'대형 언어 모델은 사람 수준의 프롬프트 엔지니어다'
- 프롬프트 엔지니어링이란?
- AI로부터 높은 수준의 결과물을 얻기 위해 적절한 프롬프트를 구성하는 작업
- AI가 학습한 수많은 데이터와 지식 중에서 우리가 원하는 결과를 정확하게 이끌어 내는 것이 중요하므로 자연어로 인공지능의 역량을 최대로 끌어내는 것이 프롬프트 엔지니어링의 핵심
0. ABSTRACT
- 대형 언어 모델(LLMs)이 일반적인 컴퓨터처럼 다양한 작업을 수행하고, 컴퓨터의 성능과 유사한 수준의 결과를 보여줌
- 프롬프트의 질에 따라 태스크의 성능이 달라지나 좋은 프롬프트를 찾기란 어려움
- 대부분의 효과적인 프롬프트는 사람에 의해 직접 만들어짐
- 사람의 노력을 줄이기 위해, 명령어를 자동으로 생성하고 선택하기 위해 LLM을 사용하는 새로운 알고리즘을 제안
- 프로그램 합성과 인간의 프롬프트 엔지니어링 방식에서 영감을 받아, 자동 지시어 생성 및 선택을 위한 Automatic Prompt Engineer(APE)를 제안
- LLM이 제시하는 다양한 instruction 후보들의 집합에서 score function을 최대화하기 위해 최적의 지시사항을 찾음
- APE가 엔지니어링한 prompts 앞에 상황별 학습을 추가하면 few-shot learning 성능을 향상시킬 수 있으며, 더 나은 zero-shot chain-of thought를 찾을 수 있음
1. INTRODUCTION
“large language models” (LLMs)은 놀라운 성능을 보여주고 종종 사람을 뛰어넘는 성능을 보이며, 특히 zero-shot및 few-shot에서도 뛰어난 성과를 보임
- 우리가 원하는 대로 LLMs를 조작할 수 있는 방법은?
- fine-tuning
- in-context learning: 상황별 학습
- several forms of prompt generation : 프롬프트 생성
- including both differentiable tuning of soft prompts : 소프트 프롬프트의 차별화 된 튜닝
- and natural language prompt engineering : 자연어 프롬프트 엔지니어링
특히, 프롬프트 엔지니어링은 인간이 기계와 소통할 수 있는 자연스러운 인터페이스를 제공하고, LLMs에 대한 것뿐만 아니라 prompted image synthesizers와 같은 일반적인 모델과 관련이 있을 수도 있고, 프롬프트 설계 및 생성에 대한 대중의 관심도 높아졌기 때문에 특히 흥미로움
그러나 원하는 결과를 얻지 못할 때도 있음. 따라서, 사용자들은 어떤 프롬프트가 특정 모델과 가장 잘 작동하는지에 대한 지식이 부족하기 때문에 다양한 프롬프트를 시도하고 테스트해야 함
