1. 분석 개요
1.1 스마트쉼터 정의
버스승차대의 고유기능에 최첨단 사물인터넷(IoT) 기술·정보통신기술(ICT)을 접목한 미래형 버스승차대
*스마트쉼터 특성 : 종합 교통 정보 제공, 공기 청정, 냉•난방, 자외선 공기살균, 미세먼지 정화 장치, 지능형 CCTV 관제, 이상 음원 감지 시스템, 공공 wi-fi 제공, 휴대전화 유•무선 충전, 휴대전화 충전 가능, 비상벨(경찰서, 소방서), 열화상 카메라와 출입문 작동 연계, 재생 에너지(태양광) 사용 등
1.2 분석 배경
-
성동구에서 현재 47개의 스마트쉼터 운영
-
매연과 미세먼지로부터 호흡기 질환 예방
: 기존 버스정류장은 매연과 미세먼지에 노출되어 있지만, 스마트쉼터 내에는 미세먼지· UV·살균 정화 등의 장치가 탑재돼 있어 호흡기 질환을 예방할 수 있음 -
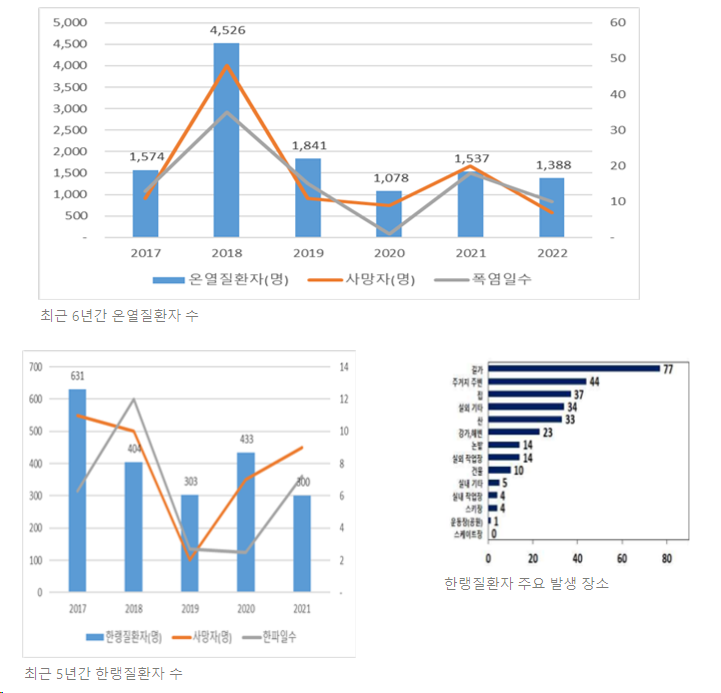
길가에서 발생하는 온열 및 한랭 질환자 증가
: 22년 7월 기준 온열질환자 885명 발생했으며, 전년 대비 22.1% 증가
질병관리청의 「한랭질환 응급실 감시체계 발생 현황」에 따르면 7월부터 8월 초까지 전국 503곳의 응급실에 한랭질환으로 신고된 환자는 모두 190명으로, 전년(21년) 대비 30% 증가
: 한랭 질환자 발생 장소로 실외가 80.4%를 차지하며 그중 33.3%가 길가에서 발생
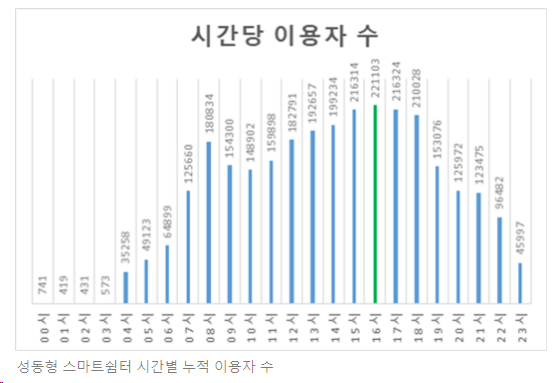
- 성동구 주민들의 높은 이용률과 만족도
: 22년 현재 300만 명을 돌파하는 누적 이용자 수를 기록
: 연간 성동구 시민의 85%가 스마트쉼터를 이용하였으며, 22년 1월 성동구 시민을 대상으로 한 스마트쉼터 이용 만족도 조사에서 약 94%가 만족한다고 응답
