
ML Kit란?
ML Kit는 Google의 온디바이스 머신러닝 기술을 Android 및 iOS 앱에 결합한 모바일 SDK입니다.
최근 유행하는 AI 서비스들은 대부분 API를 활용하여 네트워크 환경에서 서비스를 제공하고 있습니다.
그에 반해 Google에서 제공하는 ML Kit는 네트워크에 의존없이 AI 기능을 사용할 수 있습니다. (단, ML Kit에서 제공되는 기능만 사용이 가능합니다.)
ML Kit에서 제공되는 기능
- 텍스트 인식
- 얼굴 인식
- 얼굴 메시 감지
- 자세 인식
- 셀카 분류
- 제목 세분화
- 문서 스캐너
- 바코드 스캔
- 이미지 라벨 지정
- 객체 감지 및 추적
- 디지털 잉크 인식
이번 포스팅에서는 ML Kit의 얼굴 인식 기능에 대해 알아볼 예정입니다.
얼굴 인식
소개
ML Kit의 얼굴 인식 기능은 다음과 같은 주요 기능을 가지고 있습니다.
- 얼굴 특징 인식 및 위치 파악
- 얼굴 특징의 윤곽 가져오기
- 얼굴 표정 인식
- 동영상 프레임에서 얼굴 추적
- 실시간으로 동영상 프레임 처리
ML Kit의 face-detection API는 이미지 혹은 동영상에서 사람의 얼굴을 인식할 수 있습니다. (ML Kit의 얼굴 인식은 주로 사람의 얼굴을 검출하는데 특화되어있습니다. 사람의 얼굴과 비슷한 동물의 얼굴도 검출될 수 있습니다.)
!주의사항!
2024년 2월 20일face-mesh-detection API | version 16.0.0-beta2가 출시되었습니다.
실시간 얼굴 인식이 필요한 상황에는face-detection API보다face-mesh-detection API를 사용하도록 권장하고 있습니다.

API 사용 플로우
- FaceDetectorOptions 구성
- 검출하고자 하는 대상을 InputImage로 변환
- 구성된 FaceDetectorOptions를 가지고 FaceDetection 클라이언트 생성
- 검출 대상을 FaceDetector에 넣어 실행
- Listener 객체를 통해 결과를 콜백
ML Kit의 face-detection API는 위와 같은 플로우로 최종 결과값을 받을 수 있습니다.
최종 결과값으로 Face라는 객체를 얻게 되는데 해당 객체를 통해 검출된 얼굴의 특징들을 획득할 수 있습니다. (단, 이후 설명에 나오겠지만 FaceDetectorOpions 설정에 따라 획득 가능한 특징들이 다를 수 있습니다.)
이제 빌드 구성과 각각의 플로우를 설명드리겠습니다.
의존성 추가
dependencies {
implementation 'com.google.mlkit:face-detection:16.1.6'
}
// or
dependencies {
implementation 'com.google.android.gms:play-services-mlkit-face-detection:17.1.0'
}face-detection API를 사용하기 위해서 minSdkVersion은 21 이상을 요구하고 있습니다.
위와 같이 API 사용을 위해 두가지 방법이 존재하는데, 각각의 주요 차이점은 '앱 설치 시 AI 모델을 번들로 묶이느냐'입니다.
com.google.mlkit:face-detection
장점
- 앱을 설치 할 때 모델도 같이 디바이스 내에 설치하여 앱 내에서 곧바로 기능을 수행할 수 있습니다.
- Google Play 서비스가 설치되어 있지 않은 디바이스에서도 앱을 사용할 수 있습니다. (ex. 화웨이 및 특수 목적의 디바이스)
단점
- 앱의 크기가 약 6.9MB 증가 합니다.
- 모델이 의존성에 포함되어 있어, 모델이 변경될 경우 업데이트된 버전을 배포해하고 앱 업데이트를 진행해야 최신 모델을 사용할 수 있습니다.
com.google.android.gms:play-services-mlkit-face-detection
장점
- 비교적 앱 설치시 적은 용량을 가지며 설치 합니다. (약 800KB)
- 모델을 앱 설치시 다운로드 되는것이 아닌 Google Play 서비스를 통해 동적으로 다운로드하기 때문에 항상 최신 모델을 유지할 수 있습니다.
