추천시스템을 공부하기 위해 다음 유튜브 강의 및 블로그를 참고하여 정리해보았습니다.
https://youtu.be/43gb7WK56Sk
https://blog.insilicogen.com/61
01. 추천시스템의 개요
1) 정의
- 추천시스템은 사용자(user)에게 상품(item)을 제안하는 소프트웨어 도구이자 기술
- 어떤 상품을 구매할지, 어떤 음악을 들을지 또는 어떤 온라인 뉴스를 읽을지와 같은 다양한 의사결정과 연관이 있음
2) 목표
어떤 사용자에게 어떤 상품을 어떻게 추천할지에 대해 이해
02. 컨텐츠 기반 추천
1) 정의
컨텐츠 기반 추천시스템은 사용자가 이전에 구매한 상품중에서 좋아하는 상품들과 유사한 상품들을 추천하는 방법
2) 과정
items을 벡터 형태로 표현. 도메인에 따라 다른 방법이 적용됨
N개의 item -> N개의 벡터 -> 벡터들간의 유사도를 계산 -> 벡터1부터 N까지 자신과 유사한 벡터를 추출- 이미지의 경우: CNN, ResNet, VGG
- 자연어의 경우: TF-IDF, Word2Vec, Bert를 통해 아이템을 벡터 형태로 표현
3) 유사도 계산 방법
하나의 유사도를 택하기 보단 여러 가지를 적용 및 비교하여 가중치를 주어 최적의 결과를 이용
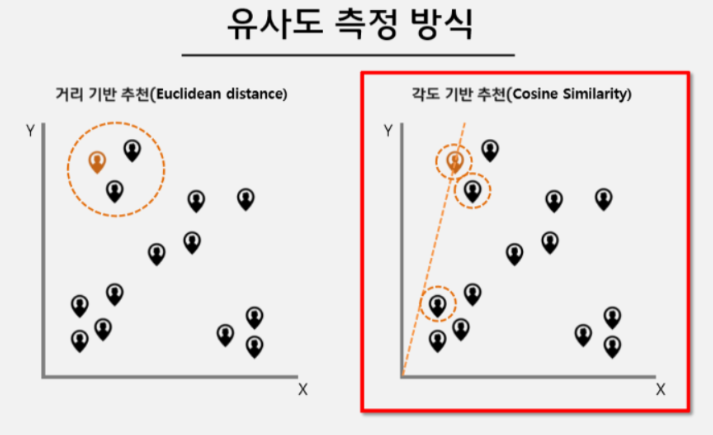
① 유클리디안 유사도
-
문서간의 유사도를 계산, 거리가 가까운 것
유클리디안 유사도 =
-
장점
계산하기가 쉬움 -
단점
p와 q의 분포가 다르거나 범위가 다른 경우에 상관성을 놓침
② 코사인 유사도
-
문서간의 유사도를 계산, 두 문서가 얼마나 비슷한 방향을 가지고 있는지 (cos(θ))
코사인 유사도 cos(θ) =
-
장점
벡터의 크기가 중요하지 않은 경우에 사용
(예: 문서 내에서 단어의 빈도수 - 문서들의 길이가 고르지 않더라도 문서 내에서 얼마나 나왔는지 비율을 확인하기 때문에 상관없음) -
단점
벡터의 크기가 중요한 경우에 대해서 잘 작동하지 않음
③ 피어슨 유사도
- 문서간의 유사도를 계산, 상관관계 분석 시 많이 사용
④ 자카드 유사도
- 문서간의 유사도를 계산, 1을 가지고 계산
J(A,B) = =
4) 벡터화 방법 - 텍스트 형태일 때
① TF-IDF
- 특정 문서 내에서 특정 단어가 얼마나 자주 등장하는지를 의미하는 단어 빈도(TF)와 전체 문서에서 특정 단어가 얼마나 자주 등장하는지를 의미하는 역문서 빈도(DF)를 통해서 '다른 문서에서는 등장하지 않지만 특정 문서에서만 자주 등장하는 단어'를 찾아서 문서 내 단어의 가중치를 계산하는 방법
- 문서의 핵심어 추출, 문서들 사이의 유사도 계산, 검색 결과의 중요도를 정하는 작업 등에 활용
- TF-IDF 사용 이유
- 빈도수를 기반으로 많이 나오는 중요한 단어들을 추출. 이러한 과정을 Counter Vectorizer라고 함
- 하지만 Counter Vectorizer는 단순 빈도만을 계산하기에 조사, 관사처럼 의미는 없지만 문장에 많이 등장하는 단어들로 높게 쳐줌
-> 이러한 단어들에 패널티를 줘서 적절하게 중요한 단어만을 잡아내는게 TF-IDF 기법 - 장점: 직관적인 해석 가능
- 단점: 대규모 말뭉치를 다룰 때 메모리 문제 발생. 높은 차원을 가지고, 매우 sparse한 형태의 데이터임
② Word2Vec
- 추론 기반의 방법
- 주변 단어(맥락)가 주어졌을 때, 빈칸에 무슨 단어가 들어가는지를 추측- 잘못 예측한 경우? 학습을 통해서 점점 모델을 개선
- 단어간 유사도를 반영하여 단어를 벡터로 바꿔주는 임베딩 방법론
- 원핫벡터 형태의 sparse matrix가 가지는 단점을 해소하고자 저차원의 공간에 벡터로 매핑
- '비슷한 위치에 등장하는 단어들은 비슷한 의미를 가진다'라는 가정을 통해 학습을 진행
- 예) 나는 강아지를 좋아한다./나는 고양이를 좋아한다. 에서 강아지와 고양이 - 알고리즘
- CBOW: 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측
- Skip-Gram: 중간에 있는 단어로 주변 단어들을 예측
- Skip-Gram이 성능이 더 좋아서 대부분 많이 사용

5) 장단점
① 장점
- 협업필터링은 다른 사용자들의 평점이 필요한 반면, 자신의 평점만을 가지고 추천시스템을 만들 수 있음
- 다른 사용자의 데이터가 존재하지 않더라도 신규 사용자에게 콘텐츠를 추천할 수 있음
- 벡터화한 콘텐츠 간의 유사성을 계산하여 높은 값을 가지는 콘텐츠를 추천하기 때문에 추천하는 콘텐츠에 대한 근거 제시 가능
- 새로 추가된 콘텐츠나 유명하지 않은 콘텐츠도 추천이 가능
② 단점
- 사용자가 흥미가 있는 콘텐츠를 제공하지 않는다면 추천 어려움
-> ott에 처음 가입하면 서비스를 이용하기 전, 이전에 시청했던 영상에 대한 평가를 받는 이유 - 콘텐츠 간 유사성을 계산하여 추천하기 때문에 사용자가 이미 알고 있는 유사한 콘텐츠만을 추천하는 문제 발생 가능, 새로운 장르에 대한 추천이 어려움