💡 성동구 스마트쉼터에 대한 입지와 주요 변수 간의 연관성을 분석하고 기존 정책을 활용하여, 이동 편의 시설을 개선하여 타 지역 시민의 복지 증진에 이바지하고자 함
1.3 부평구 선정 이유
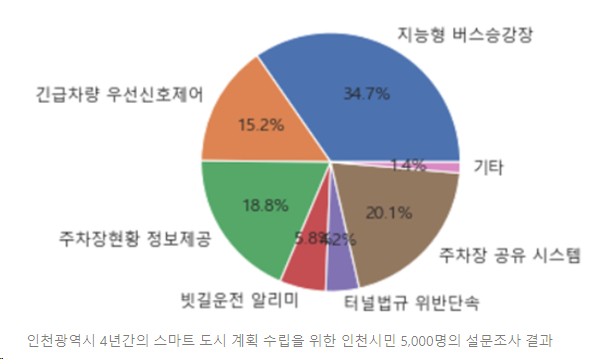
- 인천시는 현재 2020년도부터 2024년까지(4년간) 스마트 도시 계획을 수립
: 지능형 버스 승강장이 1,303명으로 전체의 34.7% 차지하여 가장 높은 선호도를 보임
- 인식에 비해 낮은 범죄율
: 인천시는 인천에서 일어난 많은 사건 사고에 의해 오명을 쓰고 있음
: 그러나 총 범죄 322,346건 중 인천에서 일어난 범죄 건수는 18,851건으로 전체의 약 5.8%밖에 미치지 않음
: 인천광역시 시간대별 범죄 발생 건수 31,159건 중 부평구의 범죄 수는 10%(3,162건)로 인천시 10개의 행정구 가운데 5위
- 많은 유동인구
: 부평구는 2022년 인천시 인구 기준 약 16.5% (486,765명)가 거주
: 부평 지하상가, 부평 문화거리 등 많은 사람들이 모이는 서비스업 중심의 산업 구조가 발달되어 있어 유동 인구가 많음
💡 현재 지자체에 박혀있는 부정적인 이미지를 개선하고자 부평구를 선정
2. 분석 프로세스
2.1 분석 프로세스 도식화
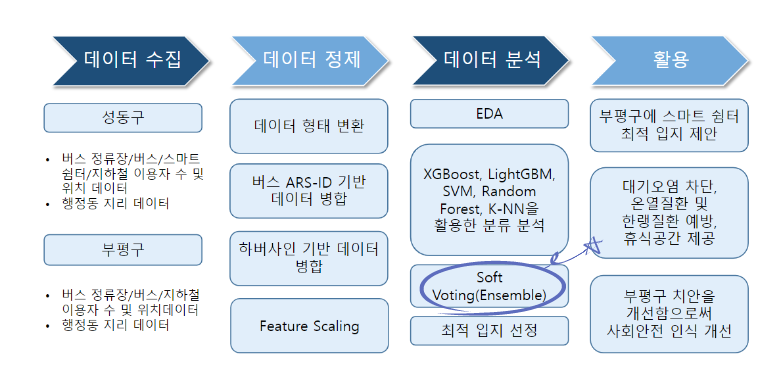
2.2 분석 방법
-
이진 분류 알고리즘 모델 구축
: XGBoost, LightGBM, SVM, 로지스틱 회귀, 랜덤포레스트, K-NN 모델을 각각 구축
