, "[[:alnum:]]"), date, NA)
trending_yt$Comment[i] <- ifelse(str_detect(comment, "[[:alnum:]]"), comment, NA)
}
trending_yt
write.csv(trending_yt, file="trending_yt.csv", row.names = F)
문제를 해결하기 전에 대략적인 코드 해석이 필요할 것으로 보인다.
-
1. remDr
익숙하지 않은 코드에 당황하기도 했지만, 차근차근보면 remDr이라는 객체가 웹 페이지를 방문하고 데이터를 받아오는 역할을 하는 것을 알 수 있다. (검색해서 찾아보니 remDr은 remote Driver란 뜻이고 RSelenium 라이브러리에 포함이 되어있는 친구였다.)
-
2. Sys.sleep(10)
처음보는 언어라도 sleep는 어느 언어에서든 의도적으로 지연을 주기 위해서 사용되므로 10초간 지연을 의도적으로 준 것이라고 해석할 수 있다. 아마도 Youtube에 웹 페이지 요청을 과도하게 빠르게 보내는 것을 방지하고 웹 크롤러가 블락 당하는 것을 방지하기 위해서 사용된 것으로 보인다. 추가로 for문 안에 이 sleep 함수가 존재하기 때문에 만약에 코드가 정상적으로 실행이 된다면 실행하는데 오랜 시간이 걸릴 것이다. 에러를 찾는데 힌트가 된 부분이기도 하다.
-
3. page, html
remDr이란 객체의 getPageSource라는 함수를 통해서 page의 소스를 얻어온 부분이다. 그리고 얻어온 page 소스를 html로 읽어 html이라는 객체에 저장한다.
-
4. channel, subscriber, view, date, comment
각 객체에는 위에서 얻은 html이란 객체에서 channel 정보, 구독자 정보, 조회수, 날짜, 댓글수를 찾아서 저장한 것이다. 아래에서 얘기하겠지만 문제가 생긴 부분은 일단 댓글수인 comment이다.
-
5. trending_yt
4번까지 이해가 갔다면 trending_yt는 일종의 Dataframe이라고 할 수 있다. 그러니까 trending_yt$Channel[i]...로 시작하는 코드는 trending_yt의 Channel이라는 컬럼의 i번째 행에 channel이라는 객체(text)를 넣겠다는 의미이다.
-
6. write.csv
마지막으로 trending_yt라는 Dataframe을 csv 파일에 쓴다.
문제 상황 설명
문제 상황에 대한 이야기는 2가지이다. 말해준 순서대로 얘기를 해보면
① 댓글수를 받아오는 부분(comment <- remDr$findElement...)이 어쩔 때는 실행이 되고 어쩔 때는 실행이 안된다.
② trending_yt라는 Dataframe을 csv 파일로 쓸 때, for문에서 trending_yt에 추가한 컬럼들은 제외가 되었다.
친구의 말로는 상황①이 언제는 되고 언제는 안된다고 하여 ②부터 진행을 하고 있다고 하여 나도 그 문제부터 해결하고자 시도해보았다.
문제 해결 과정
메신저로만 문제 상황을 잘 설명하는 것은 쉽지 않다. 게다가 에러 로그를 요구했더니 ①번 상황은 에러 메세지가 뜨지만 ②번 상황에서는 아무런 메세지가 뜨지 않는다고 한다.. 그래서 차라리 전체 실행 과정을 모두 보여달라고 했다. Google Meet를 활용하여 화면공유를 통해 실행과정을 볼 수 있었다. 친구가 말한대로 ①댓글수를 받아오는 부분에서 에러 메세지가 뜨기는 했으나 다음 코드를 계속 실행할 수 있었다.
여기서 이상한 점은 for문 안에는 Sys.sleep(10)이라는 함수가 사용되고 있는데 for문 실행이 굉장히 빨리 끝났다는 것이다. Dataframe의 행의 개수가 159개라는데, 그러면 실행하는데는 적어도 159x10초 이상, 대략 25분 이상이 걸려야 하는 것인데 그렇지 못했고 for문이 정상적으로 실행이 되지 않았다는 것을 예상할 수 있었다.
그래서 for문 안에서 에러 메세지를 출력했던 댓글수를 받아오는 부분을 지워보고 실행해보라고 했다.
