🔍 Problem
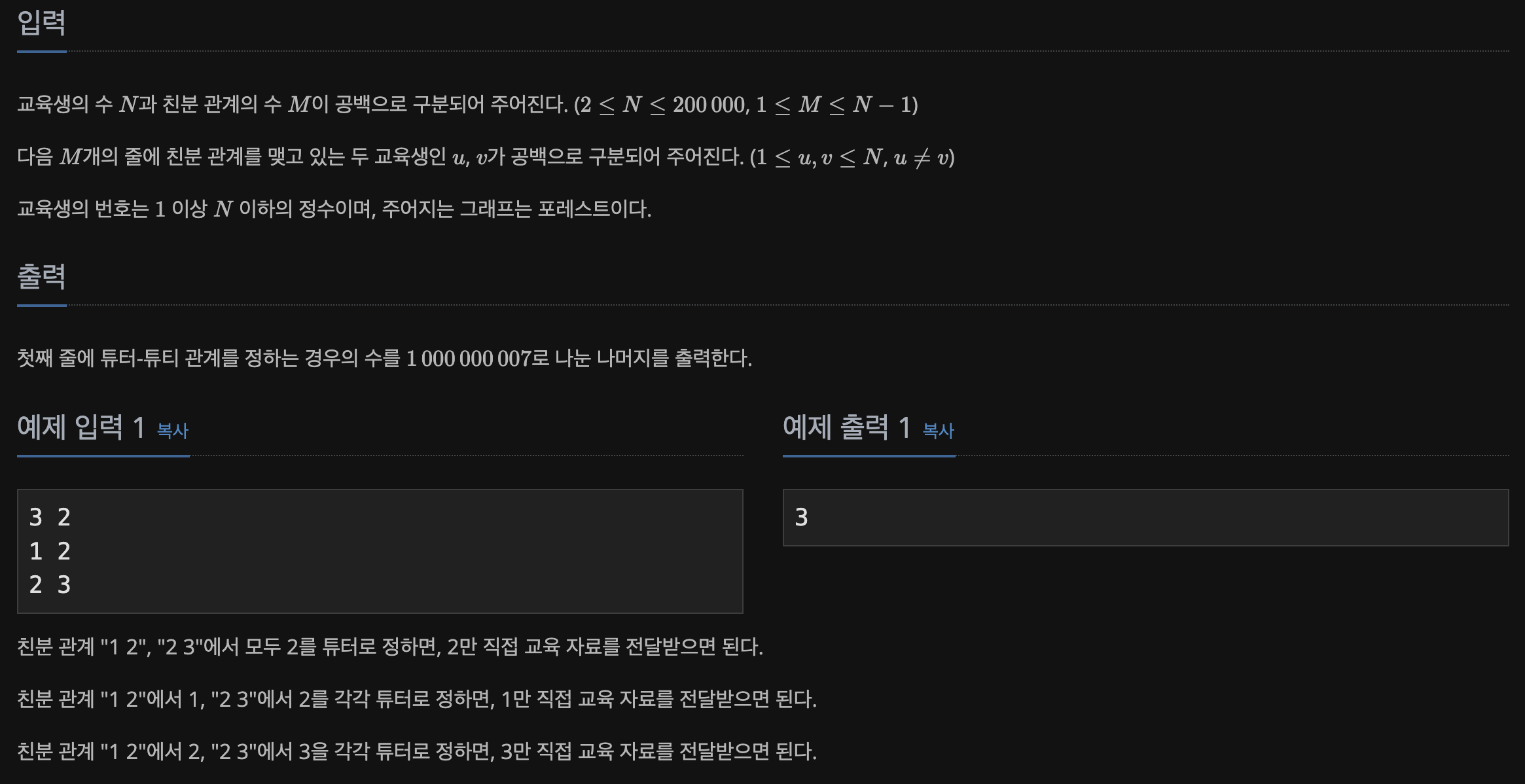
📃 Input&Output
🌁 문제 배경
가. 접근 방법
각 연결간의 size를 곱해준다.