: 타 지역 데이터를 모델에 적용하여, 정류소별 ‘쉼터 적합도’를 계산 -
앙상블 기법 중 Soft Voting 활용
: Soft Voting을 활용해 모든 분류모델의 ‘쉼터 적합도’를 평균 내어 최종 ‘쉼터 적합도’를 추출
3. 데이터 정제
3.1 데이터 전처리
- 버스 총 승차 수 데이터
: 한 달간의 버스 정류장별 승차 인원을 모두 더하여, 버스 정류장별 총 승차 승객 수 데이터를 생성
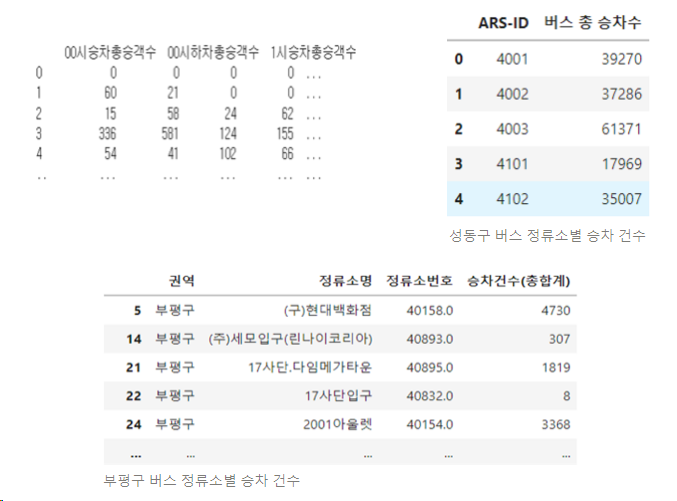
- 버스 수 데이터
버스 정류장 ‘NODE-ID’와 버스 ‘NODE-ID’를 이용하여 버스 정류장별 버스 수 데이터를 생성
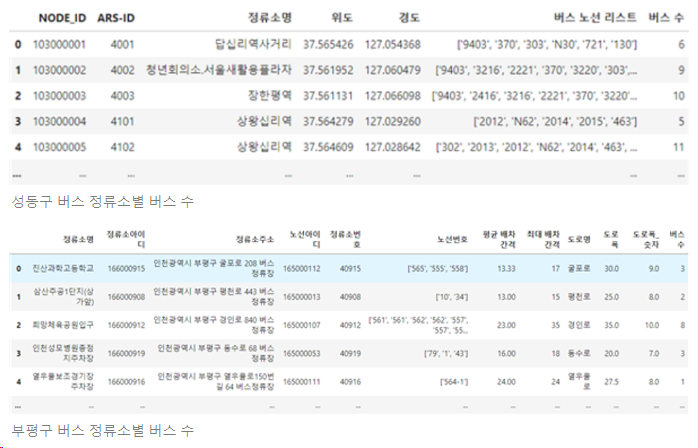
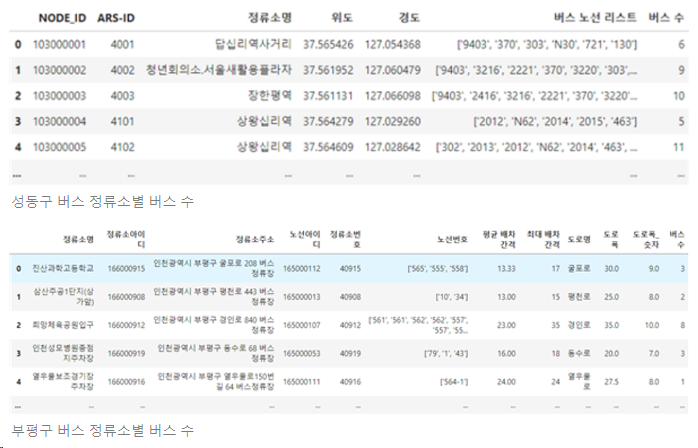
- 도로폭 데이터
: 도로폭 데이터상 ‘도로명’과 버스 정류장 데이터상 ‘도로명’을 결합하여 도로폭 데이터를 분석에 사용 가능하게 순서형 데이터로 변환
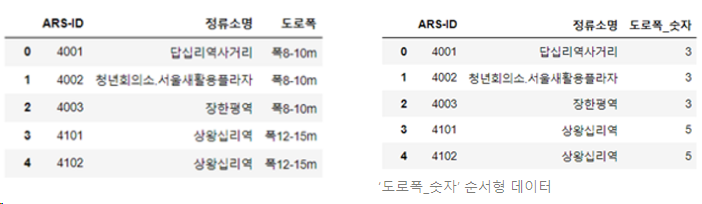
-
버스 배차 간격 데이터
: 버스 정류장별 버스 번호를 구하고, 해당 버스마다 배차 간격 추출
: 버스 정류장별 버스의 배차 간격 평균을 구하여 데이터로 활용 -
쉼터 여부 데이터
: 버스 정류장별 스마트쉼터 여부에 따라 1과 0의 명목형 데이터로 활용
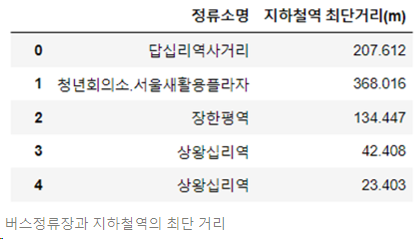
- 지하철역과의 거리 데이터
: 버스 정류장의 ‘위도, 경도’와 지하철역의 ‘위도, 경도’를 활용하여 각 버스 정류장과 가까운 지하철역 생성
: 버스 정류장과 가장 가까운 지하철역 간의 거리를 하버사인 패키지(Haversine)를 통해 구함
