0. Abstract
추천 시스템의 CTR을 극대화를 위해 정교한 feature interactions를 학습하는 것이 중요해짐
현재 존재하는 방법들의 문제점
- low- 또는 high-order interactions에 편향
- 전문적인 피처 엔지니어링이 필요
Google의 최신 와이드 & 딥 모델과 비교했을 때, DeepFM은 피처 엔지니어링이 필요하지 않음
- DeepFM
= factorization machines + deep learning (여기까지가 wide&deep) + feature engineering 필요X (wide&deep과의 차이)
기존 CTR 예측 모델에 비해 DeepFM의 효과와 효율성을 입증
1. Introduction
추천시스템에서 click-through rate (CTR)의 예측은 중요 → 사용자가 추천 항목을 클릭할 확률을 추정
대부분의 추천시스템에서 목표는 클릭률을 최대화하는 것
추정되는 CTR에 의해 아이템 랭킹을 알 수 있고 이를 사용자에게 추천할 수 있음
온라인 광고 → CTR * bid로 랭킹 전략을 세울 수 있음 → CTR을 정확하게 추정하는 것이 핵심
(bid는 사용자가 아이템을 클릭 했을 때 시스템이 얻는 수익)
- Implicit Feature Interaction을 통해 학습하는 것이 CTR 예측에서 중요
- feature interaction
- 식사 시간에 배달 앱을 다운로드 받음 → order-2 interaction: app category와 time-stamp
- 10대 남자 아이들은 shooting 게임과 RPG 게임을 좋아함→ order-3 interaction: app category와 사용자 성별 및 나이
일반적으로 사용자 클릭 행동 뒤의 이러한 상호작용은 매우 정교하며, low- and high-order feature interactions은 매우 중요한 역할을 한다.
구글의 Wide & Deep 모델에 따르면, low- and high-order feature interactions를 동시에 고려하는 것은 하나만 고려하는 것보다 더 나은 성능을 보인다.
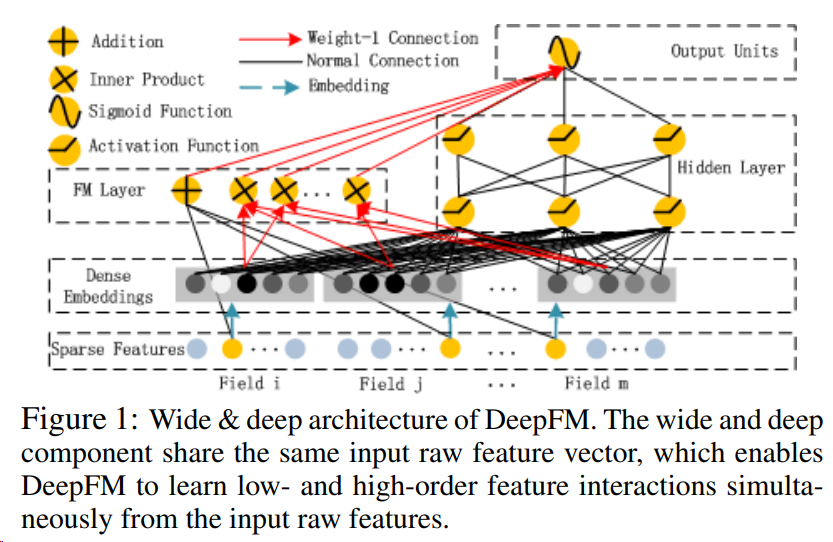
Figure 1: DeepFM의 Wide & deep 구조. wide and deep 모델은 동일한 입력값의 feature vector를 공유 → DeepFM은 low-order와 high-order feature interaction을 동시에 학습할 수 있음
주요 과제는 feature interaction들을 효과적으로 모델링하는 것
- 어떤 feature interaction은 위의 예처럼 쉽게 이해할 수 있어서 전문가에 의해 디자인 될 수 있다.
- 하지만 대부분의 feature interaction은 데이터에 숨겨져 있고 찾기 어렵다.
- 예) 기저귀와 맥주의 연관성
- 전문가가 발견하는 것이 아니라 데이터에서 포착되는 것→ 머신러닝에 의해서만 자동적으로 포착될 수 있음.
쉽게 이해 가능한 상호작용일지라도 기능의 수가 많은 경우 전문가가 이를 철저하게 모델링하기란 쉽지 않다.