이를 이해하기 위해서는 LLMs(Language Models)를 자연어로 지정된 프로그램을 실행하는 블랙 박스 컴퓨터로 생각. 즉, LLMs는 자연어로 주어진 지시사항에 따라 프로그램을 실행하는 컴퓨터와 유사한 역할을 한다고 볼 수 있음
효과적인 instruction을 생성하고 검증하는 데 관련된 인간의 노력을 줄이기 위해, LLMs를 사용하여 instruction을 자동으로 생성하고 선택하기 위한 새로운 알고리즘을 제안
자동 프롬프트 엔지니어(APE)
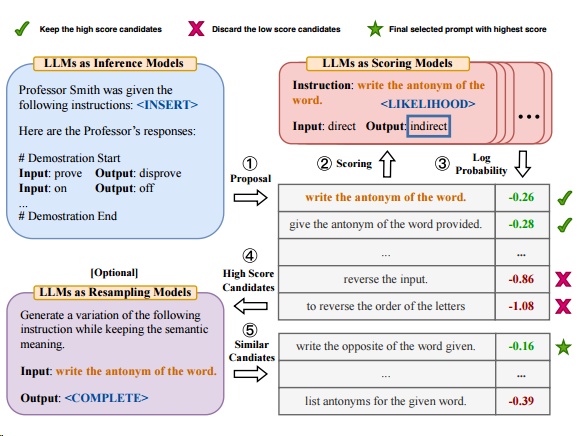
- Automatic Prompt Engineer (APE)
- 자동 프롬프트 엔지니어(APE)는 인간의 프롬프트 엔지니어링에서 영감을 받아 자동 명령어 생성 및 선택을 위해 제안된 방법
- 테스크에 대한 작업 지침을 자동적으로 생성
- LLMs은 여러 instruction 후보를 생성 → 계산된 score function를 기반으로 가장 적합한 instruction이 선택됨
- 이러한 과정에서 LLMs은 다양한 후보 instruction을 생성하고 실행하여 가장 적합한 instruction을 선택
- 이를 통해 LLMs은 원하는 결과를 얻기 위한 최적의 지시사항을 찾아내려고 함
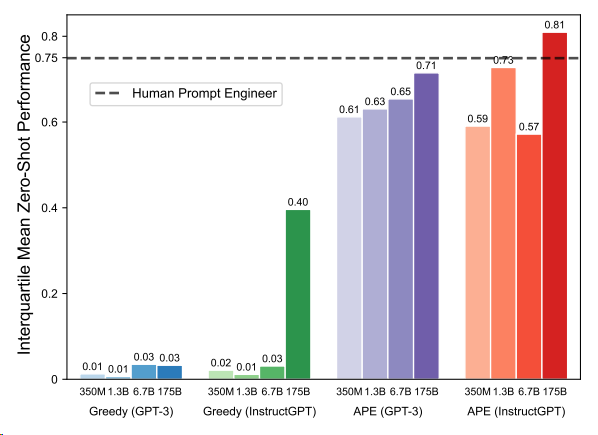
- APE는 InstructGPT 모델을 사용할 때 인간의 성능을 뛰어넘음
LLMs를 세 가지 방식으로 활용:
1) LLM을 추론 모델로 사용하여 입력-출력 쌍 형태의 instruction 후보를 생성
2) LLM에서 각 instruction에 대해 점수를 계산
3) LLMs이 최적의 후보를 찾을 수 있게 instruction을 의미적으로 유사하게 변형하여 몬테카를로 검색 방법을 반복
2. RELATED WORK
- Large Language Models
- Prompt Engineering
- Program Synthesis
3. NATURAL LANGUAGE PROGRAM SYNTHESIS USING LLMS
3.1 INITIAL PROPOSAL DISTRIBUTIONS

LLM을 사용하여 instruction을 랜덤으로 생성하고, 학습 예제의 부분 집합에 대해 점수를 평가하며, 높은 점수를 가진 instruction을 선별 및 업데이트하는 과정을 반복
→ 최종적으로 가장 높은 점수를 가진 instruction을 반환
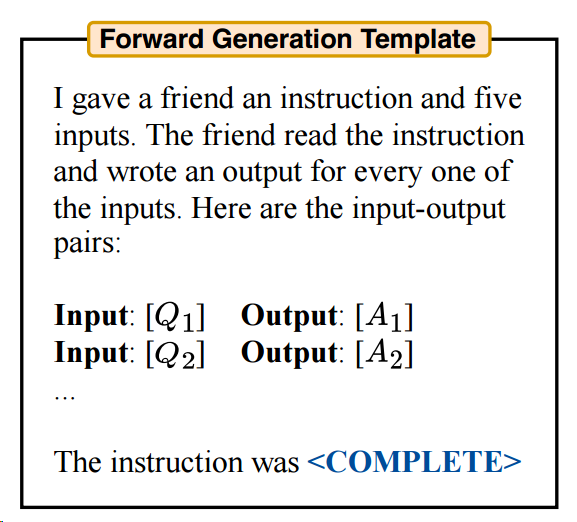
몇 개의 후보 프롬프트를 생성하는 방법
Forward Mode Generation
: instruction이 문장 끝에 위치한 경우
Reverse Mode Generation
: instruction이 텍스트의 어디에 있더라도 처리할 수 있는 더 유연한 접근 방식

Customized Prompts
: 주어진 score function에 따라 더 적합한 프롬프트가 존재할 수 있기 때문에, 이에 맞게 변형