- 인구 데이터
250m 격자 단위의 ‘인구’ 데이터와 버스 정류장 ‘위도, 경도’ 데이터를 Q-GIS를 활용하여, 격자 내 인구 수를 해당 버스 정류장 인구 데이터로 활용
3.2 이상치 처리
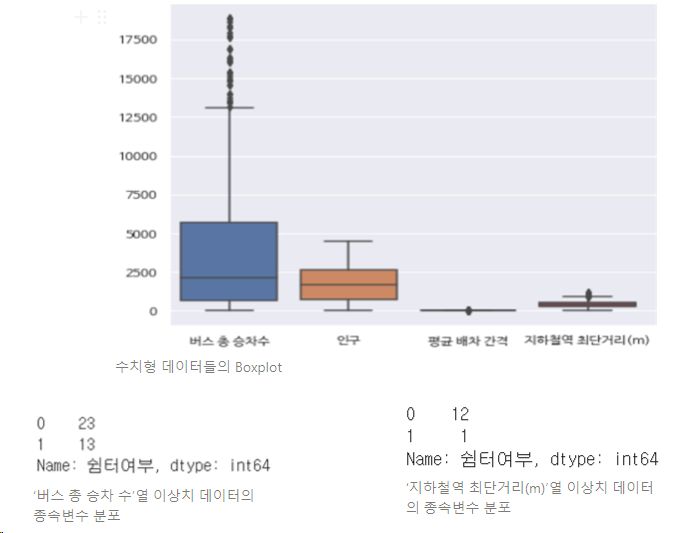
-
‘버스 총 승차 수’의 이상치 데이터를 모아 종속변수인 ‘쉼터 여부’ Class의 비율을 계산해보았을 때, 약 60:40의 비율을 띄고 있음 → 전체 432개 데이터 중 36개를 제외한 396개의 데이터를 사용
-
‘지하철역 최단 거리(m)’열의 경우 이상치가 발견되었으나, 100:0에 가까운 비율을 띄어 의미 있는 이상치라 판단하여 제거하지 않고 사용
3.3 오버 샘플링(Over Sampling)
-
현재 성동구 쉼터 데이터의 종속 변수(쉼터 여부)의 분포는 약 8.6:1로 불균형 데이터의 형태를 띄고 있음 → SMOTE(Synthetic Minority Oversampling TechniquE)을 사용하여 불균형성을 해소
-
샘플링별 평가 지표 비교
: 오버샘플링의 효과 비교를 위해 각각 조건을 다르게하여 정확도(Accuracy)와 재현율(Recall)을 확인하여 성능을 검증
: 모델은 아래에 기술한 머신러닝 알고리즘 중 하나인 XGBoost Classifier를 사용하였고, 하이퍼파라미터(Hyper Parameter)값은 동일하게 적용하여 실험
: 평가 기준은 재현율을 우선으로 평가하고, 그다음으로 정확도로 평가 -
결과 해석
: 오버샘플링 기법을 적용하지 않은 경우가 지표상 성능이 가장 높게 나타남