-
FTRL(2013)과 같은 generalizaed linear model은 간단함에도 괜찮은 성능 → 그러나, 선형 모델은 feature interaction을 학습하는 능력이 부족: 그냥 feature 페어를 하나로 포함시킬 뿐 일반화하기 어려움)
-
Factorization Model(FM)(2010)은 latent vector의 inner product로 feature interaction 학습 가능. 그러나, 실제로 order2-interaction만 거의 고려된다(복잡성의 이유)
-
feature interaction 잡는 powerful한 방법 → DNN(CNN,RNN,FNN,PNN,Wide&Deep) 간단히 소개
하지만 위 모델들은 다음 문제 중 하나 이상을 포함함(초고에서도 언급된 이유)
1. biased to low- or high-order feature interaction
2. rely on feature engineering⇒ 이걸 해결하는 게 DeepFM -
DeepFM : FM(low order feature interactions)+DNN(high-order feature interactions)
- wide&deep과의 차이점 1) no feature engineering 2) wide 파트와 deep 파트에 동일한 input, embedding vector를 사용
- wide&deep과의 차이점 1) no feature engineering 2) wide 파트와 deep 파트에 동일한 input, embedding vector를 사용
2. Our Approach
- n개의 instance를 가진 (χ, y) 훈련 데이터 세트가 있음
- χ: m개의 fields를 가지고 있음
- χ에는 범주형 필드(예: 성별, 위치)와 연속형 필드(예: 연령)가 포함
- 각 범주형 필드는 원핫인코딩으로 표현되고, 각 연속형 필드는 값 자체 또는 구간화 후 원핫 인코딩의 벡터로 표현
- 각 instance는 (x, y)로 변환:
- x는 고차원이며 매우 희소한 2차원 벡터
- y: 사용자가 항목을 클릭했으면 1, 그렇지 않으면 0
- χ: m개의 fields를 가지고 있음
2.1 DeepFM
low- and high-order feature interactions을 모두 학습하는 것이 목표
⇒ Factorization-Machine based neural network (DeepFM)을 제안
Figure 1에서 볼 수 있듯이 DeepFM은 동일한 입력을 공유하는 두 가지 구성 요소, 즉 FM component와 deep component로 구성됨
feature 에 대해서,
- 는 order-1(1차원)의 중요도를 반영
- 잠재 벡터 는 다른 feature와의 interaction의 영향을 측정
는 FM component에서는 order-2(2차원) feature interactions을 모델링, deep component에서는 고차원 feature interactions을 모델링