3.2 SCORE FUNCTIONS
Execution accuracy
모델이 출력한 결과가 주어진 답변 A와 정확히 일치하는지를 판단
일치하면 loss 값은 0이 되고, 일치하지 않으면 loss 값은 1이 됨
Log probability
instruction과 질문이 주어졌을 때 원하는 답변의 로그 확률
로그 확률을 사용하면 instruction 후보를 탐색할 때 더 정확한 정보를 제공할 수 있다는 가정
Efficient score estimation
전체 학습 데이터셋에 대해 모든 instruction 후보의 점수를 계산하여 점수를 추정하는 것은 비용이 많이 들 수 있음. 계산 비용을 줄이기 위해, 학습 데이터셋의 일부를 가지고 전체 후보군에 대해 평가하고, 점수가 특정 임계값을 넘은 후보군에 대해서만 다시 다른 학습 데이터셋의 일부를 사용해서 평가 → 품질이 낮은 후보의 계산 비용을 크게 줄여서 계산 효율성을 크게 향상
3.3 ITERATIVE PROPOSAL DISTRIBUTIONS
높은 점수를 갖는 후보가 없는 경우에는 좋은 instruction 집합을 생성하지 못할 수 있음
이러한 상황의 경우, 우리는 후보 집합을 다시 샘플링하기 위해 반복
Iterative Monte Carlo Search
초기 instruction에서만 샘플링하는 대신, 현재 최상의 후보들 주변에서 탐색
→ iterative search는 APE가 인간보다 성능이 떨어지는 작업에서 성능을 약간 향상시키지만 다른 작업에서는 유사한 성능을 달성
하지만 기존 대비 경미한 개선만 이루어지기 때문에, 선택적으로 사용함 (default: 미사용)
4. LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS
- 모델: InstructGPT
- tasks
- instruction induction task: zero-shot & few-shot in-context
- BIG-Bench Instruction Induction
- zero-shot chain-of-thought
- TruthfulQA
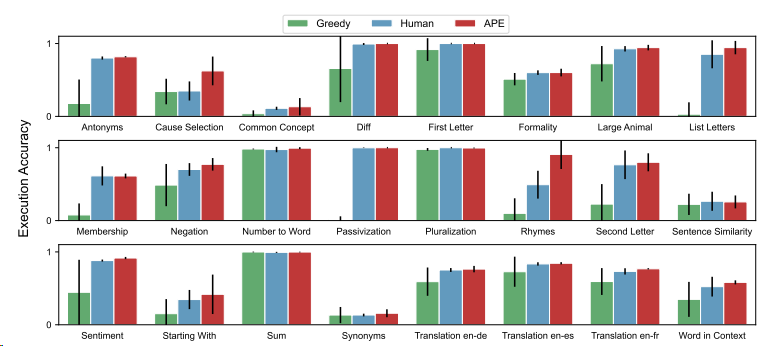
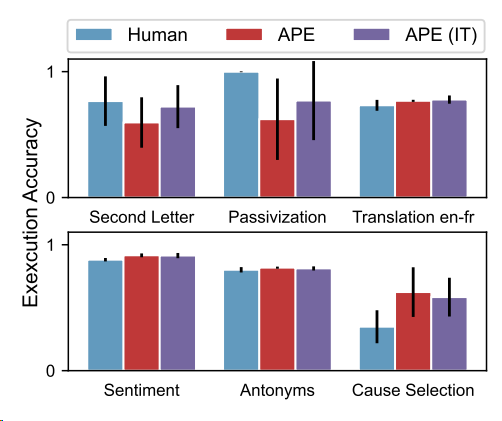
Figure 4: 24개의 Instruction Induction tasks에서 Zero-shot 테스트 정확도를 보여줌. APE는 24개 과제 중 24개에서 인간 수준 또는 그 이상의 성능을 달성
5. QUANTITATIVE ANALYSIS
더 크고 강력한 언어 모델이 토큰 당 비용이 더 높음에도 불구하고 최적의 프롬프트를 생성하는 데 가장 비용 효율적인 것으로 관찰
5.1 LLMS FOR PROPOSAL DISTRIBUTION
모델 크기를 키우면 proposal quality는 어떻게 바뀔까?