단점
- 해당 모델을 사용하는 기능을 수행할 때 모델을 Google Play 서비스를 통해 다운로드 됩니다. 이로인해 기능 수행시 네트워크 환경을 요구합니다.
- Google Play 서비스가 설치된 디바이스 내에서만 정상작동합니다.
1. FaceDetectorOptions 설정과 Client 생성
우선 FaceDetector 클라이언트를 구성하기전에 얼굴 인식을 통해 획득하고자 하는 값들을 설정하기 위해 옵션을 설정해줍니다.
각각의 옵션은 FaceDetectorOptions 인스턴스를 생성할 때 기본값을 가지고 생성합니다.
setPerformanceMode: 얼굴을 감지할 때 속도 또는 정확도를 우선시합니다.
setLandmarkMode: 눈, 귀, 코, 뺨, 입과 같은 얼굴의 '특징'을 식별할 것인지 여부입니다.
setContourMode: 얼굴 특징의 윤곽을 감지할지 여부입니다. 윤곽은 이미지에서 가장 뚜렷한 얼굴에 대해서만 감지됩니다.
setClassificationMode: 얼굴을 '웃고 있음' 및 '눈을 뜨고 있음'과 같은 카테고리로 분류할지 여부입니다.
setMinFaceSize: 이미지 너비에 대한 머리 너비 비율로 표현하여 원하는 가장 작은 얼굴 크기를 설정합니다.
enableTracking: 얼굴에 ID를 할당할지 여부입니다. 이는 여러 이미지에서 얼굴을 추적하는 데 사용할 수 있습니다.
*이번 포스팅에서는 '이미지 내 얼굴 검출' 기능을 제작하기 위해 setPerformanceMode에 대해서만 자세하게 다룹니다.
setPerformanceMode에는 2가지의 타입을 선택할 수 있습니다.
PERFORMANCE_MODE_FAST (기본값)
- 이미지 내 얼굴 인식을 속도 위주로 수행합니다.
PERFORMANCE_MODE_ACCURATE
- 이미지 내 얼굴 인식을 정확도 위주로 수행합니다.
여기서 주의할 점은 두가지 모드로 같은 이미지에 대해 작업을 수행하면 각각의 결과가 다릅니다.
'정확도 위주로 수행한 결과가 속도 위주의 결과를 포함하고 있을 것이다' 라고 예상할 수 있지만 실제로 테스트 결과 각각의 결과가 서로 다르다는것을 확인할 수 있었습니다.
때문에 사용자에게 모드 선택을 요구하는것이 아니라면, 두가지의 결과를 하나로 구성되게 만드는것이 중요합니다.
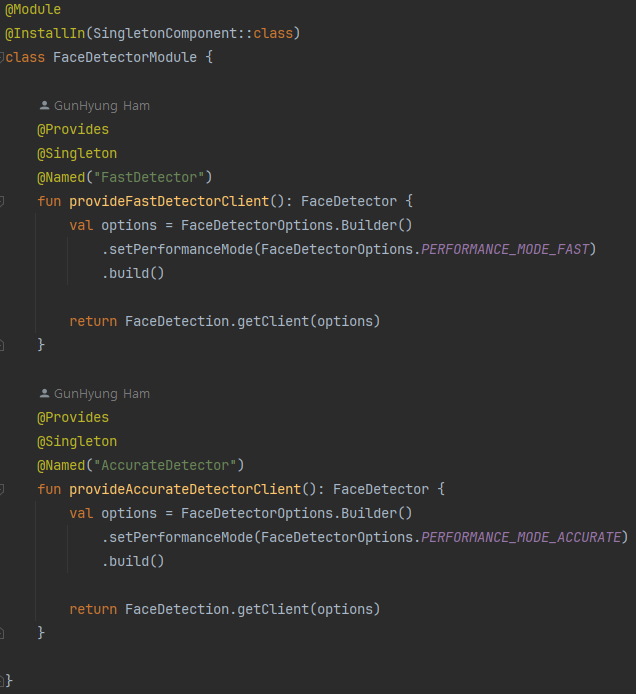
다음은 실제로 제가 구성한 옵션 설정 방법입니다.