: 증강된 데이터의 품질이 떨어져 오히려 모델의 성능을 해치는 것으로 추정
: 따라서 학습 데이터에 오버샘플링을 적용하지 않고 모델 입력으로 사용하지만, 모델 결과로 나온 확률값에서 불균형 데이터로 학습된 것을 감안하여 결과를 해석하는 방향으로 결정
4. 모델 학습
✅ 현재 종속변수 데이터는 1보다 0의 비율이 더 높은 비대칭 데이터
→ class가 0인 데이터를 맞추는 것보다 class가 1인 데이터를 맞추는 것이 훨씬 중요
→ 머신러닝 평가 지표 중 하나인 ‘재현율(Recall)’을 중심으로 평가
✅ 보통의 이진 분류 문제는 각 class에 해당하는 확률값을 0.5를 기준으로 분류하지만, 본 분석에서는 여러 분류 임계값을 사용하여 각각의 재현율 및 다른 평가 지표를 확인

- 앙상블(Ensemble)
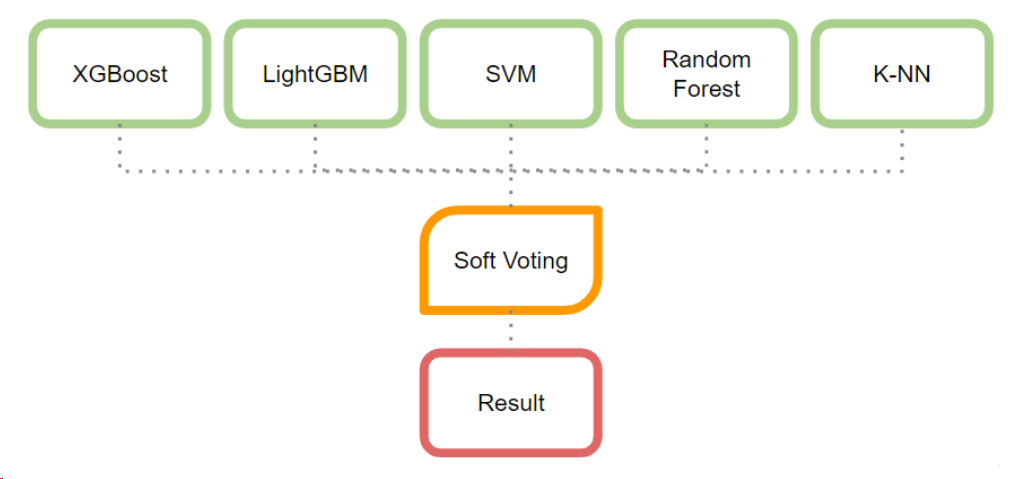
- 단일 모델을 선택하기보다 앙상블을 통해 일반화된 모델을 구축하고자 함
- 소프트 보팅(Soft Voting)을 사용
5. 분석 결과
5.1 부평구 최적 입지 적합도 상위 정류장 시각화 결과
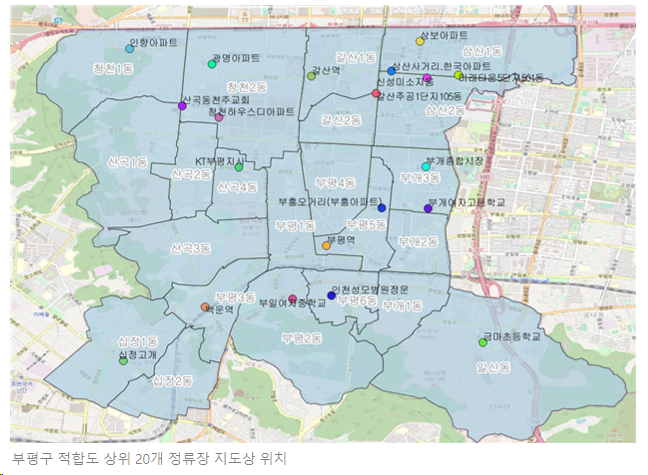
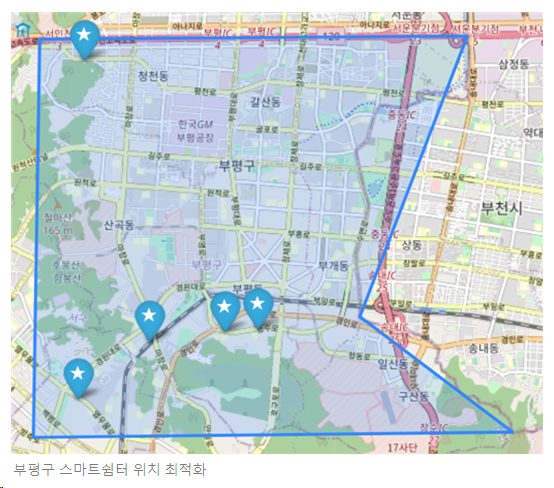
5.2 부평구 최적 입지 적합도 상위 3개 정류장 지도상 위치와 사진
1. 부일여자중학교

- 정류장 주변에 부일여중, 인천성동학교가 자리 잡고 있음
- 도보 2분 거리(104m)에 동수역이 위치
- 주변에 주거단지, 상권이 활성화되어있고 버스들의 배차 간격이 긴 편
2. 백운역
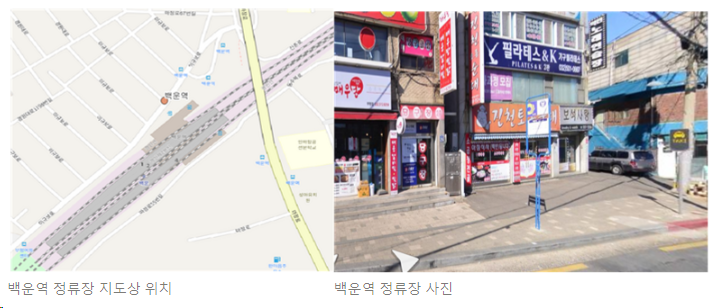