, 및 네트워크 매개변수()를 포함한 모든 매개변수가 공동으로 학습됨:
0과 1로 구성되는 은 예측된 CTR
은 FM component의 결과
은 deep component의 결과
FM Component
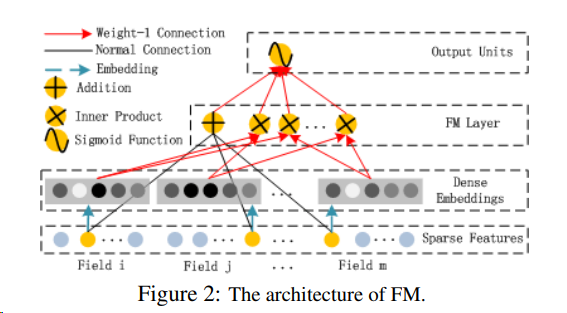
FM의 구조
FM은
- 추천을 위한 feature interaction을 학습하기 위해 [Rendle, 2010]에서 제안한 factorization machine
- feature간의 선형(order-1) 상호 작용 외에도 각 feature 잠재 벡터의 내적 곱으로 2차원(order-2) feature interactions을 모델링 함
- 데이터가 희소한 경우 order-2 feature interaction을 더 효과적으로 포착할 수 있음
- 이전 방법론에서는 feature 와 가 같은 데이터 레코드에 나타날 때만 학습될 수 있었음
- 그러나 FM에서는 잠재 벡터인 와 의 내적을 통해서 측정됨
- 유연한 설계 덕분에 FM은 데이터 레코드에 i(또는 j)가 나타날 때마다 잠재 벡터 Vi(Vj )를 훈련할 수 있음
- 훈련 데이터에 전혀 나타나지 않거나 거의 나타나지 않는 특징 상호 작용은 FM이 더 잘 학습할 수 있음
FM의 출력:
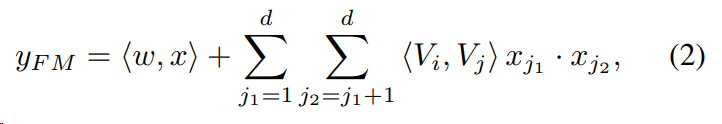
Addition unit (<>): order-1 features의 중요도를 반영
Inner Product units: order-2 feature interactions의 중요도를 반영
Deep Component
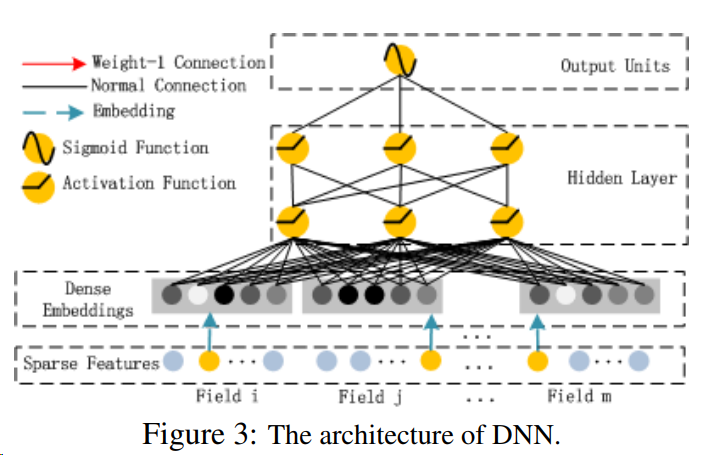
deep component는 feed-forward 신경망으로, 고차원의 feature interactions를 학습하는 데 사용됨
그림 3에서 볼 수 있듯이 데이터 레코드(벡터)가 신경망에 공급됨
- 이미지 또는 오디오 데이터를 입력으로 사용하는 신경망과 비교하면 CTR 예측의 입력은 상당히 다르기 때문에 새로운 네트워크 아키텍처 설계가 필요함
- 특히, CTR 예측을 위한 raw feature input vector는 일반적으로 매우 희소하고, 초고차원이고, 범주형-연속형이 혼합되어 있으며 필드(예: 성별, 위치, 연령)로 그룹화되어 있음
따라서 첫 번째 hidden layer에 입력하기 전에 입력 벡터를 저차원의 밀도가 높은 실제값 벡터로 압축하는 임베딩 레이어가 필요
- 그렇지 않으면 네트워크 학습에 무리가 갈 수 있음
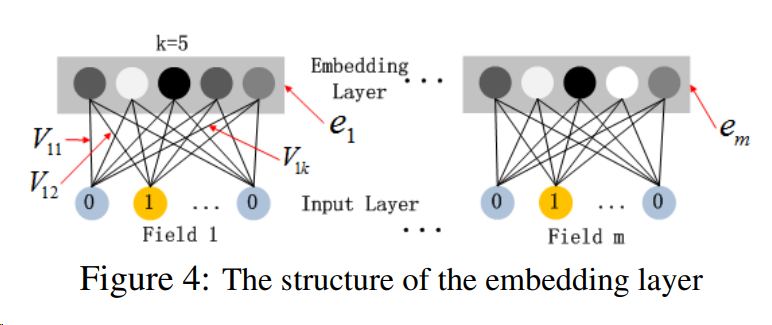
그림 4는 입력 계층에서 임베딩 계층까지의 하위 네트워크 구조를 보여줌
이 네트워크 구조의 흥미로운 특징:
1) 서로 다른 입력 필드 벡터의 길이는 다를 수 있지만 임베딩의 크기(k)는 동일하다는 점
2) FM의 잠재 특징 벡터(V)는 이제 네트워크 가중치로 사용되어 학습되고 입력 필드 벡터를 임베딩 벡터로 압축하는 데 사용된다는 점