*
Hilt를 사용한 이유는 코드 품질을 높이기 위해 사용되었습니다.
Hilt사용없이 각각의 옵션을 이후에 나오는DetectionServiceImpl객체에서 생성하여도 됩니다.
Hilt를 활용해 각각의 옵션을 설정하고 FaceDetection 클라이언트를 생성하여 FaceDetector 객체를 반환해주고 있습니다.
각각의 옵션을 가지는 FaceDetector 객체의 인스턴스를 Hilt를 통해 생성하며 실제 작업이 이루어지는 DetectionServiceImpl에서 생성자 주입을 통해 FaceDetector를 사용할 수 있습니다.
2. InputImage로 변환
FaceDetection을 사용할 때에는 대상을 InputImage 객체로 만들어 주어야 합니다.
주의할 점은 480x360 픽셀 이상인 이미지를 사용해야 정상적으로 검출을 수행할 수 있습니다.
다음은 InputImage로 변환을 도와주는 메서드들입니다.
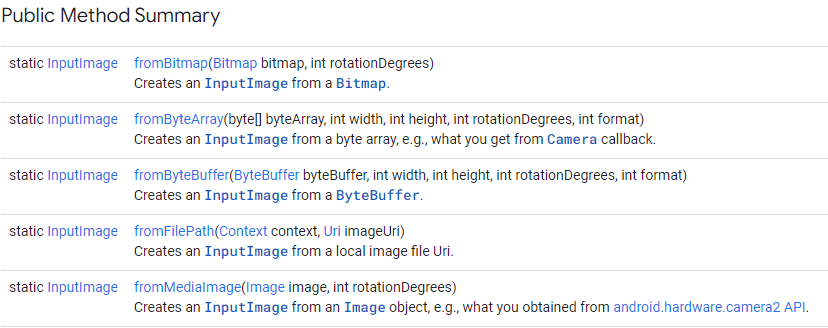
Bitmap, ByteArray, ByteBuffer, FilePath, MediaImage 타입의 이미지들을 InputImage로 변환이 가능하나, URL을 직접 InputImage로 변환을 지원하고있지는 않습니다.
그렇기 때문에 URL을 사용하는 환경에서는 중간 변환 과정을 한번 더 거치게 됩니다.
*URL을 변환할때에는 Bitmap으로 변환 이후 InputImage로 변환할 수 있습니다. 이밖에 파일로 저장하여 변환할 수도 있습니다.
다음은 실제로 구현한 코드 입니다.

변환하고자 하는 image의 타입은 ByteArray로 주어지고 있습니다.
fromByteArray와 fromByteBuffer 메서드에서는 이미지의 너비, 높이, 회전각도, 포맷을 추가로 필요합니다.
너비와 높이가 필요한 이유는 ByteArray와 ByteBuffer 타입의 이미지는 단순하게 연속된 바이트 데이터를 가지기 때문에 검출하고자 하는 원본 이미지의 너비와 높이를 요구합니다.
회전각도가 필요한 이유는 ML Kit가 얼굴을 인식할때 이미지가 회전이 되어있다면 이미지 내 눈, 코, 입 등 올바르게 검출되지 않을수 있기 때문입니다.
포맷은 아래 사진과 같이 3가지 타입의 포맷을 선택할 수 있습니다.
실제로 안드로이드에서 사용되는 ImageFormat은 다양하게 존재합니다.
그중 ML Kit에서 사용 가능한 포맷은 아래 사진처럼 3가지를 사용합니다.
마찬가지로 포맷이 필요한 이유는 ByteArray와 ByteBuffer 타입에서는 이미지의 포맷을 알수 없기 때문에 설정을 요구합니다.
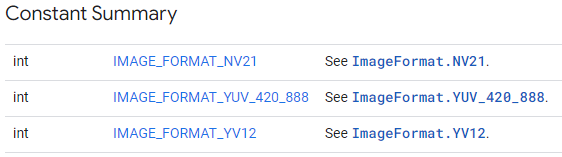

*해당 포스팅에서는 각각의 포맷에 대한 상세 설명을 다루지 않습니다.