- 정류장 맞은편에 백운역이 자리 잡고 있음
- 도보 5~7분 거리에 부평서중학교, 부평서여자중학교, 신촌초등학교, 부광고등학교 위치
- 1단지, 2단지, 3단지의 현대 아파트 위치
- 2001아울렛 부평점의 경우 버스를 이용하여 이동 시 도보 1분 내 위치
3. 인천성모병원정문
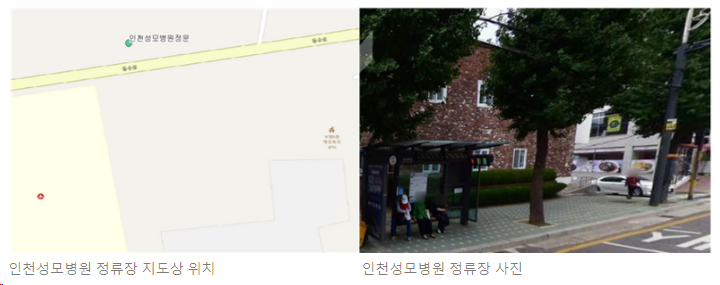
- 인천성모병원 건너편에 위치하고 다양한 상권이 형성되어 있으며 주민센터와도 가까워 높은 연령대 주민의 이용이 기대됨
- 입지 1위인 부일여자중학교 버스정류장과 근접함
- 2024.11. 부평역 해링턴플레이스 아파트 입주 예정
6. 활용방안
6.1 한계점
- 데이터 취합 문제
- 각각의 데이터의 생성 시기가 달라 취합 과정 중 성동구 버스 정류장에 대한 데이터의 일부를 제거하였고, 그 결과 성동구 스마트쉼터가 있는 버스 정류장 2개가 제거됨
- 모델 성능 문제
- 스마트쉼터가 설치된 버스 정류장이 설치되지 않은 버스 정류장에 비해 너무 적음
이를 해결하기 위해 Over Sampling(SMOTE 기법)을 사용했지만, 오히려 모델의 성능이 떨어짐
6.2 활용방안 제언
- 입지 선정 모델: 인천광역시 부평구 스마트 도시 계획 정책 수행 시 본 분석의 입지 선정 모델을 제공
- 이동 노동자 쉼터: 스마트쉼터를 넓은 의미로 활용하여 이동 시간이나 쉬는 시간 같은 공백 시간에 이동 노동자들이 밖이 아닌 설비가 갖춰져 있는 실내에서 시간을 보낼 수 있도록 공간을 제공
- 관광객 편의성 증진: 스마트쉼터 내 BIS(Bus Information System)에 외국어 지원 서비스를 유치하여 외국어 사용자의 접근성을 높일 수 있음