예상했던 대로 댓글수를 받아오는 부분을 지우고 실행해보니 실행 시간 중 사담을 나누고 있을 정도로 오래 걸렸다.(한 30분? 걸렸던 것 같다.) 그리고 생성된 csv 파일에도 Comment 컬럼을 제외한 나머지 컬럼들이 정상적으로 write되어 저장이 되었다. 즉 write.csv 함수는 문제가 없다는 것을 알 수 있다. for문 같은 경우, for문 안에서 댓글수를 받아오는 부분에서 에러가 생기다보니 for문 전체가 실행이 안되었던 것이다.
그러면 문제를 좁힐 수가 있다. 위의 코드에서 아래의 댓글수를 받는 부분만 문제가 있는 것이라고 할 수 있다.
comment <- remDr$findElement(using = "xpath", '//*[@id="count"]/yt-formatted-string')$getElementText()[1][[1]]확인해본 에러 메세지는 아래와 같다.
Selenium message:no such element: Unable to locate element: {"method":"xpath","selector":"//*[@id="count"]/yt-formatted-string"}
(Session info: chrome=96.0.4664.93)
For documentation on this error, please visit: https://www.seleniumhq.org/exceptions/no_such_element.html
Build info: version: '4.0.0-alpha-2', revision: 'f148142cf8', time: '2019-07-01T21:30:10'
System info: host: 'LAPTOP-NBG0LFLD', ip: '192.168.219.103', os.name: 'Windows 10', os.arch: 'amd64', os.version: '10.0', java.version: '1.8.0_311'
Driver info: driver.version: unknown
Error: Summary: NoSuchElement
Detail: An element could not be located on the page using the given search parameters.
class: org.openqa.selenium.NoSuchElementException
Further Details: run errorDetails method
친절하게도 에러에 대한 문서화가 되어 있어 있다.
https://www.seleniumhq.org/exceptions/no_such_element.html
페이지를 방문해보면 아래와 같이 문제의 원인에 대해서 설명해준다. "No Such Element"라는 에러를 마주했으니 그 부분을 보면 된다.
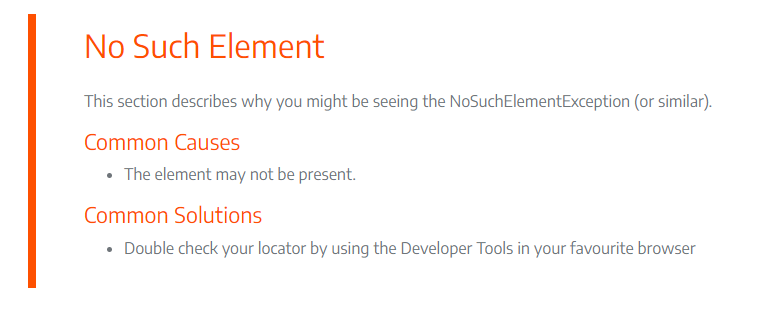
결국 element가 없어서 생긴 문제이며 해결 방안으로는 locator를 한번 더 확인해보라는 것이었다.
코드에 사용된 locator의 내용은 '//*[@id="count"]/yt-formatted-string'이다. 아래와 같이 개발자 도구(웹페이지에서 F12 키를 누르면 된다.)를 사용해서 locator를 확인할 수 있다. (xpath를 사용해서 Copy XPath 버튼을 클릭하면 클립보드에 복사가 된다.)