튜터 튜티가 최소가 되려면 각 모임간에 한명이 튜터가 되면 되고, 한 모임간 튜터가 되는 경우의 수는 모임의 인원수이고 각 모임마다 경우의 수가 n1, n2 면 모든 경우의 수는 이 값들을 곱한 값이된다.
나. 사용할 알고리즘 선택
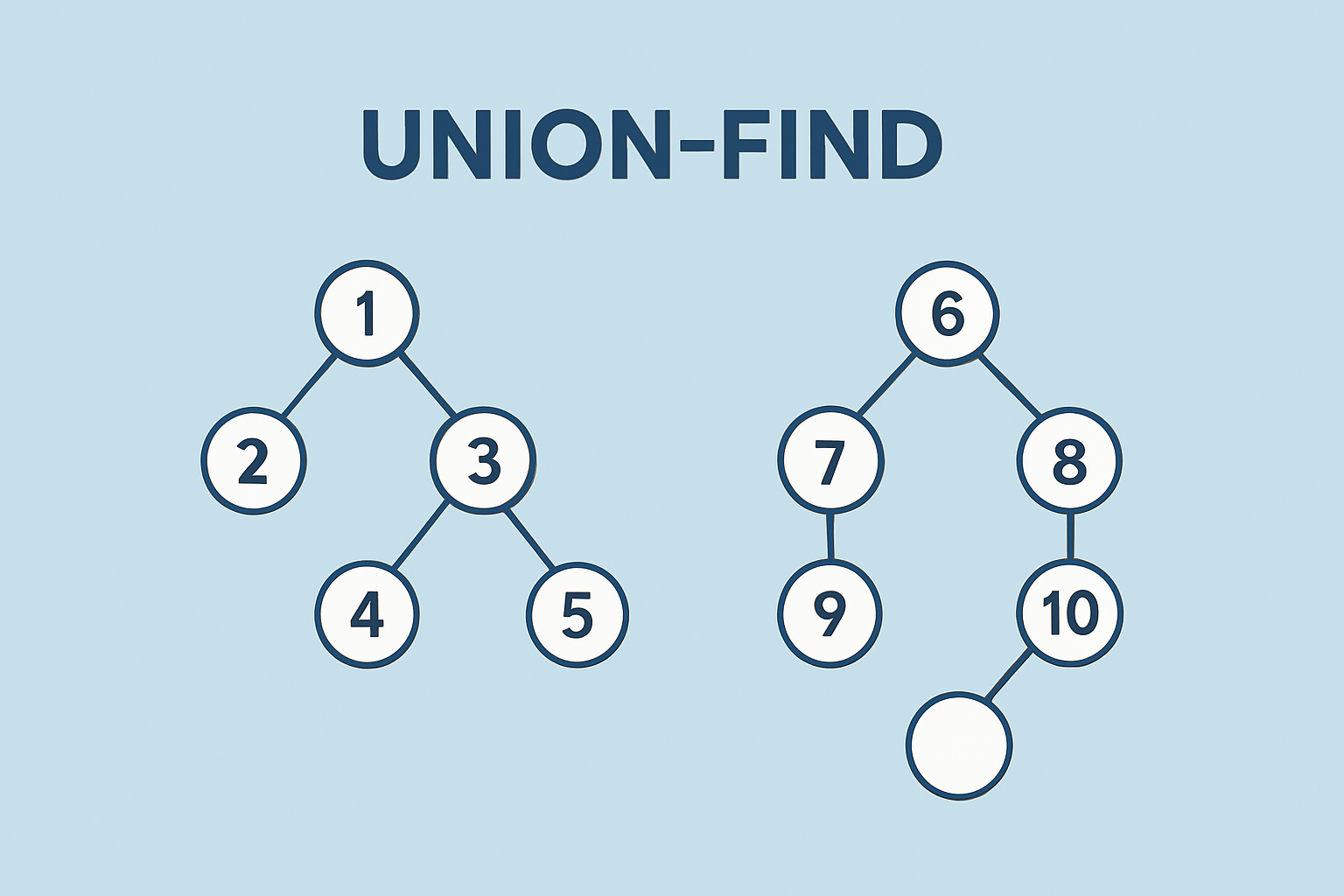
유니온 파인드
📒 해결 과정
가. 유니온 파인드를 사용하여 각 연결망 구현
위의 문제배경-접근방법에서도 말했듯이, 튜터는 연결망에서 한명으로 설정해두고 그 경우의 수는 각 인원수이며, 모든 연결망의 경우수를 생각하려면 곱을 해주면 된다.