본 연구에서는 FM의 잠재 특징 벡터를 사용하여 네트워크를 초기화하는 대신, 다른 DNN 모델과 함께 전체 학습 아키텍처의 일부로 FM 모델을 포함
따라서 FM에 의한 사전 훈련이 필요하지 않으며 대신 전체 네트워크를 end-to-end 방식으로 공동으로 훈련
end-to-end 방식
: 입력에서 출력까지 파이프라인 네트워크(전체 네트워크를 이루는 부분적인 네트워크) 없이 신경망으로 한 번에 처리한다는 의미
임베딩 레이어의 출력은 다음과 같음:
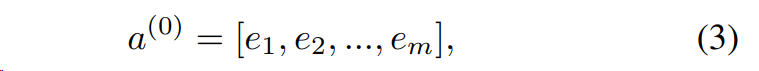
ei 는 i 번째 필드의 임베딩이고 m은 필드의 수
a(0)을 심층 신경망에 입력하면 forward 프로세스가 진행됨:
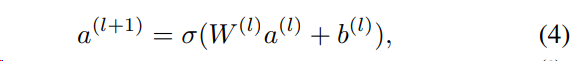
l은 레이어 깊이이고 σ는 활성화 함수
a(l), W(l), b(l)는 l번째 레이어의 출력, 모델 가중치, 바이어스
그 후 real-value feature vector가 생성되고, 이 feature vector는 최종적으로 CTR 예측을 위한 시그모이드 함수에 입력됨

|H| 는 hidden layer의 수
FM component와 deep component는 동일한 피처 임베딩을 공유하므로 두 가지 중요한 이점 존재
- raw feature로부터 low-와 high-order feature interactions을 모두 학습
- Wide & Deep에서 요구되는 것처럼 input에 대한 전문적인 feature engineering이 필요하지 않음
2.2 Relationship with the other Neural Networks
CTR 예측에 존재하는 딥러닝 모델과 DeepFM과의 비교
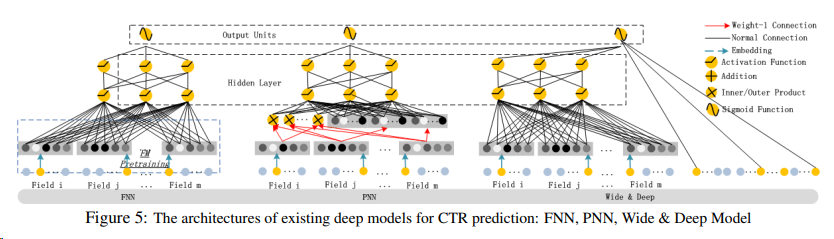
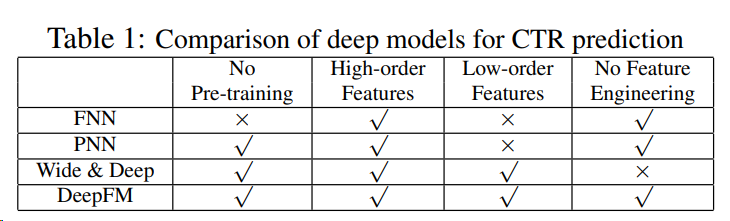
FNN(FM-initialized feedforward neural network)
FM 사전 훈련 전략에는 두 가지 한계가 있음:
- 임베딩 파라미터가 FM에 의해 과도하게 영향을 받을 수 있음;
- 사전 훈련 단계에서 발생하는 오버헤드로 인해 효율성이 감소
- 또한 FNN은 high-order feature interactions만 포착
반면, DeepFM은 사전 학습이 필요하지 않으며 high- and low-order feature interactions을 모두 학습
PNN
high-order feature interaction을 포착하기 위해 PNN은 임베딩 레이어와 첫 번째 hidden layer 사이에 product layer를 부과
제품 작동 유형에 따라 세 가지 변형이 있습니다:
IPNN, OPNN, PNN∗가 있으며, IPNN은 벡터의 내적분, OPNN은 외적분, PNN∗는 내적분과 외적분 모두에 기반
보다 효율적인 계산을 위해 저자는 내적과 외적의 근사값을 모두 계산하는 방법을 제안:
- 내부 곱은 일부 뉴런을 제거하여 대략적으로 계산합니다;
- 외부 곱은 m 개의 k 차원 특징 벡터를 하나의 k 차원 벡터로 압축하여 대략적으로 계산됩니다.