이에 대한 내용은 다른 포스팅에서 다뤄볼 예정입니다.
Q. 왜 ByteArray 타입으로 이미지를 전달하고 있나요? 안드로이드에서 주로 사용되는 Bitmap 혹은 Uri가 아닌 이유가 무엇인가요?
A. 현재 프로젝트는 클린 아키텍처로 제작이 되어있습니다. 클린 아키텍처의 핵심인 'Domain' 레이어에서 순수 코틀린 or 자바로 이미지 모델을 가질수 있는 방법은 코틀린 ByteArray 타입으로 이미지의 데이터 스트림을 가질수가 있습니다. (Uri를 String 형태로도 가질수 있습니다.)
때문에 현재 모델에 사용되는 이미지 타입은 아키텍처 규약에 맞게 ByteArray로 사용하고 있습니다.ByteArray가 아닌 다른 방법이 있다면 댓글로 알려주세요!
3. FaceDetector 실행 및 Face 객체 반환
모든 준비가 끝나면 FaceDetector를 실행하여 결과값을 획득할 수 있습니다.
설정이 끝난 FaceDetector의 process() 메서드를 통해 검출을 수행합니다.
다음은 실제 구현된 코드입니다.
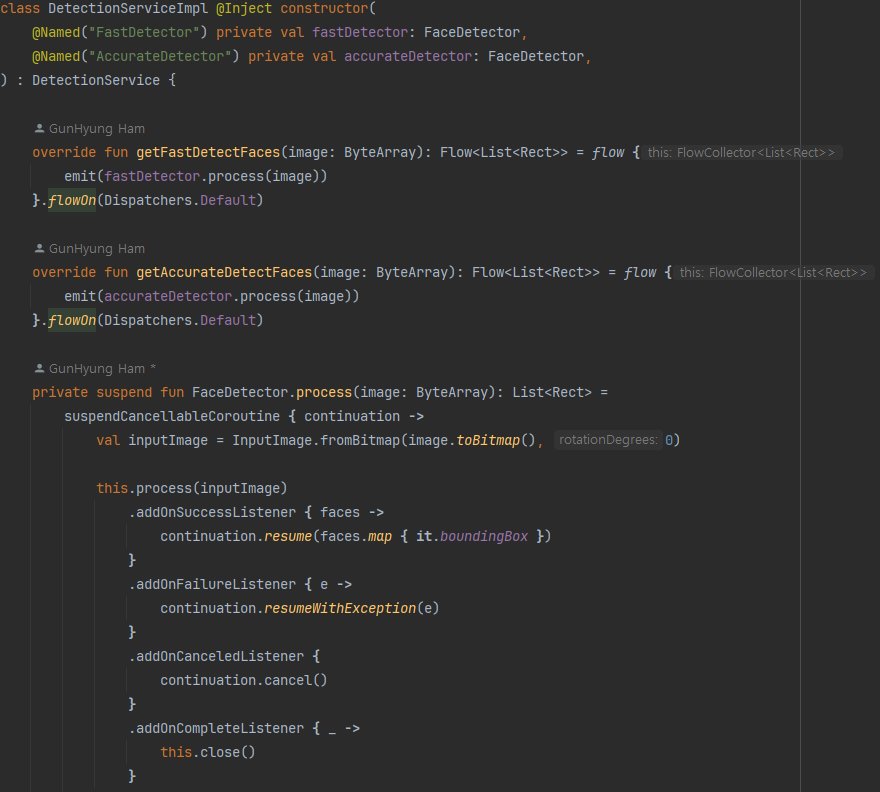

FaceDetector.Process 함수를 살펴보면 this.process(inputImage) 부분을 확인할 수 있습니다.
검출된 결과를 리스너를 통해 콜백 형태로 반환되는 것 또한 확인할 수 있습니다.
.addOnSuccessListener: 검출을 성공하였을 때List<Face>객체를 반환 합니다.
.addOnFailureListener: 검출에 실패하였을 때 예외를 반환합니다. (예외 목록)
.addOnCanceledListener: 검출을 취소 하였을 때 처리 할 내용을 정의합니다.
addOnCompleteListener: 위 세가지 리스너가 호출된 이후 호출되는 리스너입니다.