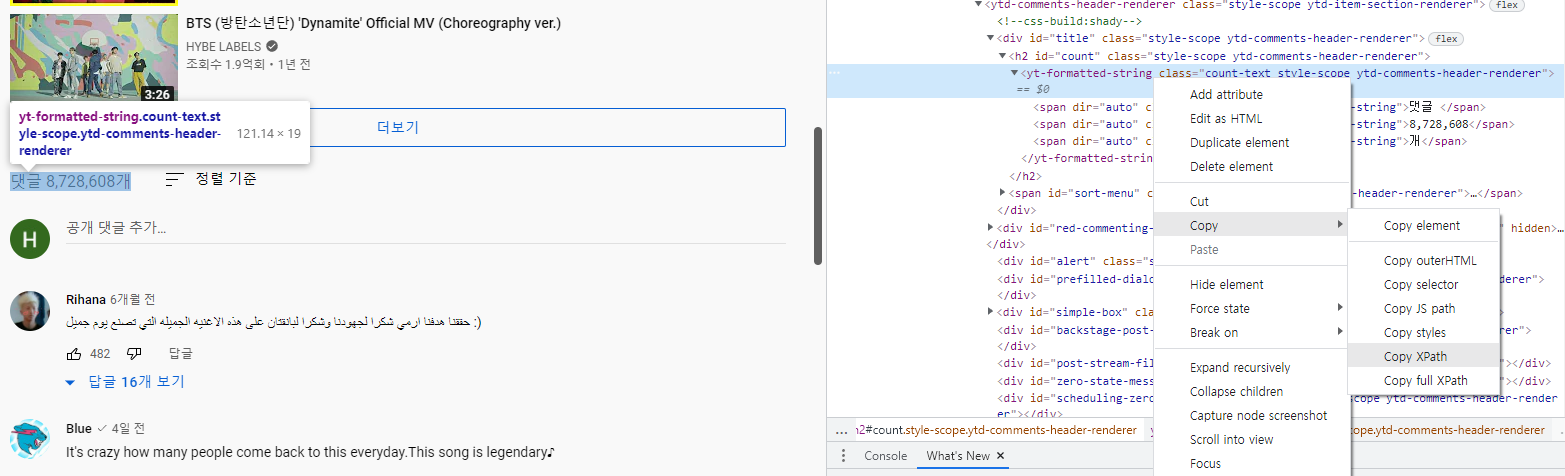
확인해본 결과 locator가 //*[@id="count"]/yt-formatted-string로 코드에 사용된 것과 같았다. 그러면 locator는 문제가 없다는 것을 알 수 있다.
힌트는 어떨 때는 잘 동작하다가 어떨 때는 또 에러 메세지를 출력한다는 것이다. 어떻게 보면 코드 문제라기 보다는 웹페이지의 소스가 유동적으로 변하다보니 생길 수 있는 문제라고 생각했다. 그러면 Locator의 내용이 유동적으로 바뀔 수도 있는 것이라고 예상할 수 있다.
그래서 직접 유튜브 웹페이지를 방문하여 Locator를 확인해보았다. 웹 페이지를 방문하자마자 F12 키를 입력하여 개발자 도구를 열고, Ctrl+F 키를 눌러 찾기를 한 다음에 XPath locator를 입력하였는데 XPath를 찾지 못하는 경우가 있었다.
그래서 개발자 도구를 이용해서 댓글수의 Locator를 다시 찾아보았다. 아래의 이미지 좌측 상단에 커서와 사각형 모양이 합쳐진 버튼을 사용하고 페이지에 커서를 옮겨 놓으면 소스에 관련된 Element가 어디있는지 찾아준다.

찾아서 다시 Locator를 확인해보니 //*[@id="count"]/yt-formatted-string로 똑같았다. 그래서 실수했나 하고 다른 유튜브 동영상 웹 페이지를 방문했는데, 여기서 문제 원인을 확실히 알게 되었다. 결론은 유튜브 동영상 웹페이지를 처음 방문하면 댓글에 대한 Element가 다 같이 로드되지 않기 때문이었다. 이것을 유튜브 페이지를 방문해보면서 스크롤 다운을 하니 아주 잠깐 동안 아래와 같은 Wait Icon이 뜨는 것을 보고 그 다음에 댓글이 나오는 것을 확인하고 알게 되었다.

그래서 내가 예상한 대로 코드 자체의 문제라기 보다는 웹 페이지 소스가 유동적으로 변하다보니 생긴 문제였고, 해결방안으로는 Selenium으로 스크롤 다운 동작을 한번 한 다음에 댓글수를 수집하는 코드를 실행하면 될 것이라고 해주었다.
친구가 내가 제시한 해결방안이 아니라 다른 방법(연관 동영상을 뜨지 않게 하는 방법, 연관 동영상이 뜨지 않으면 댓글수가 웹 페이지를 방문하자마자 나온다.)을 쓰기는 했지만 과제를 잘 처리할 수 있었고 문제의 원인을 확실하게 파악할 수 있었다.