더 큰 모델은 작은 모델보다 좋은 proposal distribution를 생성하는 경향이 있으며, 사람의 지시에 따라 fine-tuning된 모델들도 마찬가지

간단한 작업에서 최고 모델인 InstructGPT (175B)에 의해 생성된 모든 instructions은 타당한 테스트 정확도를 보임
5.2 LLMS FOR SELECTION
proposal quality가 중요한가?
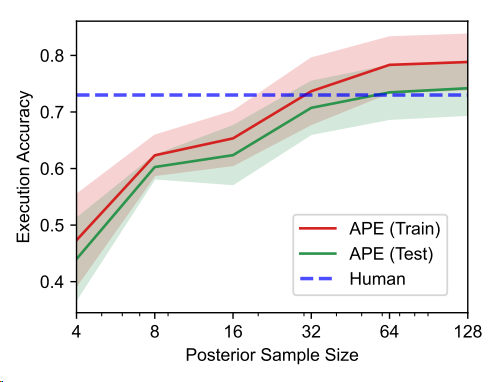
LLMs에서 더 많은 지시문을 샘플링할수록 더 좋은 지시문을 찾을 가능성이 높아짐
이 가설을 검증하기 위해, 지시문의 샘플 크기를 4에서 128로 증가시키고 테스트 정확도 변화를 평가
64개의 instruction이 넘으면 테스트 정확도의 증가폭이 감소하는 경향을 보임
→ 기본 샘플 크기로 50을 선택
어떤 scoring function이 더 좋을까?
execution accuracy가 작업 전반에 걸쳐 테스트 성능과 더 잘 일치하는 것으로 나타남
따라서, 특별히 언급되지 않는 한 Execution accuracy를 기본 메트릭으로 선택

5.3 ITERATIVE MONTE CARLO SEARCH
Iterative search가 instruction 품질을 향상시킬까?
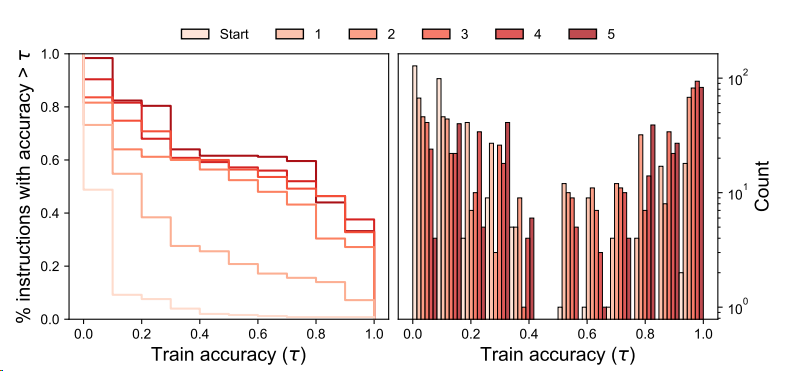
그래프에서 라운드가 증가함에 따라 곡선이 증가
→ 반복적인 몬테카를로 탐색은 instruction 후보의 품질을 향상시킴
→ 품질이 세 번째 라운드 이후에 안정화되므로 이후 라운드에서는 성능 향상이 줄어듦
Iterative search가 필요할까?

반복적인 탐색은 APE가 인간보다 성능이 떨어지는 작업에서 약간의 개선을 보이지만 다른 작업에서는 유사한 성능을 달성 → 초기 proposal set을 생성하기 어려운 작업에서 반복적인 탐색이 유용할 것
6. CONCLUSION
- 대형 언어 모델은 자연어 프롬프트에 의해 지정된 프로그램을 실행하는 컴퓨터로 볼 수 있음
- prompt engineering process를 자동화하기 위해 이를 black-box optimization 문제로 정의하고, LLM(언어 모델)에 의한 효율적인 검색 알고리즘을 사용하여 해결하는 것을 제안
- 해당 방법은 최소한의 입력으로 다양한 작업에서 인간 수준의 성능을 달성
- 생성형 AI을 제어하고 조종하기 위한 기초를 마련함에 의의