- 그러나 외적 곱의 근사 계산으로 인해 많은 정보가 손실되어 결과가 불안정해지기 때문에 외적 곱은 내적 곱보다 신뢰성이 떨어짐
- 내적 곱이 더 안정적이지만, 내적 층의 출력은 첫 번째 숨겨진 층의 모든 뉴런에 연결되기 때문에 여전히 높은 계산 복잡성을 가짐
- PNN과 달리 DeepFM의 product layer의 출력은 최종 출력 레이어(하나의 뉴런)에만 연결
- FNN과 마찬가지로 모든 PNN은 e low-order feature interactions을 무시
Wide & Deep
- Wide & Deep은 low- and high-order feature interaction을 동시에 모델링하기 위해 구글이 제안
- "넓은" 부분에 대한 입력(예: 앱 추천에서 사용자의 설치 앱과 노출 앱의 교차 제품)에 대한 전문적인 피처 엔지니어링이 필요
반면, DeepFM은 입력된 raw features에서 직접 학습하여 입력을 처리하기 때문에 이러한 전문 지식이 필요하지 않음
Summarizations
DeepFM은 사전 학습과 피처 엔지니어링이 필요 없고 low- and high-order feature interactions을 모두 포착하는 유일한 모델
3. Experiments
3.1 Experiment Setup
Datasets
- Criteo Dataset
- Company Dataset
Evaluation Metrics
- AUC
- Logloss(cross entropy)
Model Comparison
LR, FM, FNN, PNN (three variants), Wide & Deep, and DeepFM.
Parameter Settings
3.2 Performance Evaluation
Efficiency Comparison
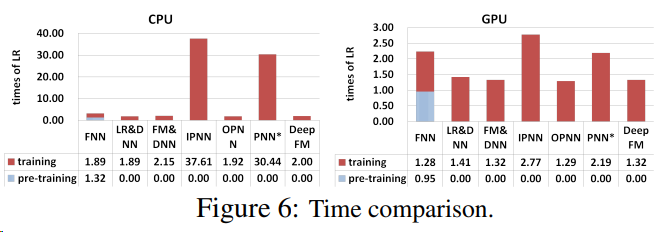
Effectiveness Comparison
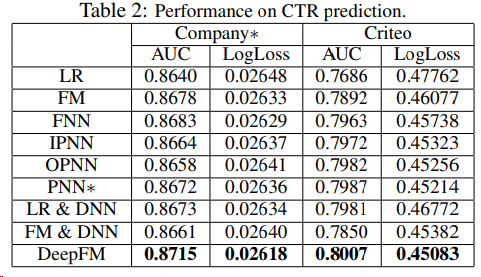
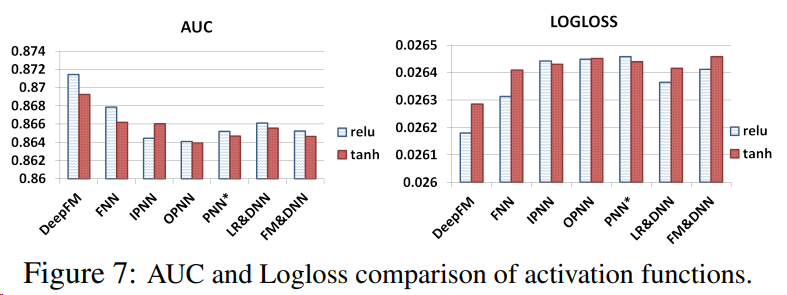
3.3 Hyper-Parameter Study
Activation Function
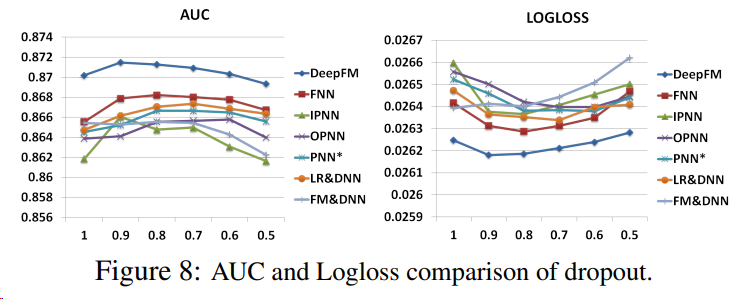
Dropout
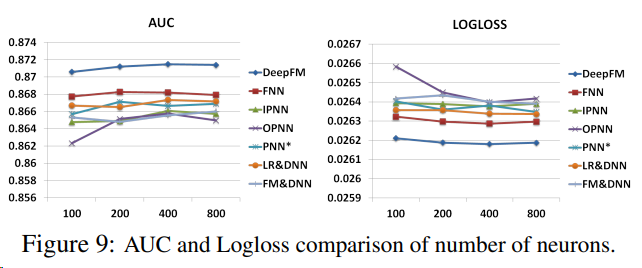
Number of Neurons per Layer
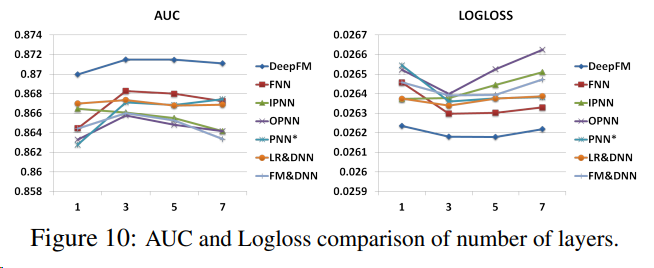
