File System
- 3개의 Virtualization중 마지막: Storage에 대한 Virtualization
1. Concept of File System
- 기본적으로 CPU의 입장에서 storage는 그냥 block들의 집합이다.
- 따라서 우리에게 필요한 것은... 이 block들의 위치와 정보를 논리적으로 재구성하는 것이 필요하는 것인데, 이 일을 해주는 것이 File System이라고 할 수 있겠다.
1-1. Abstraction for Storage
-
File
- 시프에서도 진짜 정말 많이 봤다... Sequence of Bytes
- 이 Byte들을 한개의 unique한 id(inode #)로 묶어서 관리함
-
Directory
- File이긴한데, 특수한 형태의 File
- File 이름과 Inode #를 mapping하는 형태의 특수한 파일
- Directory도 하나의 File이기 때문에 다른 Directory에 mapping될 수 있다.(Hierarchical directory tree)
- 그렇기 떄문에... 모든 파일은 root로 부터 시작되는 path를 알고 있어야 한다.
1-2. File System Components
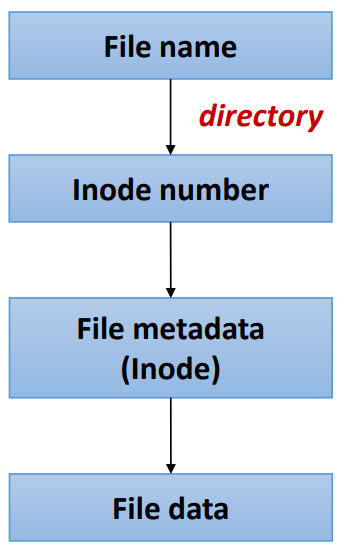
- File name을 통해서 inode #를 찾으러 간다.
- 그렇다면 최초의 File은 어떻게 하느냐... root가 있다 우리에겐
- File System마다 구현이 다르긴 한데, 일단 root를 보통 특정 위치에 고정적으로 저장하고 여기서 부터 search해 나가면 된다.
- inode number를 이용해서 inode를 가져온다.
- inode는 보통 system이 array의 형태로 가지고 있다.(진짜 array 맞다. inode #는 이 array의 index로 기능하는 것)
- inode에는 file의 metadata를 가지고 있다. 이 metadata를 이용해서 disk에서 data를 꺼내온다.
2. File System Design
2-1. Mapping
- 결국 file은 disk 내부에서는 block들로 쪼개져서 저장된다.
- <filename, data, metadata> → [a set of blocks]
- 이 block을 어떻게 저장할 것인가...
- HDD편에서 언급했지만, LVN순으로 정렬되면 가장 효율적으로 reading할 수 있다는 결과를 우리는 이미 봤다.
- block들을 어떤 식으로 disk에 mapping하는지는 매우 중요한 작업
2-2. File System Design Issues
- Goal
- Peformace: 결국 seek time을 줄여야 한다. 어떻게? → Data Structure: Tree, Hashing. 어떤 식으로든 빠르게 찾아내야 한다.
- Reliability: Data Persistence.
- Scalability: Multicore support, Maximum file size등 각종 편의 사항
- Design issues
- Metadata에는 어떤 정보가 저장되어야 하는가?
- data block을 어떤 방식으로 저장할 것인가?
- data block을 어떻게 mapping 할 것인가?
- crash로 부터 어떻게 회복할 것인가?
2-3. File Attributes
2-4. POSIX Interface
-
not important
-
Lesser known operation
int fsync(int fd);
int unlink(char *pathname);fsync:stdio는 아시다시피 자체적인 buffer를 사용하여 io system call을 wrapping하기 때문에, 이 buffer를 disk와 sync하는 함수unlink: 잘 보면, POSIX interface에 remove 함수는 없다는 것을 확인할 수 있다. 이는 file system 자체가 ref count를 기반으로 작동하기 때문에, 자동으로 ref count가 0이 되면 삭제되는 방식이기 때문이다...
2-5. Path
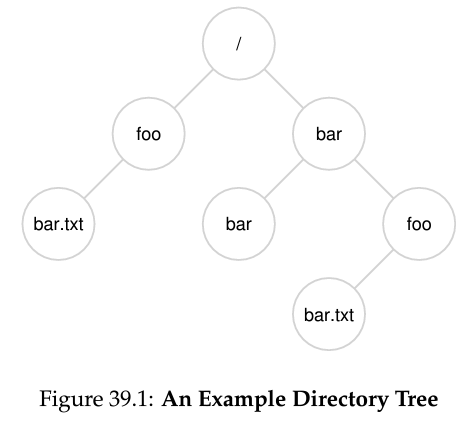
- Path finding sequence: e.g. open("/bar/foo/bar.txt");
- root directory를 찾는다.(이는 언제든지 찾을 수 있도록 고정된 위치에 저장되어 있다.)
- root의 contents에는 root dir 내부에는 inode #를 저장해놓고 있다.
- 여기서 bar를 찾는다.
- bar를 찾아서 해당 inode를 또 찾는다.
- foo를 찾는다.
- foo내부에 있는 bar.txt를 찾고 연다.
2-6. Link
2-6-1. Hard Link
- 한 파일시스템에 inode #는 고유하다는 사실을 우리는 알고 있다.
- 또한 디렉토리는 inode #를 리스트로 가지고 있는 일종의 파일.
- Hard Link는 서로 다른 파일이 같은 inode #를 링크하고 있는 방식.
- 따라서 inode는 refcount를 사용하여 몇개의 파일이 이를 링크하고 있는지를 저장한다.
2-6-2. Symbolic Link
- 간단히 말하면 바로가기...
- Hardlink와는 다르게 link하고자 하는 파일의 directory를 저장하는 방식으로 동작하며, link를 실행시키면 해당 directory로 이동하여 파일에 접근한다.
- 이와 같은 link가 사용된 이유는 inode #가 한개의 file system에 대해서는 고유하지만, mount등에 의해서 서로 다른 file system끼리는 연결이 되기도 하기 때문에... 실질적으로는 고유하지 않은 경우가 많기 떄문이다.

물리와 컴퓨터