나. 각 연결망의 인원수끼리 서로 곱한다.
모든 연결망의 경우의 수 고려를 위해 곱셈을 사용한다.
💻 Code
import java.util.*;
import java.io.*;
public class P24542 {
// 부모노드 찾는 함수
public static int GetParent(int[] parent, int idx) {
if (parent[idx] == idx) {
return idx;
}
return GetParent(parent, parent[idx]);
}
public static void UnionParent(int[] parent, int a, int b) {
a = GetParent(parent, a);
b = GetParent(parent, b);
if (a < b) {
parent[b] = a;
} else {
parent[a] = b;
}
}
static boolean FindParent(int[] parent, int a, int b) {
a = GetParent(parent, a);
b = GetParent(parent, b);
if (a == b) {
return true;
}
return false;
}
public static void main(String args[]) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
int a, b;
long res = 1;
int[] parent = new int[N + 1];
Map<Integer, Integer> hashMap = new HashMap<>();
Iterator<Integer> iter;
for (int i = 0; i <= N; i++) {
parent[i] = i;
}
for (int i = 0; i < M; i++) {
st = new StringTokenizer(br.readLine());
a = Integer.parseInt(st.nextToken());
b = Integer.parseInt(st.nextToken());
UnionParent(parent, a, b);
}
for (int i = 1; i <= N; i++) {
int root = GetParent(parent, i);
if (!hashMap.containsKey(root)) {
hashMap.put(root, 1);
} else {
hashMap.put(root, hashMap.get(root) + 1);
}
}
iter = hashMap.keySet().iterator();
while (iter.hasNext()) {
int key = iter.next();
int value = hashMap.get(key);
res = (res * value) % 1000000007;
// res *= value % 1000000007; -> 오버플로우
}
bw.write(res + "\n");
bw.flush();
bw.close();
}
}
🎸 기타
가. 유니온 파인드란?
유니온 파인드는 각 노드가 같은 연결상에 존재하는지 확인하는 알고리즘으로 다음 3개의 메서드로 구현된다.
GetParent(int[] Parent, int idx): 현재 노드의 부모(루트) 노드를 찾는 재귀 함수UnionParent(int[] Parent, int a, int b): a와 b의 연결을 이어주는 Union함수union은 합치다라는 뜻이고, a와 b의 루트 노드를 이어준다.
FindParent(int[] Parent, int a, int b): 각 루트 노드를 조사하여, a와 b가 연결되어 있는지 확인해주는 Find 함수여기서 Find 는
두 노드가 같은 연결안에 있는지 찾아준다라는 의미이다.
나. 자바 Dict구현
해쉬맵을 사용하여 구현된다.
Map<자료형1, 자료형2> hashMap = new HashMap<>();hashMap.put(key, value): 데이터 추가 그리고 이미 존재하는 경우, 값 변경hashMap.get("영수 나이"): 탐색hashMap.containsKey(key): 해쉬맵에 key 존재하는지 확인
그리고 해쉬맵을 순회하는 방법은 다음과 같다.
Iterator<int> iter = hashMap.keySet().iterator();
while(iter.hasNext()){
int key = iter.next();
int value = hashMap.get(key);
}iter.next(): key를 얻는다.hashMap.get(key): value를 얻는다.
참고로 iterator은 해쉬맵을 완성한 뒤에 할당해야한다.
🤔 느낀점
iterator을 자료구조 값을 다 갱신한 뒤에 객체 생성해줘야 한다는 점이 신선했고, 이번에도 long 을 안쓰고 Int를써서 result값이 2억을 넘어서 실패가 발생했다. 이런 점을 많이 신경써야할 것 같다. 그리고 연산할 때도 나누는 경우에는 그냥 값 while문 안에서 갱신될 때, 나눠버리자. 나눗셈은 결합, 분배 법칙이 작용되니깐 말이다.