Number of Hidden Layers
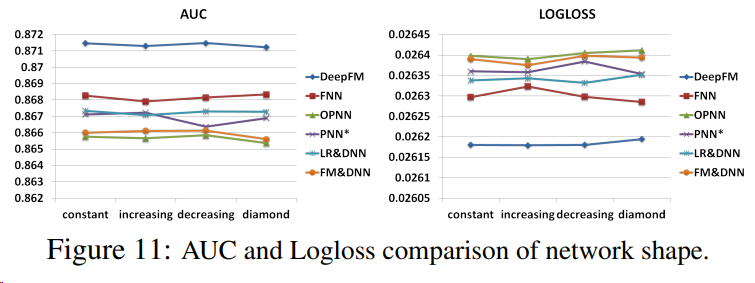
Network Shape
4. Related Work
본 논문에서는 CTR 예측을 위한 새로운 심층 신경망을 제안
CTR 예측
- 추천 시스템에서의 CTR 예측과 딥러닝의 관련 연구에 대해서 설명
- CTR 예측은 추천 시스템에서 중요한 역할을 함
- 일반화된 선형 모델과 FM 외에도 트리 기반 모델, 텐서 기반 모델, 서포트 벡터 머신, 베이지안 모델 등 몇 가지 다른 모델들이 CTR 예측을 위해 제안됨
추천 시스템에서의 딥러닝
CTR 예측 이외의 추천 작업에서도 여러 딥러닝 모델이 제안되고 있음
- 딥러닝을 통해 협업 필터링을 개선할 것을 제안
- 딥러닝을 통해 콘텐츠 특징을 추출하여 음악 추천의 성능을 향상시키기도 함
- 이미지 특징과 디스플레이 광고의 기본 특징을 모두 고려하는 딥러닝 네트워크를 고안
- 유튜브 동영상 추천을 위한 2단계 딥러닝 프레임워크를 개발
5. Conclusions
본 논문에서는 최신 모델의 단점을 극복하고 더 나은 성능을 달성하기 위해 CTR 예측을 위한 Factorization-Machine 기반 신경망인 DeepFM을 제안
DeepFM은 deep 컴포넌트와 FM 컴포넌트를 함께 학습함
다음과 같은 장점을 통해 성능을 향상시킴
- 1) 사전 학습이 필요 없음
- 2) high- and low-order feature interactions을 모두 학습
- 3) 피처 엔지니어링을 하지 않기 위해 피처 임베딩 공유 전략을 도입
두 가지 실제 데이터 세트(Criteo dataset and a commercial App Store dataset)를 대상으로 광범위한 실험을 진행하여 DeepFM과 최신 모델의 효과와 효율성을 비교
실험 결과
1) 두 데이터 세트 모두에서 DeepFM이 AUC와 Logloss측면에서 최신 모델보다 우수한 성능을 보임
2) DeepFM의 효율성은 최신 모델 중 가장 효율적인 deep model과 비슷한 수준으로 나타남
향후 연구 방향의 흥미로운 점
- 하나는 가장 유용한 high-order feature interactions을 학습하는 능력을 강화하기 위해 pooling layers 도입과 같은 몇 가지 전략을 모색하는 것
- large-scale problems를 위해 GPU 클러스터에서 DeepFM을 훈련하는 것