검출에 성공하게되면 List<Face> 객체에 접근하여 해당 검출된 얼굴에 해당하는 특징을 얻을 수 있습니다.
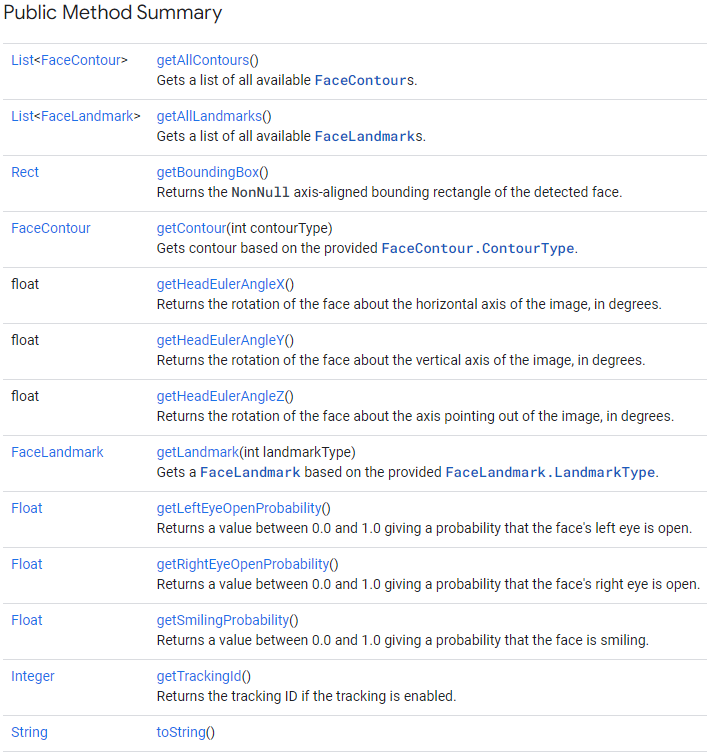
프로젝트의 요구 사항은 '이미지 내 얼굴 검출' 이므로 얼굴의 좌표값을 얻기 위해 BoundingBox를 얻는것을 선택하였습니다.
BoundingBox는 모델이 이미지 내에서 인식한 얼굴을 Rect 객체로 반환을 해줍니다.
또한 addOnCompleteListener 에서 혹은 검출이 취소가 되었을때 this.close()를 통해 모델을 닫아 앱 내 리소스를 관리해주고 있습니다.
*FaceDetector를 닫아주지 않는다면 디바이스 내 많은 리소스를 할당하고 있어 메모리 누수가 발생할 수 있습니다.
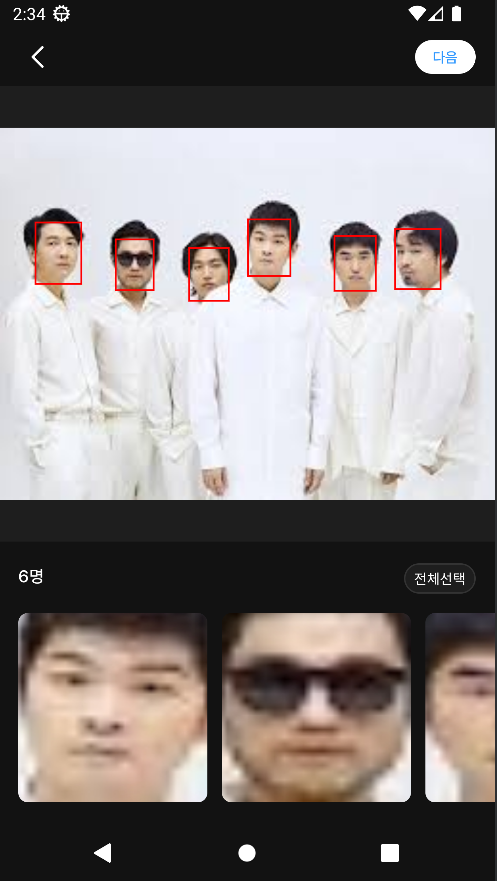
결과 이미지
참고 자료
